孟叶 于忠清 周强
摘 要: 股票价格指数是衡量整个股票市场当前行情的重要指标,通常对指数内所有个股的涨跌幅进行加权平均得到,因此股票指数能够及时准确地反映当前市场的动向走势。对沪深300指数的历史行情数据进行建模,通过挖掘大盘指数的涨跌幅与个股的涨跌比之间的关系,利用聚类算法确定对市场影响较大的指数涨跌幅集合[G],将其作为研究关键。运用集成学习的算法思想,选取K?近邻、梯度提升和自适应提升这3个分类器,通过改进的投票算法聚合成一个新的分类器模型,对指数行情数据进行学习分类,从而对[G]的出现进行预测,改进的投票算法综合考虑了弱分类器本身的分类效果,分类效果得到提升。实验结果表明,与原模型相比,新聚合的模型在一定程度上提升了股指预测的准确度,对于沪深300股指的预测具有指导作用。
关键词: 股指预测; 集成学习; 模型聚合; 机器学习; 分类器; 指数行情
中图分类号: TN911?34; C32 文献标识码: A 文章编号: 1004?373X(2019)19?0115?04
Abstract: The stock index can reflect the overall development trend of the current stock market. The historical quotations of the CSI 300 index were modeled in this experiment. By mining the relationship between the rise and fall ratio of the market index and the rise and fall ratio of individual stock, the clustering algorithm is used to determine the set G, which has a large impact on the market and is taken as the key to study. In the course of experiment, the algorithms of KNN Classifier, Gradient Boosting Classifier and Adaboost Classifier are integrated as a more effective classifier model, and the index market data is classified to predict the appearance of G. The improved voting algorithm comprehensively considers the classifying effect of the weak classifier, so its classifying effect is improved. The experimental results show that, in comparison with the original model, the new polymerized model can improve the accuracy of the stock index forecast to a certain extent, which has a guiding effect on the short?term forecast of CSI 300 index.
Keywords: stock index prediction; integrated learning; model aggregation; machine learning; classifier; index marketing
0 引 言
