王 哲,刘贵容,彭润亚
(重庆邮电大学移通学院,重庆 401520)
0 引 言
近年来,随着互联网应用的不断深入,网络成为一个多元开放平台,网络上的舆情直接影响人们生活、工作以及社会的稳定。在网络舆情中,微博热点是一种描述社会热点问题突发事件等的观点和建议[1-3]。一些积极的微博热点可以推动社会的前进,另一些负面的微博热点如反动的思想、虚假的信息迅速扩散,会影响社会稳定和人身安全,因此对微博热点的预测及监控成为当前一个重大的研究课题[4-6]。
准确的微博热点建模和预测可以帮助政府对负面事件进行及时控制,维持社会的稳定,相对于一般的博客,微博内容的实时性更强,同时其与移动终端结合,扩散速度更快,传统微博热点建模和预测方法为多元回归分析,多元回归分析从微博热点数据中提取一些特征项,研究特征之间的变化关系,然后建立一种描述特征之间变化关系的数学表达式,从而实现微博热点的预测[7]。但是多元回归分析主要反映特征之间的线性变化关系,实际上微博热点特征之间同时存在着非线性变化关系,这样使得多元回归分析的微博热点预测准确性差。随后提出基于聚类分析的微博热点建模方法,其是一种定量分析方法,聚类分析方法可以对微博热点数据之间的关联性进行挖掘,首先提取微博热点问题中的关键词,并对关键词进行打分,然后对微博热点类别进行划分,该方法只能区别微博热点的类型,对微博热点将来变化的趋势无法预测,因此缺陷十分明显[8]。随后出现了基于灰色理论的微博热点预测方法、基于神经网络的微博热点预测方法,灰色理论需要的微博热点样本小,预测速度快,但是其微博热点预测误差比较大[9]。神经网络需要的微博热点样本数据多,此时,其微博热点预测精度高;反之,如果微博热点样本数量少,那么预测结果不稳定,而且建模时间比较长[10-11]。随着现代统计学理论的发展,近年来出现了大数据分析方法,通过对问题的原始数据进行分析,然后采用机器学习算法对数据进行分析,找到隐藏在其中的变化规律,在网络流量、电力负荷预测等领域得到了成功的应用[12]。
本文结合微博热点的周期性、随机性、数据规模大等特点,针对当前微博热点建模与预测方法存在的缺陷,提出基于大数据分析方法的微博热点建模与预测方法,并与其他微博热点预测方法进行仿真对比测试,本文方法的微博热点单步预测精度超过95%,多步预测误差也处于实际范围内,相对于当前其他微博热点预测方法,预测误差更小,建模与预测效率得到提升。
1 建模与预测原理
基于大数据分析方法的微博热点建模与预测原理为:首先收集微博热点的相关数据,如历史点击率、回帖数等,然后对数据进行聚类分析,找到与待预测点相关的样本作为训练样本,最后采用极限学习机对训练样本进行学习,并确定极限学习机相关参数,构建微博热点预测模型,并对其性能进行分析,具体如图1 所示。
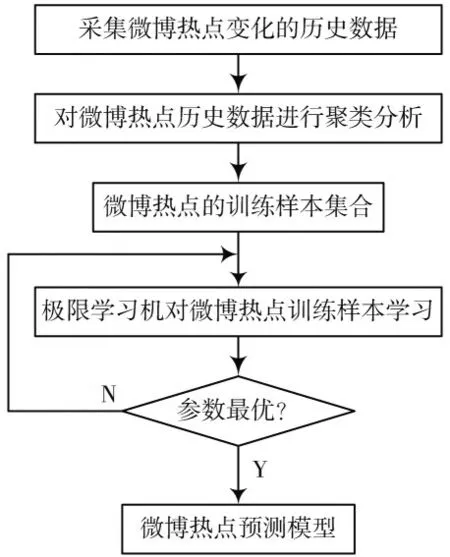
图1 基于大数据分析方法的微博热点建模与预测原理Fig.1 Principles of microblog hotspots modeling and forecasting based on large data analysis
