李学强,赵文洋,解玉琪
(中国石油大学(华东)计算机与通信工程学院,山东 青岛 266580)
0 引 言
海洋预报是一种通过海洋数值模式和相关资料的同化系统,对海温、盐度、海流、海浪、潮汐、风暴潮、海啸、海冰、海平面变化等多种时空尺度上的海洋状况与海洋现象开展预测及信息发布的技术手段[1]。
随着探测设备与信息技术的不断发展,海洋数据获取手段日益增多,海洋信息获取的速度与精度也在不断提高,获取的海洋数据量越来越大,且海洋数据已呈现出海量特征[2];海洋数据获取手段的多样化及海洋观测要素的多元化,使得海洋数据类型呈现出多类型特征。
由于海洋数据的海量性、多类型、模糊性等特征,海洋数值预报研究者难以及时获取自身所需要的数据信息[3]。因此根据用户的研究任务,将用户所需要的海洋数据信息推荐给用户成为了一个关键问题。
本文提出基于“主题模型-关联分析-相似度对比”架构的推荐算法:主题模型用以辅助建立关系数据集;使用关联关系分析数据集生成关联关系表;最终通过相似度对比查询关联关系表生成数据推荐列表。该算法避免了推荐算法中冷启动的问题,并对用户研究任务进行语义分析,分析用户的行为,提高推荐算法的准确性。该算法可根据用户的研究任务,快速、有效地进行海洋数值预报的数据推荐。
1 基于关联关系的数据推荐算法
本文针对用户的研究任务,提出了基于“主题模型-关联分析-相似度对比”架构的推荐算法,如图1 所示。
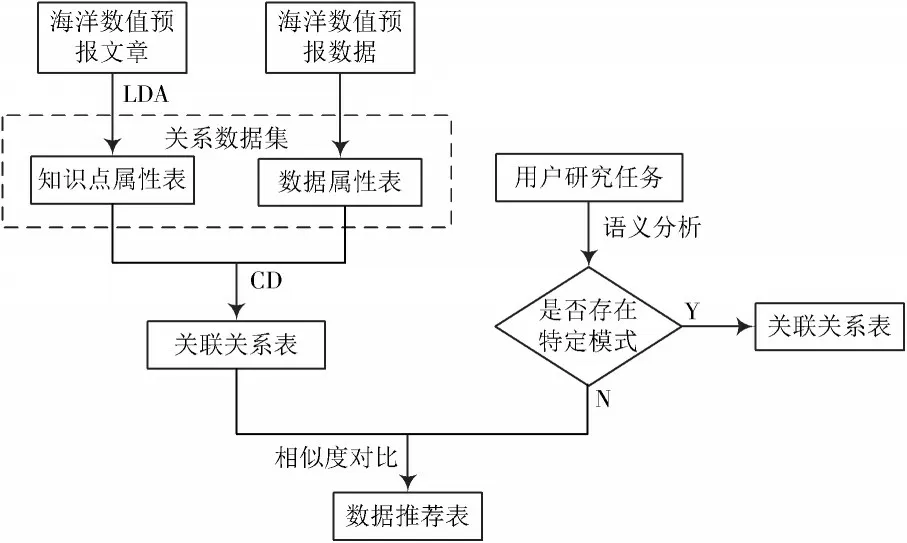
图1 “主题模型-关联分析-相似度对比”推荐算法技术流程
该算法提取海洋数值预报文献中的有效信息用以建立关系数据集,使用关联分析挖掘关系数据集中的关联规则;最终通过对比用户研究任务与关联关系表的相似度,将查询到的数据列表推荐给用户。
1.1 数据预处理
每篇海洋数值预报论文中均蕴含着用户研究任务与所用数据的对应关系,本文预计从海洋数值预报论文中提取相关信息,从而建立关系数据集。但海洋数值预报论文中包含的文本信息复杂,里面冗余信息较多,有效信息少,不利于后续处理。将文本信息主题挖掘后,使其从词项空间降维到主题空间,可以有效解决处理这一问题。LDA 模型是自然语言处理中主题挖掘的经典模型。与传统的PLSA 模型相比,LDA 主题模型是概率生成模型,具有清晰的逻辑层次,且在主题层与词层引入Dirichlet 分布,可以有效地提高模型的泛化能力,从而缓解过拟合的问题。
