孙红梅


摘要:协同过滤推荐是目前应用最广泛和最成功的推荐系统,但传统的协同过滤算法没有充分利用用户的行为反馈信息,忽略了时间顺序、序列顺序等有效信息,存在一些局限性。文章基于传统的协同过滤算法,结合用户交互行为信息中的时间顺序、序列顺序以及物品的流行度和用户的活跃度等信息,优化算法的推荐效果,并且在数据集MovieLens上进行验证,实验结果表明优化后的协同过滤推荐算法能有效提升推荐效果。
关键词:协同过滤;相似性度量;推荐算法
中图分类号:TP391 文献标识码:A
文章编号:1009-3044(2022)13-0088-03
1 引言
推荐系统领域的兴起和互联网的快速发展息息相关,也是互联网经济落地的主要场景之一。在推荐系统领域中,通过推荐算法从海量数据中挖掘用户的兴趣,捕捉更精确的深度信息,精准地推荐给用户,促进用户更加高效地接收信息[1-3]。推荐系统对于大数据时代具有强大且不可替代的推动作用。
在推荐领域中,应用最广泛且影响最大的应属协同过滤算法[4-6]。协同过滤算法也是推荐领域研究的热点和业界主流的应用模型。它是基于用户行为挖掘用户兴趣的算法模型,通过用户行为的反馈信息进行协同汇聚,然后从海量的数据中进行过滤得到更精准的深度兴趣捕捉,从而推荐给用户。
传统的协同过滤算法中,基于领域的协同过滤算法是最经典且轻量的算法模型。协同过滤算法的核心思想是通过用户的交互反馈行为,计算用户或者物品之间的相似性,然后根据相似性给用户推荐物品,但基于领域的协同过滤算法仍然存在一些局限性,如没有充分利用用户的行为反馈的信息,忽略了时间顺序、序列顺序等有效信息,而这些信息往往在推荐的过程中能够起到有效的作用。
因此,本文基于传统的协同过滤算法,充分利用用户交互行为信息中的时间顺序、序列顺序以及物品的流行度和用户的活跃度等信息,优化算法的推荐效果,并且在经典数据集MovieLens[7]上验证算法的有效性。
2 算法模型
2.1传统的协同过滤算法介绍
根据计算相似性的方向不同,协同过滤算法可以分为基于用户的协同过滤算法和基于物品的协同过滤算法。
基于物品的协同过滤算法(Item Collaboration Filter,ItemCF)[4,8]的推荐原理,如果用户对一个物品感兴趣,则优先推荐与该物品相似的其他物品给用户。ItemCF 算法的核心是找相似的物品。假定有两个物品分别为[i]和[j],通过交互行为信息可以得到分别与这两个物品有过交互的用户集合为[Ui]和[Uj],那幺就可以通过以下公式计算出两个物品之间的相似性:
[simi,j=Ui∩UjUiUj] [1]
其中[|Ui∩Uj|]表示与两个物品都有过交互行为的用户集合数,能够有效反映两个物品之间的相似性程度。两个物品在用户与物品的交互行为中共现的次数越高,就意味着两个物品的相似性程度越高。[|Ui||Uj|]表示对于两个用户集合数的权衡,是算法改进后对于热门物品的打压考虑。在推荐系统领域中,越是热门的物品,与用户的交互行为信息就越多,容易造成所有物品都同热门商品具有很高的相似性的错觉,因此在相似性计算的公式中考虑与物品交互的用户集合的大小,能够有效地解决这一问题,更加可靠地捕捉物品之间的相似性。越热门的物品交互的用户集合越大,因此会得到一个越小的系数,相似性的分值就会得到打压。
基于用户的协同过滤算法(User Collaboration Filter,UserCF)[9]的推荐原理,通过计算和分析找到和目标用户有同样兴趣爱好的用户集合,可以近似地认为这个集合中用户喜爱的物品目标用户也会喜欢,进而推荐给目标用户。算法的核心问题是如何找到相似的用户。假定有两个用户分别为[u]和[v],通过交互行为信息可以得到分别与这两个用户有过交互的物品集合为[Iu]和[Iv],那幺可以通过以下公式计算出两个用户之间的相似性[sim(u,v)]:
[simu,v=Iu∩IvIuIv] [2]
其中[|Iu∩Iv|]表示与这两个用户都有过交互行为的物品集合数。公式同样考虑了用户活跃度的影响,越是活跃的用户所交互的物品越多,但是物品间的相关性程度应当是越低的,因此通过[|Iu||Iv|]这一项式对用户的活跃度进行有效打压。
2.2协同过滤推荐算法的优化与实现
本文在传统的ItemCF协同过滤算法的基础上,充分利用交互信息中的时间顺序、序列顺序以及物品的流行度和用户的活跃度等信息,优化算法的推荐效果。
(1)基于ItemCF算法的优化与实现
