金育婵
浙江工商大学,浙江杭州 310018
1 概述
1.1 课题的研究背景
现代计算机科学技术发展的历史,同时也是数据和信息加工手段不断更新和改善的历史。随着计算机硬件和软件不断的发展,尤其是数据库技术与应用的广泛推广,摆在人们面前的问题出现了,这些急剧膨胀的信息数据,如何有效利用这一丰富数据海洋的宝藏为人类服务,也已成为广大信息技术工作者所重点关注的焦点之一。
传统的收集数据技术可以在一定程度上对收集来的数据信息进行统计分析,能够获得一定的数据价值,这种传统的收集数据技术具有一定的效果,但当这种方法在面对海量的数据并从中进行数据分析时,却没有一个比较好的解决方案。无论是数据的统计、数据的查询、数据的报表等这些传统的数据处理方式都是对收集来的数据简单的进行处理,而不能对这些数据内部所隐含的价值信息进行有效的提取和分析。在这些大量数据的背后隐藏了很多具有决策意义的信息,如何得到这些能够为我们提供决策依据的数据依据已经成为当前的一个热点的研究方向。
1.2 研究目的和意义
数据挖掘技术是面向应用型的。目前,在很多重要的领域,数据挖掘都可以发挥积极促进的作用,尤其是在如保险、交通、零售、银行、电信等商业应用领域。数据挖掘能够帮助用户解决许多典型的商业性的问题,其中包括:数据库营销、客户群体划分、背景分析、交叉销售等市场分析行为,以及客户流失性分析、客户信用评分、欺诈发现等等。
数据挖掘技术已经广泛的在企业市场的营销中得到了应用,它以市场营销学的市场细分原理为基础,通过对涉及到消费者消费行为的信息进行收集、加工和处理,得出结论以确定目标消费者地兴趣、消费倾向、习惯以及消费需求,从而能够推出目标消费者下一步的消费方向,然后以得出来的结论为基础,对目标消费者和消费群体进行定向的营销,这与传统的盲目营销的方式相比,可以在很大程度上节省因营销而产生的开支,能够提高营销的成功率,从而可以为企业带来更大的利润,也能够帮助企业树立起好的口碑。
2 数据挖掘技术的理论基础
2.1 数据挖掘技术概述
数据挖掘的定义是能够从大量、有噪声、模糊、随机、不完全、实际应用数据中提取出隐含在其中的,又不为人们所知的,同时具有潜在价值的知识和信息的过程,又被称为从数据库中的知识发现。数据挖掘不同于传统的数据分析,二者有着本质的区别,数据挖掘是在没有明确假设的前提下去挖掘信息、发现知识。通过挖掘所得到的信息应该具有未知、有效和实用等3个特征。整个KDD通常会有若干个挖掘的步骤组成,通常,数据挖掘是其中最重要的一个步骤。
通常情况来讲,数据挖掘与知识发现这两个概念很容易被人们所混淆,其主要原因是它们有相似性以及共同点,并且究其表面信息来讲,似乎如出一辙。但是就其实质来讲,两者是有显着不同的[1]。