LDA 模型[4]描述了在隐含变量上生成文本的过程,是一个“文本-主题-词”的三层贝叶斯产生式模型。LDA模型具有三层结构,分别为文档层、主题层、词层。其具体结构如图2 所示。
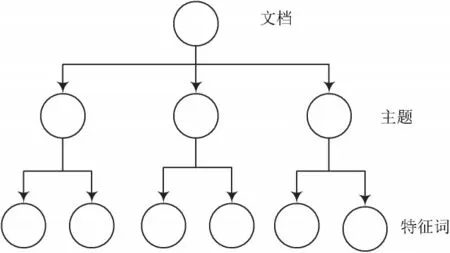
图2 LDA 拓扑结构
LDA 模型是一个有向图概率模型[5],如图3 所示。图中参数(α,β)决定了整个模型,分别反映了文档中隐含主题的强弱及隐含主题自身的概率分布;θm与φk分别表示文档下主题的概率分布及某一主题下词的概率分布;M 表示文档集合中所包含的文档数目;K 表示文档集中包含的主题数;N 表示当前文档中拥有的词数。Zm,n表 示 第m 篇 文 档 中 第 几 个 词 的 主 题;Wm,n表 示第m 篇文档中第n 个词。
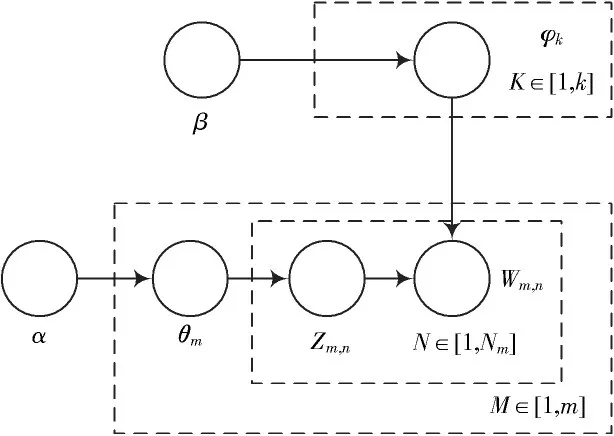
图3 LDA 有向图概率模型
LDA 模型下文本的生成过程如下[6]:
1)从Dirichlet(β)分布中抽取一个多项式分布向量φ 表示第k 个主题的词汇概率分布;
2)从Dirichlet(α)分布中抽取一个多项式分布向量θM表示第m 篇文档中主题的概率分布;
3)从多项式分布θ 中抽取一个主题Zn作为第n 个词的主题,从Zn的主题-词汇作为文档的第n 个词。
根据模型,可以得到一篇文献的生成概率为:
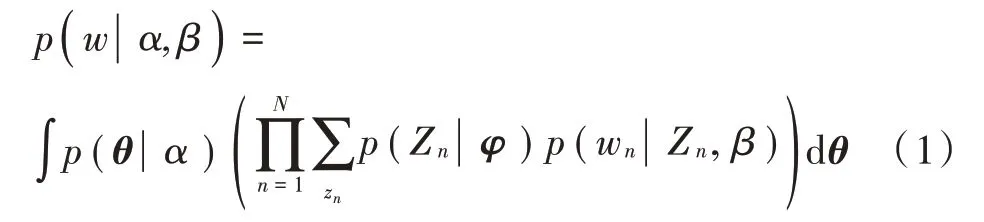
对于模型中参数α 与β 的估计,可以使用Gibbs 抽样获得:
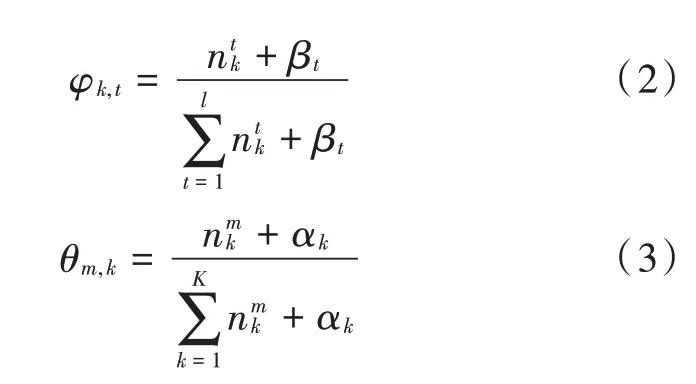
式中:φk,t表示主题k 中词项t 的概率;θm,k表示文本m 中主题k 的概率;表示主题k 中出现词t 的次数;表示文本m 中出现主题k 的次数。
1.2 关联分析
经过LDA 主题模型,将每篇海洋数值预报文献降维并映射到主题空间,获得形如Z(z1,z2,…,zm)的一个主题分布。此主题分布可以反映此篇海洋数值预报文献的研究任务,结合此文献用到的数据D(d1,d2,…,dn)得到一个事务T (z1,z2,…,zm,d1,d2,…,dn)。为了研究事务集中研究任务与所需数据的对应关系,本文使用关联分析进行挖掘。
