孟度金 唐阳山


关键词:交通标志;目标检测;联邦学习;YOLOv5;FATE
中图分类号:G391.4 文献标识码:A
文章编号:1009-3044(2023)21-0010-05
0 引言
发展至今,将交通系统与物联网、分布式框架以及人工智能等技术相结合以保证人们日常出行的安全和高效。由此生成的智能驾驶正是其中极为重要的一环。智能驾驶依靠的即是对数据的快速处理和高效的运算,但在网络环境良好且车辆停驶的情况下,也会造成巨大的算力浪费。如何有效地利用起车载设备的计算资源,避免其过多的浪费。同时为用户提供更多的数据保护,是当前许多汽车厂商需要面对的问题。交通标志是交通领域必不可少的存在。其中主标志和辅助标志更是相辅相成。交通标志的检测与识别在智能驾驶的过程中承担着极大的作用[1]。随着近年来深度学习的兴起和发展,交通标志的识别也由传统的手动设置特征转向了神经网络对特征的自动学习。但基于深度学习的交通标志识别大多针对的是常见的主标志中的警告标志、禁令标志和指示标志,而在辅助交通标志的检测与识别则缺乏关注与应用。并且在不同的地区,其交通标志的种类、数量、类型等各有不同,而常见的交通标志识别只能针对特定的拥有大量数据的交通标志做出识别。与此同时在雾霾等光线受影响的天气时,大多数模型因缺少训练数据而鲁棒性较差。由此在车载设备进行在线学习且不经过二次数据传输的情况下,将车辆本身获取的数据进行灵活的运用,这对厂商和用户本身具有重大的意义。
为解决以上问题,本文提出一种基于联邦学习[2]的交通标志识别网络。该网络的主要创新为调整联邦学习框架部分,在此基础上创建并改进框架内的模型模块、训练模块,缩短其每轮次的训练时间,同时减少模型的参数结构并提高其精度,使其整体更加轻量化,增强其整体的泛化性能。
1 相关工作
1.1 交通标志识别
关于交通标志的识别可以大概概括为三类:传统方法、机器学习、深度学习[3]。在传统方法中,主要是使用颜色空间、颜色阈值分割、霍尔变换、类特征检测、模板匹配等方法来直接进行交通标志的识别。算法简单、鲁棒性较强、识别条件明确。不过对应的条件限制性较强,需要手动定义特征,调整参数,并且可能出现目标无法识别的现象。使用机器学习来进行交通标志的识别,大多是在传统方法的基础上获取特定的特征后使用支持向量机、随机森林、提升树等算法进行分类。虽然对分类过程有更快的速度,泛化能力也有所提高。但模型在有噪点的情况下进行检测识别时依然误检较多。基于深度学习的模型不需要手动定义特征,减少了不同条件下对模型的限制。其方法模型主要包括R-CNN、Fast R-CNN、Faster RCNN、SSD、YOLO系列等[4-8]。根据其模型的分类和回归可将其划分为单阶段和双阶段。单阶段的YOLO 系列算法其超参数量小于将模型划分为分类和回归两部分的Fast R-CNN、Faster R-CNN等双阶段算法的超参数量。深度学习网络自动提取特征,针对性训练精确率高。但随着网络层数的增加,参数量较大,需减少冗余的参数。
