杨健,周涛,,郭丽芳,张飞飞,梁蒙蒙
(1.宁夏医科大学 公共管理研究中心,宁夏 银川 750004;2.宁夏医科大学 理学院,宁夏 银川 750004)
0 引言
肺癌是当今对人类生命健康危害最大的恶性肿瘤之一[1]。医学影像学方法检查广泛应用于肺部肿瘤的诊断,其中包括X线成像,CT,PET,MRI及PET等[2]。计算机辅助诊断系统能够结合高效率的计算机分析处理技术和数字图像处理技术,实现对疾病的有效诊断,为医生提供准确率较高的诊断结果,从而提高医学影像诊断的客观性、准确性和诊断效率[3]。
目前,肺部肿瘤计算机辅助诊断的处理过程主要包括预处理、分割、ROI检测、特征提取、特征选择和分类等阶段。Altarawneh等在肺癌检测中为实现去噪目的,采用Gabor滤波、自动增强和快速傅里叶变换算法对肺部CT图像进行预处理[4]。Firmino等采用区域增长法和形态学法进行肺部图像的分割[5]。计算机辅助诊断系统通常需要对具有专家标记的肺部图像从形状、纹理、灰度和形态学等角度上提取特征以训练算法模型。Demir等在提出的肺结节计算机辅助检测,提取外部表面纹理特征后进行分类,其分类效果良好[6]。近年来神经网络广泛应用于肺部肿瘤计算机辅助诊断系统中,目前已成功利用ANN分类器针对层厚较薄的CT上原发良恶性孤立型肺结节加以鉴别[3]。聂永康等从肿瘤的CT特征和PET特征角度出发[7]提出一种基于人工神经网络计算机辅助诊断系统。
目前基于医学图像的计算机辅助诊断领域,出现了各类优秀的模型和算法,但是其特征提取较为复杂,模型和算法的鲁棒性和泛化能力有限。另外,在肺部肿瘤计算机辅助诊断方面,目前的肺部肿瘤计算机辅助诊断模型仍然存在识别精度不高和漏诊率、误诊率降低困难的问题。深度学习[8](Deep Learning,DL)的出现能够有效解决算法面临的特征提取问题。深度学习是一种智能高效的特征提取方法。它能够从数据中提取更加抽象的特征,以实现对数据更本质的描述,同时其深层模型具有更强的模型泛化能力。深度信念网络[9](Deep Belief Networks,DBN)是目前深度学习中研究层次较深且应用领域较广泛的一种重要模型。深度信念网络不仅能够对数据进行高效且智能的学习,而且通过受限玻尔兹曼机[10](Restricted Boltzmann Machine,RBM)的特征提取能力能够在很大程度上提高识别性能。集成学习[11]基于训练数据建立多个同质且存在差异的个体学习器来解决同一个问题,然后将所有个体学习器的预测结果进行整合得到集成学习的最终预测结果。与个体学习器相比较,集成学习的优势体现在其能够在很大程度上有效地提高学习系统的泛化能力。本文提出一种基于集成DBN的肺部肿瘤计算机辅助诊断模型。
