刘晓敏,张艳丽,聂磊
(佳木斯大学,黑龙江佳木斯154007)
数据库与信息管理
一种基于K均值的网络文本信息挖掘算法设计
刘晓敏,张艳丽*,聂磊
(佳木斯大学,黑龙江佳木斯154007)
随着大数据、云计算等技术的发展和普及,人们已经进入到共享信息的“互联网+”时代,智能化、自动化系统运行积累了海量的数据资源,比如数以亿计的文该文档,这些资源充斥着整个网络,无处不在,给人们的搜索带来了极大的不便。该文为了解决网络文本挖掘速度慢、准确度低的问题,提出了一种基于K均值的网络文本信息挖掘算法,实验结果表明,与传统的遗传算法、支持向量机、BP神经网络相比,该文算法的准确度可以显着提高10.3%,并且不需要先验知识,更加适用于当前互联网搜索引擎、专家系统等,具有重要的作用和意义。
K均值;聚类;文本信息挖掘;准确度
Key words:K mean;clustering;text information mining;accuracy
1 概述
网络文本信息挖掘是搜索引擎、专家系统、知识库等软件的核心组成部分,也是当前互联网应用的重要基础,为电子商务、智能旅游、在线学习、物流仓储、金融证券等业务的推广提供了强大的支撑[1]。网络文本信息挖掘可以从海量的、散乱的、无序的文本数据资源中发现潜在的、有价值的信息,并且将这些信息分类成为一个个的文档簇,这些文档簇的内部具有高度相似性,簇之间具有高度的相异性。网络文本信息通过相关算法操作之后,提供给人们的结果是可解释的和有价值的,因此可以帮助人们进行决策[2]。目前,网络文本信息挖掘方法经过多年的研究,已经诞生了很多有效的挖掘方法,比如BP神经网络、支持向量机、遗传算法、贝叶斯网络等,本文提出在网络文本挖掘中引入K均值算法,并且利用模糊数学改进K均值算法,满足大规模文本数据信息的挖掘和操作。
2 背景理论
K均值算法是一种基于距离的聚类算法,其可以将任意两个对象之间的距离作为相似性度量指标,利用无监督学习的思想,将距离最近的两个数据对象集成在一起[3]。K均值算法执行中不需要任何先验知识,任何一个搜索引擎、专家系统都不需要背景知识即可完成信息挖掘和分类,同时可以利用文本数据挖掘准确度等指标进行评价,将文本数据汇聚在一起,实现数据解释和操作。K均值算法形式化描述如下:假设网络文本数据集包含n个文档,使用X={x1,x2,…,xn}表示,每一个文档都可以使用m个特征刻画,这些特征可以是某些出现频次较高的单词,也可以是文档的风格、主题等,则第j个样本的特征向量使用则数据集可以使用矩阵进行描述,如公式(1)所示。
