白乐强 刘杰 曹科研
摘 要: 针对无空闲时隙的动态多叉查询树RFID防碰撞算法在标签识别过程中吞吐量不稳定和识别效率低的问题,提出一种无空闲时隙并行识别动态多叉查询树算法。该算法利用同步正交码(WALSH)作为扩频码的码分多址技术,实现在单一时隙并行识别多个标签的功能;通过跟踪碰撞标签的碰撞位,预测标签分布,消除不存在的标签分支;使用后退查询方式减少数据传输位数,提高识别速度。理论分析和仿真结果表明该算法具有较少的总时隙数和较高的系统吞吐量。
关键词: 并行识别; 动态多叉查询树算法; 空闲时隙; 后退查询; 标签分布预测; 理论分析
中图分类号: TN911?34 文献标识码: A 文章编号: 1004?373X(2020)20?0092?05
Parallel identification dynamic N?ARY query tree algorithm without idle time slot
BAI Leqiang, LIU Jie, CAO Keyan
(School of Information & Control Engineering, Shenyang Jianzhu University, Shenyang 110168, China)
Abstract: As the dynamic N?ARY query tree RFID anti?collision algorithm without idle time slot has unstable system throughput and low recognition efficiency in the process of tag identification, a parallel identification dynamic N?ARY query tree algorithm without idle time slot is proposed. In this algorithm, the code division multi?address technology using synchronous orthogonal code (WALSH) as spread spectrum code is used to realize the function of the parallel recognition of multiple tags in a single time slot, the label distribution is predicted for elimination of the nonexistent label branches by tracking the collision bits of collision tags, and the backward query mode is used to reduce the number of data transmission bits and improve the recognition speed. The theoretical analysis and simulation results show that the algorithm has less total number of time slots and higher system throughput.
Keywords: parallel identification; dynamic N?ARY query tree algorithm; idle time slot; backward query; tag distribution prediction; theoretical analysis
