摘要:社交网络用户言论及关联性问题一直是舆情监控的一个重要工作和难点问题,针对用户不当言论及同一言论下不同用户之间的关联关系,文中通过爬虫和深度学习方法,以及大数据分析平台实现了针对用户不当评论信息来进行关联挖掘,通过爬取微博社交平台数据验证了论文提出的系统架构和方法,并取得了不错的效果。
关键词:爬虫;舆情;用户追踪
中图分类号:TP393 文献标识码:A
文章编号:1009-3044(2022)01-0026-03
1 背景
随着互联网的迅速发展,网络社交平台[1]不断涌现,大家可以随时随地在社交平台上发表自己对热点事件的观点和想法。由于社交平台的开放性和普及性,部分用户利用平台发表一些不当言论,如发布虚假消息、反动言论等。传统方式下,只能完全依赖人工去发现和评审这些言论,虽然准确率有一定的保证,但是时间成本和人力成本则不可估量。在这样的情况下需要借助机器来进行追踪,以便大大节省时间和人力成本。需求分析如下:
1)借助机器来对这些相关言论进行评审,并加以人工作为辅助决策。
2)借助机器对不当言论的用户进行平台信息追踪,并可潜在挖掘其他可能存在不当言论的用户。
3)基于机器获取到的大数据信息,构建专用知识图谱进行数据处理。
2 基于爬虫的社交平台舆情用户追踪系统设计
2.1 系统设计步骤
基于需求分析,系统设计分三步进行。
首先基于深度学习[2]实现机器评审,将机器评审问题定义为分类问题,从而基于深度学习来构建分类模型。首先通过语料库和分词构建大型中文字典,使用字典映射将文本转换为数值型向量,然后基于Embedding和LSTM构建神经网络架构,最后人工标注训练集进行多轮迭代学习。
然后基于Python爬虫[3]实现用户信息追蹤,针对某一特定社交平台,设计爬虫方案,使用爬虫来自动获取某话题下的评论信息、用户个人信息、用户关注的人的信息、用户粉丝信息和用户所发博文信息。
最后是基于知识图谱的数据处理,将大数据[4]信息解析为三元组数据,从而构建专用的知识图谱,并可基于该图谱实现各类应用,如预测、搜索等。
2.2 系统流程
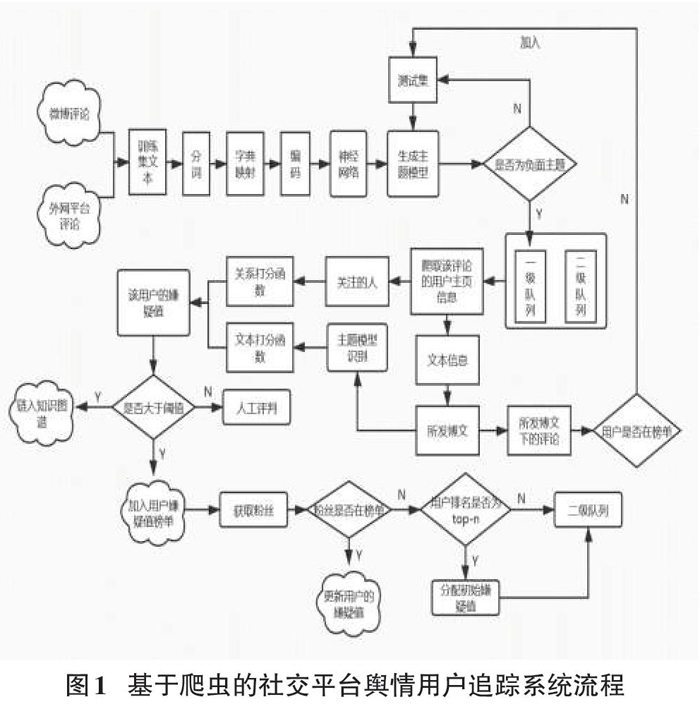
根据以上分析,基于爬虫的社交平台舆情[5]用户追踪系统流程如图1所示。
1)利用爬虫技术爬取微博平台和外网平台(如Facebook、推特等)的敏感话题评论,并且人工进行标注生成训练集,其中不当言论标记为1,不当言论标记为0。然后基于深度学习技术在训练集上生成二分类模型。
2)批量爬取微博平台的评论,将评论集作为算法的输入,基于已生成的模型对评论进行预测,如果预测为负面的评论,则将该评论人加入用户队列,等待被追踪,反之,则不处理。
3)实时监听用户队列并不断从中取出用户进行追踪,利用爬虫技术爬取用户资料并进行收集,包括用户个人信息、关注的人、粉丝和博文。
