蒋本立 张小平
摘 要: 当前的数据调度平台以数据完成时间实现网络资源的调度,将任务完成时间当成网络均衡调度的基础,未考虑大数据网络的能耗指标,无法实现真正的网络均衡调度。提出基于能量评判的大数据网络均衡调度平台,平台由服务模块、控制模块、虚拟化模块和物理资源模块组成,包括资源定义模块、资源监测模块以及资源调度模块三大功能模块。设计一种基于能量评判的网络资源调度模型,在一定的时间区间内,以能量消耗最佳为约束条件,全面分析大数据网络资源调度中的能量评判问题,给出调度平台采集数据的关键代码。实验结果表明,所设计平台的平均能耗率、吞吐率以及CPU利用率指标都较优,具有较高的负载均衡效果。
关键词: 大数据网络; 均衡调度平台; 网络资源调度; 能量评判
中图分类号: TN915?34; TP315 文献标识码: A 文章编号: 1004?373X(2016)06?0062?04
Design and improvement of balanced scheduling platform for big data network
JIANG Benli1, ZHANG Xiaoping2
(1. Department of Electronics and Information Engineering, Hunan Vocational College of Science & Technology, Changsha 410004, China;
2. Information School, Hunan University of Science & Technology, Xiangtan 411201, China)
Abstract: The current data scheduling platform realizes the network resource scheduling according to data completion time, and takes the task completion time as the basis of balanced scheduling network, in which the energy consumption index of big data network is not considered. That is why it can realize the real network balanced scheduling. Therefore, a big data network equilibrium scheduling platform based on energy evaluation is put forward in this paper. The platform is composed of the service module, control module, virtualization module and the physical resource module, including the resource definition module, resource monitoring module and resource scheduling module. A network resource scheduling model based on energy evaluation was designed, which takes optimal energy consumption