0 引 言
随着信息化时代的到来,物联网产业得到蓬勃发展,现已广泛应用于物流管理、人工智能、自动驾驶、智能家居等领域。无线射频识别(RFID)技术、传感器技术、嵌入式系统技术是组成物联网的三大关键技术,其中,RFID技术作为物联网结构中的感知层,受海内外研究人员的关注。通常,RFID系统由阅读器、标签与天线三部分构成[1]。阅读器用于识别或读取标签;标签通过内嵌芯片存储附着物的身份信息,拥有全球唯一的ID;天线用于传递两者之间内存数据的读/写操作[2]。当多个标签同时向阅读器发送处理数据时,导致通信信道堵塞,阅读器接收数据受损,无法执行正常读/写操作,这就是标签碰撞。所以,减少标签碰撞,保证数据传输的完整性和正确性是提高RFID系统稳定性,打破物联网产业技术壁垒的关键所在。
目前主要存在两类防碰撞算法:基于ALOHA防碰撞算法和基于树防碰撞算法[3]。基于ALOHA防碰撞算法采用回避原则,射频场内的所有标签可随时传递信息给阅读器,阅读器判断是成功接收还是碰撞,若为碰撞,则阅读器要求标签概率性延迟几个时隙再发送。然而,当大量标签涌入射频场,存在标签持续被延迟,最终无法被识别,这就是“标签饿死”现象。目前,研究人员主要通过事先预测待识别标签数量,采用某种算法调整帧内时隙数,最大限度减少碰撞来提高识别效率。基于树防碰撞算法[4]分为查询树(QT)算法和搜索树(BT)算法,是一种非概率性算法,能够达到百分百识别。阅读器发送查询前缀给射频场内的标签,包含该前缀的标签响应。阅读器判断是成功接收还是碰撞,若为碰撞,则阅读器扩充查询前缀再发送,直到识别所有标签。然而,当待识别标签数量较多时,碰撞时隙和空闲时隙占总时隙比例较大,导致识别时间延长,系统吞吐量降低。
基本防碰撞算法阅读器每次识别过程只能识别一个标签,系统吞吐量较低。牛爱民提出无空闲时隙动态多叉查询树RFID防碰撞(DMQT)算法[5],当多标签响应时,该算法利用曼彻斯特编码精确判断标签碰撞位,根据连续碰撞位的数量,动态调整树的分裂;通过跟踪查询碰撞位,预测碰撞标签分布,剪去标签不存在的分支。
本文在无空闲时隙的动态多叉查询树RFID防碰撞算法的基础上,结合WALSH码的同步正交特性,提出无空闲时隙并行识别动态多叉查询树算法(DIPQT)。该算法将标签ID与WALSH扩频码进行扩频,扩频后的标签会以不同的码道与阅读器通信,以此减少碰撞发生的概率。
1 DMQT算法
曼彻斯特编码常用于RFID系统中检测碰撞位的位置,如果多个标签同步传输的数据流中,存在0和1两种不同的比特,该位的曼彻斯特编码不会出现跳变,即此位为碰撞位。DMQT对自适应多叉树防碰撞算法进行优化,其主要改进是阅读器通过两类查询方式识别标签,一类是识别查询,另一类是当标签发生ID碰撞时的位跟踪查询。阅读器通过在查询前缀q1q2…qk后附加标志位(flag)来识别两类查询。每次标签接收到阅读器发送的请求指令时,首先判断flag,若flag=0,则表示识别查询,匹配查询前缀的标签将除前缀外的剩余ID号传输给阅读器;若flag=1,则表示位跟踪查询,位跟踪查询的响应方式如下:
1) 利用曼彻斯特编码判断标签最高连续碰撞位n的个数,确定分裂叉树为2n,最高不超过64叉;
2) 阅读器发送REQUEST(0…0+1…1,1)指令,其中0的比特数为n个,剩余比特均为1;
3) 标签接收到位跟踪查询指令后,将标签ID中与1…1对应位换算为十进制数字s,然后回送一个长度为2n比特数据,其中第s mod 2n位设成1,剩余位设成0。
