李驰


摘要:为了解决经典快速排序算法在面对待排序数据事先有序,大量重复数据,递归层数过深以及排序稳定性等诸多问题时暴露出来的缺陷,从枢轴的合理选择、三路划分、与其他排序法结合和尾递归优化等多个方面分析和总结了优化经典快速排序算法的各种策略,在实际使用快速排序算法时具有一定的参考价值。
关键词: 快速排序;算法优化;枢轴;三路划分;排序稳定性;尾递归优化
中图分类号: TP311 文献标识码:A
文章编号:1009-3044(2021)01-0226-03
Abstract:In order to solve the problems exposed by the classical quick sort algorithm, such as ordered data in advance, a large number of repeated data, too many recursive layers,and sorting stability, etc, this paper analyzes and summarizes various strategies of optimizing classical quick sort algorithm from the aspects of reasonable selection of pivot, three-way division, combination with other sorting algorithm and tail recursive optimization, it has certain reference value in the actual use of quick sort algorithm.
Key words: quick sort; algorithm optimization;pivot; three-way division; sorting stability; tail recursive optimization
排序一直以来都是计算机科学中的一个重要研究问题,尤其是在程序设计的算法领域。许多专家学者都在努力找到综合效率最高的排序算法。衡量排序算法效率的指标包括时间复杂度、空间复杂度和是否稳定等。这些指标中最重要的当然是时间复杂度。虽然归并排序和堆排序的最好和平均时间复杂度也能够达到O(nlogn),但其常数因子较大,所以快速排序实际上是目前发现的最快的排序算法。但是这并不意味着快速排序就没有缺点。事实上,在待排序数据事先有序,或者有大量重复数据,或者排序要求稳定性时经典快速排序算法表现就比较糟糕。所以对于经典的快速排序进行优化就显得很有必要,本文就从各个不同的角度分析和总结了对经典快速排序的优化策略。
1 具体优化策略
1.1优化不必要的交换
经典的快速排序算法需要将作为枢轴的元素在每次扫描停顿时轮流与后面的和前面的元素不断地进行交换。但其实每次交换之后枢轴的记录位置都是临时的,而它的最终位置是最后一次交换后的中间位置。所以,我们可以在算法中直接省略掉枢轴记录多次交换的折腾操作,取而代之是等到它的最终位置确定之后,再将它一次性的移动到中间的正确位置上[1]。虽然每次交换操作也只需要3条语句,但是当数据量大时,用赋值语句替换交换语句在效率上也是有一些提升的。具体从算法代码来看,就是有3个变化:
1)在每趟划分的前面追加一句“L.r[0]=L.r[low];//将枢轴记录放在哨兵位置”。
2)将经典快速排序算法中“swap(L.r[low], L.r[high]);”语句替换为赋值语句“L.r[low]=L.r[high]”。另一处也做相应对等的替换。
3)在每趟划分的后面追加一句“L.r[low]=L.r[0];//将哨兵位置的枢轴元素一次性移动到中间的正确位置上。”
1.2 针对数据事先有序的优化
如果待排序数据是随机的,通常经典的快速排序算法有很好的时间复杂度。因为理想情况下,每次划分的两个子序列很均匀,即长度差不多,因而递归树的深度约为logn,而每次递归的时间花费依次为 T(n)、T(n/2)、T(n/4)…T(1) ,最终推算出的时间复杂度为O(nlogn)。但是当待排序数据基本有序,甚至极端情况下完全有序(包括顺序和倒序)时,由于经典快速排序算法使用的枢轴元素通常总是第一个元素,导致每次划分出来的两个序列及其不平衡。一个为空,另外一个为只比上一次少一个元素的子序列,形成的递归树为一颗斜树,最终使得快速排序算法退化为冒泡排序,时间复杂度成为O(n2)。
为了避免这种情况的发生,需要打破经典快速排序算法每次固定选择第一个元素为枢轴的做法,另外选择枢轴。比较常见的有以下一些改进的做法。