in a certain time interval as its constraint condition. The energy evaluation in the big data network resource scheduling is analyzed comprehensively. The key code for data acquisition of the scheduling platform is given. Experiment result shows that the average energy consumption rate, throughput and CPU utilization rate of the designed platform are better, and it has the high load balancing effect.
Keywords: big data network; balanced scheduling platform; network resource scheduling; energy evaluation
随着网络通信技术的不断发展,网络中的数据规模逐渐增加,使得大数据网络的均衡调度问题日益突出[1?3]。当前的大数据网络存在资源使用率低、网络负载失衡的缺陷。因此,针对大数据网络资源环境下的资源调度问题,寻求高效调度策略,对于增强大数据网络资源利用率以及负载均衡具有重要作用。大数据网络的能量是有限的,网络中大规模数据的调度会消耗大量的能量,导致资源调度时间增加。传统的资源调度算法,通常基于数据完成时间实现网络资源的调度,将任务完成时间当成调度目标,未对大数据网络的能耗进行综合分析,无法真正实现网络均衡调度[4?5]。文献[6]分析了基于遗传算法的网络资源调度方法,该种方法将物理机数量和虚拟机变换次数当成优化方向,但是未对物理机的负载均衡进行全面的分析,存在一定的局限性。文献[7]通过蚁群算法实现网络负载均衡,但是蚂蚁在塑造自身的结果后,需要对信息进行调整,大大降低了算法的收敛性。文献[8]融合同构服务器资源负载,暂停空闲的服务器,降低系统的能耗,然而受到调度信息随机性的干扰,容易产生错误的负载迁移,无法实现网络资源的有效调度。文献[9]分析了基于神经网络的网络均衡调度方法,该方法通过神经网络评估网络服务器负载,但是该种方法未对大数据网络资源的多样性进行分析。
1 大数据网络的均衡调度平台设计
1.1 调度平台总体结构
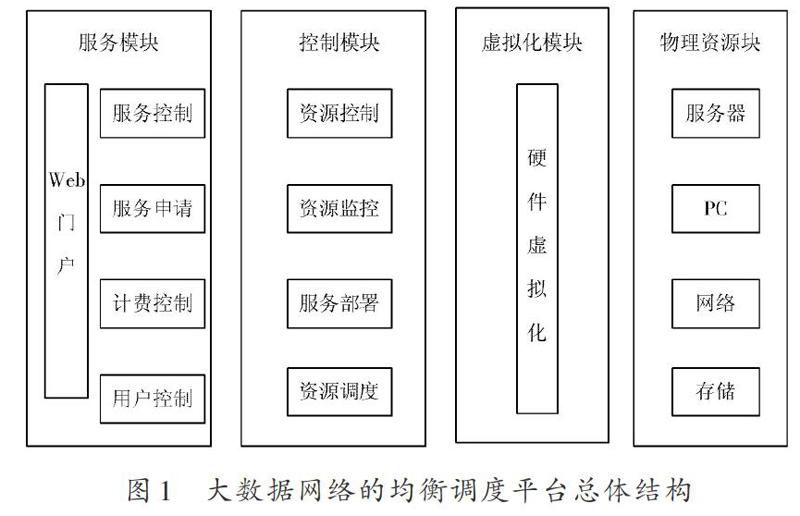
大数据数据网络资源需要合理的平台才能更好地服务于用户,大数据网络的均衡调度平台能联合控制网络资源,还能监测物理资源和虚拟资源的运用状况。并按照用户的资源申请,供应可变化的大数据网络资源。通过基于能量评判的网络资源调度方法,来完成大数据网络物理资源与虚拟资源的均衡调度,确保大数据网络的负载均衡。大数据网络的均衡调度系统平台总体结构如图1所示。
图1所示的调度平台由服务模块、控制模块、虚拟化模块和物理资源模块四大部分组成。服务模块包括:用户控制、服务申请、服务控制、计费控制,主要是把各个资源转变为相应服务,利用Web门户的方式向用户供应。控制模块主要包括:资源控制、资源监控、服务部署以及资源调度,它是大数据网络的均衡调度平台系统的处理中间件,其能够实现大数据网络中的物理部件以及资源的合理处置以及调度。虚拟化模块可在虚拟化工具VirtualBox的辅助下,实现物理资源模块的虚拟化,还可以生成大量的虚拟机,来满足不同用户的不同需要。物理资源模块,囊括了标准不一的 PC 机、服务器、网络部件等。