本文在不同的样本空间(CT,PET,PET/CT)构建三个单一DBN个体分类器(CT-DBN,PET-DBN,PET/CTDBN),并采用相对多数投票法集成三个单一DBN个体分类器,得出对三个模态肺部图像的最终识别结果,比较三个单一DBN和集成DBN在肺部肿瘤计算机辅助诊断中的整体性能。实验结果表明,集成DBN对肺部肿瘤的计算机辅助诊断能够达到99.67%的识别精度,集成DBN的识别性能整体上优于三个单一DBN模型,能够协助影像科医生进行肺部肿瘤的计算机辅助诊断。
1 基础理论
1.1 受限玻尔兹曼机
受限玻尔兹曼机(RBM)是构造深度信念网络的学习模块,它是一种概率生成模型,每个RBM分为两层,每一层的节点之间没有连接,但层和层之间彼此互连,输入数据层为显层,表示为v,不可见层为隐层,表示为h,连接两层的权值矩阵是ω,c和b分别为隐层与显层的偏置,通常将所有节点均设为二值变量。
RBM也可以看作是一个随机神经网络,当给定显层或隐层神经元状态时,隐层与显层神经元的激活概率分别为:
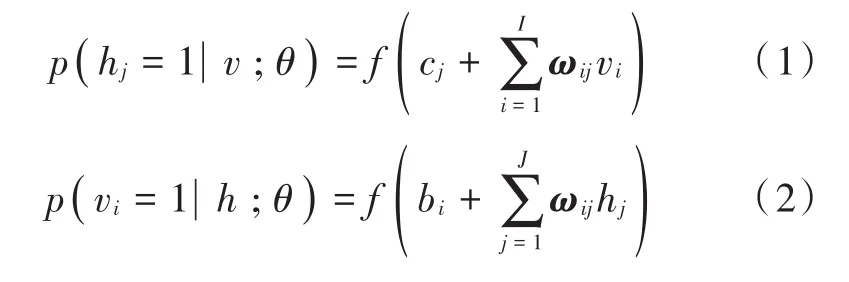
式中,函数f是sigmoid函数。
RBM训练过程要学习参数θ=(ωij,bi,cj)的值,以拟合给定的训练数据。RBM的非监督学习过程中通常采用对比散度(Contrastive Divergence,CD)的算法更新参数。
1.2 深度信念网络
深度信念网络(DBN)是结合无监督学习和有监督学习的多层概率机器学习模型。DBN是一种多层的网络结构,它是由若干层无监督的RBM单元和一层有监督的反向传播网络组成的。DBN的深层结构能够将低层特征组合形成更抽象的高层特征,有效提取训练数据中的特征信息,以实现对原始训练数据的本质描述。
DBN的学习过程主要分为无监督特征学习和有监督参数微调两个阶段:
1)无监督特征学习。本阶段即对DBN每层网络进行预训练,预训练过程采用贪婪无监督逐层学习算法自低层到顶层逐层训练每个RBM,并将本层的训练结果作为其高一层的输入,如此逐层训练整个DBN网络,从而实现网络参数的初始化。
