杨帆

摘要:这些年随着大数据时代的到来,企业的数据量在成倍的增长,互联网的普遍性和广泛应用赋予了大数据四大特征,分别为数据量大、数据类型多、处理速度极快以及价值密度低。而传统的单机模式在面对处理具有这些特性的大数据时显得力不从心,不仅存在着运算效率低下的问题,而且并不能很好的容纳不同类型的数据,扩展性较差。针对以上所述问题,采用云计算的技术建立大数据挖掘分析平台,对数据进行广泛的价值挖掘,从而提供科学的企业决策依据,是当今大数据平台构建的主要目的。本文将基于Hadoop对大数据平台构建的关键技术点进行分析,将会从数据的采集、框架计算、结果分析输出以及并行的数据算法等方面对技术的标准化进行调研和分析。
关键词:大数据分析;Hadoop平台;关键技术;标准化
中图分类号:TP393 文献标识码:A
文章编号:1009-3044(2019)15-0028-03
传统数据的挖掘分析和处理方法在大数据时代遇到不可解决的障碍。目前已有的产业行业发展过程中,当大数据问世之后都对其产生了较大的依赖性,因此在这样的倒逼状态下大数据分析行业也得到了快速的发展。在各项分析平台当中,Hadoop尤其受到各方面的关注,各大厂商都对该平台进行相对于自身的优化和定制化改造,这样的改造虽然能够为企业创造更大的价值,但是随之而来的还有数据接口标准以及分析数据服务标准的不统一等问题。这些困难也阻碍了目前数据分析技术的深入研究。因此,基于Hadoop平台的标准化工作在该产业发展遇难的过程中引来了专业领域人才们的关注。由于目前的大数据分析行业缺少在国际社会上普遍认可的标准,同时对于分析系统当中的接口以及细节没有产生统一定义,因此本文的主要目的就在于通过对各项数据的研究比对得出有关该行业中各项关键性技术标准化的可行方案,以便进行过标准化工作后的数据能够灵活地运用与各项需求中。
1 当前大数据产业的主要障碍与矛盾
目前大数据分析产业在发展中遇到的主要障碍主要是基于Hadoop平台的分析系统所提供的接口以及分析服务的标准都不尽相同。各个数据分析处理厂商对大数据在其处理挖掘数据价值的过程当中,都会有处理流程上的区别,在数据的采集、并行分析、算法以及数据展示这三个环节尤其各不相同。国际上对接口标准以及服务标准的规范与要求的缺失使得关键技术的应用难以统一,主要表现为以下问题:
首先,大数据系统化服务分析缺乏统一的服务规范以及接口。
其次,统一标准缺乏的原因,分析的结果以及数据无法在各大厂商之间通用,各个分析系统对数据结果有着不同的定义方法,因此即使对不同的问题数据场景进行分析的厂商是同一家,其结果的定义也不尽相同。这对相关业务的发展和数据共享的精神有着严重的负面影响。
除此之外,服务标准以及接口的不统一会对该产业的长远发展产生深刻影响。不同的标准服务以及接口同时并行,那幺基于Hadoop分析的GUI可视化操作以及维护方法等都需要对关键技术进行不同的优化以达到适配效果,这就使得大数据行业的关键力量在发展过程的当中被迫分散,对该行业的发展速度有负面影响。
2 典型数据分析系统架构
