左雨露,吴 宇,杨锦鹏,赵梦梦
(惠州市中大惠亚医院心血管内科,广东 惠州 516081)
据《中国心血管健康与疾病报告2021》显示,2019 年我国农村、城市心血管病分别占死因的46.74%和44.26%。每5 例死亡中就有2 例死于心血管病。推算心血管病现患人数3.3 亿,其中冠心病1139 万。减少心血管疾病的发病率及死亡率重在预防,预防的关键在于找到合适的干预靶点。既往研究显示,血脂代谢异常及脂质沉积为冠状动脉粥样硬化的启动因素。改善血脂代谢异常为预防动脉粥样硬化的重要措施。目前临床常检验的血脂指标有总胆固醇(TC)、低密度脂蛋白胆固醇(LDL-C)、高密度脂蛋白胆固醇(HDL-C)、载脂蛋白B(ApoB)、甘油三酯(TG)、脂蛋白a[Lp(a)]等。LDL-C 为转运至血管壁的胆固醇,是脂质谱中致动脉粥样硬化的主要因素,而HDL-C 为逆向转运的胆固醇,对心血管起保护作用,非高密度脂蛋白胆固醇(N-HDL-C)为TC-HDL-C,常作为控制心血管风险的备选干预靶点。ApoB 是乳糜微粒(CM)、极低密度脂蛋白(VLDL)、LDL、Lp(a)的载脂蛋白之一,每一个CM、VLDL、LDL、Lp(a)颗粒中均含有1 分子Apo B。血液ApoB 含量代表着所有致动脉粥样硬化颗粒含量。目前使用的血脂数据种类繁多,给临床工作带来诸多不便。本研究运用特征工程的思想,构建可解释的胆固醇指数,以全面的反映胆固醇对冠状动脉粥样硬化的影响,并探讨运用这一整合了所有血脂数据的单一指标来预测严重冠状动脉粥样硬化的合理性,现报道如下。
1 资料与方法
1.1 一般资料 收集2021 年6 月-2022 年6 月惠州市中大惠亚医院收治的68 例28~82 岁冠状动脉粥样硬化患者,排除既往行PCI、CABG 及外周动脉支架植入术患者,排除既往曾长期应用他汀类药物患者,排除肝功能损害、胆汁淤积、慢性肾脏病CKD3期以上、甲状腺功能异常等疾病患者,排除合并严重全身性疾病患者,排除终末期疾病患者。收集患者血 脂谱中ApoB、N-HDL-C、LDL-C、HDL-C、TC、TG、Lp(a)数据。查看患者冠脉造影结果,采用改良的Gensini 积分[1]方法由2 人共同计算患者Gensini积分。
1.2 方法 通过随机森林模型分析患者血脂谱对冠状动脉粥样硬化严重程度的预测价值。构建胆固醇指数,再次通过随机森林模型,分析加入胆固醇指数后血脂谱对严重冠状动脉粥样硬化的预测价值。
1.3 观察指标 运用随机森林模型绘制ROC 曲线及计算AUC 面积、f1 值、精准度、召回率、准确率,分析血脂谱对冠状动脉粥样硬化严重程度的预测价值。血脂谱为采集空腹静脉血,应用雅培16000 生化分析仪运用直接法检测所得。冠状动脉Gensini 积分为分析患者冠脉造影结果,采用改良的Gensini 积分方法计算。
1.4 统计学方法 采用Python 3.10、sklearn 工具包、SPSS 20.0 软件进行数据分析。计量资料以(±s)表示;运用随机森林模型,绘制ROC 曲线,计算AUC、f1 值、精准度、召回率、准确率,分析血脂谱对严重冠状动脉粥样硬化的预测价值。P<0.05 表示差异有统计学意义。
2 结果
