曹恒 陈宇璇
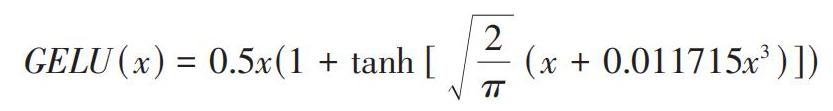

摘要:为了丰富建筑领域的知识图谱,让建筑领域的研究学者可以更直观地看出近些年国内研究现状,该文尝试从改善知识图谱构建过程中三元组的抽取工作。关系抽取作为自然语言处理领域的一大难点,尤其是在处理非结构化文本方面。该文基于深度学习的PCNN神经网络模型,进行短文本处理,获取三元组数据,为后续搭建知识图谱做铺垫。该文也是致力于能够更好地提升关系抽取的效率,为从事建筑行业研究人员或其他领域的文本抽取研究提供了实际意义。
关键词:知识图谱;关系抽取;深度学习;神经网络;PCNN
中图分类号:TP181 文献标识码:A
文章编号:1009-3044(2022)22-0052-03
1 概述
文章从建筑类文章入手,并运用了深度学习的关系抽取技术,抽取出实体对,为构建建筑类知识图谱做好准备[1]。文本格式通常是非结构化数据,目的是在非结构化文本中抽取出结构性数据信息,而关系抽取则在整个流程中起到至关重要的作用,也是技术难点。本文主要根据建筑类文本实体关联提取,首先使用PCNN建模结合了定位信息和词本体的语义信息,而后再完成建筑文本的关联提取。随后,完成了实体识别,辨识出语句中的两个实体,接着PCNN再把整个语句分为三段卷积,之后再采用分段最大池化方法捕获结构化信息,最后的抽取任务由softmax分类器来完成。另外,为了增强模型处理任务的性能,针对中文文本的特征,使用分词工具jieba对文本进行分词,调整并完善PCNN建模。通过实验结果对比发现,完善后的PCNN模型处理中文文本时,能够有效地降低对人工的依赖性。
2 常见关系抽取方法的介绍
2.1 基于规则的方法
该方法主要通过经验建立领域知识规则[2],利用模式匹配的方法完成抽取任务,该方法有明显的性能弊端,如跨应用领域的可移植性、召回率、时间成本等方面都太理想。
2.2 基于机器学习的方法
该方法是依靠人工筛选特征向量[3],需要大量的学科领域知识,不利于推广使用。
2.3 基于深度学习的方法
该方法主要有三类,首先是有监督的方法,有监督方法的优点是利用神经网络模式实现特征关联提取,并且能够减少人工的特征,对于大量的特征可以采用自动学习方法实现提取,但是对于大量没有标记的特征数据效率并不理想。其次是预测模式BERT,BERT是一种预训练语句表示模式,优点在于通过上下文信息获取整个句子的语义结构,将训练后知识运用于关系提取。该方法不擅长处理长文本,并且无法高效地解决一词多义的问题。最后是远程监督的方法,优点就是可以自动抽取大量的实体对,从而降低对人工对象的依赖性,具有较好的可移植性[4]。
3 常见关系抽取模型介绍
3.1 采用基于卷积神经网络CNN 的关系抽取模型
通过卷积神经网络CNN实现了关系提取,以便进行语句的特征向量的表示,首先是提取每个语句中最关键的特点,并进行最终划分[5]。利用卷积神经网络CNN,为了把语句中的关系词转换为词矢量,实现了预训练和随机初始化的embedding,同时还根据语句中的实体词、上下文相对地址表示实体词的地址矢量。接着利用卷积神经网络CNN提取出语句级别的特点,并利用池化方法获得了缩小后的特征向量表。最后,通过一个全连接的神经网络层处理所获取的特征向量,并对语句中所表达的关联进行了划分。不过由于卷积计算神经网络CNN也有明显的缺点,因为其卷积核是固定的,所以,若仅利用卷积计算神经网络CNN简单地进行实体关系提取,易导致对句中词的上下文语义重提取不完整。
