谢晓广,门雅范
(河南信息工程学校,河南 郑州 450003)
网络化考试组卷算法及QTI标准应用研究
谢晓广,门雅范
(河南信息工程学校,河南 郑州450003)
试卷的质量直接决定了考试的效果,优秀的考试组卷算法能够更好的满足用户设定的标准。结合现有算法和项目实际需求,基于粒子群优化算法的流程,提出了五项改进措施,包括编码方案和试卷适应度值计算方法的改进,提出了新的粒子学习过程,使粒子能够逐代变好,更快收敛到全局最优解。在改进的粒子群优化算法中,又加入了混沌初始化和混沌扰动,通过算法实验与改进,设计并实现一种新的组卷方法以期得到更好的结果,并采用QTI标准进行试题存储,实现试题共享,证明在实际应用中的可行性。
组卷;粒子群优化算法;改进与优化;QTI标准
在网络化考试中,组卷算法是考试系统构建中必不可少的环节。试卷的质量很大程度上影响并决定了一次考试是否有效。一个合适的组卷算法能够满足用户对考试指标的限制和要求,并且具有一定的随机性和合理性,是一个典型的多目标优化问题,涉及多重评估需求[1]。考试系统的教师用户希望在出题的时候能够满足一些特定的指标,比如每种题型的数目和试卷总体的难度、区分度指标。如何从海量试题库中筛选出一组满足特定评估需求的试题形成一套标准的科学的试卷在网络化考试和计算机辅助教学的研究中具有重要意义[2]。
1 QTI标准
QTI(Question and Test Interoperability)是美国高等教育协会机构EDUCAUSE制定的国际通用网络学习标准的项目组的规范之一,包括若干个规范文本,主要用来解决网络教育中测试数据的共享,作为一种标准的定义格式,可以在不同系统和用户之间被使用。QTI规范能够表述测试过程的各个环节,包括试题的描述、评估、重用和自适应测试[3]。使用QTI标准可以使试题实现跨平台和跨系统的重用,并且可以共享测评结果。QTI具有更为广泛的适应性,便于资源共享和评价结果的交互,同时便于用户的使用和扩展,主要包括ASI模型、结果规范模型、试题构成要素的QTI XML表示[4]。
2 粒子群优化算法的改进
2.1粒子群优化算法的组卷模型
采用粒子群优化算法进行组卷依据的模型:假设题库的试题数为n,从中抽取试题进行组卷实验。要求每份试卷的试题数为d,则每份试卷可以看作一个维度为d的粒子,其中的每一维代表试卷中的一道试题。选取这样的m个粒子构成一个种群,则可以根据粒子群优化算法进行迭代和寻优。将每次的组卷结果与组卷问题中由用户设定的指标值函数进行比较,并判断粒子的下一步更新方向,直到得到符合要求的试卷,停止迭代[5]。
2.2改进方案
系统目前采用的组卷算法是遗传算法,在组卷中,遗传算法需要不断根据适应度函数判断效果,并且当题型和参数要求较多的时候比较慢,因为需要经过反复的迭代和筛选,其中得到的大多数结果因为达不到条件限制,适应度低而被淘汰。所以需要多次迭代才能得到最终结果[6]。同时,现阶段的考试系统还存在一些问题,比如试题共享存储,这些都需要进一步改进[7]。
(1)改进编码方案