2 改进算法
通常,在基于树的防碰撞算法中,用时隙来表示阅读器识别标签所消耗的时间,该算法在识别标签的过程中可能会碰到以下3种时隙状态。
1) 碰撞时隙。有2个以上标签响应,并且标签与阅读器用相同的码道通信,此时标签ID及扩频码均碰撞,阅读器无法解码。
2) 伪碰撞时隙。有2个以上标签响应,但是存在标签具有唯一的扩频码,这些标签独占1条码道,解码后阅读器能够成功识别,剩余的碰撞标签等待下次查询。
3) 成功时隙。只有1个标签响应,阅读器与之建立通信并读取标签中的信息。
2.1 算法思想
Don R. Hush在RFID仲裁树算法[6]中分析,完全分裂的多叉树总时隙数[t(m)]为:
[t(m)=c(m)+z(m)+m =1+BL=0∞BL[1-(1-B-L)m-mBL(1-B-L)m-1]] (1)
式中:[c(m)]为碰撞时隙;[z(m)]为空闲时隙;m为射频场内标签数目;B为完全多叉树的分裂叉树;L为完全多叉树的深度。
碰撞时隙[c(m)]为:
[c(m)=1B(t(m)-1)] (2)
空闲时隙[z(m)]为:
[z(m)=B-1Bt(m)-m+1B] (3)
经上述公式得到完全多叉树的时隙占比如表1所示。
从表1分析随着分裂叉树B的增大,碰撞时隙占比减少,空闲时隙占比增大,如果能够完全消除空闲时隙或者用碰撞时隙代替空闲时隙,势必会提高系统吞吐量。
WALSH序列码[7]是一种同步正交码,是一个实现码分多址(CDMA)信号传输的代码,它们互相之间完全正交。WALSH码可以用来区分一个时隙里面的多个码道,扩频码长度为m时,可以产生m个互相关特性为0的扩频码。当标签接收到阅读器发送的扩频指令后,从码表中随机选择扩频码与自己的ID结合,之后阅读器与标签会通过不同的码道通信。
阅读器通过REQUEST指令查询标签,其格式如下:REQUEST(q1q2…qk,flag),q1q2…qk为查询前缀,flag表示查询标志符,flag∈{0,1},flag=0时,代表识别查询,flag=1时,代表位跟踪查询。阅读器发送REQUEST(q1q2…qk,flag)命令,符合查询前缀的标签响应。
2.2 算法流程
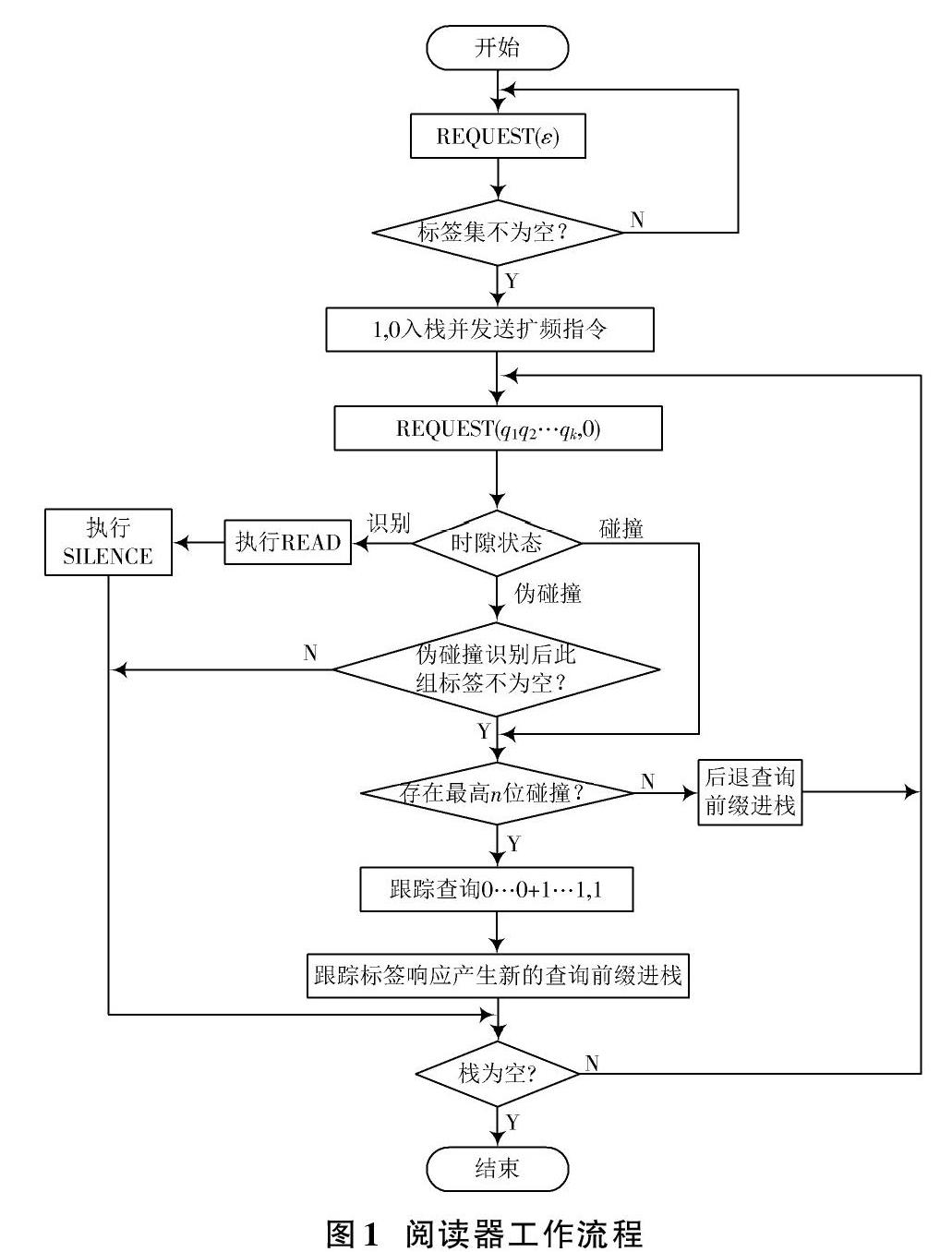
阅读器操作步骤如下:
步骤1:阅读器在内部存储器开辟空间,新建一个用来存储查询前缀的空栈S,发送REQUEST(ε)指令。
步骤2:阅读器探察有无标签回送的完整ID号,若无,表示阅读器周围无电子标签,转至步骤1;若有,执行PUSH(QUERY)进栈指令,将前缀1和前缀0入栈,同时向标签发送码长参数为m的WALSH扩频指令。
步骤3:若阅读器接收到标签ID和扩频码正交调制信号,发送REQUEST(q1q2…qk,0)指令,其中最后的0表示识别查询。
步骤4:若阅读器接收到标签传输的不包括查询前缀剩余ID数据,阅读器内部解码模块对标签数据解码,根据解码结果判断时隙的状态。
1) 如果时隙内只有1个标签响应,该时隙为识别时隙,阅读器可直接与该标签通信,识别后将标签置为沉默状态,转至步骤6。
2) 如果时隙内有2个以上标签响应,并且具有相同的WALSH扩频码,该时隙为碰撞时隙,此时标签ID及扩频码均碰撞,无法识别信息,转至步骤③。
3) 如果时隙内有2个以上标签响应,但是存在标签具有唯一的WALSH扩频码,该时隙为伪碰撞时隙,这些具有唯一扩频码的标签独占一条码道通信,可以被阅读器成功识别,识别后将标签置为沉默状态。