1.2 联邦学习
联邦学习(Federated Learning,FL) 是由谷歌研究院提出基于保护用户数据的一种人工智能解决方案[9]。联邦学习在客户端与服务器相关联架构中按照其特性可划分为横向、纵向以及迁移。支持联邦学习的框架有多种,本文选用受众较多的FATE框架[10]作为基础框架进行搭建。
2020年,由Liu等人[11]提出的联邦视觉,采用横向联邦学习与YOLOv3相结合的策略,在市场上得到了广泛的应用。用户使用联邦视觉图像注释工具来标记他们的本地训练数据集,并进行训练。本地模型收敛后,用户则可以通过客户端模块以一种安全加密的方式将本地模型参数传输到中心服务端。在每一轮学习结束后,会为模型计算一个更新的全局权重,从而达到全局更新。
2021年,学者石佳[12]则针对目标检测在智能驾驶中的一种应用场景,提出基于联邦学习的目标检测算法。其算法模型是将联邦学习与Faster R-CNN相结合也就是在目标检测双阶段法的基础上进行了实现和改进并取得了较高的精确度,提高了平均检测时间。但由于参数量过大,对算力要求较高,使用轻量型网络更有助于车载终端的实时检测。
2022年,学者张斌则提出了基于车辆网中分心驾驶行为识别的联邦学习方法[13],以MobileNetV2作为分心驾驶行为识别模型,并验证了将联邦学习应用于分心驾驶行为识别领域的可行性。
2 算法模型
本文使用FATE联邦学习框架[14]进行算法的编写和测试。其FATE的框架主要包括四大部分,分别是云平台、可视化平台、流动平台、服务平台。在FATE 的调度中主要使用有向无环图和多方任务调度器进行任务层的调度。在FATE-1.10.0版本中,FATE制定的一个更高级的接口pipeline来生成指定的json文件进行任务调度。FATE的核心是FederatedML,即联邦和隐私保护机器学习的算法库。通过该算法库进行定义数据模块、训练模块、损失模块、模型模块等四部分。
2.1 数据模块
在我国北方大部分地区,尤其是气温逐渐降低时,雾霾这种天气状况几乎成为一种常态。雾霾会降低空气的透明度,使得交通标志在较远距离难以辨认。此外,雾霾也会使得光线散射,从而影响摄像机对于交通标志的识别精度[15]。这些因素都会使得交通标志识别变得更加困难。主流的解决办法是通过算法去雾,但是更多的问题是没有足够的数据提供给模型进行优化。而大多数学者是通过基于光学模型以图像中心点向四周发散或直接在图像的三通道上附加值等方法来模拟雾霾从而获取数据集。本文的框架模型除去可以在真实世界获取数据集外,还加入基于深度的雾霾天气图像生成算法。并考虑到在实际环境中的应用价值,以及车载设备所能提供的条件要求。深度图像主要基于图像自监督深度估计模型[16]通过单目视觉图像来生成。效果对比图如图1 所示。
2.2 训练模块
对于训练模块,它可以在每轮中选择n 个客户端,计算这些客户端持有的模型损失梯度。并指定每m轮进行模型参数安全聚合来保障梯度数据的安全性。在模型经过聚合后通过服务端来将全局模型下发到各个客户端。其算法伪代码如算法1所示。