3.2 采用基于递归神经网络 RNN 的关系抽取模型
与卷积式神经网络CNN网络的提取句子特征方法不同,递归神经网络RNN模型则主要使用双向LSTM网络来提取语句的特征[6]。为使模拟的输入能够表现出较为充分的上下文语义信息,可以加入Attention机制对输出词的特征向量加以权重,再利用自注意力机制对输入的词向量加以计算,就能够获取新的词向量,最后得到具有偏向性质的词矢量表示。然后再把得到的词矢量注入全连接的神经网络层中,以完成相对关系的分析。
3.3 采用基于 Capsule 的关系抽取模型
模型的主要思想是,被处理的句子与计算机之间,应该有一整套激活的神经元来表示,这样才可以更好地表示出句子里实体坐标。把坐标系作为先验知识,而卷积神经网络没有类似坐标的概念。Capsule模型首先是预处理语句,然后利用经过预训练的embedding分析句中的所有单词,并得出词向量;最后为获得粗粒度的句子特征表示结论,利用了BiLSTM网络,接着再将得出的结论注入胶囊网络系统中[7]。利用构造出的primary capsule获得与分类结果相符的输出胶囊,而分类结果的概率大小则利用胶囊的模长表达。
3.4 采用基于 Transformer 的关系抽取模型
Transformer模式是用全Attention的结构代替了LSTM,由Google公司为解答Seq2Seq提问而发明的,计算速度更快,起初在翻译任务上取得了不错的效果。该关系抽取模型首先需要编码句子的信息,使用的是Transformer 的 encoder 部分[8]。为了不断抽取句子中的重要特征,使用的是multi-head attention 模块。为了把从注意力层获得的产出与投入拼接到仪器上进行正则化,采用残差网络的叠加方式。这样的方法可实现多层堆叠,进而更有效地抽文本信息。最后利用每一级的全连接层整合Transformer的结果,得出了最终的分类效果。
3.5 采用基于 GCN 的关系抽取模型
GCN模型为了高效地提取相关关系,充分利用了依赖树中的信息。该模型是一个基于依存树的GCN节点为中心,利用局部信息聚合技术,在获取图像信号方面具有较好的有效性[9]。因此在处理文本数据方面,可以效仿其在图像处理领域中的使用方法,把方法运用在关联提取中。首先获取一个图卷积中的邻接矩阵,由句子的依赖分析树组成。接着,做图卷积运算,以语句中的各个词汇为动作节点。然后再完成提取语句相关消息的工作,以及通过池化层和全连接层之间作关联提取的各项任务。
3.6 采用基于 BERT 语言预训练模型的关系抽取模型
Bert(Bidirectional Encoder Representations from Transformers)模型由Google在2018年发布,在机器阅读方面取得了惊人的成绩,开启了NLP的新时代。BERT的主要构造层为Transformer的encoder层,最大的亮点是通过获取上下文相关的双向特征表示,从而融入了双向语言模式,其实质上是对二种单向语言模式(前向和后向)的融合[10]。同时通过保存已预训练好的前两层BiLSTM,并通过将特征集成应用于下游任务。结果表明对下游的NLP任务有了较大的改善,并且能够有效提高关系抽取的有效性。但Bert模型也具有几个突出的缺陷,第一是预训练流程与实际生产过程的不统一,会使得实际生产任务有效性不佳;其次是无法解决文本层级的NLP任务,仅适合语句与段落层级的任务。