① 如果伪碰撞时隙内除去有唯一扩频码的标签后没有剩余标签待识别,转至步骤6;如果伪碰撞时隙内除去有唯一扩频码的标签后还有剩余标签待识别,在剩余标签中,判断连续最高碰撞位数目n。若n=1,转至步骤②;若n>1,转至步骤③。
② 阅读器产生两个新查询前缀,执行PUSH(QUERY)指令,QUERY_1=原查询前缀,QUERY_2=首碰撞位之前的位串+1。
③阅读器发送位跟踪查询指令REQUEST(0…0+1…1,1),其中0的比特数为n,剩余比特均为1。
步骤5:若阅读器接收到标签发送的位跟踪查询的计算结果信息,用曼彻斯特编码判断哪些分支存在标签,剪去标签不存在的分支,执行PUSH(QUERY)指令,QUERY=原前缀+标签存在分支。
步骤6:判断栈S状态,如果栈S不为空,则读取栈首位,作为查询前缀继续查询,转至步骤3;如果栈S为空,则查询结束。
DIPQT算法阅读器流程如图1所示。
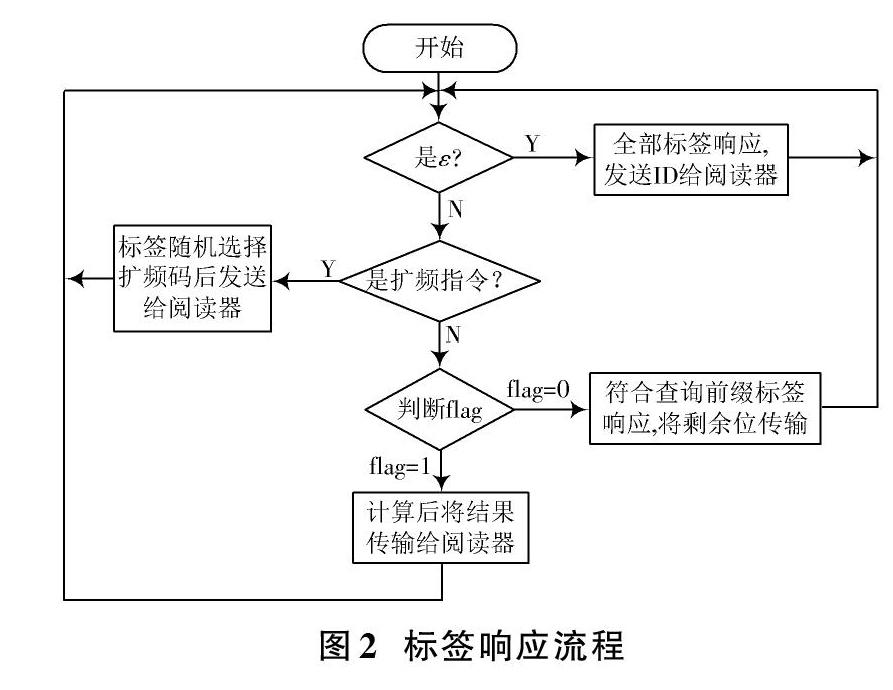
标签操作步骤如下:
步骤1:若标签接收到REQUEST(ε)指令,将自己的ID号发送给阅读器。
步骤2:若标签接收到码长参数为m的WALSH扩频指令,标签随机选择扩频码与ID进行扩频,将标签ID和扩频码正交调制信号回送给阅读器。
步骤3:若标签接收到REQUEST(q1q2…qk,flag)指令,根据flag判断阅读器的查询类型,若flag=0,转至步骤1);若flag=1,转至步骤2)。
1) 标签检测自己的ID是否与查询前缀匹配,如果不匹配,不作响应;如果匹配,发送除查询前缀外的剩余ID号。
2) 标签根据位跟踪查询REQUEST(0…0+1…1,1),将ID中与1…1对应位换算为十进制数字s,然后回送一个长度为2n比特数据,其中第s mod 2n位设成1,其他位设置为0,将位跟踪查询的计算结果信息回送给阅读器。
DIPQT算法标签响应的流程如图2所示。
3 算法理论分析
在RFID系统中,评价防碰撞算法好坏的重要指标有总时隙数和系统吞吐量。DIPQT算法利用自适应多叉树的动态分裂特性,树的分裂叉数可随碰撞标签数目变化。假设标签ID长度为96 bit,最高连续碰撞位为h位,此时采用2h叉树分裂,分裂叉树必须小于标签ID长度,即DIPQT算法最高分裂64叉,此时得到最少总时隙数。
完全64叉树DIPQT算法的总时隙数为:识别时隙+碰撞时隙+位跟踪查询时隙(位跟踪时隙数等于碰撞时隙数)。若射频场内中有N个标签等待识别,则完全64叉树的总时隙数[5]T64为:
[T64=65N-263] (4)
若扩频码随机分布,且扩频码码长为m,理想状况下扩频后的最小总时隙Tmin为:
[Tmin=T64m=65N-263m] (5)
当最高连续碰撞位仅有1个,此时碰撞时隙最多,得到最多总时隙数,完全2叉树的总时隙数T2为[8]:
[T2=2N-1] (6)
理想状况下扩频后的最大总时隙Tmax为:
[Tmax=T2m=2N-1m] (7)
由式(5)和式(7)得到理想状况下DIPQT算法所需的总时隙数T为:
[T∈65N-263m,2N-1m] (8)
通过上述分析可知,若标签数量一定,随着扩频码码长m的增加,总时隙数会大幅度下降,但系统的设计复杂度会变大,阅读器利用码表扩频占用较多时间,使得算法的整体工作效率变低。
系统吞吐量表示阅读器在一个时隙内平均识别标签的数量,是评价RFID防碰撞算法性能的重要指标之一。假设系统中有N个标签待识别,在一个时隙内,有n个标签响应且WALSH扩频码码长为[m]的期望吞吐量ESlot为:
[ESlot=mnm1-1mn-1] (9)
设L为树分裂的叉数,则树搜索的层数k为:
[k=logLNn] (10)
