秦灿 李旭东


摘要:近年来,商品的种类和数量迅速增长,使消费者难以找到感兴趣的产品。各大电商平台开始利用推荐技术为用户提供更好的服务,其中使用最多的是协同过滤推荐算法。主要概括了协同过滤推荐算法的核心思想,归纳了它的相似度公式和相应的评价法则,并总结了该算法目前存在的一些问题,以及研究人员针对这些问题给出的解决方案,最后提出了推荐算法的未来的改进方向。
关键词:电子商务;推荐技术;协同过滤;精准推荐;机器学习
中图分类号: TP301 文献标识码: A
文章编号:1009-3044(2019)13-0288-04
Abstract: In recent years, the variety and quantity of commodities have increased rapidly, which makes it difficult for consumers to find products of interest. Major e-commerce platforms begin to use recommendation technology to provide better services for users, among which collaborative filtering recommendation algorithm is the most widely used. This paper mainly summarizes the core idea of collaborative filtering recommendation algorithm, summarizes its similarity formula and corresponding evaluation rules, and summarizes the existing problems of the algorithm, as well as the solutions given by researchers to these problems. Finally, the future improvement direction of the recommendation algorithm is proposed.
Key words: E-commerce; recommendation technology; collaborative filtering; precise recommendation; Machine learning
1 背景
近年来,随着互联网技术的高速发展,互联网成为信息共享和处理的平台,不同行业的用户们开始利用互联网处理信息,然而面对互联网上日见增多的资源,用户很难在各种资源中获得对他们有价值的内容。网络资源可以包含电影、新闻,也可以是购物网站中的商品信息等。面对日益增多的网络资源,学者们提出了搜索引擎技术[1],它能搜索和筛选所需要的信息,用户必须手动输入关键字才能出现自己需要的信息,当用户不明确当前需求时,该技术也就不能帮助用户获取有用的信息了。后来出现了推荐系统,它依靠用户的行为记录,并结合个人注册信息为其提供较精准的信息推荐服务。一般而言,推荐算法可分为:基于内容的推荐、基于关联规则的推荐、协同过滤推荐和混合推荐等。而当前使用最为广泛的便是协同过滤推荐算法。
2 协同过滤推荐算法理论
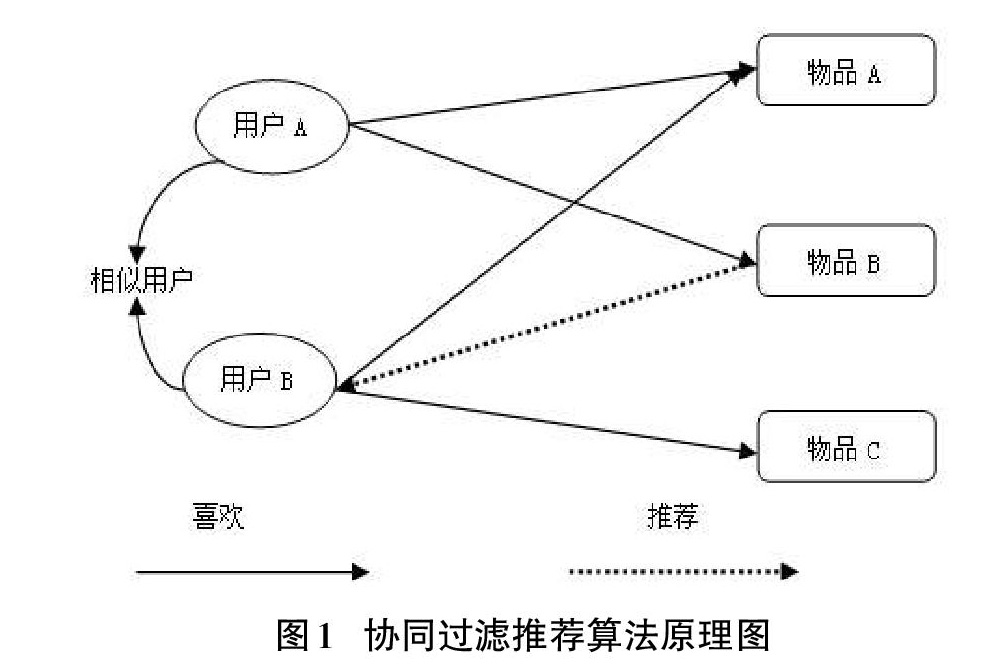
1992年施乐帕克研究中心的高柏等人提出了一种叫Tapestry的框架用来新闻推荐和信息筛选的协同过滤推荐模型[2]。协同过滤算法的本质上属于机器学习方法,它能很好地解决搜索引擎的检索内容过于单一的问题,该算法的主要思想:用户A和B存在共同的偏好,当用户A喜欢购买或者浏览物品a时,推测出用户B也可能喜欢物品a。协同过滤算法运用用户的历史行为数据进行比对并计算相似度,然后生成推荐矩阵。协同过滤推荐算法原理如图1所示。