2 算法分析
2.1 微博热点数据的聚类分析算法
当前聚类分析的方法很多,如模糊聚类算法、K 均值聚类算法等,相对于其他聚类算法,K 均值聚类算法的迭代次数少,可以很好地将微博热点原始数据根据聚类中心划分为多种类型,其具体工作步骤为:
Step1:设原始微博热点数据集合为I={xi,i=1,2,…,n},共有K个类别,它们均有一个聚类中心,即Zj(I),j=1,2,…,k。
Step2:根据式(1)计算微博热点样本和每一个聚类中心之间的距离D(xi,Zj(I)):

Step3:如果满足条件D(xi,Zk(I))=min{D(xi,Zj(I))},则表示样本xi属于该类样本集合。
Step4:采用式(2)对聚类结果好坏进行评价。
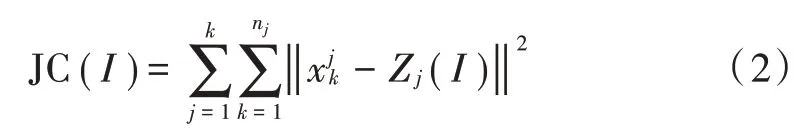
Step5:如果满足‖JC(I)-JC(I-1) ‖<ζ,那么聚类终止,否则迭代次数增加,采用式(3)计算新聚类中心,并转到Step2 继续迭代。
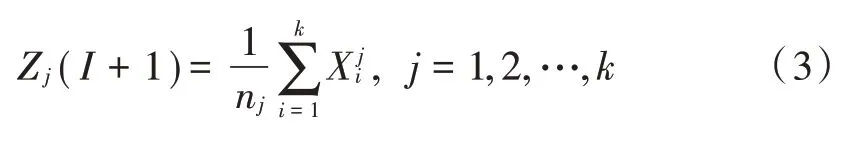
经过以上步骤,可以将待预测的微博热点样本划归到相应的微博热点类别中,将该类别中所有的微博热点样本作为训练样本。
2.2 极限学习机的微博热点建模与预测
构建微博热点的训练样本,那么采用极限学习机可以建立如下预测模型:

要建立最优微博热点预测模型,首先要得到权值βN,根据KKT 最优化条件解得:
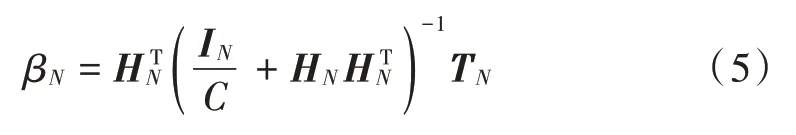
由于微博热点变化具有非线性、随机性,因此引入满足Mercer′s 条件的核矩阵,具体为:
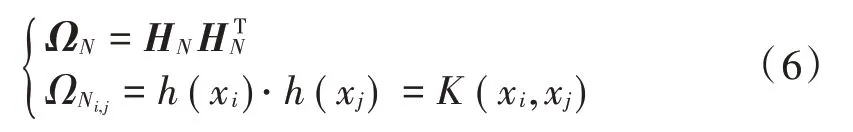
式中K(xi,xj) 表示核函数。
由于径向基核函数具有通用性,而且十分简单,因此选择其为K(xi,xj),具体为:
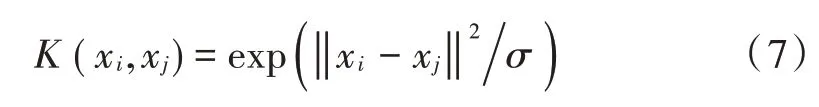
基于极限学习机的微博热点输出结果为:
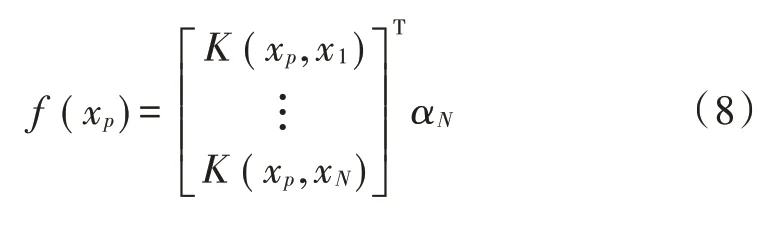
3 微博热点建模与预测性能的验证
3.1 微博热点原始数据
为了分析大数据分析方法的微博热点建模与预测效果,选择当前一个微博热点话题作为研究对象,其为“公交车抢方向盘事件”,其变化曲线如图2 所示,最后200 个数据作为验证数据,其他作为训练数据。为了使本文方法的实验说服力更强,选择文献[13-14]的微博热点预测模型进行对比实验。
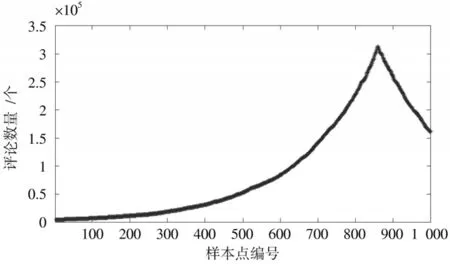
图2 “公交车抢方向盘事件”的样本数据Fig.2 Sample data of "Bus steering wheel robbery incident" event
3.2 微博热点预测结果分析