根据查询树的基本原理,在一个时隙内有n个标签响应的概率[P(T)]服从二项分布[9]:
[P(T)=CnN(L-k)n(1-L-k)N-n] (11)
基于树查询算法的吞吐量为一个时隙内有n个标签响应的期望吞吐量与概率乘积的加和,即DIPQT算法的吞吐量S为:
[S=n=0NP(T)?ESlot] (12)
由DIPQT算法可知,当扩频码长度m确定,连续最高碰撞位h=6时,最高分裂叉树等于2h=64叉,DIPQT算法的系统吞吐量S为:
[S=n=02CnN(2-k)n(1-2-k)N-n?mnm1-1mn-1+ n=363CnN(n-k)n(1-n-k)N-n?mnm1-1mn-1+ n=64NCnN(64-k)n(1-64-k)N-nmnm1-1mn-1] (13)
通过以上对DIPQT算法性能的理论分析可知,DIPQT算法的防碰撞性能得到了较大提升,系统吞吐量高于DMQT算法。
4 算法仿真及分析
以Matlab 2018a为仿真平台对算法进行仿真,阅读器射频场内的标签数量取值为100~1 000,标签ID均匀分布,固定为96 bit长度,仿真20次取平均值。下面将DIPQT算法和GBAQT算法[10]、A4PQT算法[11]、DMQT算法进行仿真分析,从总时隙数和系统吞吐量两个方面进行比较。
在RFID系统中,当标签数量一定的情况下,随着扩频码码长m的增加,标签在同一个时隙内出现“码碰撞”的概率就越小,系统期望的吞吐量随之增大,防碰撞的性能越好。但是,m值的增加就意味着系统运行占用的资源增加,系统的硬件设计复杂度会大大增加[12]。经验证,取值m∈{2i,i=0,1,…,7}可满足实际生活需要。
图3表示DIPQT算法与其他三种算法总时隙数的比较。基于四叉树修改的A4PQT算法在标签数量变多时总时隙数变得非常大,识别1 000个标签大约需要2 000个时隙。
GBAQT算法采用标签分组的方法消除了部分空闲时隙,标签数量小于500时,总时隙数与A4PQT算法和DMQT算法相差不大;标签数量大于500时,GBAQT算法明显逊色于DMQT算法。DMQT算法虽然完全消除了空闲时隙,但是会增加少许的位跟踪时隙,DMQT算法大幅度减少了总时隙数,识别1 000个标签约需要1 400个时隙。前三个算法由于没有使用并行识别技术,总时隙数都在1 000以上,而DIPQT算法(m=8)识别1 000个标签所需时隙数约为700个,DIPQT算法(m=128)所需总时隙数更少,最大不超过200个时隙。通过对以上对比发现DIPQT算法更适用于标签数量较多的场景。
图4表示DIPQT算法与其他三种算法的系统吞吐量的比较。通过图4a)可看出,DIPQT算法(m=8)的吞吐量要明显高于GBAQT算法和A4PQT算法。GBAQT算法的吞吐量在0.54上下波动,趋于稳定;A4PQT算法的吞吐量一直在0.50以下,这是因为随着标签数量的增加,A4PQT算法会增加许多空闲时隙,从而导致吞吐量较低;DMQT算法消除了空闲时隙,使DMQT算法系统吞吐量提升幅度较大,在0.59和0.71之间波动,上下波动明显。DIPQT算法(m=8)的系统吞吐量随标签数量变化的曲线轨迹比较平稳,较DMQT算法平均提高约8.6%。图4b)中DIPQT算法(m=128)的吞吐量较DMQT算法平均提高约38.4%,当标签数量达到500后,DIPQT算法的吞吐量在0.89趋于稳定。
通过对算法的仿真结果分析可知,DIPQT算法系统吞吐量高于现有的其他查询树算法。
5 结 语