协同过滤算法主要分为三种类型:基于用户的协同过滤算法[3-4]、基于项目的协同过滤算法[5]和基于模型的协同过滤算法[6]。
2.1 协同过滤推荐算法的基本原理
协同过滤推荐算法实现过程主要包含收集用户信息、相似度计算、生成推荐列表这三个步骤。
⑴ 收集用户评分信息
首先通过数据挖掘,获取用户评分数据集,生成相应评分矩阵,评分矩阵如表1所示。
⑵ 相似度计算
相似度是衡量两个对象的类似的程度,最常使用的计算方法:余弦相似度[7]、Pearson相关系数[8]和修正余弦相似度 [9]。
余弦相似度[7]就是将两个用户的评分数据分别设一个向量,然后利用余弦定理公式计算两个向量的余弦值。若它们之间的余弦值越小,则说明它们的相似程度越高。计算公式如下:
⑶ 预测评分并生成推荐列表
选取最近邻居,根据上一步过程计算可以得到用户间的相似度,然后将相似度按照从大到小的顺序排列,最后针对目标用户生成个性化的推荐列表。
2.2 基于用户的协同过滤推荐算法
基于用户的协同过滤推荐算法通过比较不同用户的浏览或购买等行为数据的相似度,然后计算出与目标用户距离最近的集合,最后将这个集合中可能是用户最感兴趣的且没有浏览过的内容或项目推荐给目标用户。
2.3 基于项目的协同过滤推荐算法
近年来,随着京东、淘宝、拼多多等大多数电商平台面临着用户数量不断增长的情况,评分矩阵变得越来越复杂,从而导致相似度计算变得越来越困难,因此便出现了基于项目的协同过滤推荐算法。电商平台的商品数量相对稳定,但用户数是不断增加的,因此计算项目之间的相似度更容易。基于项目的协同过滤算法的原理:首先对用户的历史评分数据集进行分析,然后根据用户的偏爱程度对所有项目进行分类并排序生成集合,再使用最短路径算法在集合中找到距离该用户最近的新项目,最后为该用户生成推荐列表。例如小王刚在教材网站购买了《数据系统简介》,而《数据系统简介》和《Oracle数据库开发》非常相似,它们都属于数据库技术类的教材,因此,给小王推荐《Oracle数据库开发》。
2.4 基于模型的协同过滤推荐算法
基于用户的协同过滤和基于项目的协同过滤都归类于基于记忆的推荐算法,它通过分析比对用户已评分项目,以推算用户未评分项目,然后获得相应的推荐矩阵。但是伴随着用户和项目数量的不断增加,需要占用大量的网络和硬件资源,进行实时推荐时较困难。而基于模型的协议过滤算法是通过对用户的评分大数据进行挖掘,然后再利用机器学习的算法对之进行处理,将用户评分数据集分成测试集和训练集,然后使用训练集生成合理的推荐预测模型,最后利用该模型预测出其他尚未评分的项目。
3 协同过滤推荐算法的评价指标
⑴ 用户满意度
满意度是评估推荐系统合理性的重要指标。满意度是衡量用户对推荐结果认同度的指标,通常在电商平台中,可以通过分析用户浏览和购买等行为数据计算出满意度,例如某用户购买了系统给他推荐的某商品或长时间浏览了该商品,可以表示用户对该推荐结果是满意的。因此,可以通过购买或长时间浏览的商品总数与已推荐商品总数的比值来衡量用户的满意度,即推荐购买率。
⑵ 预测准确度
预测准确度是评价一个推荐算法预测用户评分结果的准确性,一般情况下,在我们评估预测准确度时,首先将数据库中的用户评分记录整理为训练集和测试集,然后应用机器学习算法生成包括用户行为和兴趣的推荐预测模型,推荐模型用于预测用户对测试集的行为和兴趣偏好。最后比较预测结果和实际测试集两者之间的重复度。预测准确度通常用均方根误差(RMSE)和平均绝对误差(MAE)来计算。
⑶ 覆盖率