4)根据人际关系和文本信息分别设计打分函数,将已收集的用户资料输入至打分函数,计算得出用户嫌疑值。
5)设定阈值将用户传入不同的名单,如果用户被加入嫌疑榜单,则将该用户的粉丝加入用户队列,等待被追踪。
2.3 系统模块
2.3.1 神经网络模型生成模块
神经网络模型生成模块使用机器算法实现社交平台中言论的情感识别,代替人工识别言论是否为不当言论,从而大幅节省人力和时间成本。基于深度学习技术构建神经网络模型,该模型在人工标注的训练集上进行迭代训练,从而生成二分类模型。
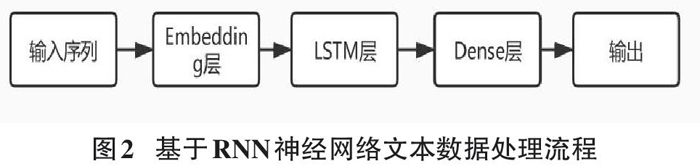
RNN神经网络在处理文本类数据有很好的表现,但是考虑到RNN难以记忆长期的文本信息,所以采用LSTM作为架构的核心组件。对于文本的编码,不采用高维稀疏的one-hot编码,而是基于任务训练的过程中自训练Embedding层来对文本进行编码,基于RNN神经网络文本数据处理流程如图2所示,通过输入序列检测目标文本,在Embedding层分词后生成对应的向量矩阵,在LSTM层矩阵进入长期记忆神经网络进行训练,全连接神经网络层激活函数,最后自定义判别阈值,以二分类形式进行输出。
考虑到模型任务的特殊性,构建专有的语料库并基于该语料库构建映射字典。所有文本经过字典映射为数值索引。
从微博平台和外网平台采集相关的正负例数据并人工进行标注作为模型的训练集,其中留出部分训练数据作为验证集来验证模型在训练过程中每轮的损失值和精度,通过观察每轮的参数来判断模型训练多少轮,这样可以防止模型过拟合。将训练好的模型保存为HDF5格式,其中包含架构中每个层的权重和参数。当使用模型进行预测未知文本时,即加载HDF5文件并重新构建出模型。
2.3.2 追踪模块
基于模型预测将筛选的可疑用户加入待追踪队列,追踪模块将使用爬虫技术对这些用户资料进行收集。包括用户个人信息、关注的人、粉丝和博文。
针对微博平台的评论信息和用户主页信息,设计两种不同的爬虫方案。
1)话题下的评论信息爬取,微博平台实施了各种反爬措施,如对访问频率的监控、页面所有数据使用异步加载和使用JS封装数据请求接口等。对这三种反爬措施采用如下解决方案。
①访问频率的监控:由于评论信息爬取需要首先进行登录验证,所以微博平台会对该用户和IP进行访问监控,若频率大于一定人工使用频率,则IP甚至用户的账号会被封。出于该问题的考虑,我们使用浏览器提前进行登录,获取到浏览器中的cookie信息并封装到请求头中。以及使用代理IP的方式进行动态更换请求的IP地址。另一方面,通过sleep函数使程序更像人工访问频率。
②数据使用异步加载:微博平台的评论信息全部使用ajax异步加载,这样导致通过requests发起的请求获取到的页面数据是静态的,并非包含我们所需的数据。我们采取selenium的方式进行自动模拟人工打开浏览器进行访问。