2.1 一般资料 68 例患者中男48 例,女20 例,平均年龄为(57.96±11.33)岁,TC 均值(4.94±1.11)mmol/L,LDL-C 均值(2.77±0.87)mmol/L,HDL-C 均值(1.07±0.27)mmol/L,N-HDL-C 均值(3.88±1.03)mmol/L,ApoB 均值(0.96±0.21)mg/L,TG 均值(1.76±0.87)mmol/L,Lp(a)均值(294.40±272.94)mg/L,Gensini 积分均值(23.47±26.38)分。采用Python split函数将病例随机分为训练集和测试集,75%为训练集,共51 例,25%为测试集,共17 例。训练集和测试集的年龄、性别、严重冠状动脉粥样例数、TG、Lp(a)、TC、LDL-C、HDL-C、N-HDL-C、ApoB、胆固醇指数比较,差异无统计学意义(P>0.05),见表1。
表1 训练集和测试集一般资料比较(±s,n)

表1 训练集和测试集一般资料比较(±s,n)
2.2 原始血脂谱对严重冠状动脉粥样硬化的预测价值 运用随机森林模型,绘制ROC 曲线,计算AUC面积,将Gensini 积分超过均值23.50 定义为严重冠状动脉病变。根据原始血脂谱数据,随机森林模型预测严重冠状动脉粥样硬化病变的AUC 为0.64(95%CI:0.41~0.80),见图1。
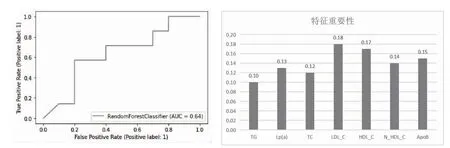
图1 原始血脂谱ROC 曲线及特征重要性
2.3 构建新特征-胆固醇指数 特征工程为机器学习的数据预处理过程,构建新特征为特征工程的重要内容。此研究新构建的特征胆固醇指数可表示为HDL-C。其解释为:胆固醇的致动脉粥样硬化作用为含ApoB 脂蛋白颗粒数与可致动脉粥样硬化胆固醇总量的共同作用,用(ApoB×(LDL-C+a×(NHDL-C-LDL-C)))表示,而且与HDL-C 呈负相关,用(ApoB×(LDL-C+a×(N-HDL-C-LDL-C)))/HDL-C 表示,为消除单位,分子取平方根。故最终公式为其中a×(N-HDL-C-LDL-C) 表示N-HDL-C 中除LDL-C 外可致冠状动脉动脉粥样硬化的胆固醇总量。N-HDL-C 中除低密度脂蛋白胆固醇外,还包括CM 残余物、中间密度脂蛋白(IDL)等所含胆固醇,上述颗粒只有直径小于70 nm 才有致动脉粥样硬化作用,所以N-HDL-C-LDL-C 的系数a 应小于1。通过分析a 取小于1 的不同值时,随机森林模型预测严重冠状动脉粥样硬化的AUC,发现当a=0.1时,AUC 达到最大值,见图2,故取系数a=0.1,胆固醇指数=HDL-C。可以看出,不论系数a 取小于1 的何值,新特征都可提升随机森林模型的预测价值。
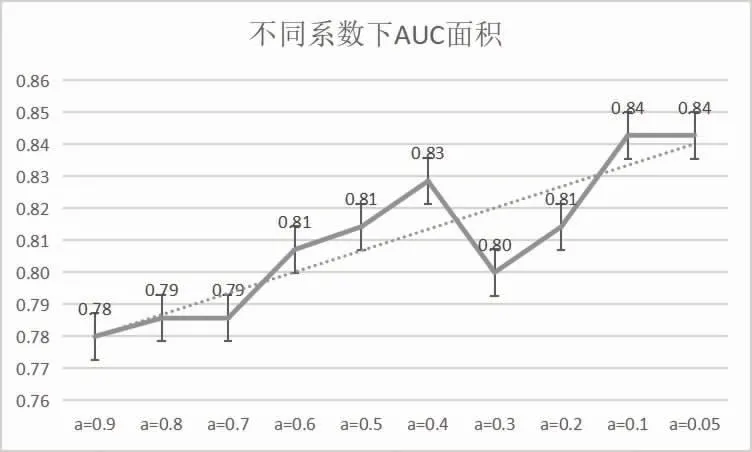
图2 a 取不同值时的AUC 面积

图3 胆固醇指数ROC 曲线及特征重要性

表2 使用新特征胆固醇指数后评价指标对比
3 讨论
血脂异常是动脉粥样硬化性疾病发生的启动因素。血脂是血浆中的胆固醇、甘油三酯和类脂等的总称,血脂与特殊的蛋白质即载脂蛋白结合形成脂蛋白溶于血液,被运输至组织进行代谢。目前临床常用血脂指标有TC、N-HDL-C、LDL-C、ApoB、HDL-C、TG、Lp(a)等。目前不同血脂指南中涉及的血脂指标种类繁多,2020 年中国心血管病一级预防指南中推荐LDL-C 作为评估ASCVD 风险的指标和治疗靶点,同时也建议将N-HDL-C、TC、HDL-C等控制到目标值[2]。中国血脂管理指南(2023 年)的推荐靶目标与之类似[3]。而国外指南如2019ESC/EAS 血脂指南、2021ESC 心血管病预防临床实践指南、2021 美国脂质协会关于血脂测量在心血管疾病中运用指南不仅将LDL-C 作为血脂控制的首选靶目标,对TC、HDL-C、N-HDL-C、ApoB、TG 都有相应的诊治意见提出[4-6]。