2)有监督参数微调。由于RBM的逐层训练仅能实现本层网络参数达到最优的效果,并不能达到整个网络的最优状态,所以本阶段使用反向传播算法对整个DBN网络的参数进行深度的优化和调整。将第一阶段中网络参数初始化得到的权重作为DBN网络的初始权重,连接各层RBM,利用反向传播算法从DBN顶层向低层对其权重进行修正,构成整个DBN深度结构。
1.3 集成学习
集成学习的核心思想是建立多个同质且存在差异的个体学习器来解决同一个问题,然后将所有个体学习器的预测结果通过一定的策略进行有机组合即得到集成学习的最终预测结果[12]。根据集成学习用途的不同,通常选择采用不同的结果合成方法:若集成学习的用途为回归估计,通常将各个体学习器的预测结果进行简单平均或者加权平均从而得到集成学习的最终预测结果[13];若集成学习的用途为分类,通常对各个体学习器的分类结果进行投票从而得到集成学习的最终分类结果。投票方法分为绝对多数投票法和相对多数投票法,绝对多数投票法,即超过半数的个体学习器输出同一种分类结果,则该结果为集成学习输出的最终分类结果;相对多数投票法,即输出某种分类结果的个体学习器的数目最多,则该结果为集成学习输出的最终分类结果[14]。
2 基于集成DBN的肺部肿瘤计算机辅助诊断模型
2.1 算法思想
首先,以肺部CT图像为例探讨不同的隐层数和隐层节点数对DBN识别性能的影响,从而确定合适的网络结构,并以该网络结构在三个模态(CT,PET,PET/CT)肺部图像构成的样本空间构建三个单一DBN个体分类器(CT-DBN,PET-DBN,PET/CT-DBN);然后,以CTDBN为例探讨输入图像大小、RBM学习率、训练批次大小、反向传播次数对DBN识别性能的影响,从而确定合适的参数训练三个单一DBN个体分类器;最后,采用相对多数投票法对三个DBN个体分类器进行集成,得到该模型的最终结果。本文算法流程图如图1所示。
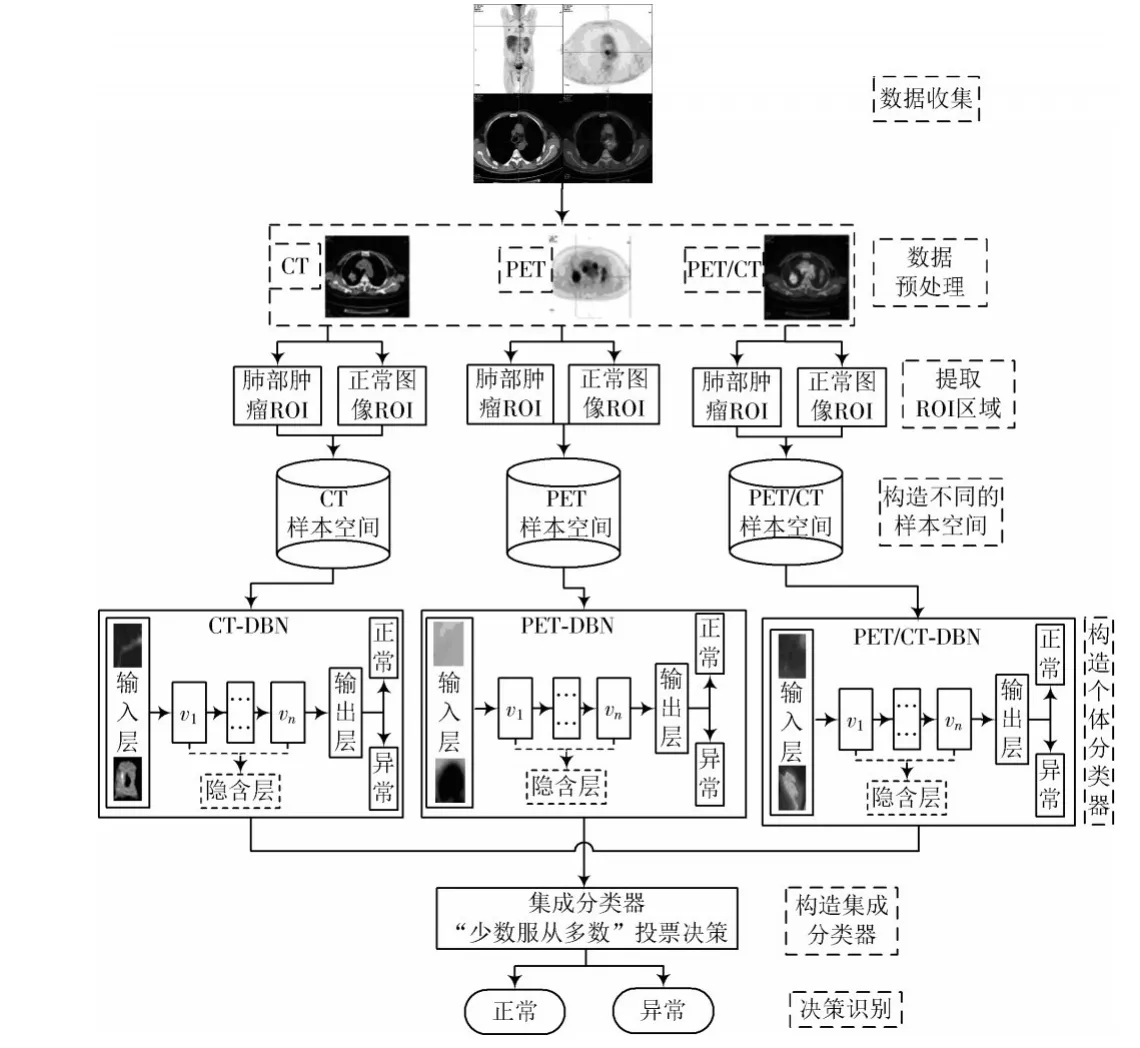
图1 本文算法流程图Fig.1 Flow chart of algorithm proposed in this paper
2.2 具体流程
基于集成深度信念网络的肺部肿瘤计算机辅助诊断模型构建的具体流程如下。
1)数据收集。从宁夏某三甲医院核医学科获取CT,PET,PET/CT三种模态的肺部图像各3 000例,每种模态的图像均包括经核医学科医生标记的1 500例异常图像和1 500例正常图像。图2为获取到的其中一幅图像,图2a)为全身CT影像;图2b)为肺部肿瘤的PET影像;图2c)为肺部肿瘤的CT影像;图2d)为肺部肿瘤的PET/CT融合影像。