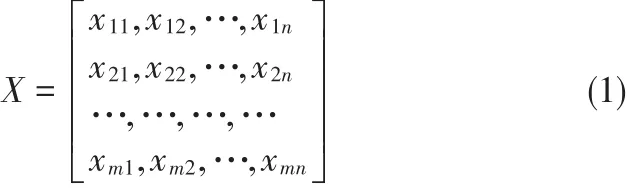
其中,xij表示样本j的特征i,j=1,2,…n,i=1,2,…m。
在k均值算法处理过程中,为了能够消除数据集m个特征值之间的量纲差别,需要对其进行归一化处理,具体处理过程如公式(2)所示。

其中,ximax表示第i个指标特征的最大取值;ximin表示第i个指标特征的最小取值;rij表示归一化后xij的取值。归一化之后,数据集的描述矩阵X可以使用矩阵R表示,如公式(3)所示。
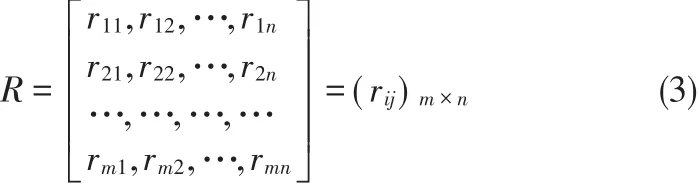
假设数据集X拥有C个类别,则数据集X的模糊识别矩阵如公式(4)所示。
水稻种质资源耐旱性鉴定与评价………… 王宝祥,余剑锋,徐 波,刘 艳,邢运高,孙治广,迟 铭,石时来,边建民,徐大勇(1)
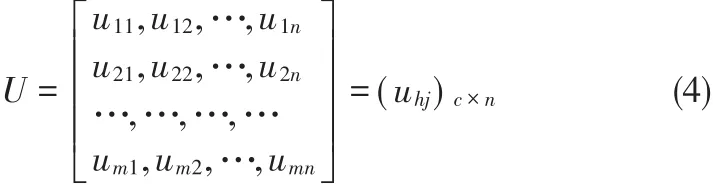
其中,uhj表示数据集中的样本j归属于h类的隶属度,h=1,2,…,C,并 且 满 足 以 下 约 束 条 件 :0≤uhj≤1,
假设类别h的m个特征值称为类的聚类中心,则c个类别的特征值可以使用模糊聚类中心阵表示,如公式(5)所示。
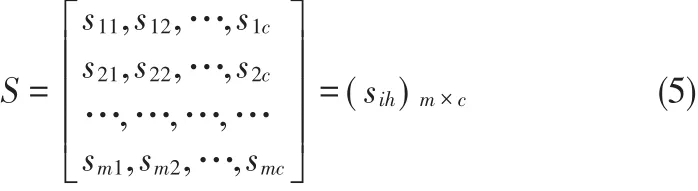
其中,sih表示类别h指标i的归一化特征值,0≤sih≤1。
在模糊聚类执行过程中,可以设置不同的特征权重,一般能够优化突出较为重要的特征贡献,特征权重向量如公式(6)所示。
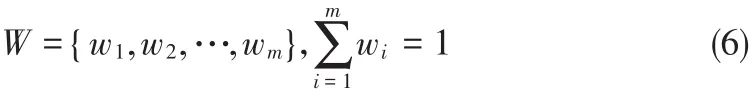
通过分析,模糊聚类的目标函数如公式(7)所示。
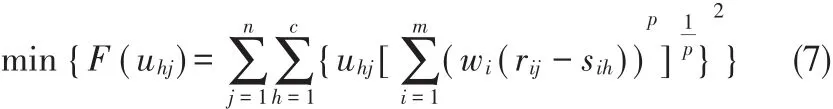
具体地,在实际应用过程中,具体算法可以采用迭代执行的过程,求取目标函数的最优解。
3 基于K均值的网络文本信息挖掘算法设计
3.1 算法设计
K均值算法引入模糊数学,将K均值从传统的硬划分改进到软划分,这样就可以更好地将每一个数据划分到类别中,具体的基于模糊数学改进的K均值算法目标函数如公式(8)所示。
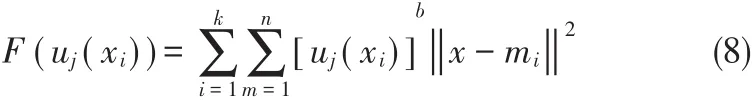
其中,b是一个模糊数学模糊度常数,其可以有效地控制模糊聚类结果,通过对模糊K均值算法的隶属度进行求导数,可以获取一个最优解,具体的执行过程如公式(9)和公式(10)所示。