1.2 平台的硬件功能模块组成
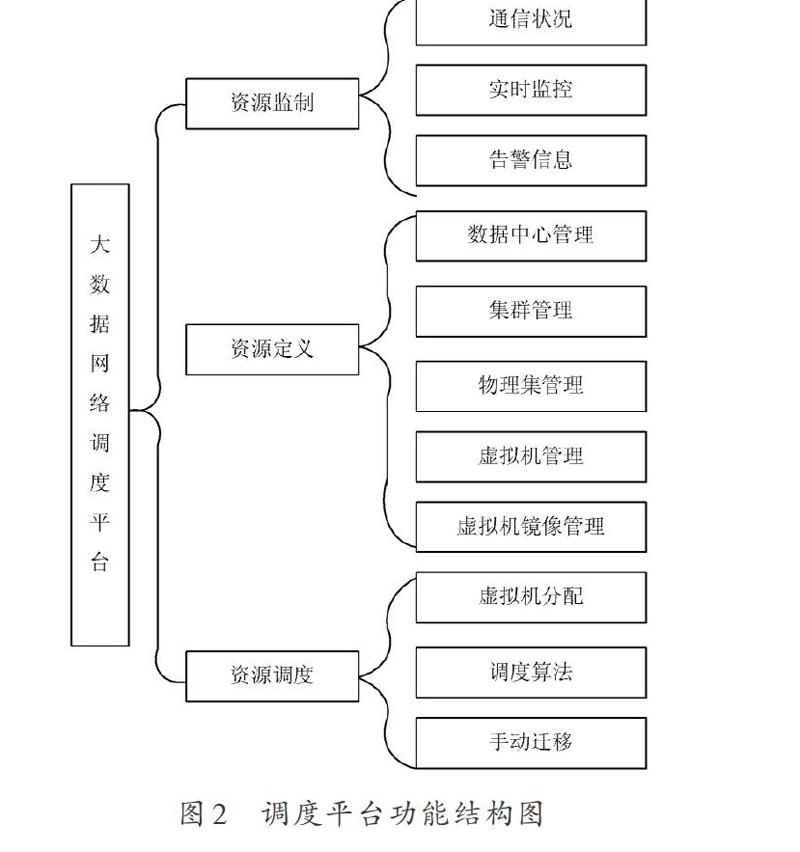
大数据网络均衡调度平台由资源定义模块、资源监测模块以及资源调度模块三大功能模块构成。如图2所示。大数据网络均衡调度平台基于资源管理方案,综合控制大数据网络的物理资源和虚拟资源,并且可面对用户的资源申请信息,检索当下所拥有的资源信息,并且按照一定的标准分派用户的资源申请。各模块的功能如下:
(1) 资源定义模块。资源定义模块主要负责管理大数据网络的资源实体,采取的基本方法有创建、删除、修改、查询等。所谓资源实体,指的就是大数据网络、集群、物理主机、虚拟机以及虚拟机镜像等。
(2) 资源监测模块。资源监测模块起到一个监督、视察的作用,主要针对大数据网络里的物理机和虚拟机的资源使用情形和运营状况。大数据网络节点的负载状况并不是始终如一的,它会因为时间的改变而千变万化,所以要收集每一个大数据网络节点的负载状况,以保证向用户分配资源与合理调度资源的顺利实施。通过设置在不同位置上的大数据网络节点里的监视设备,这个模块可以依照运行周期来收集大数据网络的资源使用情况,将网络监视设备布置在大数据网络服务器上,用来接收不同节点上监视设备输送出来的网络负载数据,并将已完成解析的数据储存到数据库中。对所有收集到的数据都要逐一研究,以便于指导虚拟机布置和负载均衡调节。
(3) 资源调度模块。资源调度模块的数据来自资源监测模块,主要对大数据网络内每项物理机和虚拟机的资源负载状况进行计算,分置好各用户的虚拟机,通过基于能量评判的调度方法,实现大数据网络负载的均衡。资源调度模块采集并分析用户申请,根据用户需要设立虚拟机,并联系此时大数据网络资源的负载情况,在匹配的物理机上设置好虚拟机呈递给用户。
资源监测模块采集大数据网络中物理机和虚拟机的数据,基于获取的数据评估物理机的负载情况。如果物理机负载高于设置的阈值,则说明其负载超标,此时需要在该物理机中选取相应的虚拟机,并将大数据网络中未工作的服务器当成目标移动节点,对虚拟机进行移动,确保大数据网络实现负载均衡。
1.3 基于能量评判的大数据网络均衡调度模型设计
大数据网络均衡调度平台通过基于能量评判的调度方法,对网络中的资源进行均衡调度。基于能量评判的网络均衡调度模型中的资源节点和网络任务间的相关参数含义为:集合[R={r1,r2,…,rn}]用于描述n个异构资源节点构建的网络情况;集合[T={t1,t2,…,tm}]用于描述m个网络任务;设置[ETij]描述资源节点[rj]实施任务[ti]花费的时间;[Bj]用于描述资源节点[rj]的初始能量值。[Ej]用于描述特定时间里资源节点[rj]实施任务要花费的能量值;[Cj]用于描述特定时间里资源节点[rj]沟通单元数量数据的耗能量;[BWj]用于描述资源节点[rj]的网络带宽。网络数据调度模型的耗能是指,任务[ti]通过资源[rj]的本地计算耗能量[EECij]与实施任务时间[ETij]和耗能量率有着紧密的联系,如式(1)所示:
[EECij=ETij·Ej] (1)
任务[ti]利用网络沟通的思维来考虑资源[rj]里沟通的耗能量[CECij],将单元数据量的网络传递时间界定成网络带宽[BWj]的最后一位数,如果任务传递的数据量为[Gi],网络沟通耗能量如式(2)所示:
[CECij=Gi?(1BWj)?Cj] (2)
[ECij]表示测量网络任务匹配到网络资源中的耗能量,有:
[ECij=EECij+CECij] (3)