利用机器学习进行投资分析的研究最早起源于19世纪末的美国,其研究结果也被证明切实可行。随着研究的深入,机器学习在金融领域得到认可并被大量应用于股市交易领域,主要算法有支持向量机(SVM)、人工神经网络(ANN)、随机森林(Random Forest)、隐马尔可夫模型(HMM)等,主要用于对股票趋势进行预测。文献[1]提出结合股票新闻事件的方法对时间序列数据进行准确预测,这是对股票进行文本分析的尝试。文献[2]将4种机器学习算法应用于股指预测,包括人工神经网络、支持向量机、随机森林和朴素贝叶斯等算法,对数据预处理进行改进,结果表明随机森林的性能整体优于另外三种模型。国内利用机器学习进行投资分析的研究在21世纪才开始兴起,相关研究较国外少,研究方法大都是根据已有模型进行改进并在中国股市进行实验。文献[3]将支持向量机和小波分析相结合,在数据去噪方面具有一定优势。文献[4]设计了一套将机器学习和技术指标相结合的量化投资策略,策略的年化收益均跑赢大盘指数并且各项风险指标均优于大盘指数,是一个高收益低风险的稳健策略。
本文对指数的涨跌行为进行预测,但对涨跌重新定义:当大盘的涨跌幅达到一定程度时,市场中的个股涨跌有了明显的趋向性,个股有较大概率跟随大盘走势,通常发生于股指大涨或大跌之时,此时大盘指数的指导作用开始显现,若能对其进行预测,对于投资者规避风险,投资获利有一定指导作用。实验主要分为聚类和预测两个步骤:
1) 聚类:数据样本为沪深300指数2015—2018年的历史涨跌幅数据与通过统计得到的对应当日个股涨跌比数据。通过聚类算法K?means根据个股涨跌比对大盘涨跌幅进行分类,根据聚类结果和股指涨跌幅对每日股指进行标记,将原本涨跌的二分类结果转化成涨跌类别的多分类结果。
2) 预测:数据样本为上文已经通过聚类标记好涨跌类别的历史交易数据,并根据基本行情数据计算出近50个股票技术指标辅助预测;将3个经典的机器学习分类器模型通过加权投票的方式聚合成为一个新的分类器,提升分类效果,预测下一个交易日的股指涨跌类别。
1 算法思想
1.1 Adaboost算法
Adaboost算法是在文献[5]中提出的,是boosting方法中最优性能的代表算法。首先赋予[n]个训练样本相同的权重,从而训练出一个基分类器,之后进行预先设置的[T]次迭代,每次迭代将前一次分类器中分错的样本加大权重,使得在下一次迭代中更加关注这些样本,从而调整权重改善分类器,经过[T]次迭代得到[T]个基分类器,最终将这些基分类器线性组合得到最终分类器模型。
1.2 投票算法
投票(voting)广泛用于对离散型数据输出分类器的集成。集成学习中的投票方法[6]主要有:多数表决、简单多数表决和带权重的投票。多数表决即基分类器的某一预测结果出现的次数超过了半数,则该预测结果为最终结果;若没有超过半数的结果,则该集成分类器没有结果输出。简单多数表决与多数表决基本类似,即只要哪个基分类器的预测结果出现次数最多则为最终结果,无需过半数。带权重的投票就是对每一个基分类器的结果分配一个权重,最终结果为预测结果与权重的乘积之和的最高者。本次实验采用带权重的投票方式并对其进行改进,将多数投票和带权重投票结合,对弱分类器利用多数投票产生一列新的预测结果并将其与弱分类器得到的结果进行加权平均,权重按照各自的预测精度成比例设置,最终结果即为预测结果与权重的乘积之和的最高者。
2 实 验
2.1 数据获取
本次实验所需要的数据样本包括:2015—2018年沪深300成分股每个交易日的涨跌幅数据;沪深300指数2015年4月8日—2018年4月13日的历史交易行情数据,共640行数据,数据均通过Tushare接口进行获取。
此次实验的股指预测是根据当前交易日的行情数据对下一个交易日的涨跌类别进行预测。通过将技术指标数据进行量化建模,利用分类器进行训练:基于已获取的收盘价、成交量等指标计算出如MACD(指数平滑移动平均值)、MASS(梅斯值)、EWMA(指数加权移动平均值)等47个技术指标以帮助分类器进行训练,提升预测精度。
2.2 K?means聚类
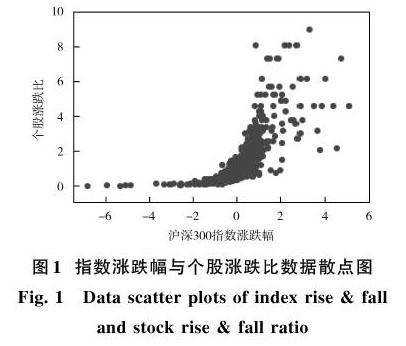
沪深300指数的涨跌幅与沪深300成分个股涨跌比间的关联关系若只通过观察数据样本则较难得到,因此先将数据进行可视化处理,绘制散点图如图1所示。
通过散点图可以发现:指数涨跌幅与个股涨跌比存在某种线性关系,但并非简单的一元线性关系;数据点的分布呈现一定规律——散落在涨跌幅(-2%,2%)的数据点最为密集;个股涨跌比最高不超过10,最低却趋近于0,指数跌涨比最高达到100,远远大于10,表明指数大跌时个股的普跌性远大于指数大涨时个股普涨性,也说明我国股市的抗压能力较弱,投资者面临指数大跌时的恐慌与非理性情绪会造成市场的进一步恶化。
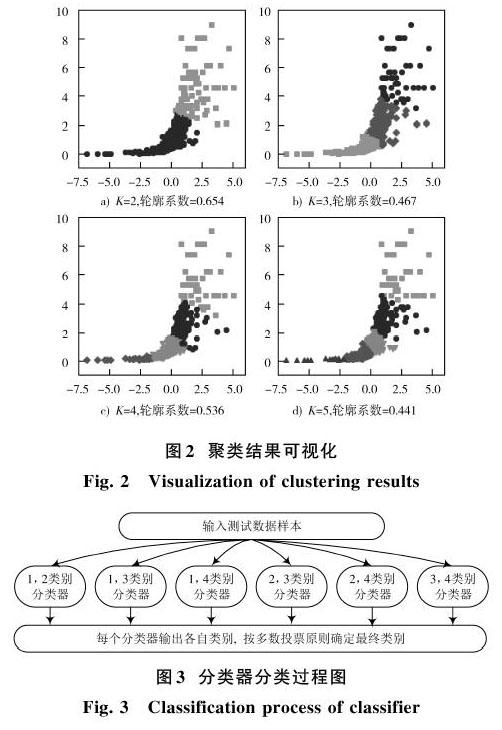
对图中数据点进行K?Means聚类,可视化展示如图2所示。