关联规则学习是数据挖掘的重要研究方向之一,关联规则学习挖掘的目的是从事务数据集中分析数据项之间潜在的关联关系。关联规则挖掘主要分为以下两个步骤:
1)从关系数据集中挖掘所有支持度不小于最小支持度阈值的频繁项集;
2)从上一步结果中生成满足最小置信度阈值要求的关联规则,从而形成关联关系表。
Apriori 算法[7]是一个经典的关联规则算法,使用逐层搜索的方式寻找频繁项集。其主要原理为:若一个项集不是频繁项集,则其所有超集也不是频繁项集。Apriori 算法寻找频繁项集主要分为两步:连接步与剪枝步。算法步骤如下:
1)循环次数k=1 时,遍历所有1 项集,计算支持度,与支持度阈值作比较,找出频繁项集L1;
2)循环次数k>1 时,将频繁项集Lk-1与自身连接形成产生候选k 项集,计算支持度,与支持度阈值作比较,找出频繁项集Lk。
为提高算法效率,本文使用Apriori 算法的并行化算法CD(Count Distribution)算法[8-9]。CD 算法的基本思想是由各个处理器首先独立地生成全局候选项集和频繁项集,其次需要将其生成的局部候选项集计数发送至其他处理器后再进行同步处理。
由于需要挖掘研究任务与所需数据的对应关系,即需要形如z1z2→d1的有效关联规则,对形如d1d2→d3(数据推出数据)、z1z2→z3(主题推出主题)、z1d1→d2(主题、数据推出数据)、z1d1→z2(主题、数据推出主题)的关联规则,本文称之为无效关联规则。因此在由频繁项集挖掘关联规则前,需要对频繁项集L(l1,l2,…,lk)进行扫描,将所有只含主题或只含数据的频繁项集(如z1z2,d1d2等)删除;在根据频繁项集产生关联规则的过程中,需要计算有效关联规则的置信度,这在一定程度上减少了CD 算法的时间复杂度。
1.3 数据推荐
对用户研究任务进行预处理(分词+去除停用词),分词结果中出现海洋数值模型(如FVCOM[10-12]、HYCOM[13-14]等)等词组时,直接将数据列表推荐给用户(海洋数值模型使用的海洋数据一般是固定的);分词结果中未出现海洋数值模型及同化方法等词组时,使用LDA 算法提取用户研究任务的主题,计算用户研究任务与每条知识点之间的相似度。