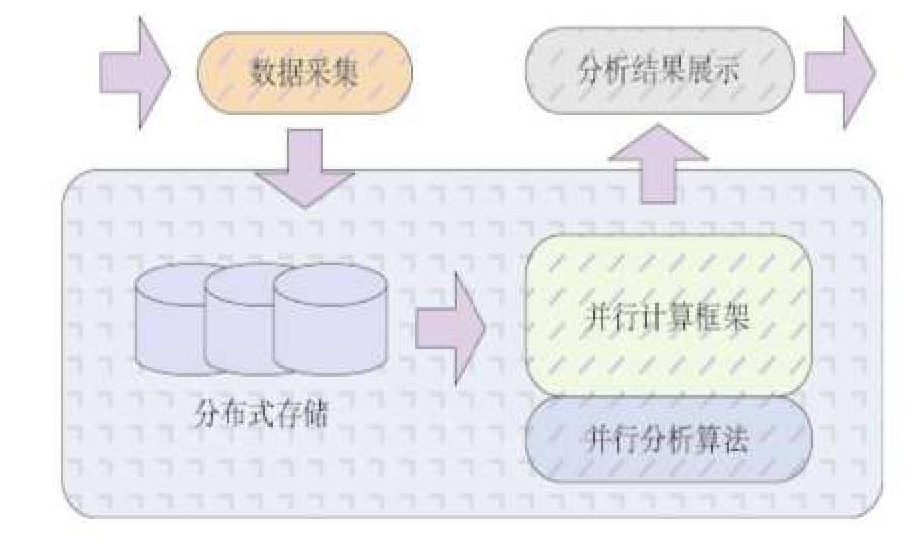
在经过对多个基于Hadoop大数据分析平台系统的对比,我们可以发现在平台系统的功能以及接口标准上虽然存在不统一的情况,但是经过对比的几个平台模式都是统一的,如下图所示:
1)数据采集
数据采集是将经过业务系统的用户已授权开放使用数据采集到 Hadoop分析系统当中,这个过程并不在 Hadoop平台当中实现,但是在整个大数据分析的过程当中却占有重要地位,连接着业务系统以及分析系统,实现其两者之间的解耦工作。
2)分布式储存
分布式储存在大数据分析平台当中是储存内容的重要支撑,所有基于Hadoop平台的反洗系统所使用的支撑储存子系统基本上为HDFS ,但同时也可以选择其他类型的云储存作为储存子系统。
3)并行计算框架
并行计算框架是基于Hadoop大数据分析平台系统的核心功能,它的作用在于提高该系统的分析效率,能够统一时间支持多台数据分析服务器的运作。
4)并行分析算法
传统的算法分析方法在复杂的大数据面前是无法应用的,只能基于 Hadoop并行分析算法的框架才能够实现并行化,然后在Hadoop分析系统中进行运行。与Hadoop结合较好的算法有Mahout、R语言以及我国学术界专业领域对于Hadoop进行针对优化之后产生的并行算法。
5)分析结果展示
分析结果的展示是指对整体流程进行大数据的分析之后,得出分析结果并且以分析结果为依据,提供给业务系统决策依据。一般的分析结果有统计结果以及数据分析结果两种。
3 主流关键技术对比以及标准化工作建议
我国的大数据挖掘、分析、处理等技术并没有形成一个成熟的大数据行业体系,而国际上并没有对相关技术的标准化提出明显简介。但是由于该技术的重要性以及高价值性,业内已经开始推动大数据分析技术相关服务的标准化工作,其中最具代表性的成果之一就是开放数据中心联盟推出的《大数据消费者指导手册》,其主要目标在于推动大数据分析行业的标准化。而网络储存工业协会也发布了大数据云储存的标准,储存标准的具体化为大数据分析行业发展以及标准化提供了基础。在大数据分析的整个程序当中总结经验并提炼出Hadoop平台的相关意见并进行总结,将会对这一平台的持续性发展以及大数据分析行业的发展有重要意义。
3.1 数据采集
目前主要的数据采集工具有Flume、Scribe、Kafka、Time Tunnel等,而这些平台也都实现了对Hadoop的对接和上载功能。笔者在此次的研究分析当中选择了Flume以及Scribe,现在Flume已经是Apache的孵化项目。
相似点:在业务系统对数据抓取的节点当中应用PUSH存储,也就是利用了该框架实现;两个数据采集工具在架构上都包括了agent、collector、storage三大核心组件;实现数据用过Thrift接口同步;都形成分布式的高可用并且可扩展采集系统。
不同点:Flume 支持多 master,没有单点故障;Scribe 只支持 Thrift 接口并且需要经由业务系统才能够实现;Flume 所提供的agent十分丰富多样并且都可以直接使用;Flume 还能够提供丰富的数据源功能。