系统采用实数编码的方式,由于试题本身在数据库存储的时候具有ID属性,根据题号作为编码也是比较自然的处理办法,并且易于理解,从整体流程上来说,减少了编码解码的操作,组卷效率更高[8]。
(2)加入混沌初始化和混沌扰动
在改进中采用由Logistic映射产生的混沌系统,组卷问题上,利用混沌的遍历性,在粒子初始化的时候生成一系列多于要求种群数目的个体,并根据适应度值从中选出符合种群规定数目的一组质量较优的个体子集,不仅保证了种群个体的随机分布,也保证了个体质量。利用Logistic映射,在粒子学习的过程中加入混沌扰动。粒子当前时刻的位置通过前一时刻的位置和当前速度进行更新后,对粒子进行范围调整,使之不超过问题的最大范围,之后加入一个扰动的变量,并检查加入扰动之后的个体是否优于之前的个体。混沌扰动可以帮助粒子跳出局部最优解,避免粒子早熟。
(3)惯性权值的自适应改进
在算法实现的过程中,进行粒子学习之前,先调用函数得到最新的惯性权值,在进化的过程中智能调整。当适应度值较小的时候,即低于平均适应度值的时候,取较大的惯性权值,目的是在全局寻优。当适应度值较大的时候,即高于平均适应度值的时候,根据迭代的情况,取较小的适应度值,目的是不断微调,寻找到最优解。
(4)改进粒子学习过程
计算出自适应改进的惯性权值等参数,参照标准遗传算法中最常使用的赌轮选择方法进行选择,赌轮选择主要是依据各个指标值占总值的比例进行选择,所以又称适应度成比例选择。值越大的个体,被选择的机会也越高。因为是对学习结果进行过检验的,所以可以保证粒子在学习之后可以变好,同时也具有一定的随机性和不确定性,有利于保持种群的多样化。学习之后,还要加上以上所述的混沌扰动过程,避免粒子陷入局部最优解。
(5)改进适应度的计算方法
在组卷问题中,适应度值的计算主要考虑试题类型的符合程度,试题状态的符合程度,试卷难度和区分度的符合程度等。这里对试卷难度和区分度的计算采用一种加分数权值的方法。在计算难度和区分度的时候加上分值的权值,有利于组卷过程中的总体控制。
3 改进算法实现
在算法改进与实现部分,共设计并实现了4种算法,分别为标准遗传算法、改进遗传算法、标准粒子群优化算法和改进粒子群优化算法。部分实验参数设置如下:
(1)对比算法1(遗传算法)的主要参数:交叉率CROSSRATE=0.7;变异率MUTERATE=0.05;种群数量POPULATIONSIZE=40;最大适应度值 FITSCORE= 80 000。
(2)对比算法2(改进遗传算法)的主要参数:初始的交叉概率CROSSRATE=0.7;自适应改进的最大交叉概率crossMax=0.9;自适应改进的最小交叉概率cross-Min=0.5;初始的变异概率MUTERATE=0.05;自适应改进的最大变异概率:mutationMax=0.1;自适应改进的最小变异概率:mutationMin=0.01;种群数量:POPULATIONSIZE=40;目的适应度:FITSCORE=80 000。