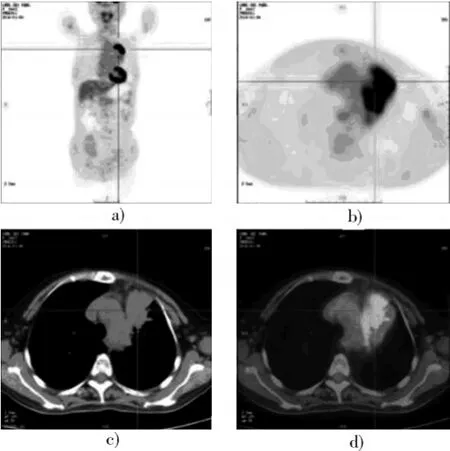
图2 CT,PET,PET/CT原始图像Fig.2 Original CT,PET and PET/CT images
2)图像预处理。分别对三个模态的图像一一对应地截取ROI区域,三个不同模态一一对应同一患者的不同影像数据,以保证后续集成实验的可行性和可操作性;最后将截取的三个模态图像归一化为28×28和48×48大小,以保证后续实验的统一性。预处理后的部分图像如图3所示。

图3 预处理后部分图像Fig.3 Part of preprocessed images
3)构造不同的样本空间。分别从CT,PET,PET/CT三个模态的图像中随机抽取300例作为测试集,其余2 700例作为训练集。构建CT,PET,PET/CT三个不同的样本空间集,DBN针对三个模态的样本集进行训练和测试。
4)构建单一DBN个体分类器。在三个模态(CT,PET,PET/CT)肺部图像构成的样本空间构建三个单一DBN个体分类器(CT-DBN,PET-DBN,PET/CT-DBN)。
5)构建集成DBN。对三个DBN个体分类器进行集成,构建集成DBN模型。
6)决策识别。采用相对多数投票法得出模型的最终分类决策结果,从识别精度、训练时间、灵敏度和特异度等方面比较三个单一DBN个体分类器和集成DBN在肺部肿瘤计算机辅助诊断中的整体性能。
2.3 关键技术
2.3.1 单个DBN分类器构建
本文首先以CT图像为例探讨不同的网络结构,即不同的隐含层数和不同的隐含层节点数对DBN识别精度和训练时间的影响,从而确定合适的网络结构并以该网络结构在不同的样本空间(CT,PET,PET/CT)构建三个单一DBN个体分类器(CT-DBN,PET-DBN,PET/CTDBN);然后以CT-DBN为例探讨DBN模型中输入图像大小、RBM学习率、反向传播次数和训练批次大小对识别精度、训练时间、灵敏度和特异度等方面的影响,根据实验结果选取合适的参数进行后续的集成实验。
由于CT图像成本最低,且CT-DBN的识别率较PETDBN和PET/CT-DBN识别率低,所以以CT图像为例探讨DBN网络结构和参数对DBN识别性能的影响更为合适。
2.3.2 集成DBN构建