综合考量轮廓系数和聚类效果图得出聚类数目为4时聚类效果最好,符合实验的目的——将对市场影响较大的涨跌幅都聚为一类(图中红色与绿色部分),样本分布也较为均匀。
2.3 分类与融合
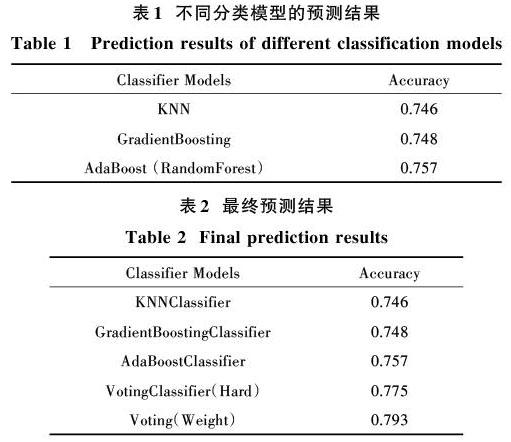
本次实验选用的分类器模型——K?NearestNeighborClassifier,GradientBoostingClassifier,AdaBoost Classifier。由于分类器模型均是处理二分类问题的模型,而本次实验中涉及到了4个类别,因此采用迭代分类的策略[7]:首先各自训练[C24]=6个分类器模型,每次选择2个类别的数据样本进行训练,共进行6次分类操作。6个分类器模型训练完毕后对同一测试样本进行预测,最终预测结果以多数投票原则确定,即分类器输出各自分类结果,输出最多的即为最终类别,具体分类操作如图3所示。
由于本次实验的目的是预测出对市场影响较大的指数涨跌幅集合即涨跌类别中的1,4类别,因此预测结果的评判标准为1,4类别的预测准确率。
2.4 股指预测
本次实验选用3个分类器模型:K?NearestNeighborClassifier,GradientBoostingClassifier,AdaBoostClassifier,其中,GradientBoostingClassifier和AdaBoostClassifier是基于boosting算法的分类器,分类效果较为理想,通过for?loop对模型中的参数进行调参,得到预测精度最高的参数。对分类器都做调参优化,得到的预测结果如表1所示,3个分类器的准确度都大于0.5,所以原则上都是有效的分类器,可以作为集成学习的第一层分类器。
对分类器进行集成学习,这里使用VotingClassifier(投票分类器)对3个分类器进行第一次集成,由于本次实验只有3个基分类器,因此不会产生投票数相同的情况。直接使用多数投票方法,使用投票分类器的预测结果为0.775,整个模型的预测精度得到提升。再将多数投票分类器与前3个基分类器按预测精度分配权重,并对4个分类器的结果取加权平均。
2.5 结果分析
最终经过加权投票分类后的预测精度为0.793,与4个基分类器的预测精度结果如表2所示。
由表2可以看出,集成后的分类器预测效果大大提升,相比弱分类器中准确度最高的AdaboostClassifier提升了4.7%,最终分类准确度为0.793。对于股市预测而言,一般在0.56以上的预测结果即被认为是很好的分类结果[8],对于股市投资具有一定指导意义。实验通过挖掘大盘指数涨跌幅与个股涨跌比间的联系确定了对市场影响较大的涨跌幅集合,通过构建分类器模型对指数大涨和大跌进行预测,对于投资者而言,利用预测结果进行辅助决策,不仅避免投资过程中非理性因素的干扰,而且对于降低投资风险,提高投资收益都具有一定意义。
3 结 论
本文的创新点在于:
1) 通过K?means聚类算法挖掘出指数涨跌幅与个股涨跌比间的内在联系,依据个股涨跌比将大盘涨跌幅进行聚类,得到多个涨跌类别,并选择对市场影响较大的涨跌类别作为预测重点。
2) 将集成学习的算法思想运用于股指预测当中,对股指预测不只局限于涨跌这两种情况——将涨跌行为定义为多类别问题,对股指“大涨”和“大跌”进行预测,与单纯涨跌预测相比,预测精度得到提升。
3) 通过将传统的股票技术分析进行程序量化,基于原数据基本行情指标计算出近50个技术指标辅助决策,使得学习器有更佳的学习性能,预测精度得到提升。
实验结果较为理想,与文献[9]在利用支持向量机对沪深300股指的涨跌进行预测的实验结果0.595相比,有了较高的提升,基于集成学习预测股市行情总体而言是有效的。由于中国股市本身就是一个弱式有效市场,政策性、突发性的事件会对股市行情产生很大影响,因此预测模型还存在一定的局限性,下一步的工作就是完善模型,提升现有效果。
参考文献
[1] YOO P D, KIM M H, JAN T. Machine learning techniques and use of event information for stock market prediction: a survey and evaluation [C]// International Conference on Computational Intelligence for Modelling, Control and Automation and International Conference on Intelligent Agents, Web Technologies and Internet Commerce Vol. IEEE Computer Society: IEEE, 2005: 835?841.