多样的血脂指标给临床工作带来不便,本研究致力于将指南推荐的各种血脂指标整合为单一指标。脂蛋白依密度增加为序可分为CM(80~100 nm)、VLDL(30~80 nm)、IDL(25~40 nm)、LDL(20~25 nm)和HDL(8~13 nm)[4]。在血液中,CM残余物和IDL(也称为VLDL 残余物)由CM 和VLDL 水解转化而来。绝大部分CM 残余物和少部分VLDL 残余物被肝脏清除,大部分VLDL 残余物进一步转化为LDL。LDL-C 是主要致动脉粥样硬化的胆固醇,未被清除的CM 残余物也可致动脉粥样硬化。上述脂蛋白所含胆固醇包含所有致动脉粥样硬化性脂蛋白胆固醇。HDL 在肝脏和肠道中合成,脂蛋白为ApoA,不含ApoB[7]。HDL 是血浆中颗粒密度最大的一种脂蛋白,具有抗动脉粥样硬化作用,可将胆固醇从肝外组织逆向转运至肝脏代谢成胆汁酸等,后通过胆汁排出体外,现认为其与ASCVD 风险呈负相关。
目前研究表明[8],脂蛋白的致动脉粥样硬化作用与脂蛋白颗粒密切相关。同时含ApoB 脂蛋白颗粒大小也是滞留动脉壁内的重要因素,所有直径小于70 nm 的含ApoB 脂蛋白颗粒[CM、VLDL、LDL、IDL、Lp(a)]都可以穿透动脉内膜进而沉积[9]。显然,胆固醇的致动脉粥样硬化作用既与含脂蛋白颗粒数量相关,也和脂蛋白颗粒大小相关,当然也和胆固醇总量相关。降脂治疗应同时关注到血脂颗粒密度[10]。因所有可致动脉粥样硬化脂蛋白都含有一分子ApoB,所以ApoB 的量可表示所有含ApoB 颗粒数,N-HDL-C 包含所有可能致动脉粥样硬化的胆固醇总量,其致动脉粥样硬化胆固醇为所有LDL-C 和部分直径小于70 nm 的CM 残余物、IDL 中所含胆固醇。故ApoB、LDL-C、N-HDL-C 三种指标在致动脉粥样硬化当中应该是相辅相成的。而HDL-C 与动脉粥样硬化呈负相关。研究认为[11],现有血脂谱包含的TG、TC、LDL-C,N-HDL-C 和HDL-C 这5 个数据在生理上紧密相连,在统计分析时不应被视为独立的变量。现有研究表明,HDL 的代表ApoA1 和致动脉粥样硬化脂蛋白的代表ApoB 的比值和冠状动脉粥样硬化严重程度相关[12],同时与冠状动脉粥样硬化斑块的不稳定性相关[13]。但上述研究未将胆固醇等数据纳入整体指标。整合血脂谱对临床工作有很大的意义,但在国内外数据库中尚未查到有关于整合血脂谱的文献。如能找到一种指标将血脂谱彻底整合,可为动脉粥样硬化性疾病的防治带来新的进展。
特征工程正是机器学习中研究特征转换的重要步骤,是机器学习不可或缺的一环,其用一系列工程化的方式从原始数据中筛选出更好的数据特征,以提升模型的训练效果。新特征不是随意生成的一组新数据,其的可解释性非常重要。新特征的构建既可以运用PolynomialFeatures、Featuretools 等工具构建,也可发挥人脑的创造力构建。在本研究中遵循一定运算规律通过工具批量生成的新特征其可解释性都不强。所以选择通过研究胆固醇的代谢特点及在动脉动脉粥样硬化中的作用来生成新特征。
综上所述,新特征胆固醇指数可有效的整合胆固醇数据,提升随机森林模型对严重冠状动脉粥样硬化的预测价值。本研究为运用单一指标代替血脂谱来预测冠状动脉粥样硬化的新尝试。但本研究存在一些不足:①样本量不够;②没有剔除其它混杂因素;③没有进行前瞻性队列研究。希望能有大型的设计严谨的前瞻性队列研究及更加专业的统计分析来验证这一构想。



