张捷


摘 要: 极限学习机算法适应新鲜样本能力强、学习速率快,为此提出基于极限学习机算法分析图书馆读者借阅行为。但是极限学习机算法输入权重与隐层阈值随机确定,行为分析结果随机性强、可靠程度低,所以采用高适应度值遗传算法确定极限学习机算法的输入权值与阈值。高适应度值遗传算法选择算子复制两份适应度值最优个体、复制一份适应度值较优个体作为遗传种群;交叉算子选取2个适应度值最优新个体开始变异操作;确定算法最优输入权值与阈值后,提取读者借阅行为特征作为训练样本,构建图书馆读者借阅行为分析模型,测试样本代入模型得到读者借阅行为分析结果。经测试,所提方法能准确分析出高校学生频繁借阅、少量借阅等图书借阅行为。
关键词: 极限学习机; 图书馆; 输入权重; 高适应度值; 遗传种群; 借阅行为分析
中图分类号: TN911.1?34; TP391 文献标识码: A 文章编号: 1004?373X(2020)05?0121?04
Analysis of borrowing behavior of library readers
based on extreme learning machine algorithm
ZHANG Jie
(Langfang Normal University, Langfang 065000, China)
Abstract: The extreme learning machine (ELM) algorithm is ofpowerful adaptability to fresh samples and of fast learning rate. Therefore, the borrowing behavior of library readers is analyzed based on the ELM algorithm.However, the input weight and hidden layer threshold of the LEM algorithm are determined randomly, and the behavior analysis results are of serious randomness and low reliability, so the genetic algorithm with high fitness value is adopted to determine the input weight and threshold of the LEM algorithm. The selection operator of the genetic algorithm with high fitness is used to replicate two individuals with optimalfitness value and one individual with better fitness value as the genetic population, and the crossover operator is used to select two new individuals with optimal fitness values to start mutation operation. After determining the optimal input weights and thresholds of the algorithm, the characteristics of readers′ borrowing behaviors are extracted as training samples to construct the analysis model of borrowing behaviors. The test samples are subjected to the model to obtain the analysis results of readers′ borrowing behaviors. After testing, the proposed method can accurately analyze the borrowing behaviors of college students, e.g., frequent but few borrowing.