本文基于动态多叉查询树和并行识别技术,提出一种无空闲时隙并行识别动态多叉查询防碰撞算法。该算法使用跟踪碰撞时隙之间碰撞位的方法消除空闲时隙,利用码分多址的扩频码技术进行并行识别。扩频后的阅读器与标签会使用不同的码道通信,减少了标签碰撞的产生,实现了在一个时隙内最多可并行识别多个标签的功能,在每次识别完标签后后退到上一级碰撞节点,减少了数据传输。理论分析和仿真结果证明DIPQT算法大幅度减少了防碰撞算法的总识别时隙数,能有效提高系统识别速度和系统吞吐量,更适合用标签数量较多的场景。
参考文献
[1] 郭振军,孙应飞.基于标签分组的RFID系统防碰撞算法[J].电子与信息学报,2017,39(1):250?254.
[2] 曾实现,薛蕊,陈江波.基于物联网RFID技术的导引系统设计与研究[J].现代电子技术,2017,40(19):22?24.
[3] 王雪,钱志鸿,胡正超,等.基于二叉树的RFID防碰撞算法的研究[J].通信学报,2010,31(6):49?57.
[4] LIU Xiaohui, QIAN Zhihong, ZHAO Yanhong, et al. An adaptive tag anti?collision protocol in RFID wireless systems [J]. China communications, 2014, 11(7): 117?127.
[5] 牛爱民.无空闲时隙的动态多叉查询树RFID防碰撞算法[J].计算机应用与软件,2016,33(6):277?281.
[6] HUSH D R, WOOD C. Analysis of tree algorithms for RFID arbitration [C]// Proceedings of IEEE International Symposium on Information Theory. Cambridge: IEEE, 1998: 107?116.
[7] 王岳松,孔韬.一种基于同相正交环的数字曼彻斯特解码方法[J].中国电子科学研究院学报,2015,10(3):317?320.
[8] ZHANG Yin, YANG Fan, WANG Qian, et al. An anti?collision algorithm for RFID?based robots based on dynamic grouping binary trees [J]. Computers and electrical engineering, 2017, 63: 91?98.
[9] YEH M K, JIANG J R. Parallel splitting for RFID tag anti?collision [J]. International journal of ad hoc and ubiquitous computing, 2011, 8(4): 249?260.
[10] 付钰,钱志鸿,程超,等.基于分组机制的位仲裁查询树防碰撞算法[J].通信学报,2016,37(1):123?129.
[11] ZHANG W, GUO Y, TANG X M, et al. An efficient adaptive anticollision algorithm based on 4?ary pruning query tree [J]. International journal of distributed sensor networks, 2013, 2013: 1?7.
[12] 王必胜,张其善.可并行识别的超高频RFID系统防碰撞性能研究[J].通信学报,2009,30(6):108?113.