本文通过实验确定了单一DBN个体分类器的模型结构和参数,在不同的样本空间建立三个相对独立的DBN分类器(CT-DBN,PET-DBN,PET/CT-DBN)。在此基础上集成三个DBN模型得到最终的识别结果,即三个DBN个体分类器分别对肺部影像进行分类识别,然后采用相对多数投票法对三个识别结果进行投票,根据投票得到的票数结果进行决策,将票数最多的分类结果作为该样本的最终分类。
3 仿真实验
3.1 实验环境
软件环境:Windows 7操作系统,MatlabR 2013a;硬件环境:IntelⓇCore(TM)i5 4670-3.40 GHz,8.00 GB内存,500 GB硬盘。
3.2 实验结果分析
以下实验结果均为相同实验环境下5次相同实验的均值。
3.2.1 DBN网络结构探讨实验
本实验以CT图像为例探讨不同的DBN网络结构对其识别性能的影响。通过改变隐含层数和隐含层节点数来观察DBN识别精度和训练时间的变化,从而为后续实验选择合适的DBN网络结构。
1)隐含层数对DBN识别精度和训练时间的影响
本实验对不同的网络层数进行探讨,选择合适的网络层数以提高DBN的学习效率。本实验固定每个隐含层的节点数为100,设定隐含层层数分别为 1,2,3,4,实验结果如表1所示。
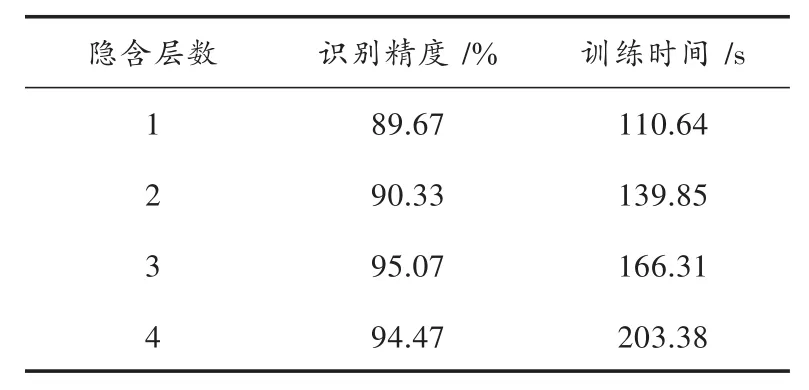
表1 不同隐含层数的实验结果Table 1 Experimental results of different hidden layer numbers
实验结果表明,随着隐含层数的增加,DBN识别精度的变化趋势为先上升后下降,层数为3时识别率最高,同时训练时间呈现明显的上升趋势,在可承受的范围之内。当隐含层数为4时,其识别率相比隐含层数为3时的识别率低,出现过拟合现象。
2)隐含层节点数对DBN识别精度和训练时间的影响
本实验对不同的隐含层节点数进行探讨,选择合适的隐含层节点数以提高DBN的学习效率。本实验固定隐含层数为3,设定隐含层节点数分别为50-50-50,100-100-100和200-200-200。实验结果如表2所示。
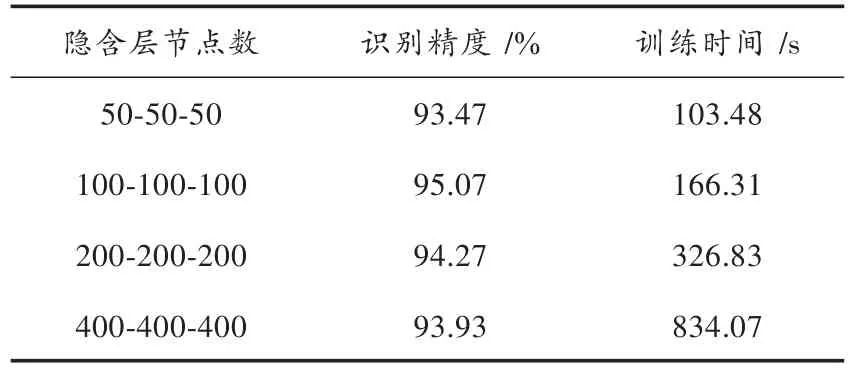
表2 不同隐含层节点数的实验结果Table 2 Experimental results of different hidden layer node numbers