在接口方面,上文提到Scribe 只支持 Thrift 接口,并且数据收集最后到Scribe的服务系统端上。而Flume支持各种数据接口,如下图所示:
从以上对比来看,Scribe提供的接收接口消息只有一个,那幺在来源处理方面就需要有根据该接口进行的大量应用系统定制工作。Flume提供的数据语言功能比较。全面并且相较于Scribe非常灵活,能够与多种平台进行对接。同时在文本处理监控以及端口监听方面能够无条件适用,与各种主流社交平台的插件对接,该系统可以以零再次开发的状态进行直接使用。
从以上对比可以看出,大量数据的采集标准化方法可以。从接口以及系统架构两个角度切入。数据采集的标准化建构可以基于PUSH以及包含agent、collector、storage三大核心组件并且支持分布可扩展等的模型架构来进行,而接口则可以根据Rest、Thrift 接口进行标准化设计。
3.2 并行计算框架
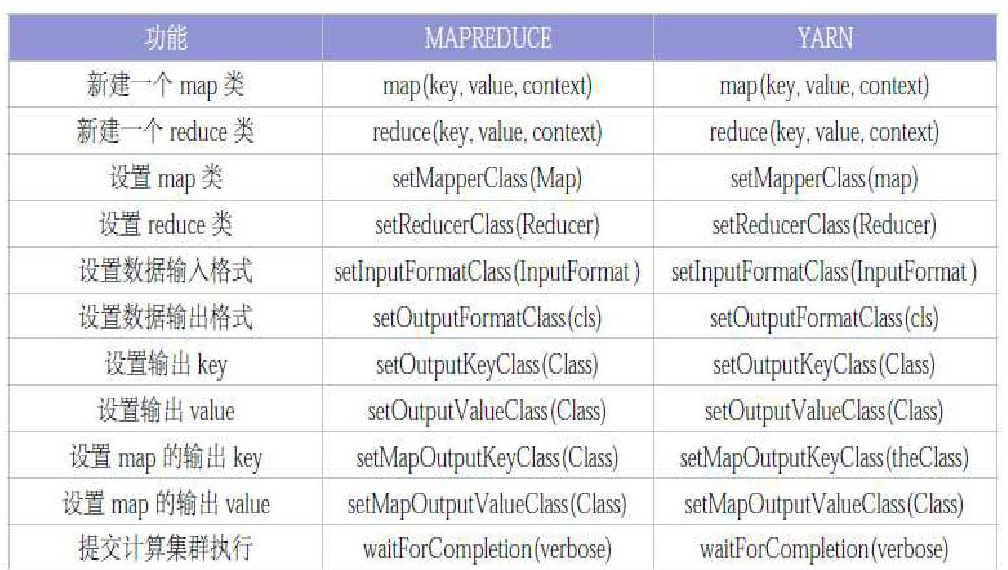
基于 Hadoop 平台的并行计算框架主要有:MAPREDUCE 以及 YARN。并行计算框架的主要作用是,给编程提供API接口,同时平台的任务需要基于API接口完成任务的并行计算。MAPREDUCE和 YARN 的主要计算接口比较如下图:
从上图对比结果分析可知,两个主要的并行框架接口层方面是基本相同的,这对于业务系统的接口来说是统一的。
由于目前的大数据分析系统的运行必须在并行计算框架的技术支撑之下才能够整体完成,因而对计算机框架进行优化是大数据分析标准化的基础一环。上述的对比表格经分析后可得出并行计算框架接口提供的一致性使得服务框架标准化绝对可行,除此之外在具体的接口处理情况当中,可以通过java、rest、C、thrift 等接口方式帮助接口在定义上的调整,以做好标准化的准备。
3.3 并行算法
数据分析系统的算法需要在Hadoop并行计算框架上进行并行化,只有该工作实现才能够通过并行算法覆盖各个类别、分类以及贝叶斯等包含大部分的数据深度挖掘方法。目前相对于Hadoop比较流行的算法工具有Mahout和R。
Mahout作为数据去挖掘,以及机器在挖掘过程中学习的。一个分布式框架在基于Hadoop平台的开发与设计算法工具库中实现的算法主要有分类,聚类以及协同过滤,其普遍适用程度基本上可以覆盖已有的可供分布式的算法。
而在R语言方面,目前已经存在连接开源R 与 Hadoop之间的连接器,使得其二者可以进行数据共享以及深度数据挖掘的分析。在对R语言特性进行一定程度的继承的同时,又能够利用Hadoop分布式计算环境为已有数据提供并行算法。
R语言作为Mahout通用算法库里面的一个编程环境和语言分支本身就充斥着较大数量的第三方包,这就方便开发者能够基于R语言工具对算法进行分析开发。
3.4 数据可视化