(3)改进粒子群优化算法的主要参数:惯性权值:W=0.1;惯性权值最大值:W=0.8;个体学习因子的最大值:c1max=2.3;个体学习因子的最小值:c1min=1.2;群体学习因子的最大值:c2max=1.3;群体学习因子的最小值:c2min=0.6;速度最大值:Vmax=300。
3.1参数取值分析
惯性权值用来保持个体原来的速度,cpbest和cgbest用来决定向其他个体学习的力度。惯性权值较大,利于跳出局部最优点,惯性权值较小,利于帮助算法快速收敛。
以如下试卷指标进行实验:难度3.0,区分度3.0,试题数量10,单选题数4,多选题数3,简答题数3,公有试题数为7,私有试题数为3。先对惯性权值Wmin和Wmax进行实验。实验初期,设速度最大值Vmax=100,个体学习因子最小值c1min=1,个体学习因子最大值c1max=2,群体学习因子最小值 c2min=1,群体学习因子最大值c2max=2。表1为惯性权值的实验结果,其中,横向表示惯性权值的最小值Wmin,纵向表示惯性权值的最大值Wmax。
表1可以显示出,当Wmin=0.1,Wmax=0.8时,程序在时间和平均适应度值上都比较好。
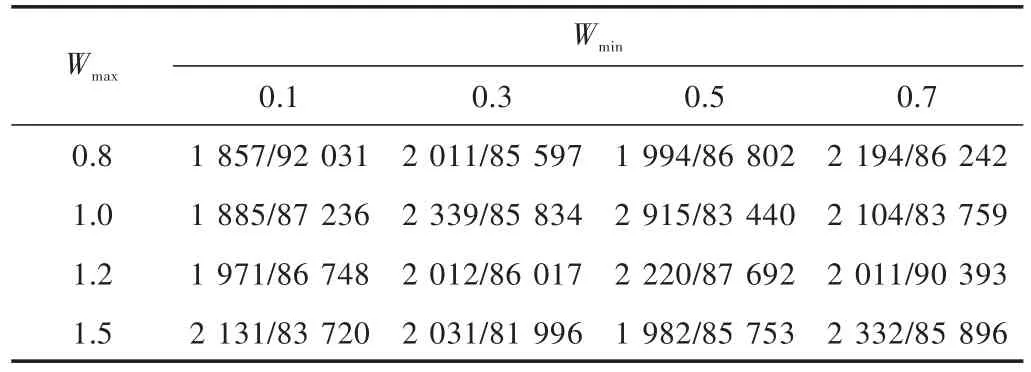
表1 惯性权值实验结果
设速度最大值Vmax=100,惯性权值最小值Wmin= 0.1,惯性权值最大值Wmax=0.8。
个体学习因子的试探范围为2~3,群体学习因子的试探范围为1~2。结果数据由程序运行20次的时间和平均适应度值组成。学习因子实验结果如表2所示。由表2可以看出,个体学习因子为2.3,群体学习因子为1.3时 ,效 果 会 好一 些 ,设 置 c1max=2.3,c1min=1.2,c2max=1.3,c2min=0.6,继续后续实验。
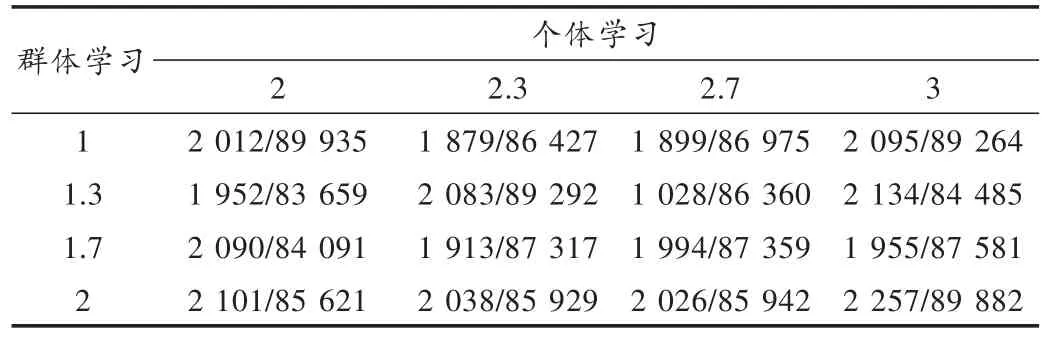
表2 学习因子实验结果
设 速 度 最 大 值 Vmax=100,Wmin=0.1,Wmax=0.8,c1max=2.3,c1min=1.2,c2max=1.3,c2min=0.6。如表3所示,第一列表示速度最大值Vmax,第二列表示按上述参数运行程序20次得到的时间,第三列表示这20次的平均适应度值。题库的总试题数为6 000,以此进行实验。当Vmax=300时,时间和平均适应度值比较好。
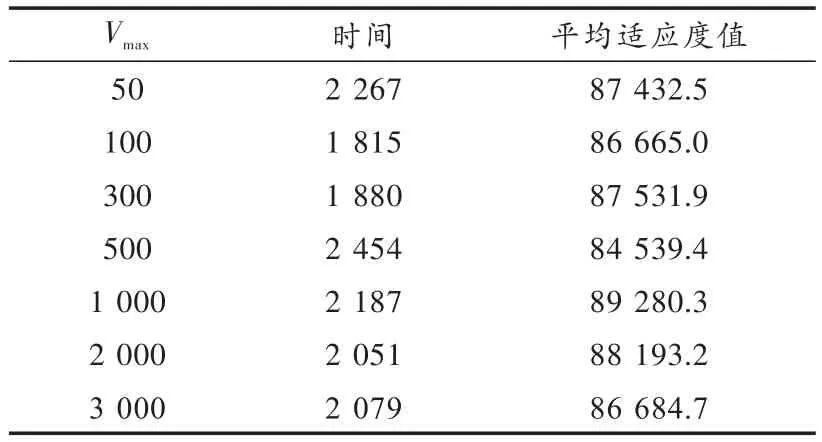
表3 最大速度实验结果
最终的数据设置为:最大速度Vmax=300,最大惯性权值Wmax=0.8,最小惯性权值Wmin=0.1,个体学习因子最大值c1max=2.3,个体学习因子最小值c1min=1.2,群体学习因子最大值 c2max=1.3,群体学习因子最小值c2min=0.6。
3.2改进结果的分析与评价
(1)单次运行结果
单次运行结果比较如图1所示。为便于查看,将程序各运行20次,从中选出迭代次数最大的两组进行画图比较。横坐标为迭代次数,纵坐标为每次迭代后的适应度值,因为程序设置的可接受阈值为80 000,所以设置坐标的最大值为80 000。

图1 单次运行结果比较
(2)多次运行结果