实验结果表明,随着隐含层节点数的增加,DBN识别精度的变化趋势为先上升后下降,训练时间呈现明显的上升趋势,隐含层节点数为100-100-100时识别率最高,同时训练时间也在可承受的范围之内。当隐含层节点数为200-200-200和400-400-400时,其识别率相比隐含层节点数为100-100-100时的识别率低,出现过拟合现象。通过探讨不同DBN模型结构对其识别性能的影响,考虑识别精度和训练时间,构建隐含层数为3,隐含层节点数为100-100-100的DBN模型,并以此模型结构构建三个单一DBN个体分类器。
3.2.2 DBN参数微调实验
1)输入图像大小对DBN识别精度和训练时间的影响
本实验为探讨输入图像大小对DBN性能的影响,选取28×28和48×48大小的图像作为输入样本。实验结果如图4所示。
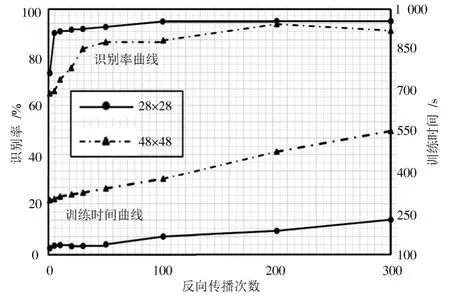
图4 输入图像大小对识别性能的影响Fig.4 Influence of input image size on recognition performance
实验结果表明,随着反向传播次数的增加,DBN的识别率均呈现上升趋势,并能够保持较高的识别水准;但是28×28图像的识别率整体上高于48×48图像,48×48图像的训练时间较28×28图像更长,且随着反向传播次数的增加训练时间增长的趋势更明显。综合考虑识别精度和训练时间,28×28大小的图像更适合作为DBN的输入图像。
2)RBM学习率对DBN识别精度和训练时间的影响
本实验选取0~1之间不同大小的学习率。实验结果如图5所示。
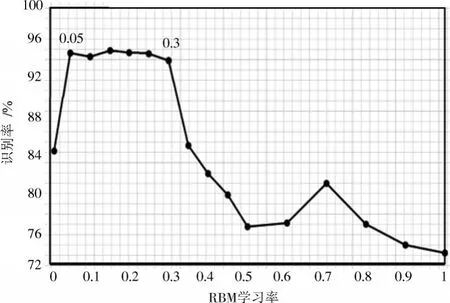
图5 RBM学习率对识别性能的影响Fig.5 Influence of RBM learning rate on recognition performance
实验结果表明,学习率在[0.05,0.3]之间时,识别率较高且结果相对稳定,所以固定RBM学习率ε=( 0.05+0.3 )2≈0.18。
3)RBM训练批次大小和反向传播次数对DBN识别精度和训练时间的影响
在RBM训练过程中通常选择一种比较高效率的方法,即将训练集分批进行权值更新,这将大大提高RBM训练速度。本实验选取训练批次大小分别为10,20,50;反向传播次数分别为 1,5,10,20,30,50,100,200,300。探讨DBN识别精度和训练时间随反向传播次数的变化,结果如表3所示。