Keywords: LEM; library; input weight; high fitness value; genetic population; borrowing behavior analysis
0 引 言
图书馆应以读者借阅行为为依据开展图书资源建设与读者服务工作,所以,正确掌握读者借阅行为是有效管理图书文献资源的前提条件[1?2]。近年来,极限学习机算法在行为分析领域应用较多,在学习速率与泛化能力方面表现突出[3],很快适应崭新样本,掌握数据样本隐藏规律[4]。因此,本文采用极限学习机算法分析图书馆读者借阅行为。极限学习机算法无需计算输入权重与隐层阈值,随机输入即可,导致算法随机性强,不能快速得到符合标准的分析结果,针对这种情况,本文采用高适应度值遗传算法确定极限学习机的输入权值与阈值[5],保障极限学习机训练准确度,最后输出准确的图书馆读者借阅行为分析结果。
1 图书馆读者借阅行为分析
1.1 极限学习机算法理论
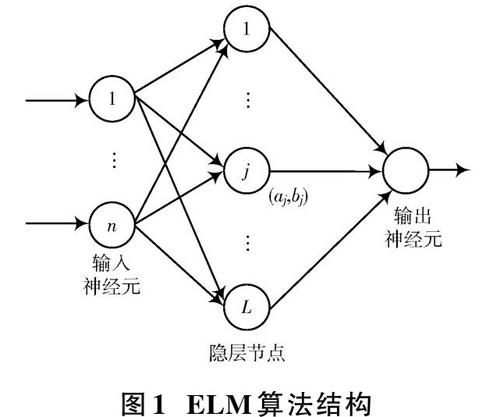
在前馈神经网络基础上构建一种机器学习方法,称为极限学习机(Extreme Learning Machine,ELM),ELM在监督学习与非监督学习方面取得了显著成效,ELM结构[6?7]如图1所示。由图1可知,结构隐层节点参数与结构不存在关联,所以无需网络迭代调整参数、训练参数较少、防止过度拟合、学习效率高是极限学习机的优点,因此,基于极限学习机算法分析图书馆借阅行为结果相对可靠、输出结果较快[8]。算法求解过程中,唯一需要定义的参数为隐层神经元数量,即可得到唯一最优解[9]。极限学习机输入权重与隐层阈值随机输入即可,算法训练数据样本时,省略调整权重与隐层阈值的环节。
已知[N]个训练样本集用[xk,ek]表示,[k=1,2,…,N],样本集输入与输出维数分别为[m]维、[n]维;样本[xk]期望输出向量为[ek],式(1),式(2)为样本集输入与输出变量表达形式:
[xk=xk1,xk2,…,xknT∈Rn] (1)
[ek=ek1,ek2,…,eknT∈Rn] (2)
定义[L]表示隐层节点数量,[gx]表示隐层激励函数,ELM算法输出形式如下:
[fx=i=1LηiVai,bi,xi=i=1Lηigai?xi+bi=η?Dx] (3)
式中[x]与[Dx]分别为输入数据与隐层输出矩阵。面对多个差异性输入数据时,多个差异性输出向量[hx]构成隐层输出矩阵[Dx]。神经网络输入层至第[i]个神经元输入权值与第[i]个隐层节点的阈值为随机分配,两参数形式为[ai=ai1,ai2,…,ainT],[bi],作用是连接第[i]个隐节点到输出权值[ηi=ηi1,ηi2,…,ηinT],[ai?xi]是两向量内积。
定义[Oi]为神经网络的学习误差,得到尽量小的输出误差是单隐层神经网络学习的主要目的,逼近相同连续[N]个样本时的误差为0,方法见式(4):
[i=1Lηigai?xi+bi=tj, j=1,2,…,N] (4)
隐层输出矩阵[D]用激励函数[gx]表示,根据式(3),式(4)可知,[Dη=T],[T]为[ti]的向量,若同时输入多个数据,多个不同输入数据下[gx]构成隐层机理函数[Vx],采用式(5)描述[Vx]与[Dx]的关系:
[Da1,…,aL,b1,…,bL,x1,…,xN=Va1?x1+b1…VaL?x1+bL???Va1?xN+b1…VaL?xN+bLN×L] (5)
[η]与[T]的表达式如下:
[η=ηT1?ηTLL×n, T=tT1?tTNN×n] (6)
极限学习机算法学习时,随机输入权值与阈值后得到确定的隐层矩阵用[D]表示,即神经网络隐层输出矩阵。此网络训练相当于求解线性系统[Dη=T]的二乘解最小值,用[η]表示。计算得到[η]极限学习机算法训练过程结束,得到权值矩阵。