③JS封装数据请求接口:微博页面中数据请求接口的url都封装到JS函数中,通过获取到该页面的html代码是无法取到该url。我们使用浏览器网络状态进行人工实时追踪这些请求url。
2)用户主页信息爬取,微博平台的官网网址根据智能终端的不同分为三种,即智能手机端、电脑端、非智能手机端。三端的数据是互通的,并且反爬强度顺序为电脑端〉智能手机端〉非智能手机端。为了用户主页信息爬取的稳定性,使用https://weibo.cn/网址进行爬取。针对登录验证和数据解析,采取如下设计方案。
①登录验证:采取cookie内嵌到请求头信息中的方式来完成登录验证,为了防止cookie的失效或者账户被封,我们自定义了cookie池,当某一个cookie无法验证成功时,请求头会自动从cookie池中获取cookie进行替换。
②数据解析:验证成功后,使用requests库获取包含用户数据的html代码,采用xpath来解析代码,精准获取到包含数据的标签,对于具有分页的数据,通过解析和拼接url进行多次请求获取。
2.3.3 用户嫌疑值计算和判定模块
将追踪模块收集的用户资料分为人际关系和文本信息两个方面,设计不同的打分函数量化用户在该方面的嫌疑值,并且为每个方面分配权重,进而计算用户嫌疑值。设定阈值,判断用户嫌疑值和阈值的大小,如果嫌疑值小于阈值,则将该用户加入人工判定名单,反之,则加入用户嫌疑榜单并链入知识图谱。
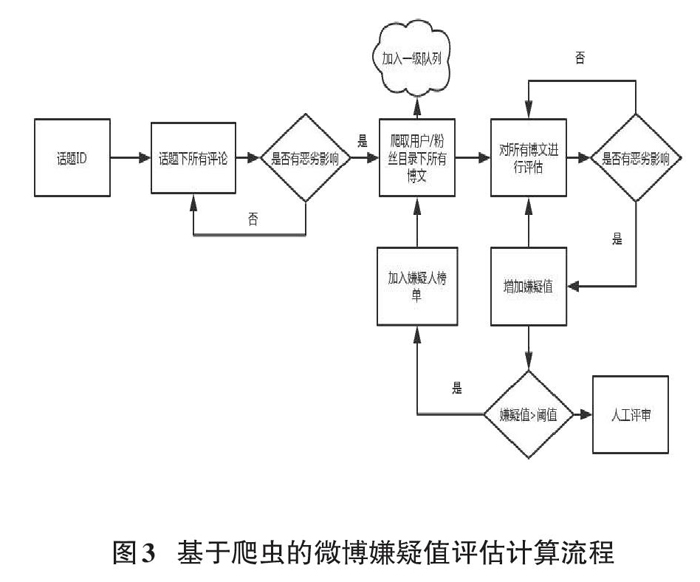
基于爬虫的微博嫌疑值评估计算流程如图3所示,如果话题下的评论存在不当言论,则爬取用户及粉丝目录下的所有博文,并把用户及粉丝加入一级队列,如果博文存在负面影响,则增加嫌疑值,并加入嫌疑人榜单,若嫌疑值大于阈值,需进行人工评审。
3 基于爬虫的社交平台舆情用户追踪系统实现
1) 建立模型,通过爬虫随机爬取微博8000余条评论作为语料库,基于该语料库和Jieba分词构建字典。爬虫爬取微博敏感主题(如国安法、中印等)下的评论,以及人工采集外网社交平台(推特、Facebook等)的负面评论。取其中的1700余条作为训练集并人工进行标记,正面评论和负面评论大约各占一半。然后基于Embedding和LSTM深度学习技术来构建分类模型。取1/5的训练集作为验证集,模型最佳验证精度达80%左右。
2) 追踪爬取,通过爬虫方式采集微博平台的评论集,加载已训练好的模型,对评论集进行批量预测,若某条评论的预测结果为负面,则该评论人会以初始嫌疑值k进入待追踪阶段。然后爬取该用户的微博主页信息,其中包含关注的人、粉丝、个人基本信息、所发的博文以及博文下的评论。爬取效果如图4所示。
3.3 嫌疑值计算,根据人际关系和文本信息两个维度分别进行打分