3.7 采用基于PCNN的远程监督关系抽取模型
PCNN模式比较简单,和传统的神经网路比较,最主要的差异就是池化层的不同,采用了分段池化方式代替了之前的最大值池化方法使用[11]。为减少对人工标注数据结果的依赖性,人们提出了远程监测的概念,前提是二种实体之间在知识库中具有一定关联,以及包含了这两种实体之间的句子,都可以表示出这种关系。在关系提取任务中引入了远程监督学习的方式,为克服远程监督中的标记噪声问题,先用PCNN提取语句的特征矢量表,并且充分考虑在同一个Bag中语句,表述关联的各种意义,最后又引进了句子级别的Attention机制。语句特征矢量表:PCNN和CNN模式的提取语句特征矢量方法一样,通过合成词和词相应部位的embedding显示,进入后 CNN 模式完成卷积。然后通过word2vec的Skip-gram模块把词表现为向量形状,和位置向量加以拼合作为输入,然后再通过卷积层完成feature map。分段池化按照语句中2个实体的情况把语句分成三个部分,然后再依次执行池化操作。因为语句被两个实体分为了左、中、右三段文字,在这三段中间加上了相应的两个地址向量。所以整个网络中总共有了九个输入,这样就可以捕捉语句中的结构信号和更细粒度的特征。
4 PCNN模型结构介绍
4.1 模型结构
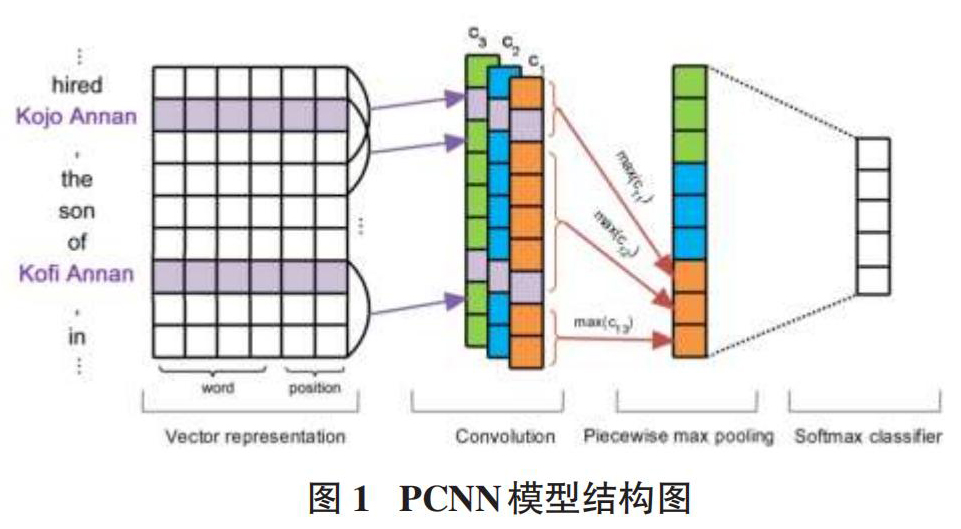
如图1显示,分别为获取向量信息的Vectorzation层、合并特征的卷积层、捕获结构化信息的分段最大池化层以及softmax分类层。
4.2 Vectorzation层
该层的功能是获取向量信息,故Vectorzation层主要由两个部分构成。
一部分是词向量。由于实验数据都是中文文本,所以使用skip-gram模型进行训练,得到每个词的向量,转化成计算机能理解的形式。
另一部分是位置向量。先分别以两种实体词作为基准实体,使其位为零,然后依次计算其他单词与该基准实体的相对位置信息。如“《建筑工程中再生材料应用探究》的作者是高阳”,可以分为“《建筑工程中再生材料应用探究》”“的”“作者”“是”“高阳”为实体,那幺其他词与“《建筑工程中再生材料应用探究》”的相对位置为[0,1,2,3,4],与"高阳"的相对位置为[-4,-3,-2,-1,0]。
4.3 卷积层
为了给出整个句子的预测关系,需要捕捉到不同的特征,然后利用卷积合并所有的特征。该层共设计三种卷积,每种卷积含有100个卷积核。
结合文本中数据的特点,选择GELU函数作为卷积层的激活函数,公式为:
[GELU(x)=0.5x(1+tanh[2π(x+0.011715x3)])]
4.4 分段最大池化层
PCNN模型通过考虑实体的内部上下文与外部上下文,获取两个实体间的结构化信息。于是,根据两个实体的位置将句子划分为3个部分。第一部分是从句首到第一实体,第二部分是从第一实体到第二实体,第三部分是从第二实体到句末,这样每个过滤器卷积的结果就被分为三段。
两个实体把每个卷积核的输出分为三部分,为了捕捉到不同的特征,将使用n个卷积核,则分段最大池化输出向量就是:
[{pi={pi1,pi2,pi3}pij=max(cij)1≤i≤n,1≤j≤3]
4.5 softmax分类器
为了避免模型中发生过拟合现象,需要增强模型的健壮性。首先需要对卷积层中的输出做进一步处理,然后通过每一个线性层次把数据的维降至N维(N为关系类型) ,进行了最后的划分。最后通过softmax分类器做最后的预测,公式为:
[yi=eijej,r*=argmaxiyi]
4.6 模型改进
PCNN模型训练的特点是,在输入序列中随机mask掉一些单词,然后将获取的上下文信息输入PCNN模型中预测。PCNN在处理中文文本的时存在弊端,由于PCNN是针对英文设计的模型,对英文单词进行mask,不会损失句子本身的语义。但运用在中文文本中时,会损失大量文本的语义。因此本文首先使用了分词工具jieba对文本进行分词处理,自监督训练以词为粒度进行随机mask,以此提高对中文文本特征的提取效率。
5 分析
本文利用准确率P、召回率R和F1值进行方法的性能评测,公式如下:
[p=TPTP+FPR=TPTP+FNF1=2PRP+R]
其中,TP代表正例被准确预计的样品总数,FP代表正例被出错预计的样品总数,而FN代表负例被出错预计的样品总数。
PCNN模型和传统RNN模型比较,准确率、召回度以及F1值均有提高,说明了PCNN模式能够更高效地提取文件中的特征信息。任务中用PCNN模型可以进行分段池化得到更有效的上下文信息,也体现出PCNN模型更擅长处理中长短句的特点。将修改后的模型和PCNN模型进行对比,可以发现准确率、召回度和F1值也有所提高,说明在进行中文实体关联提取任务过程中,首先完成对中文的分词预处理,之后再进行关联提取,能有效提高模型的性能。
6 结论
本文首先根据国内建筑方向知识图谱缺乏的现状,针对该领域短文本关系抽取难点,对PCNN模型进行了改进,该模型不但具备了PCNN模型分段最大池化获得句子局部特征的优势,而且同时兼顾了中文文本的语义特点,因此能够更有效地提取出中文语义关系。完善后的PCNN模块可以更好地提取出短文本中的实体关系信息,为今后建立建筑方向知识图谱带来了帮助。
参考文献:
[1] 宋厚岩.基于图数据库的电力系统知识图谱研究与应用[D].北京:中国科学院大学(中国科学院沈阳计算技术研究所),2021.
[2] 谢明鸿,冉强,王红斌.基于同义词词林和规则的中文远程监督人物关系抽取方法[J].计算机工程与科学,2021,43(9):1660-1667.
[3] 王思丽,刘巍,杨恒,等.基于自然语言处理和机器学习的实体关系抽取方法研究[J].图书馆学研究,2021(18):39-48.
[4] 张娅.基于深度学习的远程监督关系抽取算法研究[D].北京:北京交通大学,2021.
[5] 武文雅.基于卷积神经网络的实体关系抽取方法研究[D].北京:北京交通大学,2019.
[6] 岳琪,李想.基于BERT和双向RNN的中文林业知识图谱构建研究[J].内蒙古大学学报(自然科学版),2021,52(2):176-184.
[7] 杨超男,彭敦陆.融合BSRU和胶囊网络的文档级实体关系抽取模型[J].小型微型计算机系统,2022,43(5):964-968.
[8] 周博学.改进的Transformer模型在关系抽取任务中的研究与应用[D].无锡:江南大学,2021.
[9] 郑余祥,左祥麟,左万利,等.基于时间关系的Bi-LSTM+GCN因果关系抽取[J].吉林大学学报(理学版),2021,59(3):643-648.
[10] 黄徐胜,朱月琴,付立军,等.基于BERT的金矿地质实体关系抽取模型研究[J].地质力学学报,2021,27(3):391-399.
[11] 张彤,宋明艳,王俊,等.基于PCNN的工业制造领域质量文本实体关系抽取方法[J].信息技术与网络安全,2021,40(3):8-13.
【通联编辑:唐一东】