极限学习机算法随机确定输入权值与隐层阈值,虽然简化计算步骤,但是用于图书馆读者借阅行为分析时精确度较低[10],输入权值与隐层阈值随机确定容易导致部分数值为0,个别隐层节点无效,另外,随机确定参数的方式提升了极限学习机的随机性[11]。综上,采用高适应度值遗传算法改进极限学习机训练过程,确定输入权值与隐层阈值,获取性能优异的极限学习机训练模型,可以提升图书馆读者借阅行为分析准确度。
1.2 高适应度值遗传算法
种群编码、适应度计算、选择、交叉、变异是遗传算法的主要步骤,高适应度值遗传算法改进选择算子与交叉算子步骤,提升遗传算法输出解的精准度。
1.2.1 高适应度值选择算子
通过选择方式获取适应度优异的染色体个体,优秀个体很大几率成为父代,通过交叉与变异产生子代。高适应度值选择算子与以往轮盘赌选择方式不同,总结方法为:定义[n]表示初始种群,随后求取全部染色体的适应度值并排序(由大到小),均分种群规模,复制两份适应度值最优个体,复制一份适应度值较优个体,染色体中适应度值最小的种群不复制[12]。这种方式令适应度值较大种群存在更大几率进入交叉阶段,种群大小没有改变,与优胜劣汰原则一致,该方法有效避免了轮盘赌选择的随机误差。染色体适应度值排序如图2所示,其中,[f]表示染色体适应度值,由大到小排列。
1.2.2 高适应度值交叉算子
采用高适应度值方法选择遗传算法算子,提升新种群适应性能,在新种群中交叉得到两个染色体作为父代,置换父代染色体基因后得到两个新个体[13]。新个体携带父代特征,由于选择算子在一定程度上破坏了种群多样性,所以采用高适应度值方法获取交叉算子,方法为:选择满足要求的父本与母本后,以此为基础,基于随机交叉点位展开[n]次多点交叉,每次交叉操作均产生两个新个体,在新产生的个体中选取2个适应度值最优的个体作为初始种群,展开变异操作[14]。这种方式保障了种群多样性、未改变种群规模,而且每个个体均遗传父代基因特点,有利于改善新种群整体性能。
1.3 基于极限学习机改进算法的读者借阅行为分析
基于上述高适应度值遗传算法确定极限学习机输入权值与阈值,分析读者借阅行为,步骤如下:
Step1:基于特征优选策略选取图书馆读者借阅行为特征数据,将图书借阅类型、月平均借阅次数、单次借阅图书数量、借阅时间段4种特征作为图书馆读者借阅用户行为特征集的内容,可准确体现读者借阅行为。归一化处理读者借阅行为特征集,作为极限学习机算法训练数据。
Step2:确定极限学习机输入层神经元、隐层神经元以及输出层神经元数量。
Step3:编码极限学习机输入层至隐层的权值与阈值,获取遗传算法初始种群。
Step4:通过解码操作得到权值与阈值,使用新获取的权值与阈值展开极限学习机训练。
Step5:极限学习机训练完成,采用测试样本展开测试,此时适应度函数为测试样本期望值与预测值的误差平方和。
Step6:对种群执行选择、交叉、变异操作获取更新后的种群,若网络权值与阈值的误差平方和最小,符合标准[15];反之,执行Step2。
Step7:得到优化完成的权值与阈值,代入训练模型中,求取隐层输出矩阵[D]与矩阵的MoorePenrose广义逆,即[D+]。
Step8:求取极限学习机输出层权值[η=D+T],由此基于极限学习机的图书馆读者借阅行为分析模型训练完成,将预处理完成的读者行为测试特征样本输入到训练模型中,输出结果即为图书馆读者借阅行为分析结果。
2 高校图书馆读者借阅行为的测试实验
2.1 实验环境设置
以某高校图书馆作为读者借阅行为分析对象,采用本文方法分析读者借阅行为,选取2019年3—5月之间产生的读者借阅数据作为训练样本。该高校读者为教师与在校学生,均办理借阅证,图书借阅类型、月平均借阅次数、单次借阅图书数量、借阅时长等读者数据均记录在借阅证中。测试样本数据为2019年6月产生的读者借阅数据,内容同上。高适应度值遗传算法的种群大小与遗传代数最大值分别设置为60,45;变量二进制位数为10,交叉与变异概率分别为0.65,0.01。本文方法图书馆读者借阅行为样本训练的误差平方和如图3所示,由图3可知,高适应度值遗传算法迭代至30次时,误差平方和趋于稳定,稳定值为1.50。由此可知,迭代30次时即可得到最优的极限学习机输入权值与阈值,无需达到最大次数45,缩短模型训练时长。