三种方法的“公交车抢方向盘事件”数据预测结果如图3 所示,对“公交车抢方向盘事件”数据预测结果进行分析可知:
1)文献[13-14]的“公交车抢方向盘事件”数据预测误差大,“公交车抢方向盘事件”数据预测精度低,无法准确描述“公交车抢方向盘事件”数据的随机性变化态势,难以获得理想的微博热点预测效果。
2)本文方法的“公交车抢方向盘事件”数据预测精度高,预测误差低于文献[13-14]的微博热点预测方法,主要是因为本文方法首先引入了聚类分析对“公交车抢方向盘事件”数据进行处理,选择了最优训练样本,然后引入极限学习机对“公交车抢方向盘事件”的变化特点进行建模,提高了“公交车抢方向盘事件”的预测精度。
统计三种方法的训练和测试时间(单位:ms),结果如表1 所示。从表1 可知,本文方法的微博热点建模的训练和测试时间更短,这是因为通过引入聚类分析对微博热点样本数据进行预处理,减少了训练样本的规模,加快了聚类分析对微博热点建模速度。
3.3 本文方法的通用性测试
为了分析本文方法的微博热点预测通用性,采用当前9 个典型微博热点作为测试对象,预测精度如表2 所示。从表2 可以看出,本文方法的微博热点预测精度平均值超过了95%,达到了网络舆情监控的要求,具有较好的通用性,但是对比方法的微博热点预测结果不稳定,微博热点平均预测精度低,难以获得较好的微博热点结果预测。
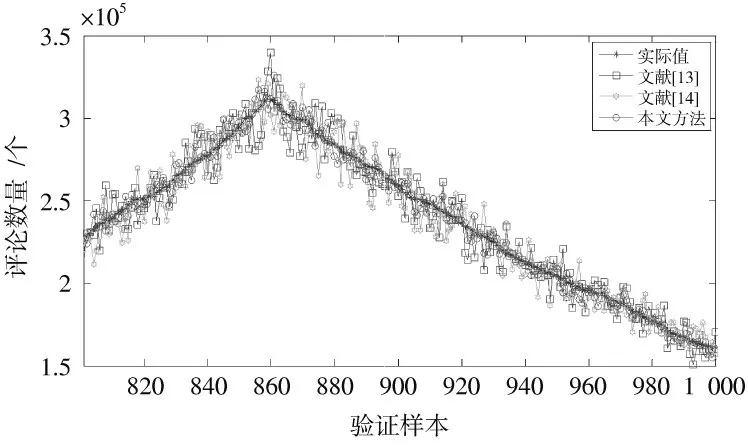
图3 “公交车抢方向盘事件”数据的预测结果Fig.3 Prediction results of "Bus steering wheel robbery incident" event data
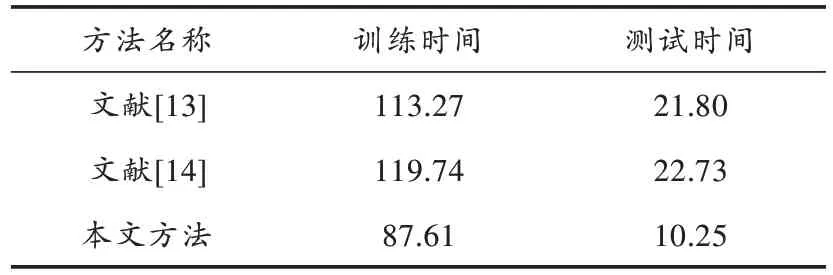
表1 微博热点训练和测试时间对比Table 1 Comparison of microblog hotspot training and testing time ms

表2 微博热点预测的通用性测试Table 2 Universality testing of microblog hot point prediction method %
4 结 论
为了解决当前微博热点建模与预测过程中存在的不足,本文提出了基于大数据分析方法的微博热点建模与预测方法,并采用具体数据对其进行测试。通过引入聚类分析对微博热点样本数据进行预处理,选择重要的样本组成训练样本,减少微博热点建模计算复杂度,建模时间大幅度减少,解决了当前方法对大规模微博热点数据建模效率低的缺陷。通过引入极限学习机对微博热点样本数据的周期性、随机性变化特点进行拟合,全面描述微博热点的发展趋势,使得微博热点的预测精度得到提高,微博热点的预测误差变小,充分说明了本文方法的微博热点预测效果要优于当前微博热点的建模与预测方法,解决了当前方法微博热点预测误差大的缺陷。本文方法是一种预测精度高、速度快的微博热点建模方法,同时为其他具有相似变化特点的问题提供了一种建模预测思想,具有广泛的应用前景。