一种做法是每次划分选择下标为low~high之间的随机整数的数组元素作为枢轴,这样可以大概率地避免由于待排序数据的有序性每次选到最大值或者最小值作为枢轴。但是这种做法还是和待排序数据的分布以及运气有关,另外调用随机函数也有一定的系统开销,而且也很难得到真正的随机数。
另外一种更常见的做法叫“三数取中”法[2]。即取下标为low、(low+high)/2和high三个数组元素的中间值作为枢轴。这种方法虽然不能百分之百保证每次划分的两个子序列绝对均衡,但是由于取到的是中值不是最值,所以可以大概率的保证不会出现极度不平衡的递归斜树。同时三数取中不需要遍历整个数组,只需几次简单比较,所以计算开销不大。
有文献还提到了一种“均值”法来取枢轴[3]。即将整个数组的平均值作为枢轴。虽然这种方法比“三数取中”法有更大的概率得到一颗非常平衡的递归树,但是由于每次划分都要遍历整个数组,会占用较多时间开销。此外,当待排序的数据大小极度悬殊时,例如,待排序的序列为{1,10,100,1000,10000,100000},仍然会使得每次划分非常不平衡。
1.3 针对数据大量重复的优化
排序算法的理论模型往往是一些互不相等的数据,但实际生活中的数据往往有大量的重复。例如,某个学校三千人的数学成绩大概率的集中在60到100分,这必然有大量的重复数据。经典快速排序算法对含有大量重复数据的待排序列的排序效率并不高。
一种常见的应对重复数据的改进排序算法是“三路划分快速排序”[4]。它的思想是将待排序序列分为三部分,最前面是所有小于枢轴元素值的元素; 中间是等于枢轴元素值的元素,最后面是所有大于枢轴元素值的元素。这样由于中间的部分不再是一个元素,而是好几个相同元素构成的一个区段,从而使得左右两个子序列的长度缩短了,当再次递归调用划分时效率会得以提高。划分的示意图如图1所示。
但以上的“三路划分快速排序”有个限制,就是要求枢轴元素刚好是重复元素。文献[4]中还提到一种“加强型三路划分快速排序”,让中间的那路数据不是值等于某个具体值的数据,而是在某个范围的数据,这样即使待排序的数据没有重复值,被划分出的中间那路也可以有不止一个元素。因此在本算法中需要有两个枢轴元素,在这里分别记为 middle1、 middle2。“加强型三路划分快速排序”的划分示意图如图2所示。
实现的核心代码如下:
void ThrQSort(Sqlist &L,int low,int high){
int originLow = low,originHigh = high;
int i = low, j = high,current;
//将两枢轴的值分别初始化为第一和最后一个元素
int middle1 = L.r[low],middle2 = L.r[high];
if(middle>middle2) swap(middle1,middle2) ;
//找到第一个大于middle1的位置i
while(L.r[i]<= middle1) i++;
//找到第一个小于等于middle2的位置j
while(L.r[j]> middle2) j--;
current = i;
//循环分3种情况处理中路的数据
while( current <= j)
{
if(L.r[current]<= middle1) swap(L.r[current++],L.r[i++]) ;
else if(L.r[current]>middle2) swap(L.r[current],L.r[j--]) ;
else current ++;
}
//分左中右三路递归调用
ThrQSort( L,originLow, i -1) ;
ThrQSort( L,i,current -1) ;
ThrQSort( L,current,originHigh) ;
}
1.4 与其他排序法结合的优化
众所周知,经典快速排序的时间复杂度是O (nlogn),通常认为是低于时间复杂度为O(n2)的插入排序的,但是这个结论是建立在数据n的规模很大的前提条件下的。所以,当数据规模n很小时(通常认为n小于16时),插入排序的时间效率反而优于快速排序。因此,当递归划分的子序列长度低于16时,我们可以选择不再递归调用快速排序,转而使用插入排序,这样可以使得算法效率有所提高。实现这个算法只需要在代码中加入一句判断语句:“if(high-low<16)InsertSort(L,low,high);”。
还可以考虑一种结合归并排序的快速排序算法[5]。前面已经说过,如果每次划分导致左右两个子序列的长度极为不平衡,就会增加递归树的深度,从而影响算法时间效率。所以,一种思路就是对每次划分出来的两个子序列的长度进行比较, 如果其中一个与另一个的长度比超过某一界限时, 则认为这是一个“畸形划分”, 对较短的子序列继续使用快速排序, 而把较长的子序列平分为两个子序列分别排序, 然后再进行一次归并。