数据可视化是对大数据的结果进行分析后呈现出的统计结果,以及数据挖掘分析结果的图表展示。Hadoop目前只对大数据分析系统提供同步的。主要框架进行计算。在该平台之上进行结果分析,通常有两种形式,分别为采用文本文件方式存储在 HDFS、Key-Value 方式存储在HBASE,除这两种形式之外,有时也会将数据分析的系统结果储存到相应的关系型数据库当中。通过以数据分析结果为依据的各个厂商都可以以不同的形式呈现出个性化的可视化展示。
由于厂商的不同,会面对不同的客户需求,因此在数据可视化方面千差万别是可以被允许的。这符合市场的多样性特征。故在数据可视化这一环节并不建议进行统一的标准化工作约束。
4 总结
在大数据到来的时代,大数据应当成为我们生活当中可利用的一部分。那幺为了更好地实现对大数据术的利用,构建Hadoop数据处理平台进行分析就是利用大数据的重要一环,本文所研究的Hadoop处理平台属于当前大数据分析系统领域中最主流以及应用最广泛的处理平台,它将储存管理以及分布式计算融为一体,与多个主流用户的应用平台可以进行无条件对接,因此在该平台的构建与研究上进行深入非常有必要。
本文通过提出大数据产业发展的主要问题,分析大数据系统架构模型的典型来对数据采集、分布式储存、并行计算框架、并行分析算法、分析结果展示等进行充分说明与研究后提出了针对数据采集、并行计算框架以及并行算法三个方面的标准化建议。
当前我国大数据业务随着该类平台的开发持续进行开展,而Hadoop 平台也在这样的过程中越来越被各大厂商所关注。并且各厂商开始对该平台进行有针对的自身改造,以便符合各厂的使用习惯和最大化完成使用需求。而对该平台的改造又导致这个并未完全成熟,还没有统一标准的大数据分析行业变得差异化更加严重,使得基于Hadoop的大数据分析平台对于标准化工作的进行需求愈加紧急。当前如果要对我国市场当中的基于Hadoop平台执行标准化,必须考虑到在使用大数据分析的整个动态系统圈中,中国市场具有的特殊性以及中国人的使用和观看习惯。现代化分析体系标准化将会有利于各个大中小企业进入可以“以负担得起的成本”使用大数据分析以促进细分市场精准定位以及精准营销之外,就是促进大数据产业这个新兴行业的蓬勃与发展之外,对其他产业的促进作用也不可小觑。
参考文献:
[1] 李伟,孙新杰,武晋民.基于Hadoop的大数据分析平台构建研究[J].信息通信,2017(8):247-248.
[2] 王子毅,张春海. 基于ECharts的数据可视化分析组件设计实现[J].微型机与应用,2016(14).
[3] 李巍巍.基于云计算的大数据统一分析平台设计与应用[J].自动化与仪器仪表,2016(08).
[4] 杨美沂,林勇.大数据背景下基于云计算的政府统计平台构建[J].统计与决策, 2016(04).
[5] 林昕.基于云计算的大数据挖掘平台构建研究[J].山东工业技术,2015(17).
[6] 李国杰,程学旗.大数据研究:未来科技及经济社会发展的重大战略领域——大数据的研究现状与科学思考[J]. 中国科学院院刊,2012(6).
【通联编辑:唐一东】