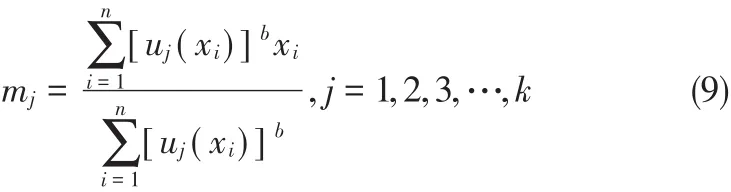
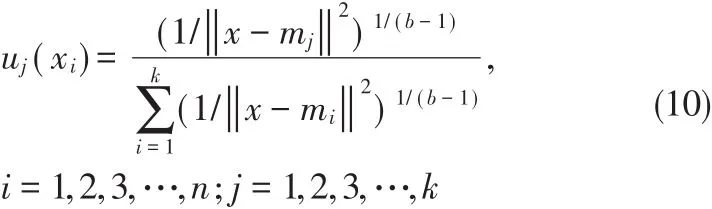
模糊K均值算法执行过程中,公式(9)和公式(10)可以进行有效的迭代执行,这样就可以将所有的数据划分到一个簇中,标注出每一个文本对象属于数据集的隶属度,当隶属度不再改变时即可完成数据的分类。具体地,模糊K均值算法在文本信息挖掘中的具体描述如下:
算法输入:文本对象簇数目K,参数b,包含N个文本对象的数据集。
算法输出:K个文本对象簇。
算法步骤:
1)利用随机化方法或启发式方法划分文本对象数据集为K个簇,指定每一个簇的中心数据对象为mi;
2)计算文本对象数据集中的每一个文本信息隶属函数,采用的计算公式为公式(10);
3)基于步骤2)的隶属度函数计算各个簇的中心值mi,采用的计算公式为公式(9);
4)遍历文本对象数据集中每一个文本,当隶属度不再发生任何变化时,算法终止;否则返回步骤2)。
3.2 算法实验结果及分析
文本数据挖掘过程中,本文的主要关注点是新的算法能否从数据集中正确地发现隐含的模式,以便能够判断文本数据挖掘的准确度。因此,在算法运行和评估过程中,本文使用已知类标号的数据集进行实验,便于进行准确度评估。具体地,本文的数据集来源于Lang收集的数据集,这个数据集共计包含2000篇信息文档,并且分为20个种类,对每一件文档都进行了评论,每个评论组均包含100个用户,因此评价指标包括2000个评价得分。本文通过对2000篇文档进行评价,将其分为9个子数据集,每一个文本数据集包含了500篇文档,每一个子数据集都是从2000篇文档中随机挑选的,具体地,Binary_1,2,3表示拥有两个真实类别的文档数据集;Multi5_1,2,3可以描述拥有五个真实类别文档数据集;Multi10_1,2,3可以描述拥有十个真实类别文档数据集。
通常情况下,文本数据挖掘采用准确度作为算法评价运行结果的标准,算法运行结果准确度评价公示如公式(11)所示。
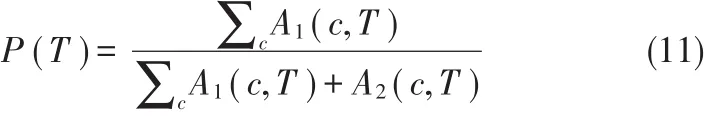
其中,t∈T,其可以描述相关的数据对象;c∈C,其可以描述相关的类别号或簇标号;A1(c,T)可以描述相关的已经正确分配到c中的文档或元组的数量;A2(c,T)可以描述相关的算法不正确的分配到c中的文档或元组的数量;A3(c,T)可以描述相关的不正确的没有分配到c中的文档或元组的数量。