式(3)中的耗能量值[ECij]是一个资源[rj]在调度里的耗能量状态,但模型应考虑总体调度环境,完成能量的改进。所以需要增加一个衡量数值[ECavg],[ECavg]用于描述全部网络资源的平均耗能量率,同时也是调度计算耗能量的衡量规范。[ECavg]值同调度能耗具有正相关性,[ECavg]的表达式如下:
[ECavg=j=0n-1(ECijBj)n, rj∈R] (4)
基于能量评判的大数据网络均衡调度的具体过程为:
(1) 将大数据网络资源调度任务集T里的全部任务,映射到资源节点集R中的全部资源节点上,通过检测模块计算出全部相匹配的代价值[Cost(i,j)]。
(2) 记忆模块设置大数据网络资源集里的全部资源节点状态为未标记。
(3) 随意提取大数据网络资源调度任务集中的1个任务[ti],将其映射到代价值[Cost(i,j)]中最小的资源节点[rj]上,同时计算出[Cost(i,j)]值,这个值表示最小代价。
(4) 获取映射值,它的含义是当把大数据网络资源调度任务,映射到[rj]以外的任意资源节点的过程,就会产生更多的能耗,映射值就是最小代价和第二小的代价间的差值。
(5) 分析大数据网络资源节点[rj]的标示状态:假设资源节点没有标示,在大数据网络资源调度任务集T里过滤任务[ti],设置资源节点[rj]为已标记;假设资源点是标记状态,对比待映射到资源节点[rj]中的任务帐和任务[ti]映射值,如果[rj]的映射值较小,那么要把帐再次返还到任务集T里,并把[ti]映射到[rj]中,在任务集T里过滤[ti]。
(6) 循环运行过程(3)~过程(5),直到不能将新大数据网络资源调度任务支配出去。
(7) 被支配的新大数据网络资源调度任务资源节点的准备时间[Di]与资源结余能量值,在当前迭代中完成实时调整。
(8) 循环运行过程(2)~过程(7),自适应调度模块进行数次迭代,一直到任务集里的全部任务都完成,并计算[ECavg]的数值。通过调控[ECavg]值,实现大数据网络负载的控制,确保大数据网络负载均衡。
2 代码设计
大数据网络均衡调度平台,通过塑造通信连接类SocketConnection类和一些物理监视器彼此创立联系,得到需要调度的数据,关键代码如下:
Public boolean open () {
if (the.MaterialWeblogic==nought || the.MaterialWeblogic.acquireIP()==nought)
rewarding artificial;
//构造物理机的hole地址
bottom=fresh InetHoleSite(the.MaterialWeblogic.acquireIP(),Integral number,anatomise Int|the.MaterialWeblogic.acquirePort|);
try{
//连接到物理机
confluent.couple(bottom);
institution.out.println("couple toMaterialWeblogic victory");
//输出调度数据
in fresh target investment Stream(confluent.acquire investment Stream; //数据流调度
rewarding true;
catch (IOException e){
Syatem,out.println["couple to MaterialWeblogic failed!"];
//调度失败
}
rewarding artificial;