2.3 模型模块
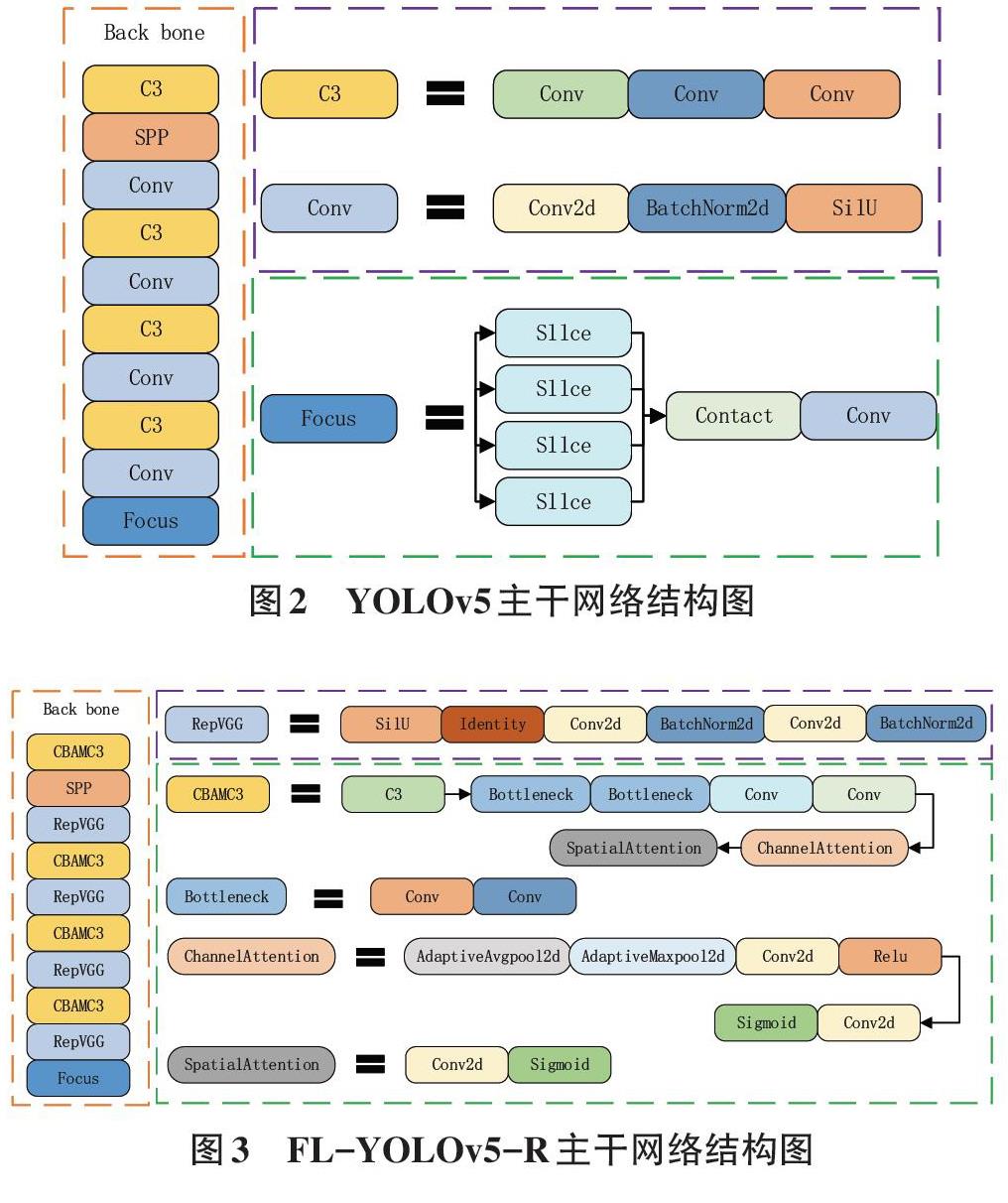
该网络是基于联邦学习与YOLOv5模型,所以将该模型命名为FL-YOLOv5。YOLO的实现是基于卷积神经网络的回归模型。YOLO将输入图像划分成网格区域,然后对其进行预测。在多目标检测中通过聚类与NMS来调整输出结果。损失函数是由坐标、置信度和类别等三方面组成。其原始YOLOv5模型包含391层,21 222 087个参数。YOLOv5的主要结构是由CSPDarknet架构和YOLOv3的FPN特征提取器组成。CSPDarknet是一种卷积神经网络,用于提取特征。而FPN特征提取器则是一种可实现多尺度目标检测的算法。其模型主干结构如图2所示。
FL-YOLOv5的模型模块主要基于YOLOv5模型。
如果想要模型轻量化,必不可免需要缩减其参数量。
由此,使用RepVGG网络[17]替换YOLOv5骨干网络结构中的Conv模块。RepVGG可以解决传统卷积网络参数使用不充分、重复计算和计算性能低等问题。可以在极大保留特征的基础上尽可能缩减计算量。并在其骨干网络的C3模块加入CBAM注意力机制[18],提高每个网格通道的权重,使得网络的特征表示更加有效,提高模型的准确性和鲁棒性。本文将该模型命名为FL-YOLOv5-R,其主干网络结构图如图3所示。在模型改进的过程中,将RepVGG模块与CBAM注意力机制全部替换进YOLOv5,即YOLOv5+RepVGG+CBAM,获得的模型层数为415层,参数量为5 574 639。虽然层数有所增加,但其参数量相对于YOLOv5缩减了73.7%。
2.4 损失模块
在目标检测YOLO系列模型中的损失函数,通常是由回归损失、分类损失、置信度损失这三部分组成。在本文的YOLOv5模型中,分类损失和置信度损失均是由二进制交叉熵损失函数来构成,默认的回归损失是LOSSCIOU。
3 实验与分析
本节首先描述数据集、实验环境和评价指标,接着以YOLOv5为基准与改进后的YOLOv5模型进行对比。同时对FL-YOLOv5、FL-YOLOv5-R在不同的环境下实施评估,最后依据上述实验结果进行总结。
3.1 数据集介绍
本文的数据集为TT100K-r主要包含自制的辅助标志数据集以及从开源数据集TT100K中筛取的主标志数据集。TT100K包含的标志牌类别一共有200多种,但其各类别数量分配不均衡,本文选取的训练数据是各类别实例数大于100的标志,其中警告标志4 种,禁令标志30种,指示标志8种。辅助标志数据集,是由课题组在行车过程中进行街拍自制。由于其辅助交通标志的多样性,且辅助标志数量较少,自制辅助标志数据集主要划分为包含文字的辅助标志、包含数字的辅助标志、包含图像的辅助标志以及混合辅助标志。训练集的数据总量为7 398张,测试集的数据总量为1 087张,验证集的数据总量为2 177张。
