杨晓梅,郭文强,张菊玲
(新疆财经大学 信息管理学院,新疆 乌鲁木齐 830012)
0 引 言
进入21 世纪以来,互联网金融横空出世,越来越多的互联网金融产品和服务走进了人们的生活[1-2]。与此同时,使用互联网金融的用户越来越多,互联网金融产品也越来越丰富,用户与产品之间的联系愈发的密切。海量的用户数据以及交易数据在互联网金融企业各部门之间不停地交互,为满足海量的用户数据的处理及用户的多样性需求,更好地为互联网金融客户提供优质的服务,采用设计互联网金融用户画像的形式,对已有的金融用户进行分类,并提供针对性的服务[3-4]。这种用户画像是用户联系用户需求和服务方向的有效工具。
随着信息技术的快速发展与信息能力的不断变革,互联网金融企业对海量数据处理的技术提出了更高的要求。原有的用户画像构建技术分类效果较差,因而,设计基于大数据的互联网金融用户画像技术。在此次的设计中,将引用大数据技术中的数据挖掘技术以及数据分类处理技术,提升文中设计技术的分类效果。为保证此次设计的有效性,在设计完成后,将采用与原有用户画像设计技术对比的形式,得出文中设计技术的使用性能。
1 互联网金融用户画像技术设计
针对原有互联网金融用户画像技术在使用过程中,对用户画像的分类效果不佳的问题,引用大数据技术对原有的互联网金融用户画像技术展开优化,在提升此技术分类效果的同时,保证此技术可用于多种系统平台中。此次优化设计过程设定如图1 所示。
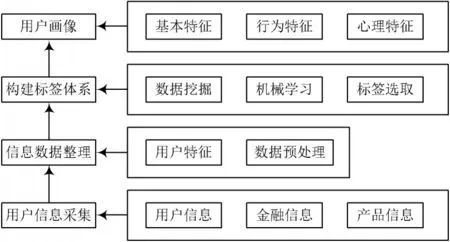
图1 互联网金融用户画像技术设计路线
1.1 获取互联网金融用户特征数据
用户数据获取是实现和发挥用户画像技术的基础,为保证此次设计中应用的大数据技术能够对互联网金融用户进行处理,将使用关系型数据库完成对互联网金融用户特征数据的获取。在此次设计中使用Kettler 软件[5-7]实现不同用户信息数据库之间的数据存储、转换、装载的过程。为保证此软件的正常使用效果,将此技术中涉及的数据库设定为异构数据库[8]。使用上述软件将原有相对独立的数据连通起来,获取互联网金融用户的使用信息。在信息采集的过程中,由于数据量较大,在实现采集的计算机中增加相应的数据采集芯片,提升文中设计方法的数据采集能力。在此次研究中,选用数据采集芯片如图2 所示,采用其作为此设计中技术的通信部分,获取网络中的金融用户信息。将此芯片与常用的电脑系统相结合,形成集成性的操作系统,使用此系统中的设备驱动程序,完成数据的发送与捕获。