} }
3 实验分析
为了验证本文方法的有效性,需要进行相关的实验分析。实验研究本文方法和启发式调度方法,对于某大型电子商务网络服务器在能量评判、吞吐率以及CPU利用率上的性能对比。实验针对不同的任务数,对两种方法进行调度检测,循环运行100次,分析两种方法的平均能量消耗率,结果如图3所示。
由图3可知,与启发式调度方法对比,本文方法的平均能耗率较低,同时随着任务数的逐渐提升,能量消耗率呈现平稳变化趋势,但是启发式调度方法却存在较高波动。主要是启发式调度方法在调度网络资源过程中仅考虑任务完成时间,对高能耗的运算能量高的资源进行调度,使得能量消耗率高并且具有加大的波动。
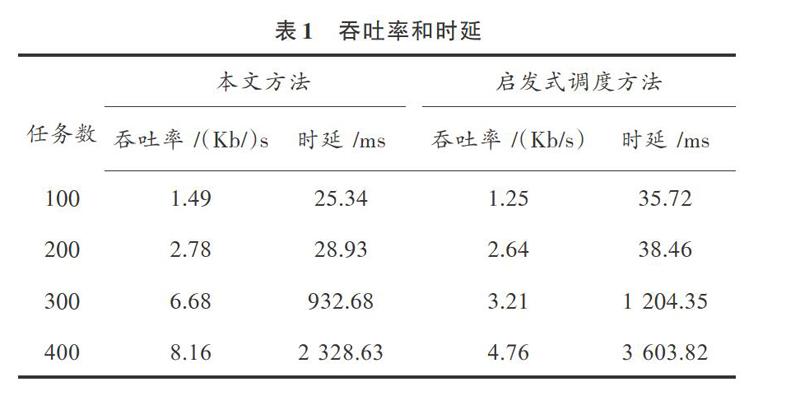
实验统计两种方法在发送任务数过程中的吞吐率和时延,结果如表1所示。
表1 吞吐率和时延
由表1可知,当任务数较小时,两个算法的吞吐率相差不大,但是启发式调度方法的时延高于本文方法。说明当任务数增加,网络负载提升情况下,本文方法可针对大数据网络环境进行资源自适应的调整,并且具有较高的吞吐率,大数据均衡调度优势充分表现出来。实验通过图4分析两种方法的CPU利用率情况。
分析图4可得,本文方法的CPU利用率始终高于启发式调度方法,并且变化较为平稳,本文方法具有较高的负载均衡效果。
4 结 语
本文提出一种基于能量评判的大数据网络均衡调度平台;平台由服务模块、控制模块、虚拟化模块和物理资源模块组成,包括资源定义模块、资源监测模块以及资源调度模块三大功能模块。调度平台基于能量评判的网络资源调度算法,在一定的时间区间内完成能量消耗最佳为最终目标,全面分析了大数据网络资源调度中的能量评判问题,给出了调度平台采集数据的关键代码。实验结果说明,所设计平台的平均能耗率、吞吐率以及CPU利用率指标都较优,具有较高的负载均衡效果。
参考文献
[1] 潘飞,蒋从锋,徐向华,等.负载相关的虚拟机放置策略[J].小型微型计算机系统,2013,34(3):520?524.
[2] 邓维,刘方明,金海,等.云计算数据中心的新能源应用: 研究现状与趋势[J].计算机学报,2013,36(3):582?598.
[3] 魏彦红.BI?PaaS平台中BI应用的调度方案的研宄与实现[D].北京:北京邮电大学,2014.
[4] 张洁.Agent的制造系统调度与控制[M].北京:国防工业出版社,2013:18?21.
[5] 魏晓辉,付庆午,李洪亮. Hadoop平台下基于资源预测的 Delay调度算法[J].吉林大学学报(理学版),2013,51(1):101?106.
[6] 胡丹,于炯,英昌甜,等.Hadoop平台下改进的LATE调度算法[J].计算机工程与应用,2014(4):86?89.
[7] 柯何杨,杨群,王立松,等.Hadoop 延迟调度中延迟时间间隔的合理设置[J].计算机应用与软件,2013(12):207?210.
[8] 刘莉,姜明华.异构集群下的任务调度算法研究[J].计算机应用研究,2014,31(1):80?84.
[9] WU Kehe, CHEN Long, YE Shichao, et al. A load balancing algorithm based on the variation trend of entropy in homogeneous cluster [J]. International journal of grid and distributed computing, 2014, 7(2): 11?20.