1.5 算法稳定性优化
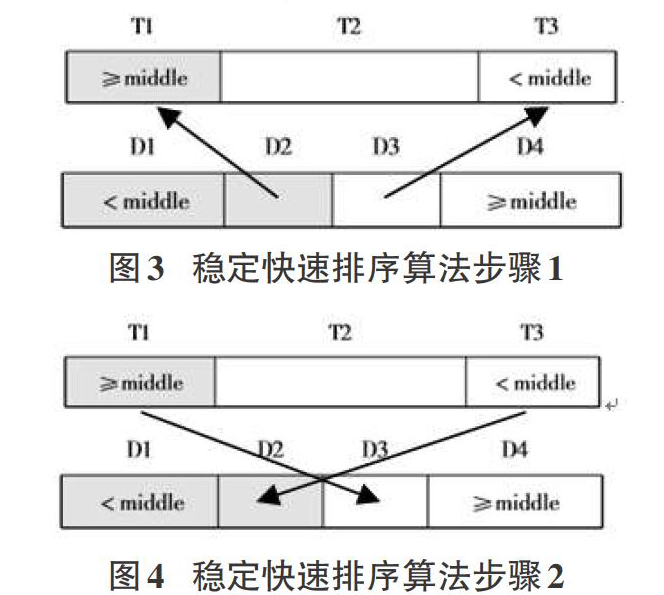
经典快速排序虽然速度很快,但是排序算法是不稳定。所谓排序算法的稳定性是指在待排序的记录序列中,如果存在多个具有相同的关键字的记录,经过排序后,这些记录的相对次序保持不变,即在原序列中, ri = rj,且 ri 在 rj 之前,而在排序后的序列中, ri 仍在 rj 之前,则称这种排序算法是稳定的,否则称为不稳定的。排序的稳定性有时是有实际意义的,例如只对提交作品成绩排名前100的人颁奖,如果第100名的成绩刚好有几个并列的,由于奖金有限只对并列成绩的第1个人颁奖,这时并列成绩的记录顺序就很重要,不希望在排序后改变。文献[6]给出了一种将经典排序算法改进为稳定排序的方法。具体思路是首先增加与待排序数据数量相同的辅助存储空间,然后进行如下两个步骤:1)在一趟快速排序中,左边的low指针与右边的high指针交替往中间扫描,在左边的low指针扫描时,将所有小于 middle 值(枢轴)的元素按原顺序存放在原来存储区最前部 D1 区,所有不小于 middle 值的元素按原顺序连续存放在辅助存储区最前部 T1 区; 在右边的high指针扫描时,将所有大于等于 middle 值的元素按原顺序存放在原来存储区最后部 D4 区,所有小于middle 值的元素按原顺序连续存放在辅助存储区最后部 T3 区;2)把T1 区数据复制到D4区的前部即D3区,把T3 区数据复制到D1区的后部即D2区,一趟处理完成。这两个步骤的示意图如图3,图4所示。
1.6 其他方面的优化
1.6.1优化递归操作
递归对性能是有影响的,经典的快速排序算法在每次划分之后有两次递归操作。当递归层次很深时,例如递归树不平衡,递归深度趋于n而不是平衡时的logn,就会占用大量的栈空间,从而降低性能。采用尾递归优化[7],对每次划分后较短的子序列仍然直接递归,而较长的子序列使用尾递归方式可以使得这个问题有所改善。实现代码如下:
void QSort(Sqlist &L,int low,int high){
while( low < high ){
int pivotloc = Partition(L,low,high);
//如果左边长度小于右边
if(pivotloc -low < high- pivotloc ) {
QSort(L, low, pivotloc -1); //左边
low = pivotloc + 1 ; //尾递归
}
else{
QSort(L, pivotloc +1,high); //右边
high = pivotloc -1; //尾递归
}}}
1.6.2加入逆序判断
经典的快速排序算法在一趟快速排序中,左边的low指针与右边的high指针交替往中间扫描,在这个过程中除了将当前元素与枢轴比较大小外没有再做其他额外的工作,实在有些浪费。有一种改进思路就是在这个扫描过程中对相邻元素进行逆序检测[8],如果检测到有逆序可以进行冒泡交换,甚至如果发现某一侧的子序列没有一个逆序时,证明这一侧的子序列已经有序,且又位于枢轴的同一侧,则可以直接终止这一侧的递归,以节省系统开销。
2 总结
经典的快速排序算法是目前已知排序算法中时间复杂度最好的算法,但是它在面临待排序数据事先有序,大量重复数据以及对排序稳定性有要求时仍然存在很多问题需要优化。本文从枢轴的合理化选择、三路划分、与其他排序法结合、尾递归优化等多方面对经典排序算法的优化策略进行了分析和总结,在实际使用快速排序算法时有一定的参考价值。
参考文献:
[1] 严蔚敏,吴伟民.数据结构[M].北京:清华大学出版社,2007.
[2] 李红丽,袁海根.快速排序的分析与改进[J].轻工科技,2012,28(1):65-66.
[3] 连顺金.快速排序的一种改进算法[J].三明学院学报,2009,26(4):420-422.
[4] 王善坤,陶祯蓉.一种三路划分快速排序的改进算法[J].计算机应用研究,2012,29(7):2513-2516.
[5] 刘新,刘任任.用归并法改进快速排序[J].计算技术与自动化,2005,24(1):31-33.
[6] 邵顺增.稳定快速排序算法研究[J].计算机应用与软件,2014,31(7):263-266.
[7] 程杰.大话数据结构[M].北京:清华大学出版社,2011.
[8] 张晓煜.基于前置、后置策略的快速排序算法研究[J].渭南师范学院学报,2018,33(16):29-37.
【通联编辑:唐一东】