在此次设计的技术中,将用户数据采集设定为数据存储与数据预览两种采集模式。使用这两种模式,完成用户信息的采集工作。在此次设计中,设定数据采集过程遵循以下原则:在不影响用户使用的前提下,确保数据获取的高效性、可控性与完整性。根据实际的数据需求完成源数据的全量导入与增量采集。采用流水线式[9]的数据处理方式,保证数据采集的过程中,数据处理尽可能具有相对的独立性。采用以上设定的原则完成数据采集过程。

图2 用户数据采集芯片
1.2 用户信息预处理
将上述部分采集到的用户数据存储到专属的数据库中,并对数据展开预处理。此次技术使用到大数据技术,将其预处理过程设定如下:采集到的网络用户数据大部分为网络日志的形式,首先对数据进行整理,获取网络数据中完整的数据,将数据分割为使用数据分析的数据特征字段,而后对数据特征字段进行数据清洗。在此次设计中的数据清理设定为数据字段的提取过程,清洗对数据特征具有影响的数据。数据清洗过程分为两部分,首先将具有特征的数据存储到数据库中,而后减少无线数据的行数。之后将处理后的数据进行整合,并完成用户识别,将识别后的数据设定为如表1格式。
采用此部分设计的采集方式,并将采集到的信息采用以上方式完成存储与整理[10]。采用此数据作为用户画像构建的基础。
1.3 设定用户标签体系完成用户画像设计
采用上述处理完成的原始用户特征信息作为用户标签体系构建的数据基础,在此次设计中将用户标签体系设定为如表2 所示层级。
由于用户标签体系的构成较为复杂,在此次设计中,结合互联网金融用户的相关特征,将互联网金融用户画像标签体系设定为上述格式。在用户画像的构建过程中,标签体系是影响用户画像构建结果的重要影响指标之一。因而,在此部分设计中,务必使指标体系贴合用户画像的构建对象。
1.4 构建用户画像模型
采用上述体系的建设方法与建设规则,完成此次设计中的标签体系构建过程。在此次设计中,采用数据挖掘技术中的K 均值[11-12]计算方法,完成标签体系的聚类处理。设定采集到的原始数据为A={b1,b2,…,bn},其聚类类别数目为k,设定k 的初始系数为{∂1,∂2,…,∂n},设定聚类中心为C。若i=1,2,…,n,则信息样本bi到均系数∂j之间的距离为:
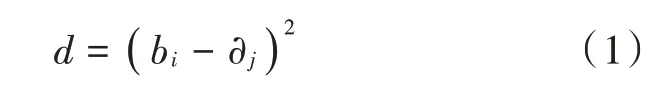

表1 互联网金融用户特征数据预处理结果

表2 用户标签体系层级及内容
通过式(1),选取距离均值数据,确定bi的簇标标记为:

将样本数据代入上述式(2)中,对样本进行划分,并计算出新的均值数据:
SCR3000/4500型燃气竖炉是典型连续式高温熔铜设备。从热工的角度分析,在设计容量相同的前提下,圆筒形竖炉与矩形竖炉相比,炉内体积更大,炉子容积热强度更大,小时吨铜熔化率更高,且炉型结构便于安装燃烧器,有利于组织合理的炉内气流流动,热交换效率更高,吨铜能耗更低。采用炉顶加料口加料方式,可缩短装料时间,实现快速装炉操作,提高装料作业率。
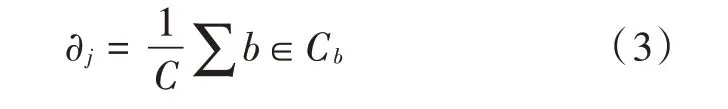
将上述计算得出的数据作为更新数据,对样本展开迭代计算,完成信息聚类,并将聚类后的信息作为用户画像的标签。
采用上述设计的标签体系,构建互联网金融用户画像。在此次设计中采用多层次的用户画像模型[13-14],实现对互联网金融用户的用户画像设计。具体模型如图3 所示。
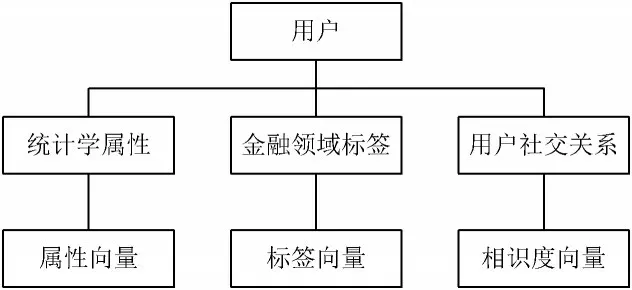
图3 用户画像模型
使用此模型,提升对互联网金融用户画像的设计效率。多层级的用户画像模型可将用户更加全面立体地展示出来,以便于对其研究。在此次设计中,引用TFIDF 算法[15]对标签体系中用户所占的比重展开计算,并将其带入到用户画像模型中,完成用户画像的设计。
将上述设计部分与原有用户画像设计技术相结合,至此,基于大数据的互联网金融用户画像技术设计完成。
2 技术测试
为保证上文中设计的基于大数据的互联网金融用户画像技术使用上的可行性,设定技术测试环节对文中设计的技术与原有的技术展开技术测试。通过两种技术对比的形式,获取文中设计技术与原有技术的使用差异性。
2.1 测试内容
针对网络数据量过大的问题,采用仿真实验测试的形式,完成文中设计的基于大数据的互联网金融用户画像技术与原有技术的对比。在此次测试中,为对文中设计技术进行具体的研究,将测试分为两部分处理。为保证此次测试的正常运行设定测试平台参数,如表3所示。
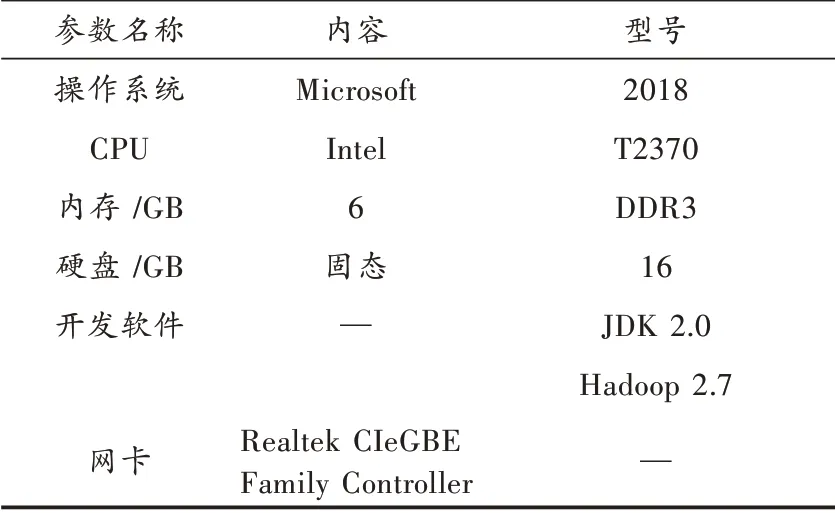
表3 测试平台参数
采用上述参数完成测试计算机的组装,设定此平台中共有6 台采用上述参数设定的测试计算机,将其组装为此次测试中的测试平台以及计算机网络。具体主机名称与节点如表4 所示。
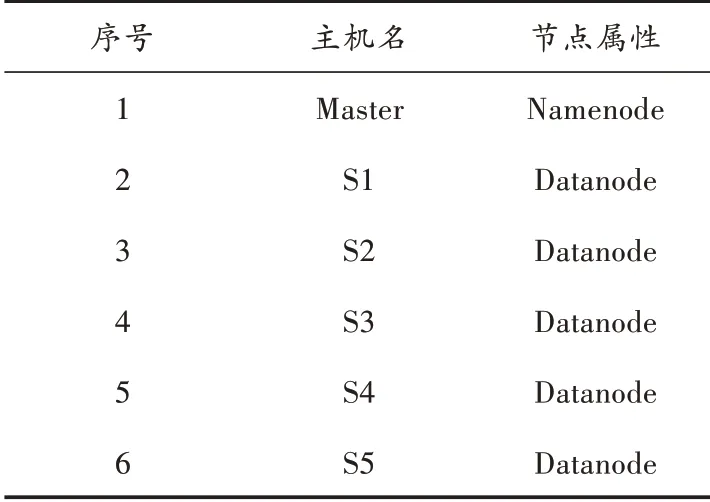
表4 测试网络节点设定
使用上述节点设计完成测试网络的构建。将网络结构设定为网络拓扑的形式,根据网络数据处理的相关要求,将此次测试中的网络拓扑结构设定为星型结构,具体结构如图4 所示。