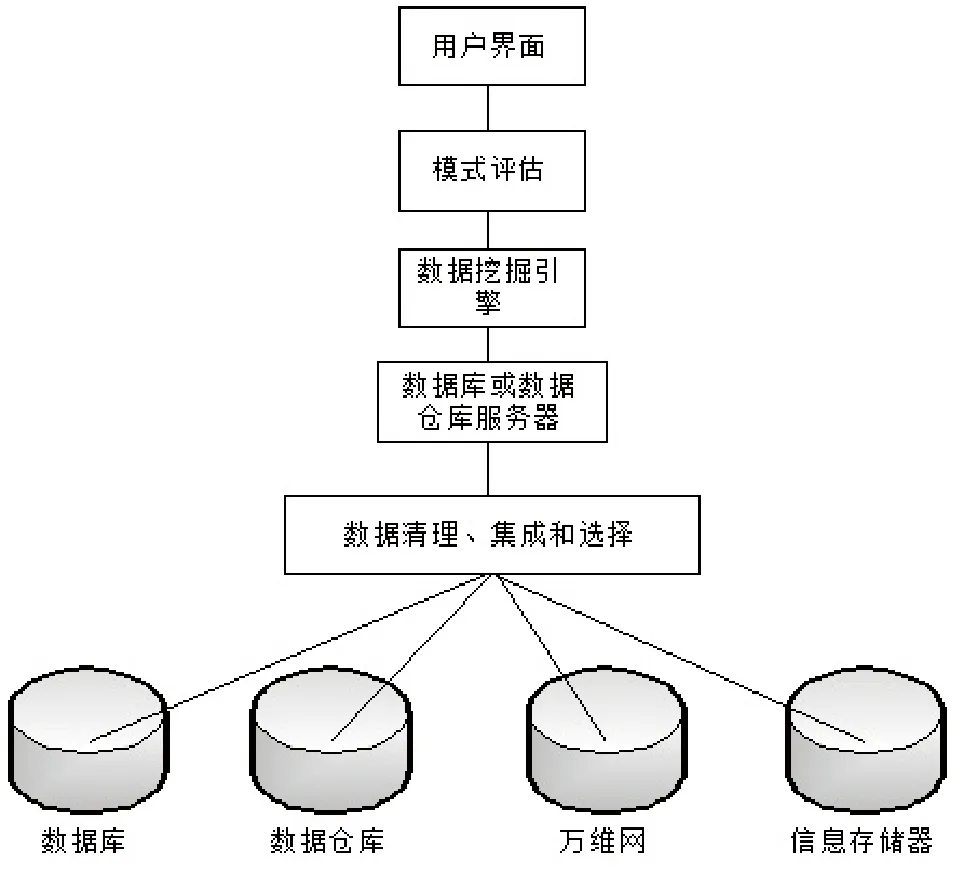
图1 数据挖掘技术结构图
2.2 数据挖掘的任务
数据挖掘的任务主要是关联分析、聚类分析、分类、预测、偏差分析和时序模式。
2.2.1 关联分析
关联规则挖掘是由2个或2个以上变量来取值的。这些变量之间假如存在着某种关系,就可以称这些变量之间相互关联。数据的关联在数据库中可以把分为简单、时序和因果的关联,同时也是目前对数据关联的一个热门的研究方向。
2.2.2 聚类分析
聚类分析就是把数据按其相似性进行分类,分为不同的类别,同一类别中的数据是相似的,不同类中的数据是不相同的。通过聚类分析我们可以发现数据的分布模式,通过数据的分布模式找出可能的数据属性之间的关系。
2.2.3 分类
分类就是在数据的分析过程中找到一个分类的概念,然后对这个分类的概念进行详细的概述,不同的分类代表不同类别数据的信息,并用对这种分类的详细定义来构造相应的模型,这种构造的模型一般用决策树的模式或者规则模式进行详细的描述。
2.2.4 预测分析
预测就是希望通过对数据的系统分析,以找到数据变化的趋势和发展的规律,并依照这种趋势和发展的规律建立对应的数学模型,然后用这种数学模型对数据的未来走势和发展进行对应的预测。对预测结果关心的是预测的准确度,这个准确度通常可以用预测的方差进行度量。
2.2.5 偏差分析
在对偏差的分析过程中能够用到很多的知识,而数据库中的数据多多少少有着异常的情况,通过对数据使用偏差分析来发现数据库中数据存在的异常状况,这对对于数据挖掘来说是非常重要的。
2.2.6 时序模式
时序模式是指通过时间序列的方法来找出的发生概率比较高的数据模式。这种数据模式与回归模式是一样的,也就是通过使用己知的数据来对数据未来的值进行预测。
2.3 数据挖掘的方法
数据挖掘的方法包括:神经网络方法、统计分析方法、模糊集方法、遗传算法、决策树方法、覆盖正例排斥反例方法等等。
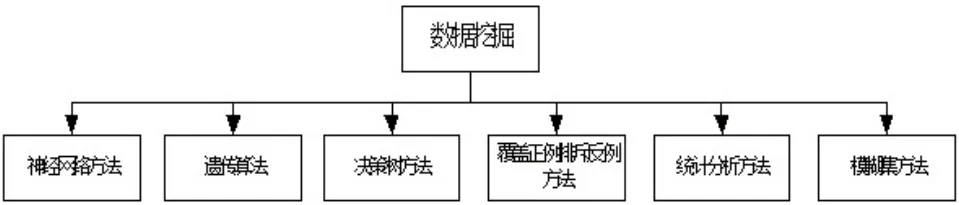
图2 数据挖掘的方法
2.4 数据挖掘的对象和流程
根据信息存储格式,用于挖掘的对象有关系数据库、文本数据源、多媒体数据库、空间数据库、时态数据库、面向对象数据库、数据仓库、异质数据库以及Internet等。
数据挖掘的流程包括:定义问题、数据准备、数据挖掘、结果分析和知识运用等。如下图所示:
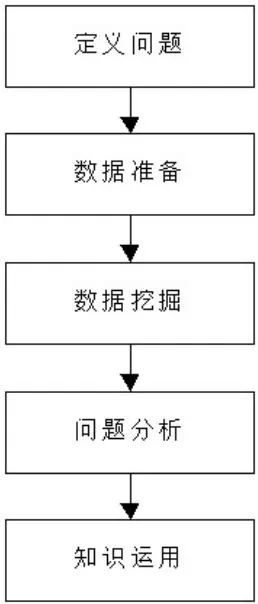
图3 数据挖掘流程图
2.5 数据挖掘的应用