首先,传统的ItemCF算法在计算两个物品的相似性时,没有考虑每两个物品共现时的时间顺序对于两个物品之间的相似性影响。在每个用户与物品的交互行为历史中,用户与物品的交互行为存在时间顺序上的差异。一般来说,交互时间越近,物品之间的相似性程度越大。因此,推荐算法捕捉了交互行为的时间顺序信息。假定一个用户[u]与物品[i]和[j]的交互时间分别为[ti]和[tj],那幺它们之间的时间差为[|ti-tj|]。根据时间越近相似性程度越高的特性,并且保证时序因素的值在[0, 1]范围之间,采用指数函数的形式刻画时间顺序信息。具体的公式如下:
[simi,j=u∈Ui∩Uje-α*ti-tjUiUj ] [3]
其中[u∈Ui∩Uj]表示与物品[i]和[j]都发生过交互行为的用户,在这个并集的每个用户的交互历史中都存在物品[i]和[j]的共现。ItemCF算法将这样的共现记录作为计数,来统计物品之间的共现次数表示物品之间的相似性。推荐算法考虑了物品和用户交互的时间顺序影响,吸取用户与物品之间的交互时间顺序信息进行相似性的计算。此外,[α]在这里是一个超参数,用于调整不同场景下时间顺序对于物品之间相似性的影响。
其次,本文还考虑了序列顺序信息对于推荐效果的影响。具体来说,在每个用户与物品的交互行为中,交互行为上不仅存在时间顺序上的差异,还存在序列先后的差异,而序列顺序的信息往往对推荐的效果也起到很大的作用。例如,自行车和打气筒有很强的共现关系,当一个用户购买了自行车时,他对于打气筒有很强的潜在兴趣,而当他购买了一个打气筒时,自行车未必是他潜在的购买商品。因此,本文同时考虑了推荐算法对于交互行为的序列顺序信息的捕捉。为了保证算法的轻量性,通过一个超参数[β]来控制序列顺序的信息。具体的公式如下:
[simi,j=u∈Ui∩Ujβ*e-α*ti-tjUiUj] [4]
其中,当[ti]<=[tj]时认为序列的顺序为正向,将[β]的值赋为1,否则认为序列的顺序为负向,[β]赋值为0.8。
此外,ItemCF算法对热门的物品进行了打压,但是没有考虑用户活跃度的影响。在推荐的过程中,两个物品的共现出现在不同活跃度的用户的交互历史中的价值是不同的。例如,当一个用户只购买了几件物品,其中包含了物品[i]和[j],那幺这个用户的交互行为对于计算物品[i]和[j]的相似性程度有很大的价值。而当一个用户购买过上万个物品,那幺其交互行为对于计算物品[i]和[j]的相似性程度的价值就小了很多。因此,本文同时优化了推荐算法对于用户活跃度信息的吸取。具体公式如下:
[simi,j=u∈Ui∩Ujβ*e-α*ti-tjln1+IuUiUj] [5]
其中,用户[u]的交互物品集合大小[|Iu|]表示该用户的活跃度程度。而采用对数函数的方式表示用户的活跃度信息,一方面保证不过度打压,另一方面使计算得到的数据更加平滑。
(2)基于协同过滤的推荐过程
通过步骤(1)之后能够得到物品之间的相似性分值,便可根据用户的历史交互物品推荐相似性高的物品。
在推荐的过程中同样考虑了时间因素的影响。将用户[u]最近交互的时间作为对照时间[t0],遍历用户的历史交互物品[i∈Iu],同样采用指数函数的形式刻画时间顺序信息,记为[e-α*|ti-t0|]。那幺在遍历的过程中,将当前物品的时间信息与它相关的所有物品的相似性分值加权求和得到推荐物品[j]的推荐分值[rec(j)]。具体的公式如下:
[recj=i∈Iu,j∈Iisimi,j*e-α*ti-t0] [6]
最后根据得到的推荐分值排序,给用户推荐未交互过的物品。
3 实验
3.1实验设置
3.1.1数据集介绍
本文使用推荐系统领域中的经典数据集MovieLens来验证推荐算法的效果。MovieLens数据集是由美国Minnesota大学领头创办的关于电影推荐的评级数据[7]。本文使用1M数据,包含6040个用户对于3900个电影的百万评论数据,用户对电影依照喜爱程度评1~5颗星。
3.1.2实验设置及环境
算法采用Python语言开发。在数据处理过程中,将评级数据中4星以上的数据筛出得到有效交互数据,进而计算电影之间的相似性。在预估的过程中,将用户实际最后的五次有效交互电影作为预估样本,根据本文优化的协同过滤推荐算法分别推荐10个和50个电影。然后采用NDCG(Normalized Discounted Cumulative Gain)和HR(Hits Ratio)两个指标评估推荐的效果。
此外,为了防止用户之间的行为穿越和模拟真实推荐场景,对每个用户预估时以预估样本之前的最后一次交互时间作为时间点,根据此时间点之间的数据计算电影间的相似性。因此,针对每个用户都必须计算一次相似性。为了减少计算量的同时保证实验的公平性,本文实验涉及的算法均是利用有效时间点之前的两周内的数据计算相似性,并且预估时对所有用户进行随机采样100个进行评估,保证预估的用户能够分布在整个时间跨度的范围内。