人际关系打分:若用户A关注的人中存在嫌疑用户B,嫌疑用户B的嫌疑值越高,那幺用户A存在嫌疑的可能性就越大。若用户A的粉丝C为嫌疑用户则无法判定用户A的嫌疑性。基于这两条常识,故人际关系打分仅考察关注的人。打分规则是基于嫌疑用户榜单,逐一排查用户A关注的所有人中是否存在榜单中。每存在一人,则用户A的嫌疑值加2,无上限。
文本信息打分:对于博文以用户A所有博文为单位组成一个批量,加载模型预测每条博文。对于博文下的评论是将所有评论添加到扩充评论集,并写入文件中,作为后续算法的输入。打分规则是若某条博文被判定为负面,则用户A的嫌疑值加5,无上限。
用户嫌疑值=用户初始嫌疑值+用户主页信息嫌疑值,其中用户初始嫌疑值从评论集或粉丝中产生,用户主页信息嫌疑值=人际关系分数×权重 + 文本信息分数×权重。
3.4 判定阶段
1)设定用户嫌疑榜单,用于记录具备一定嫌疑的用户,榜单存于数据库中。
2)设定人工评判名单,用于保存那些被算法过滤掉的可能不具备嫌疑的用户,该名单中的所有用户将由人工进行最终评判。由于机器算法存在一定错误率,该名单将有助于容忍这种错误。
3)设定嫌疑阈值t,令t=k来保证只要有一定嫌疑可能的用户就会进入到嫌疑榜单和知识图谱中。
4)当用户A的嫌疑值大于或等于t,则将用户A加入嫌疑榜单。
5)当用户A的嫌疑值大于或等于t,则将用户A的相关信息链入知识图谱。
6)对进入嫌疑榜单的用户A的所有粉丝进行逐一排查,若粉丝C已经在嫌疑榜单中,则不操作,若不在,则将粉丝C以初始嫌疑值0进入待追踪阶段进行迭代。
对微博部分数据进行模拟预测,负面评论效果如图5所示。
4 结束语
通过基于爬虫的社交平台舆情用户追踪系统的设计和实现,验证了基于需求点的可行性研究,系统全过程大部分不需要人工参与,多个目标可以同步进行检测,相互不影响。在实时热门的评论下,一旦出现不良言论即可开始追踪,对其微博博文的搜查提高精度。由此证明,借助机器在很大程度上可以节省大量的人力和时间成本。但由于短时间和人工标注,目前代码的训练集仅有1700余条(正负例约各一半),属于小样本训练。另外,负例数据难以找寻,导致训练集的数据规模难以短时间扩大,所以模型的泛化能力不强。
参考文献:
[1] 王建庆.基于深度学习的社交平台评论情感分析研究[D].青岛:青岛科技大学,2020.
[2] 蒋彭.基于深度学习的情感分类及其在舆情分析中的应用[D].南昌:南昌大学,2020.
[3] 田煜.基于语义情感分析的网络热点爬虫舆情分析系统[J].软件,2020,41(8):89-93.
[4] 刘斌.基于大数据的网络舆情分析方法研究[J].电脑知识与技术,2020,16(30):25-27.
[5] 袁志远,徐怀超,郭金顺,等.基于大数据的网络舆情分析系统设计与实现[J].西藏科技,2020(12):76-80.
【通联编辑:谢媛媛】
收稿日期:2021-09-16
作者简介:陆莉莉(1978—),女,江苏南京人,副教授,硕士,研究方向为大数据爬虫。
3445500589208