数据挖掘在各领域的应用还是比较广泛的,只要该产业的数据具有分析价值并且需要利用数据仓库和数据库,皆可利用数据挖掘工具来进行有目的的挖掘分析与评估。通常情况来讲,较为常见的数据挖掘应用多发生在制造业、零售业、财务金融保险、直效行销界、通讯业以及医疗服务等。
3 关联规则的理论基础和算法研究
3.1 关联规则概述
如果假设I是项的集合。那幺给定一个交易数据库,交易数据库中每个事务是I的一个非空子集,即,每一个交易都与一个唯一的标识符TID对应。关联规则在D中的支持度是D中事务同时包含X、Y的百分比,即概率;置信度是包含X的事务中同时又包含Y的百分比,即条件概率。关联规则是有趣的,如果满足最小支持度阈值和最小置信度阈值。这些阈值是根据挖掘需要人为设定。
关联规则的数据挖掘过程大体的可以分成2个过程:
1)首先从数据资料的集合中找出所有相关的高频数据项目组;
2)接下来对这些高频数据项目组生成相应的关联规则。
3.2 Apriori算法的基本思想
Apriori算法是一种基于数据挖掘的布尔关联规则频繁项集算法,这种算法具有一定的学术界影响力。这种算法首先需要找出所有的与数据相关联的频集,频集中包含的项集出现的频率需要和事先定义的最小支持度至少保持一样。接下来由频集产生相应的数据的强关联规则,这些数据的强关联规则需要满足最小的可信度和最小的支持度。最后使用一开始找到的频集,利用频集产生期望的数据规则,产生的数据规则包含集合的项中所有的数据关联规则,其中每一个数据规则的右部有且只有一项,在Apriori算法中我们使用的是中规则的相关概念。
3.3 Apriori算法的不足
由频繁k-1项集进行自连接生成的候选频繁k项集的数量是非常巨大的。在验证候选频繁k项集的时候需要对整个数据库进行扫描,这个扫描的过程是非常耗费时间的。
3.4 Apriori算法的改进
Apriori算法为了减少因自身原有的缺陷,而带来的消极影响,以提高Apriori算法在执行方面的效率,针对Apriori算法本身的缺陷,并在Apriori算法的基础上提出了几个基于Apriori算法改进的算法。在此介绍几种典型的改进的算法:
1)基于散列的优化方法
基于散列的优化方法的典型算法就是DHP算法。这种算法利用散列表来产生候选集,可以用于压缩侯选k-项集的集合q(k>-2)的大小。基于散列的优化方法算法能够有效地减少了2维和3维的候选项目集的数量,是对Apriori算法的直接改进。
2)基于事务压缩的优化方法
AprioriTid和APriorHybrid算法是基于事务压缩的优化方法的典型算法。这种算法的主旨思想是通过减少不必要的事务的个数来达到减少扫描数据库数量的目的。
3)基于划分的优化方法
基于划分的优化方法的典型改进算法-Partition算法。这种优化方法最大的优势就是扫描数据库的次数较少,只需对原事务数据库D两遍扫描。