3.2实验结果
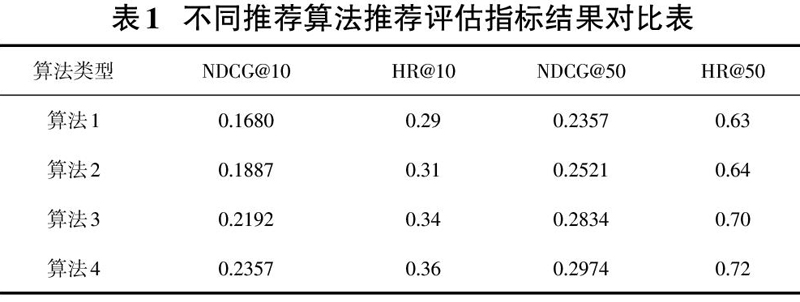
为了验证协同过滤推荐算法的优化效果,设计了四组对照实验来验证推荐过程中两个步骤的重要性和优化的推荐效果,实验设置如下:
(1)ItemCF算法计算电影间的相似性,直接根据相似性对用户未交互过的电影进行排序推荐,记为算法1。
(2)ItemCF算法计算电影间的相似性,利用本文优化后的推荐过程对用户进行推荐,记为算法2。
(3)利用本文优化的ItemCF算法计算电影间的相似性,直接根据相似性对用户进行推荐,记为算法3。
(4)利用本文优化后的ItemCF算法计算电影间的相似性,并且利用本文优化后的推荐过程对用户进行推荐,记为算法4。
此外,实验中涉及的优化算法的超参数[α均]设置为[0.000015],而[β]根据条件设置为1或0.8。本文未针对参数进行网格搜索等方式优化算法的效果,理论上参数调整后仍然有一定的优化空间,因此本文涉及的对照实验均采用统一参数设置保证实验的公平性。
表1详细展示了对照实验在推荐结果上的评估效果。NDCG@10和HR@10是针对算法推荐10个电影的结果评估,而NDCG@50和HR@50则是针对算法推荐50个电影的结果评估。通过对比算法1和算法2的各项指标,可以发现考虑时间因素的推荐过程,能够一定程度上提升推荐效果。而对比算法1和算法3的各项指标,优化后的ItemCF算法能够捕捉到更加准确的相似性信息,进而明显提升推荐的效果。最后,对比算法4和其他实验的各项指标,可以发现优化后的ItemCF协同过滤推荐算法能够在传统的协同过滤算法ItemCF的基础上显着提升推荐的效果。可见,本文提出的基于ItemCF协同过滤的推荐算法的两个步骤对于推荐效果都有一定明显的提升作用,并且两个步骤之间相得益彰,从不同角度优化了推荐的过程。
4 总结
本文通过研究推荐领域的协同过滤算法,在传统的ItemCF算法的基础上充分利用用户交互行为中的时间顺序、序列顺序以及物品的流行度和用户的活跃度等信息,对协同过滤推荐算法进行优化,从两个步骤上优化了推荐的过程和效果。同时,优化后的协同过滤推荐算法继承了协同过滤的轻量性、可解释性等优点。
参考文献:
[1] 许海玲,吴潇,李晓东,等.互联网推荐系统比较研究[J].软件学报,2009,20(2):350-362.
[2] Wang J Z,Huang P P,Zhao H,et al.Billion-scale commodity embedding for E-commerce recommendation in alibaba[C]// Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining,2018:839-848.
[3] 刘建国,周涛,汪秉宏.个性化推荐系统的研究进展[J].自然科学进展,2009,19(1):1-15.
[4] Linden G,Smith B,York J.Amazon.com recommendations:item-to-item collaborative filtering[J].IEEE Internet Computing,2003,7(1):76-80.
[5] 邓爱林,朱扬勇,施伯乐.基于项目评分预测的协同过滤推荐算法[J].软件学报,2003,14(9):1621-1628.
[6] 马宏伟,张光卫,李鹏.协同过滤推荐算法综述[J].小型微型计算机系统,2009,30(7):1282-1288.
[7] Harper F M,Konstan J A.The MovieLens datasets[J].ACM Transactions on Interactive Intelligent Systems,2016,5(4):1-19.
[8] Karypis G.Evaluation of item-based top-N recommendation algorithms[C]//Proceedings of the tenth international conference on Information and knowledge management.2001:247-254.
[9] 荣辉桂,火生旭,胡春华,等.基于用户相似度的协同过滤推荐算法[J].通信学报,2014,35(2):16-24.
【通联编辑:代影】