通过观察可以得知,在9个数据集上,本文算法可以很好地发现真实文档之间存在的模式,更加精准地寻找到潜在结构和类别,尤其是在两类文档中,算法分析的准确度可以达到93.94%,能够为用户推荐更符合和满足用户需求的文档数据搜索结果,具有非常重要的意义和价值,这些搜索数据机结果可以为百度搜索、搜狗、腾讯、京东等网站进行使用,更好地为用户提供真实文档数据分析服务,发掘潜在的价值。算法运行结果如表1所示。
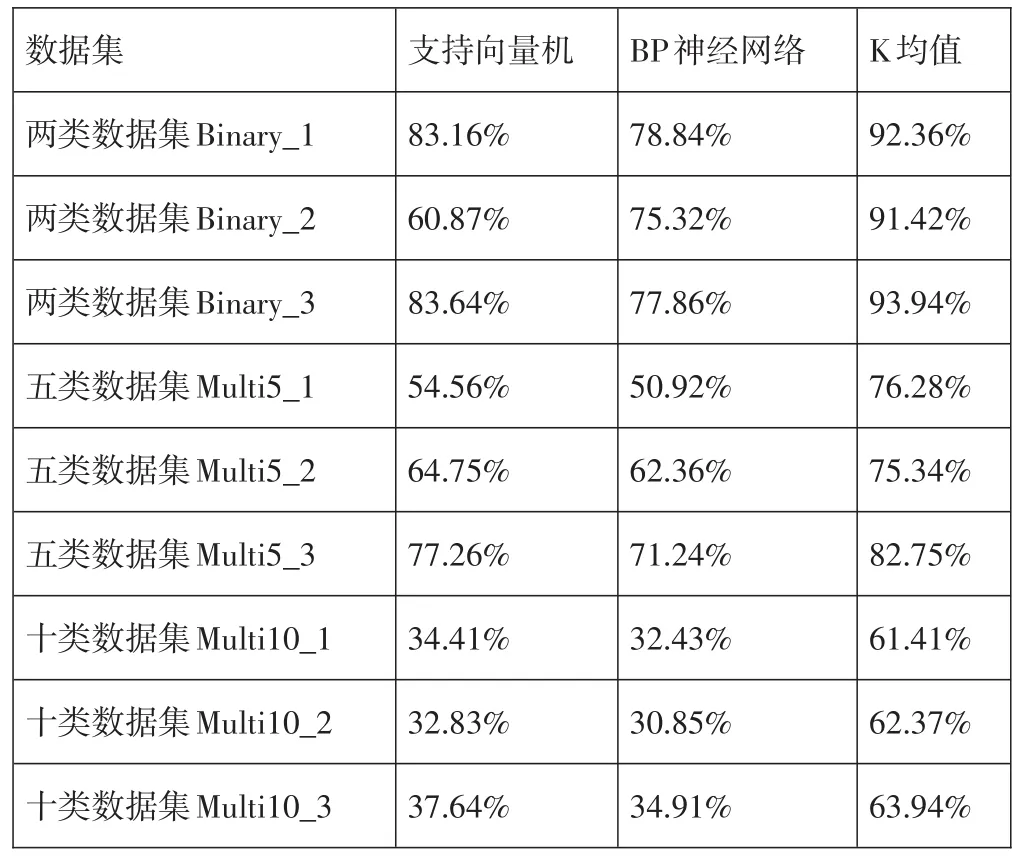
表1 三种算法的实验结果准确度对比
4 结束语
随着互联网应用软件的诞生,软件运行积累了海量的数据资源,尤其是文本文档数据呈现出指数级速度上升,因此如何从海量文本数据中挖掘潜在的有价值信息,为人们的工作、生活和学习提供决策支撑,具有重要的作用和意义。K均值是一种无监督的聚类算法,其在执行中不需要任何先验知识,同时可以准确地划分文本数据集,提供一个准确的分类,可以大大地提高电子商务、搜索引擎的运行准确度,具有重要的作用和意义。
[1]张群,王红军,王伦文,等.基于词条属性聚类的文本特征选择算法[J].计算机应用研究,2017(2):369-372.
[2]徐勇,陈亮.一种基于降维思想的K均值聚类方法[J].湖南城市学院学报:自然科学版,2017,26(1):54-61.
[3]李晓瑜,俞丽颖,雷航,等.一种K-means改进算法的并行化实现与应用[J].电子科技大学学报,2017,46(1):61-68.
Design of Network Text Information Mining Algorithm Based on K Mean
LIU Xiao-min,ZHANG Yan-li★,NIE Lei
(Jiamusi University,Jiamusi 154007,China)
TP311
A
1009-3044(2017)24-0001-02
2017-07-30
佳木斯大学校级重点项目《计算机科学与技术专业实施导师制的研究》(项目编号:2017LGL-009);佳木斯大学教研项目(2016JL1015);佳木斯大学学位与研究生教研项目(基于“产、学、研”的研究生创新能力的培养与实践)
刘晓敏(1980—),女,佳木斯大学,讲师,硕士,主要从事计算机专业的教学,主要研究方向为图像处理和模式识别;通讯作者:张艳丽(1974—),女,佳木斯大学,讲师,博士,主要从事农业电气化、电气工程专业的教学。