多次运行结果如表4所示,将标准遗传算法,改进遗传算法,标准粒子群优化算法和改进粒子群优化算法进行比较。表中的数据时间都是以ms为单位,时间是20次程序运行结果的总和。指标值是运行结果的平均值,为便于比较,时间和指标值都通过四舍五入的方法保留2位小数。
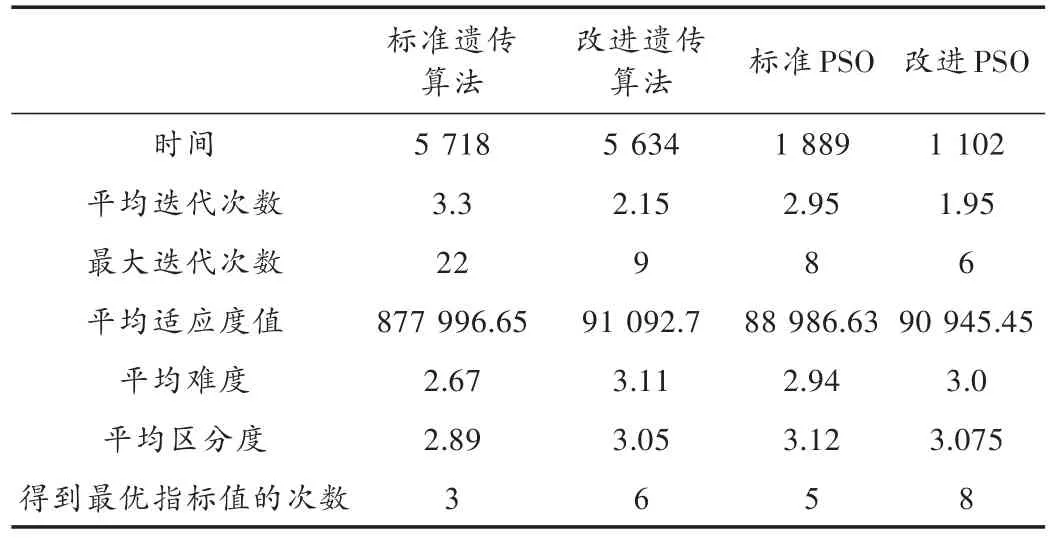
表4 多次运行结果数据
由表4中的数据可见,不管是改进遗传算法还是改进PSO算法,都比原算法有更好的效果。在时间、迭代次数和指标值方面都有一定程度的优化。改进算法平均用时更少,迭代次数更少,得到最优解的次数更多。而粒子群优化算法与遗传算法相比,在时间上有显著的优越性。
4 组卷系统的设计与实现
4.1系统功能描述
组卷系统的开发主要满足教师用户功能,包含四个主要的功能模块:试题管理、试卷管理、试卷评阅和结果反馈。
(1)试题管理
录入试题:试题的题型有单选、多选、简答、问答四种。用户可以设置试题的主要指标,如难度、分值、状态等。题目里可以包含图片或者公式,并可以进行简单的格式调整。
(2)试卷管理
查询试卷:可以根据试卷的不同参数指标对试卷进行查询。组卷:可以设置试卷的指标,由系统自动从题库中选择试题进行组卷,也可以由用户自己录入试题组卷。浏览试卷:对发布的试卷进行浏览,查看试卷中的试题。
(3)试卷评阅
可以通过输入的试卷名称或者用户名称进行查询,对查询到的试卷可以进行查看。如果试卷未经过评阅,可以进行评阅,需要评阅的一般为试卷中的主观题部分。对于已阅试卷,可以进行查看。
(4)结果反馈
可以通过输入的试卷名称或者用户名称进行查询,对查询到的试卷可以查看评阅结果。
4.2系统设计
(1)功能模块设计
功能模块分解如图2所示。重点完成的部分为试题管理和试卷管理。在试题管理的导入试题中,应用QTI技术,规范化XML,实现试题共享。
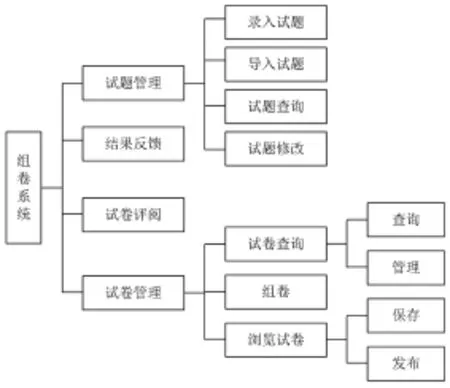
图2 系统功能模块分解
(2)QTI的设计与应用
在系统的实现中,采用QTI形式进行试题存储。单选题、多选题和主观题的共同点是:每个Item中都包含两个主要节点,即试题描述presentation和试题答案reprocessing。但是在细节处理上各有不同,包括标识符,存储形式和表现形式等。
多选题与单选题的结构类似,只是所有表示类型的字段对应改为Multiple。此外,在答案部分,多选题有两个<varequal></varequal>节点,每个节点的内容为一个选项字母。主观题与选择题的区别是,首先标志性字段改为SimpleAnswer。其次,没有选项信息,即render_choice内容。第三,respcondition节点的response_type属性为str,说明它的答案应该是一个字符串,而不像单选和多选中是lid属性。
5 系统实现
整个系统在eclipse下使用java和jsp进行开发,数据库使用MySQL。开发环境是jdk-1_5_0-windowsi586,服务器使用apache-tomcat-6.0。