定义极限学习机输入神经元数量、隐层神经元数量、输出层神经元数量分别是4,15,6,输入神经元即图书馆读者借阅行为特征,分别为图书借阅类型、月平均借阅次数、单次借阅图书数量、借阅时间段;输出层神经元即读者借阅行为输出结果,分别为文科型、理工型、频繁借阅、偶尔借阅、少量借阅、大量借阅6种。
2.2 图书馆读者借阅行为分析
基于以上设置,极限学习机读者借阅行为类型与神经元输出情况见表1。
表1体现了不同读者借阅行为分析结果形式,以测试数据中8个学生数据为例,展示读者借阅行为分析结果,如表2所示。
由图书馆学生借阅行为分析结果能够看出,不同院系、不同专业学生借阅图书的行为,如编号为1的市场营销专业学生偶尔到图书馆借阅,每次借阅图书数量较少;编号为2的经济学专业学生每次借阅少量图书,借阅次数频繁;编号为7的统计学专业学生借阅理工型图书,每次借阅图书量少,偶尔借阅。
上述分析显示,通过本文方法得到的图书馆学生借阅行为分析结果能够清楚分析读者借阅图书的行为,明确读者喜欢的图书类型、掌握读者喜好、了解每个读者借阅习惯,为合理规划图书馆图书资源提供借鉴。
3 结 论
本文采用极限学习机算法分析图书馆读者借阅行为时,采用高适应度值遗传算法确定极限学习机的输入权值与阈值,降低极限学习机算法的随机性。高适应度值遗传算法相对传统遗传算法而言,改变选择算子与交叉算子方式,采用高适应度值选择算子代替轮盘赌选择算子,这种方式使适应度值较大的种群具有更大机率进入交叉阶段,有效避免轮盘赌选择的随机误差。高适应度值交叉算子保障种群的多样性,并且无需改变种群规模。由此可知,高适应度值遗传算法为极限学习机确定精准的输入权值与阈值,提升了极限学习机分析图书馆读者借阅行为的可靠程度。
参考文献
[1] 陈美.图书馆数字资源管理困境与创新[J].现代情报,2017,37(6):119?123.
[2] 秦东方,陆晓曦.21世纪我国高校图书馆人力资源管理研究述评[J].大学图书馆学报,2017,35(5):24?30.
[3] 刘鹏,王学奎,黄宜华,等.基于Spark的极限学习机算法并行化研究[J].计算机科学,2017,44(12):33?37.
[4] 李佩佳,石勇,汪华东,等.基于有序编码的核极限学习顺序回归模型[J].电子与信息学报,2018,40(6):1287?1293.
[5] 赵大兴,余明进,许万.基于高适应度值遗传算法的AGV最优路径规划[J].计算机工程与设计,2017,38(6):1635?1641.
[6] 高彩云,崔希民,高宁.熵权遗传算法及极限学习机地铁隧道沉降预测[J].测绘科学,2016,41(2):71?75.
[7] 周书仁,曹思思,蔡碧野.基于改进极限学习机算法的行为识别[J].计算机工程与科学,2017,39(9):1749?1757.
[8] 高琪娟,刘锴,陈佳.面向Spark的图书借阅数据关联模型的研究[J].安徽农业大学学报,2018,45(4):768?771.
[9] 陆俊,陈志敏,龚钢军,等.基于极限学习机的居民用电行为分类分析方法[J].电力系统自动化,2019,43(2):97?104.
[10] 谢发徽.高校图书馆座位管理系统的读者行为分析[J].图书馆论坛,2018,38(3):108?116.
[11] 金奇文.公共图书馆少年儿童读者借阅分析及馆藏优化建议:以上海图书馆为例[J].图书馆杂志,2018,37(7):53?62.
[12] 刘浩然,赵翠香,李轩,等.一种基于改进遗传算法的神经网络优化算法研究[J].仪器仪表学报,2016,37(7):1573?1580.
[13] 刘玉梅,魏欧,黄鸣宇,等.应用改进的遗传算法优化软件产品线特征选择[J].小型微型计算机系统,2017,38(1):35?39.
[14] 文艺,潘大志.用于求解TSP问题的改进遗传算法[J].计算机科学,2016,43(z1):90?92.
[15] 辛宇,童孟军,华宇婷.一种基于最优特征选择改进的遗传算法[J].传感技术学报,2018,31(11):1747?1752.