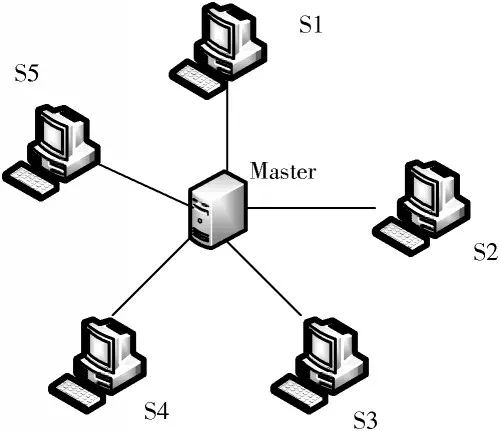
图4 网络结构示意图
采用上述网络结构对互联网金融交易展开仿真,并获取仿真过程中的用户数据以及交易信息。使用文中设计技术以及原有技术对上述网络中的信息进行聚类处理,并完成测试过程。在此次测试中将对原有技术与文中设计技术的信息聚类能力进行测试,将测试分为两部分,首先为信息等级明确的信息聚类。而后为信息量增大后信息等级类别不清时的信息聚类。使用上述设定完成此次测试内容。
2.2 信息等级明确测试结果
在信息量较为固定时,原有技术与文中设计技术的测试结果如图5 所示。
通过上述测试结果可以看出,在用户信息等级明确的前提下,文中设计技术的信息聚类能力优于原有技术的信息聚类能力。在用户标签数目相同的情况下,文中技术可对信息进行全部聚类,原有方法聚类能力较差,造成部分信息数据遗漏的问题。文中设计技术对于信息的聚类划分较为清晰,并未出现新消息数据聚类不清的问题。由此可知,在信息等级明确的前提下,文中设计的基于大数据的互联网金融用户画像技术的聚类效果更佳。
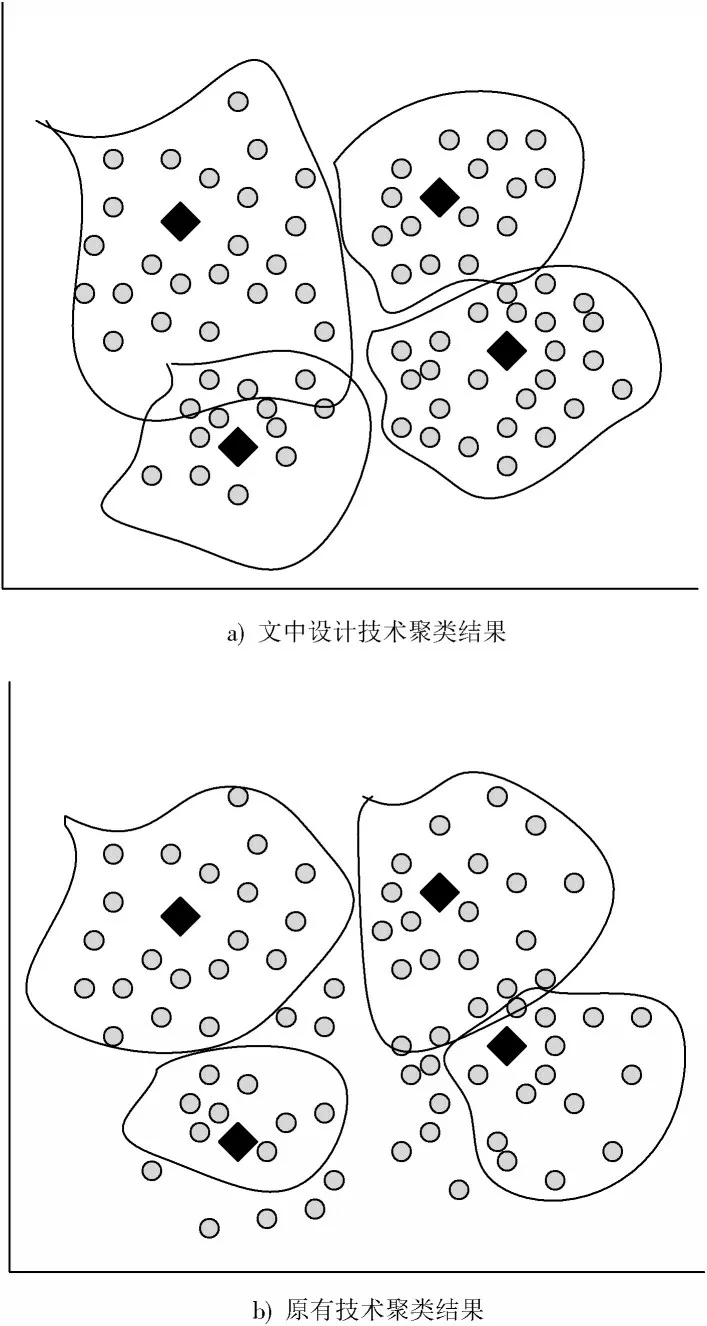
图5 信息等级明确测试结果
2.3 信息量增大后信息等级类别不清测试结果
在此次部分测试中,在原有的信息基础上增加部分信息,此信息中包含不同类型、不同等级的信息数据。设定此次测试中的基础迭代次数为30 次,迭代次数的上限为40 次。对比原有技术与文中设计技术的均方误差和,具体测试结果如表5 所示。

表5 信息量增大后信息等级类别不清测试结果
通过上述实验结果可知,文中设计技术在原有技术的基础上,聚类的正确率明显提升。且迭代次数相同的情况下,文中设计技术的均方误差降低幅度较低。将此测试结果结合上部分测试结果可知,文中设计的基于大数据的互联网金融用户画像技术对于用户信息的聚类能力优于原有互联网金融用户画像技术。
通过对以往文献的分析可知,用户画像技术中的信息数据聚类能力直接影响到用户画像的构建精度。由此可知,文中设计的基于大数据的互联网金融用户画像技术在使用中,其性能会明显优于原有的用户画像构建技术。
3 结 语
针对互联网金融用户画像这个问题,在本文中首先对用户的用户特征数据进行采集,从用户画像的构建根源提升画像设计结果的可信度。通过研究可知,在用户画像的构建中增加相应的大数据技术,对于互联网金融用户画像日后的研究具有一定的帮助。因而,在日后研究中,可将文中设计技术进行广泛的应用。