覆盖率是评测一个推荐系统对需求量较低或者销售冷淡的商品的推荐能力,衡量方法是该推荐算法推测出的项目数与测试集中总项目数的比值,推荐的冷门商品的数量越多,间接的表示该推荐算法的质量越高。
⑷ 多样性
多样性主要是照顾到用户的购物需求是具有多样性的,为了提高用户的体验,满足用户对不同类别商品的需求,同时还能提高电商平台的运营效益,推荐系统需要面向用户推荐多种不同类别的商品,例如用户购物时可能同时需要蔬菜类、肉类和水果类,这时推荐列表的界面中需要同时出现这三类商品才能满足用户的购物需求。推荐系统多样性评测指标主要有两种:推荐列表多样性和平均多样性。
⑸ 新颖性
新颖性指标是说明为了给用户眼前一亮的感觉,即需要将用户以前没有看过和听过的项目进行推荐。新颖性的指标是用来评估项目的平均流行度,物品的新颖度随着物品的流行度提高而降低。
⑹ 实时性
推荐系统的实时性是指推荐给用户的项目必须具有时效性,否则不能取得较好的平台效益,例如当天用户购买某品牌手机时,应该同时推荐手机耳机等配件,而不是等到几天以后根据用户的购买行为数据再进行离线推荐手机配件。
4 协同过滤推荐算法面临的问题
(1) 数据稀疏问题
数据稀疏问题是推荐系统普遍存在的现象,协同过滤算法是使用用户的评分数据计算相似度的,但电商平台的项目数量相当大,而参与交互评价的项目数量较少,用户不可能针对每个项目都做出详细的评分,导致评分矩阵出现了不少的空白项,也就是评分矩阵出现了异常的稀疏问题,从而导致推荐结果出现偏差。
针对评分矩阵的数据稀疏问题,学者们提出了不少解决方法,最常用的有矩阵填充[10]、降维[11]、聚类[12]等。矩阵填充[10]是最简单的方法,它的方法是针对评分矩阵中用户没有给予评分的项目填入一个缺省的固定数值,这个固定数值通常是一个常数。其次,矩阵降维[11]也是一种降低稀疏性比较好的方法,它是通过先分析评分矩阵的主成分(PCA),然后再降低矩阵的维度从而降低了数据的稀疏性,这种方式虽然降低了数据的稀疏性,但是计算过程较为耗时,同时可能出现精确度下降问题。另外的一个方法就是聚类法[12],首先通过获取聚类中心,分析比对出目标用户与中心的距离,然后为目标用户选择距离最近的类,最后对用户未评分的项目给出评分。
(2) 冷启动问题
冷启动问题分为用户的冷启动、项目的冷启动。冷启动问题是由于推荐系统中新注册的用户缺少个人注册信息和购物行为信息,或者新添加的项目短期内缺少评分数据。推荐算法在计算相似度时因评分矩阵中缺少部分数据,从而不能为用户推荐新项目。针对这个问题,可以通过获取用户的个人注册信息,然后在其注册信息中提取其兴趣爱好并分类,最后根据所属分类给他推荐喜欢的项目。
(3) 可扩展性问题
协同过滤推荐算法是对系统中最新的用户-项目的评分数据进行全局分析,然后给用户较准确的推荐。但是,随着数据库中新增用户和项目的数量日益增长,从而直接导致相似度的计算机量变大,进而严重影响它的工作效率。针对这一问题,学者们提出了EM算法、模糊聚类算法和K-means聚类算法[12]等。
(4) 用户隐私问题
在网络中,用户的隐私保护是尤为关键的,电商平台的推荐算法的原理是使用用户的个人信息、用户行为的历史记录等属性进行相似度计算,以获得推荐结果。如果一个电商平台不重视用户的个人隐私保护,这会使得用户缺少安全感从而降低对平台的信任度,用户就不愿意提供更多个人信息用于推荐计算,这将降低推荐系统的准确性。主流的数据保护方法有数字摘要算法、对称加密算法、非对称加密算法[13]。
(5) 移动平台的推荐问题
当前,广大的网民普遍使用移动设备进行浏览新闻或者购物,但是由于手机等移动设备的屏幕大小和设备硬件性能限制,传统的协同过滤推荐算法不能直接应用在移动端,研究人员需要结合移动设备独有的参数如当前时间、地理位置、实时天气等参数,例如小张目前正在某城市旅游,他打开手机地图软件时,系统会自动给他推荐附近的旅游景点、酒店、公交车路线信息等。