[2] PATEL J, SHAH S, THAKKAR P, et al. Predicting stock and stock price index movement using trend deterministic data preparation and machine learning techniques [J]. Expert systems with applications, 2015, 42(1): 259?268.
[3] 李元诚.股市预测中的小波支持向量机方法研究[J].计算机科学,2003,30(10):215?217.
LI Yuancheng. Research on wavelet support vector machine in stock market prediction [J]. Computer science, 2003, 30(10): 215?217.
[4] 李斌,林彦,唐闻轩.ML?TEA:一套基于机器学习和技术分析的量化投资算法[J].系统工程理论与实践,2017,37(5):1089?1100.
LI Bin, LIN Yan, TANG Wenxuan. ML?TEA: a set of quantitative investment algorithms based on machine learning and technical analysis [J]. Systems engineering—theory & practice, 2017, 37(5): 1089?1100.
[5] FREUND Y, SCHAPIRE R E. A decision?theoretic generalization of on?line learning and an application to boosting [J]. Journal of computer and system sciences, 1997, 55(1): 119?139.
[6] 周星,丁立新,万润泽,等.分类器集成算法研究[J].武汉大学学报(理学版),2015,61(6):503?508.
ZHOU Xing, DING Lixin, WAN Runze, et al. Research on classifier ensemble algorithms [J]. Journal of Wuhan University (Natural science edition), 2015, 61(6): 503?508.
[7] 杨新武,马壮,袁顺.基于弱分类器调整的多分类Adaboost算法[J].电子与信息学报,2016,38(2):373?380.
YANG Xinwu, MA Zhuang, YUAN Shun. Multi?class adaboost algorithm based on the adjusted weak classifier [J]. Journal of electronics & information technology, 2016, 38(2): 373?380.
[8] GEORGE Tsibouris, MATTHEW Zeidenberg. Testing the efficient markets hypothesis with gradient descent algorithms [M]. [S. l.]: Johnwiley & Sons, 1995.
[9] 任东海.基于支持向量机的股指变动方向预测[D].济南:山东大学,2016.
REN Donghai. Predicting direction of stock price index movement based on support vector machines [D]. Jinan: Shandong University, 2016.



