张坚英,马俊杰
中国人民解放军63726部队技术室,宁夏 银川 750004
0 引言
随着信息技术的发展,数据挖掘在一些深层次的应用中发挥了积极的作用。但与此同时,也带来隐私保护方面的问题。例如,通过一般的方法对银行卡客户的交易行为等信息的关联分析,可以发现用户在交易行为上的特点,但不可避免地会造成用户的隐私泄漏。所以在数据挖掘过程中解决好隐私保护的问题,成为数据挖掘的一个研究热点[1-2]。
数据挖掘的目标是从数据库中提取隐藏的或者是潜在的有用规则或者模式,然而,数据挖掘中隐私保护的目标是把特定的敏感信息隐藏起来,而不被数据挖掘技术发现。对于给定需要隐藏的项目集,对LHS(ISL)法和RHS(DSR)法进行了改进,解决了关联规则提取中的隐私保护问题,同时保证处理后的关联规则在随后的关联规则挖掘中不被发现。
1 相关工作
数据隐藏试图在数据泄露前将机密或隐私信息的有关数据删除。知识隐藏是指保密知识远离数据进行保密处理。因为关联规则挖掘的缘故,众多有效的关联规则得以发现;但与此同时,许多不想为人知的隐私规则也暴露无遗。为解决这一矛盾性问题,我们必须对挖掘过程加以限制,以确保这些敏感规则隐藏起来,这方面的解决办法非常之多。其中常用的一种即基于支持度和信任度的分块方法[3-5]。
针对上一节问题给出了问题的解决办法,首先,采用先验算法来找出频繁项集,然后,为获得全局支持度和信任度而不泄露隐私,会采用安全计算法。而针对知识隐藏会采用一种改进算法来达到满意效果。
2 算法改进的描述
通过其它方法来隐藏敏感规则时,要删除某个项目或借助一个未知数据来改变原始数据来实现针对如何隐藏信息的关联规则,Wang and Jafari[6]给出两种数据挖掘算法即:增加支持LHS(ISL)法和减少支持RHS(DSR)法。前一种算法旨在增加对规则左边的支持度,而后者则在于减少对规则右边的支持度。有关ISL算法的具体介绍如下:
ISL算法
输入:


3 实验与结论
通过上述方法,敏感规则会被隐藏,但一些非敏感规则也可能也被隐藏,并可能人为生成许多新规则。为解决这一问题,系统应通过使用挖掘结果来对选择过程(挑选出项目以进行修改)加以限制,有关操作步骤如图1所示。
修改选择过程时,我们可以选择其它项作为牺牲项以获得更好的效果。然后,加入一些噪音规则以提高安全性。
由于分块算法的主要不足之处在于,数据集与分块值的数据均不会失真,因此,建立一些噪音规则就成为必要,以使数据集失真,这个可以在剪枝算法环节进行删除。
本文在探讨关联规则挖掘、数据挖掘系统的构建时,对针对隐私保护的一些解决方法进行了详细分析,它们均考虑到数据挖掘过程中存在的主要安全隐患问题。通过采用ISL和DSR方法来实现对敏感规则的隐藏;同时,本文提出了一种可以获得更佳效果的优化方法,其负面影响也较小。针对海量数据,有关解决方法所带来的负面影响尽管较小,但安全计算会带来通信成本巨大、密码系统复杂以致算法效率降低等问题。
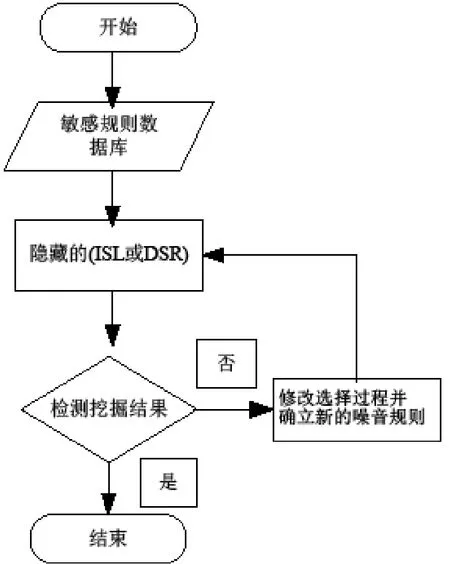
图1 敏感规则的隐藏过程图
[1]Evfimievski A,Srikant R,Agrawal R.Privacy preservingmin2ing of association rules[J].Information Systems,2004,29:343-364.
[2]S.-L.Wang and A.Jafari.Hiding informative association rule setsExpert Systems with Applications,2007,33:316-323.
[3]Y.Saygin, V.S.Verykios, and C.Clifton.Using unknowns to prevent discovery of association rules.ACM SIGMOD Record, 2001,30(4):45-54.
[4]Weimin Ouyang and Qinhua Huang, Privacy Preserving Association Rules Mining Based on Secure Two-Party Computation, Lecture Notes in Control and Information Sciences, 2006, Volume 344/2006, 969-975.
[5]Seifert J W.Data mining and the search for security[J].Gov2ernment Information Quarterly,2004,21:461-480.
[6]张瑞,郑诚,陈娟娟.关联规则挖掘中的隐私保护研究[J].计算机技术与发展, 2008,18(10):13-19.