系统设计开发中采用三层架构,划分了较为典型的界面层、逻辑层和数据访问层:界面层与系统用户进行交互。获取用户输入,进行合法性验证,后台进行处理后将结果以多种形式向用户呈现。界面层的设计要求具有一定的安全性,过滤明显易于验证的非法输入,确保不泄露程序内部信息。
用户打开网站,通过首页导航条的链接可以选择查看试题管理、试卷管理、试卷评阅或是评测结果的页面并进行相关操作。点击最后一栏的“查看”,可以跳转到试题浏览界面,进行试题查询。
在试题管理页面,可以进行试题录入。设置参数并输入题目和选项信息。编辑框的设置会随着不同的题型而改变,比如,单选题和多选题有6个编辑框,简答题和问答题有两个编辑框。编辑框采用的是FCKEditor插件,支持富文本编辑,通过配置,可以实现插入图片和公式等较为高级的功能。试题录入完成后点击“提交”按钮,可以跳转到试题浏览页面。在试题浏览页面,可以点击“编辑”按钮对试题重新进行编辑。通过点击链接,可以查看另一个功能:试题导入。试题导入要求符合XML规范的文件,点击导入,实现将试题保存到数据库。
试卷评阅和评测结果两部分主要是展示考试的效果,功能比较简单,还需要进一步进行完善。
6 结 论
本文主要以粒子群优化算法为基础,结合工程项目在应用中的实际需求进行改进。本文提出一种比较新的编码和适应度值计算方法,将试题的属性结合到编码中,减少了数据库的读取,在组卷时间上会更好。同时对粒子学习过程进行了改进,与机械式的套用粒子群优化算法的公式不同,真正实现了粒子学习的本质,即每次学习的结果得到的是与最优个体之间的补偿值。
在改进粒子群优化算法中,加入了混沌初始化和混沌扰动,使组卷具有更好的效果。对改进粒子群优化算法进行参数取值实验,选择一组比较适合的参数,通过与标准粒子群优化算法、遗传算法和改进遗传算法进行对比,证明改进粒子群优化算法不仅节省组卷时间,并且组卷结果也更为理想。
[1]付细楚.考试系统中若干关键技术研究与系统实现[D].长沙:湖南大学,2005:22-24.
[2]刘玲,钟伟民,钱锋.改进的混沌粒子群优化算法[J].华东理工大学学报(自然科学版),2010(2):267-272.
[3]刘亚琼.基于加强学习的自动组卷算法的研究[D].天津:天津大学,2006:66-67.
[4]孙艳霞,王增会,陈增强,等.混沌粒子群优化及其分析[J].系统仿真学报,2008(21):5920-5923.
[5]王成华,曾超峰.浅基础的混沌粒子群优化设计方法[J].沈阳建筑大学学报(自然科学版),2011,27(6):34-35.
[6]王维博,冯全源.基于分层多子群的混沌粒子群优化算法[J].控制与决策,2010(11):55-57.
[7]张亮,赵娜.基于.NET的网络考试系统设计与实现[J].现代电子技术,2010,33(8):64-66.
[8]司存瑞,周岩,孙米.网络考试系统平台的设计与实现[J].现代电子技术,2006,29(20):44-46.
Test-paper combination algorithm of networked examination and application research of QTI Standard
XIE Xiaoguang,MEN Yafan
(Henan Information Engineering College,Zhengzhou 450003,China)
The quality of test paper directly determines the test result,so the excellent test-paper combination algorithm can better satify the standard set by the user.In combination with the practical demand of the project and existing algorithms,5 improvement measures are proposed based on the particle swarm optimization algorithm.The computing method of test-paper fitness and coding scheme were improved.The new particle learning process was improved to make the particles better for each generation and have the performance of fast convergence to the global optimal solution.The chaos initialization and chaos disturbance are added into the improved particle swarm optimization algorithm.A new test-paper combination method was designed and implemented by means of algorithm experiment and improvement to obtain the better results.The QTI Standard is used to store the test questions and share them.The method feasibility was verified in practical application.
test-paper combination;particle swarm optimization algorithm;improvement and optimization;QTI Standard
TN915-34;TM417
A
1004-373X(2016)13-0112-04
2015-11-10
国家自然科学基金项目(81271284)
谢晓广(1971—),男,河南郑州人,硕士,高级讲师。主要研究方向为网络技术与教学。
门雅范(1972—),女,硕士,高级讲师。主要研究方向为计算机网络技术。