由于知识点与用户研究任务在经过分析后均降维到主题空间,用主题概率分布进行表示。因此,知识点与用户研究任务的相似度可以用KL 距离[15]进行形容。其物理意义是:在相同事件空间里,概率分布P(x)对应的每个事件,若用概率分布Q(x)编码时,平均每个基本事件(符号)编码长度增加的比特数[16]。本文用D(P||Q)表示KL距离,计算公式如下:
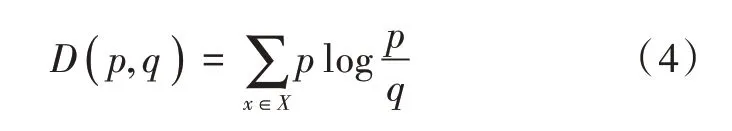
式中:P(x)与Q(x)分别代表知识点和用户研究任务的主题分 布;p 为X =x 时 主 题 分布P(x)对 应的值;q 为X =x 时主题分布Q(x)对应的值。通过KL 距离衡量用户研究任务与知识点的相似度,查询关联关系表,将对应的数据列表推荐给用户。
2 实验结果与分析
2.1 实验数据
笔者在中国知网下载海洋数值预报的相关文献300 余篇,将其中80%的数据用来训练模型,20%的数据用来测试结果。实验在1 台Windows 10 旗舰版操作系统、IntelⓇCoreTMi5-4220 CPU、3.2 GHz、内存4 GB 的计算机上进行。
2.2 模型训练与参数设置
提取海洋数值预报论文的摘要、研究内容、实验分析和结论等部分,形成海洋数值预报知识点样本,将其用于LDA 模型的训练。主题个数为LDA 模型的重要参数,其设置的是否合理,将直接影响LDA 模型的优劣。困惑度是评价LDA 模型的重要指标之一,其代表训练出来的模型对文档d 所属主题的不确定性。在LDA 模型中,困惑度计算公式如下:

式中:D 代表文本库中的测试数据集;M 表示文档数;Nd表示文档d 中的单词数;wd表示文档d 中的词。在本文档库中,困惑度随主题数的变化如图4 所示。
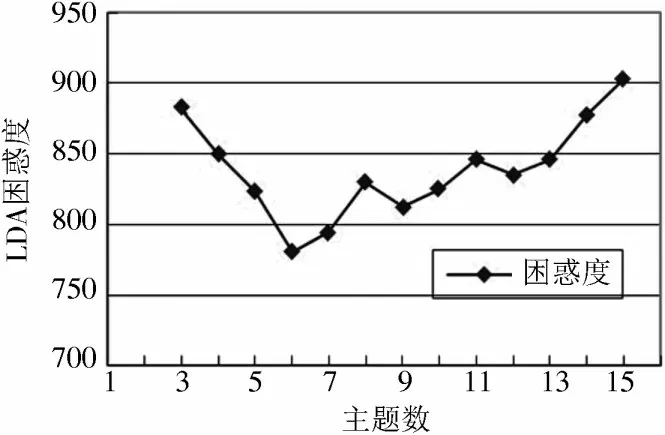
图4 不同主题数下LDA 困惑度
由图4 可知,当主题数为6 时,LDA 模型的困惑度最低,则LDA 模型在本文档库中的最优主题数为6。
推荐准确率(Precision)与推荐召回率(Recall)是衡量推荐算法的重要标准,其计算公式分别为:
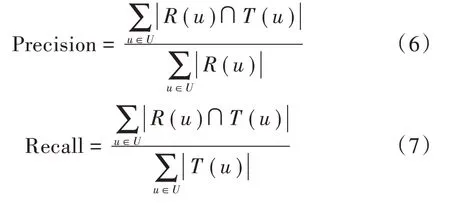
在数据列表推荐模块中,需要对比用户研究任务与知识点的相似度,将相似度差异小于阈值的数据列表推荐给用户。相似度阈值的大小直接影响推荐算法的准确率与召回率。本文根据实验来测试最优相似度阈值,如图5 所示。
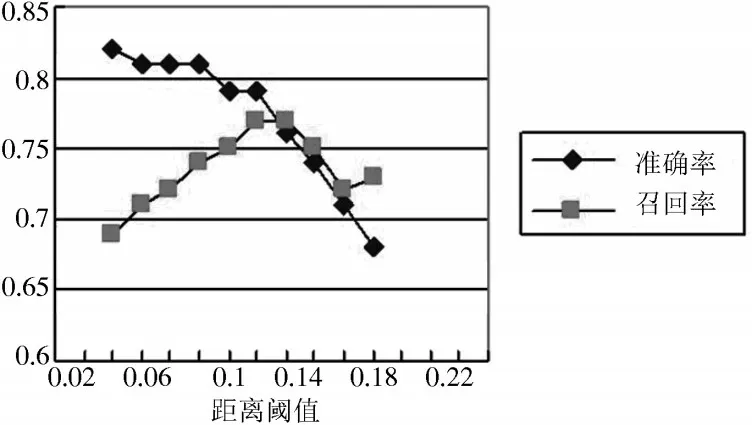
图5 准确率与召回率随相对熵阈值的变化
由图5 可以看出,当KL 距离阈值为0.16 时,推荐准确率相对较大,推荐召回率达到最大;而KL 阈值继续减小时,推荐准确率提升较低,推荐召回率迅速下降。因此,较优KL 距离阈值为0.16。
2.3 结果分析
将相关参数代入“主题模型-关联分析-相似度对比”模型,获得部分关联关系表,如表1 所示。
由于数据量较大,表1 只展示了部分频繁二项集与频繁三项集。
由表1 分析可得,在支持度0.1,置信度0.8 的条件下,涉及风暴潮的知识点主要用到的数据为风场、水流;涉及海洋气象预报的知识点主要用到的数据为风场、气温、海流;涉及波浪的知识点主要用到的数据为风场、温度;涉及海洋预报的知识点主要用到的数据为温度、盐度、叶绿素;涉及涡旋的知识点主要用到的数据为风场、洋流。
本文模拟了60 组用户研究任务与所需数据。用LDA 主题模型处理用户研究任务,通过用户研究任务与知识点的KL 距离来衡量用户研究任务与知识点的相似度。查询关联关系表,最终将用户的预期数据与通过本文模型获取的数据进行对比,得到模型的平均推荐准确度约为0.775,平均推荐召回率在0.756 左右。
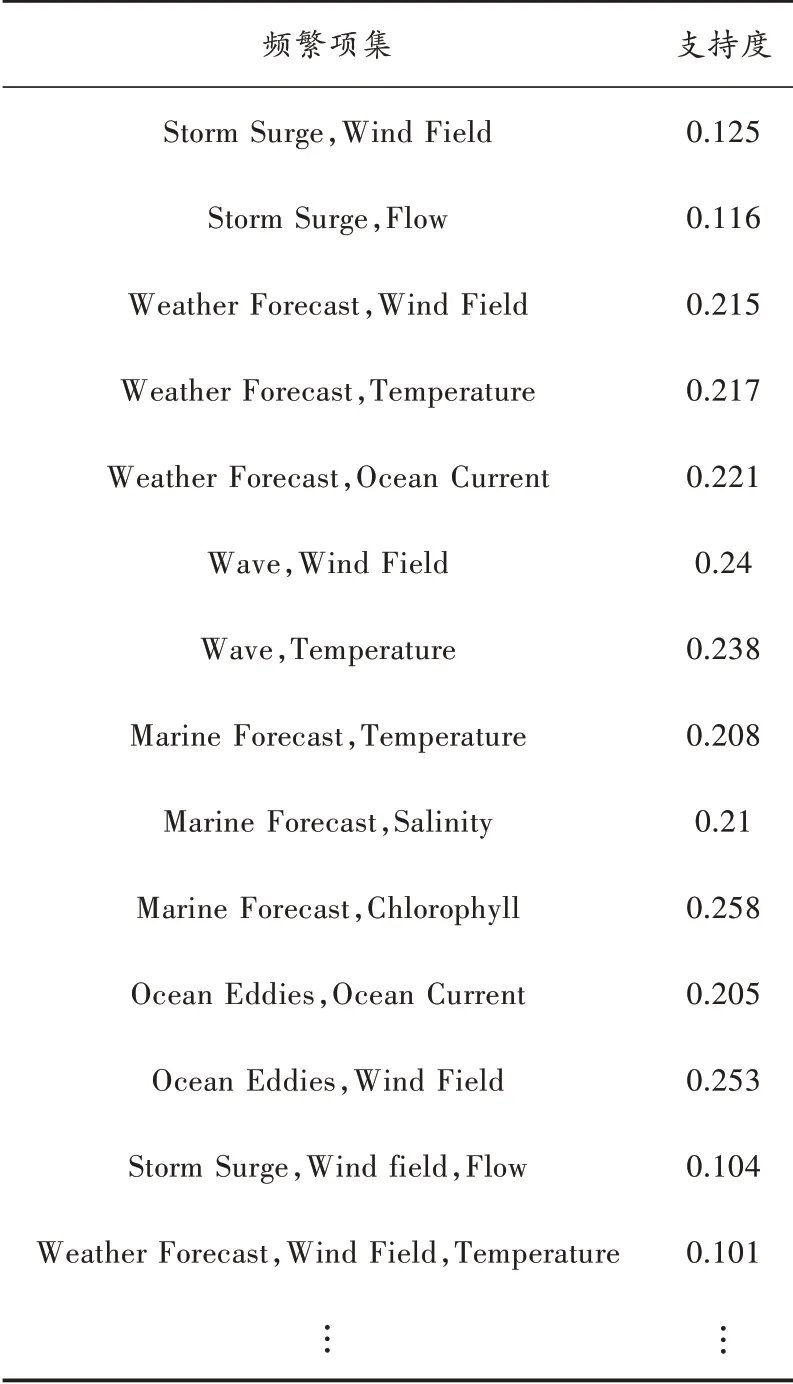
表1 部分关联关系表
3 结 语
本文提出一种基于用户任务的海洋数值预报数据推荐方法,建立一种基于“主题模型-关联分析-相似度对比”架构的推荐算法模型。主题模型用以辅助建立关系数据集,使用关联关系分析数据集生成关联关系表,最终通过相似度对比查询关联关系表生成数据推荐列表。该算法避免了推荐算法中冷启动的问题并对用户研究任务进行语义分析,从而分析用户的行为,提高推荐算法的准确性。根据用户的研究任务,快速、有效地进行海洋数值预报的数据推荐。