实验结果表明,随着反向传播次数的增加,DBN的识别精度呈现明显的上升趋势;当反向传播次数达到100时,DBN识别精度达到95%左右,且在此基础上再次增加反向传播次数,其识别精度不会出现过拟合现象,能够一直保持较高的识别水准,从而也印证了DBN网络结构的稳定性。同时DBN的训练时间会随着反向传播次数的增加逐步上升,当反向传播次数相同时,批次越小,DBN训练时间越长,识别精度相对较高;但是反向传播次数达到100之后,批次大小对识别精度的影响减小,即无论批次大小,DBN识别精度均保持较高水准。此现象说明当实验能够确保较高的反向传播次数时,可以在一定范围内适度增加训练批次大小。
通过探讨不同DBN模型参数对其识别性能的影响,考虑识别精度和训练时间,为实现后续集成实验的可行性,统一选取后续实验的输入图像大小为28×28,RBM学习率为0.18;同时为提高集成实验中个体学习器,即三个单一DBN个体分类器的差异性,CT-DBN,PET-DBN,PET/CT-DBN随机选取训练批次大小分别为10,50,20。
3.2.3 集成DBN与单个DBN识别性能对比实验
为了对比集成DBN与三个单一DBN的整体性能,本实验首先从识别精度、训练时间、灵敏度和特异度四个方面对三个单一DBN的识别性能进行了探讨;然后,进行集成实验,集成三个单一DBN得到集成DBN的识别结果;最后,对比分析集成DBN与三个单一DBN的识别性能。实验结果如表4所示。
通过对三个单一DBN识别性能的探讨,实验结果表明:
1)CT-DBN随着反向传播次数的增加识别精度呈上升趋势,当反向传播次数达到100时,识别率达到95%左右,且在此基础上再次增加反向传播次数,其识别精度不会出现过拟合现象,能够一直保持较高的识别水准。
2)PET-DBN的识别率相对较高,在反向传播次数达到50之后基本收敛,识别率达到99%左右,且能够一直保持较高的识别水准。PET-DBN能够达到较高识别率的原因在于PET属于功能影像,代谢功能异常的区域,即病灶部位在PET影像上会呈现明显的亮斑,易于辨识;而正常区域则不会存在亮斑,其影像基本能够保持相同灰度大小,所以PET影像易于辨识,PET-DBN的识别能力更强。
3)PET/CT-DBN在反向传播次数达到30时,识别率达到98%左右,且随着反向传播次数的继续增加能够达到99%左右的识别率。PET/CT是CT图像和PET图像的融合图像,融合了CT和PET的特点,能够使图像更加清晰,从何能够达到较高的识别精度。