3.2 实验环境与指标
相对于车载计算机,其算力相当于普通电脑的硬件水平,能够在消耗极低的情况下达到较高的运算水平。由于资源限制,本文在进行模型改进时使用的硬件条件为12核vCPU,40G内存,显卡为RTX 2080Ti。在进行联邦学习时使用的硬件条件为阿里云计算型c5系列12核vCPU,24GB运行内存。基于上述情况,本文实验所用到的软件条件为操作系统CentOS7.9 64 位、联邦框架FATE-1.10.0、Python3.8.13、Py?Torch1.13.1。评价指标分别选用精确率(Precision) 、召回率(Recall) 、平均精度(mAP) 以及每秒帧数(FPS) 。
3.3 实验结果分析
1) 模型改进实验本文的实验对比对象主要是以YOLOv5基准与YOLOv5+RepVGG+CBAM 进行对比。这里设置批次大小为32,工作线程为12。
CBAM有助于模型更好地捕捉特征和注意到关键的空间信息,从而提高了模型的泛化能力。结合RepVGG这种高度可重复使用和可训练性的结构,使得该组合模型可以更好地适应各种任务和场景。从图4 中可以轻而易举地观察到YOLOv5+RepVGG+CBAM的mAP相比于YOLOv5模型具有更快的提升速度。
同时为对比各个模块的重要程度,本文进行了消融实验,结果如表1 所示。在替换其卷积层为RepVGG模块后,模型在召回率上虽然相比较低,但其FPS值是可以达到四种模型的最高值。如果只在C3 模块中加入CBAM模块,虽然mAP值有所提升,但实时性较差。综合对比,YOLOv5+RepVGG+CBAM具有最高的性价比,mAP值比基准高了约3%。
2) 联邦学习实验
FL-YOLOv5 与FL-YOLOv5-R 对比在联邦学习条件下模型的性能。在进行联邦学习时,本文设定客户端代号为9999、9998、9997,服务器端代号为10000,聚合轮次T 为1或5。其客户端数据为随机从数据集抽取200至300张图片数据。由于设备限制,批次大小与工作线程均设置为2。训练的可视化界面如图5 所示。
评估结果如图6所示,T 为1或5时,进行50轮的联邦训练后,在mAP这项指标中FL-YOLOv5-R均比FL-YOLOv5高了9%。其精确率和召回率在同等条件下,FL-YOLOv5-R均优于FL-YOLOv5。T 为1时,其FL-YOLOv5平均每1轮模型训练和聚合的时间之和为135.04分钟,占用内存为162MB;FL-YOLOv5-R为68.15分钟,占用内存为43.2MB。
4 结论
在FATE框架上开发的交通标志识别模型具有较高的现实意义。将多个设备或节点上的数据和计算资源共享,不仅避免了计算资源的浪费,而且极大地提高了模型的效率。替换YOLOv5的主干网络后,其模型大小得到缩减的同时其精确率与训练速度均有所提升。但在进行实验的过程中,由于使用的是同一种设备。所以,如何在不同设备上进行训练和识别以及模型的融合是接下来需要做的重点研究工作。