(6) 用户的兴趣变化问题
在现实生活中,人的兴趣爱好可能随时变化的,用户兴趣既有长期也有短期类型。用户的兴趣会随着环境、年龄、性格改变等因素改变,但一般的推荐算法很难通过用户的历史行为数据去推测出用户兴趣的改变,可能某些时候的预测结果与用户当前的喜好不一致,例如一个用户平时喜欢看动漫作品,而在世界杯期间,他也可能会关注一些足球赛事直播视频。针对这个问题,算法的改进需综合考虑用户的位置信息、当前时间等多种因素。
5 结束语
协同过滤推荐算法广泛应用在电商平台、新闻推送软件、音视频软件,对提升企业效益有着不可或缺的作用。本文首先解读了协同过滤推荐算法的特点,其中详细介绍了算法的核心思想、算法的分类和算法的评价指标。然后分析了传统的协同过滤推荐算法普遍存在的问题,并依次列举出学者们提出的解决方法。对于未来的研究,协同过滤推荐算法需要考虑提高推荐的友好性、数据的安全性、移动平台的自适应性等。
参考文献:
[1]胡玲,李鹏,赵德平.基于WEB的钢铁行业信息搜索引擎技术[J].电脑知识与技术,2018,14(28):224-226,229.
[2] Goldberg D, Nichols D, Oki B M, et al.Using collaborative filtering to weave an information tapestry[J].Communications of the ACM.December,1992.35(12):61-70.
[3] Laizhong Cui,Peng Ou,Xianghua,Fu,Zhenkun Wen,Nan Lu.A novel multi-objective evolutionary algorithm for recommendation systems [J].Journal of Parallel and Distributed Computing.2016(10):69-73.
[4] 王成,朱志刚,张玉侠,苏芳芳. 基于用户的协同过滤算法的推荐效率和个性化改进[J].小型微型计算机系统,2016,37(03):428-432.
[5] 黄传飞. 基于项目的协同过滤算法的改进[D].江西师范大学,2015.
[6] 于波,杨红立,冷淼.基于用户兴趣模型的推荐算法[J].计算机系统应用,2018, 27(9): 182-187.
[7] 朱坤,刘林峰,吴家皋.一种基于节点位置余弦相似度的机会网络转发算法[J].计算机科学,2018, 45(12):61-65,85.
[8] 陈功平,王红.改进Pearson相关系数的个性化推荐算法[J].山东农业大学学报(自然科学版),2016, 47(6):940-944.
[9] Can Cui, Teresa Wu,Mengqi Hu,Jeffery D. Weir; Xiwang Li. Short-Term Building Energy Model Recommendation System: A Meta-Learning Approach,[J].Applied Energy. 2016(3):690-698.
[10] 钟宜梅.浅析矩阵填充方法[J].电脑知识与技术,2018, 14(23):270-271,276.
[11] 董骏.面向数据集的ST-SNE算法高维数据降维研究[J].计算机技术与自动化,2018,37(4):116-122.
[12] 王筱远.数据挖掘中的聚类算法分析[J].中国新通信,2018,20(23):110-111.
[13] 任华新.数据加密算法的综述[J].探索与观察,2016(18):95, 97.
【通联编辑:梁书】