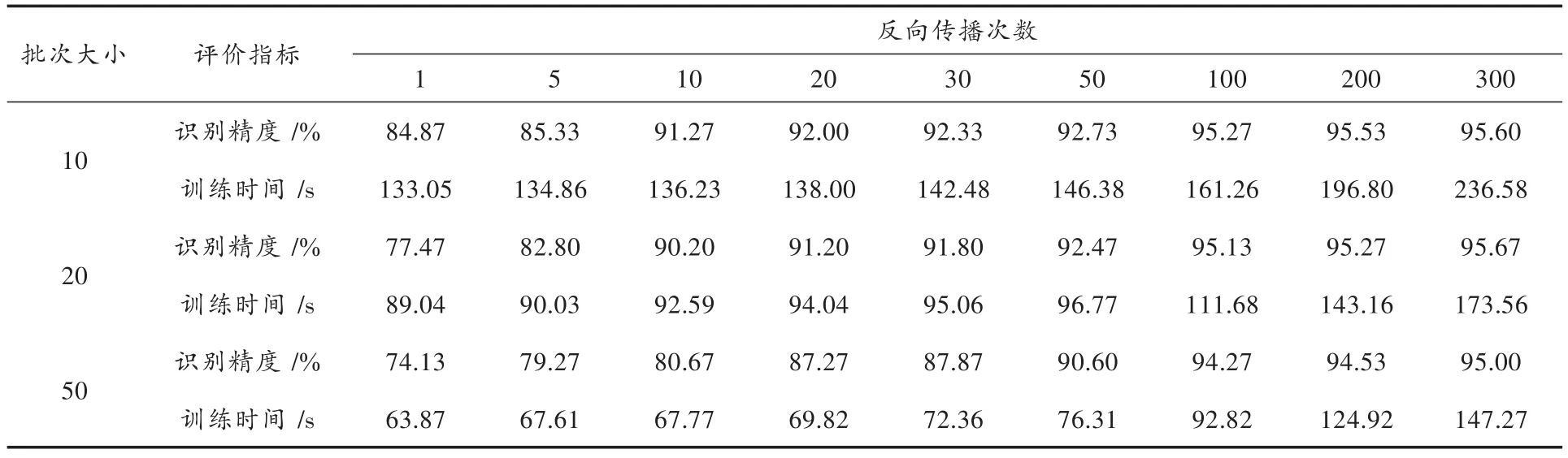
表3 不同预训练批次大小和反向传播次数的实验结果Table 3 Experimental results of different pre-training batch sizes and back propagation times
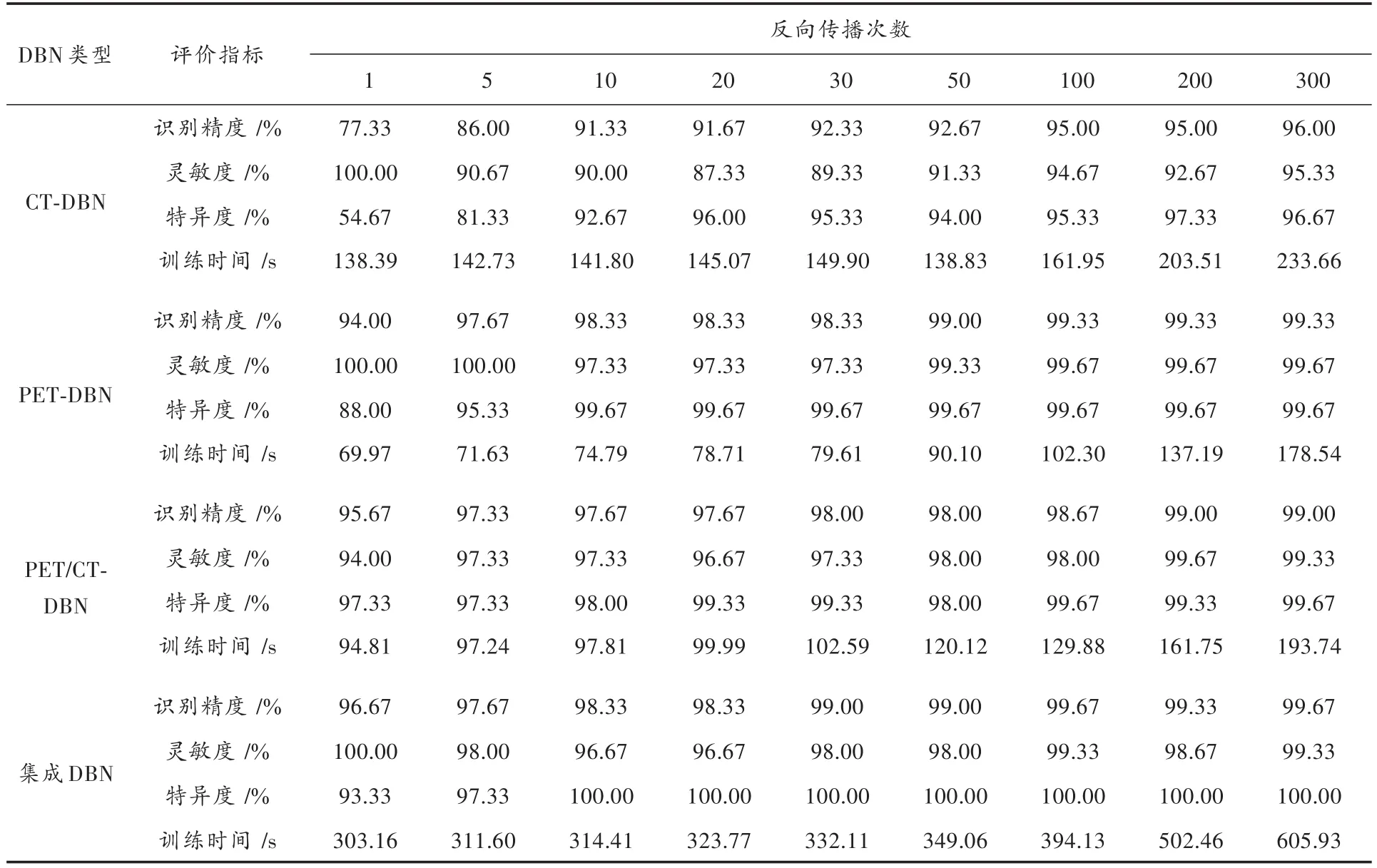
表4 集成DBN与单个DBN识别性能比较Table 4 Comparison for recognition performances of integrated DBN and single DBN
对比集成DBN与三个单一DBN的识别性能,实验结果表明,集成DBN对肺部肿瘤的计算机辅助诊断能够达到99.67%的识别精度。集成DBN的识别精度相对于CT-DBN有大幅度的提升,相对于PET/CT-DBN有较低程度的提升;而相对于PET-DBN略有提升或者与其持平甚至略低于PET-DBN的识别率。因为PET-DBN的识别性能是三个单一DBN个体分类器中最优良的,能达到较高的识别精度,所以集成DBN对于PET-DBN识别性能的提升效果不明显;但是集成DBN的识别性能整体上优于三个单一DBN个体分类器。虽然集成DBN的训练时间明显高于三个单一DBN,但是降低训练时间可以通过改善实验环境和进一步优化模型参数来实现。通过集成DBN与单一DBN个体分类器识别性能的对比,得出如下结论,集成DBN比单一DBN对肺部肿瘤的识别性能更优良,能够协助影像科医生进行肺部肿瘤的计算机辅助诊断。
4 结语
本文通过实验确定合适的模型结构并以该模型结构在不同的样本空间(CT,PET,PET/CT)构建三个单一DBN个体分类器(CT-DBN,PET-DBN,PET/CT-DBN),然后采用相对多数投票法集成三个单一DBN,得出肺部肿瘤计算机辅助诊断的最终结果,有效地提高了学习系统的泛化能力,解决了过拟合问题。通过比较三个单一DBN个体分类器和集成DBN在肺部肿瘤计算机辅助诊断中的整体性能,结果表明,集成DBN比单一DBN个体分类器对肺部肿瘤的识别性能更优良,能够有效解决目前基于DBN的肺部肿瘤计算机辅助诊断模型存在的识别精度不高和漏诊率、误诊率降低困难等问题,能够为影像科医生提供准确率较高的、可供参考的诊断结果。