3.5 FP-growth算法的基本思想
FP-growth算法的基本思想是采用分而治之的方法。这种思想需要首先在对数据库进行第一次扫描时导出相应的和Apriori算法相同的频集项的集合与相应的频集项的支持度。
然后可以根据导出的频集项的支持度的大小来对频繁项集进行一个大小的排序,利用这种方法可以构造一个FP树,在构造FP-growth树的时候,可以将数据库中的频集项压缩到一棵频繁模式的树中去,在压缩的过程中需要保留各频集项的基本相关信息,根据频集项的FP树中的关联信息,再将频繁模式的树分化成一些条件库,之后采用不同的数据挖掘方法对这些条件库进行相应的数据挖掘,实行数据挖掘的目的是得到生成长度为2的频集项。
3.6 FP-growth算法的优缺点
FP-growth增长算法有着很明显的优点,主要的优点是:
1)能够将原来的数据库能够有效地压缩成比较小存储空间;
2)不会产生候选项集,所以这种FP-growth增长算法在执行的效率方面会比其他的算法要高很多;
3)数据挖掘的数据与要远远的小于原数据库。
4 结论
数据挖掘可以应用在很多行业,目前主要应用在农业、电信、银行、生物、天体、电力、化工、零售、医药等方面。从表面上看,数据挖掘的应用范围是非常的广泛,但是在实际应用当中却没有达到很深的程度。根据2010年度的Gartner报告,数据挖掘技术将会成为未来40年内一项最重要的技术之一。
基于关联规则的数据挖掘技术的发展应是挖掘工具在先进理论指导下的一种改进,而就目前的情况来看,数据挖掘技术还有很大的发展空间。虽然数据挖掘是一个过程,但是与此过程相关联的是以前数据挖掘之前的结果和数据,那些已获得的数据正是我们想要的,可以不断的分析和产看,因为如果没有进行相应的数据挖掘,是不可能得到有价值的数据。就实际情况来看,只有那些可以依据过去经验形成的合理的解释才是有价值的。
[1]张凤荔.基于关联规则的数据挖掘算法研究[D].电子科技大学,2010.
[2]梅俊.数据挖掘中关联规则算法的研究与应用[D].安徽工程大学,2010.
[3]百度百科. http://baike.baidu.com/view/1076817.htm
[4]钱志忠.偏差检测的相关研究[J].计算机工程与应用,2007,36(1):60-63.
[5]范明,刘艳波,尹军.数据挖掘:概念与技术[M].北京:机械工业出版社,2001.
[6]廖波,王天明.新型数据挖掘算法[J].计算机学报,2003,18(3):364-368.
[7]谭光明,冯圣中,孙凝晖.一种基于新型的数据挖掘算法研究[J].软件学报,2006,17(7):1501-1509.



