杨立东,张壮壮
(内蒙古科技大学 信息工程学院,内蒙古 包头 014010)
0 引 言
音频场景分类(Acoustic Scene Classification,ASC)属于计算机听觉场景分类的(Computational Auditory Scene Analysis,CASA)研究领域,是通过对音频的环境场景进行识别,将语义标签与每个音频场景相互关联在一起[1]。音频场景分类应用于很多方面,例如:老年人的监护、多媒体内容的自动标注、生活日志的采集、机器人的导航系统等。具体来说,智能手机可以持续感知周围的环境,当进入音乐厅自动切换到静音模式;助听器辅助装备可以根据室内或者室外环境识别来调整其功能等等。
音频场景分类主要包括特征提取和分类器构建。常用的特征提取方法有log-mel 特征、MFCCs(Mel-Frequency Cepstral Coefficients)和mel 特征。特征提取的目的是提取出可以代替原始音频信号的数据。近几年,卷积神经网络(CNN)成功应用于分类任务中,大大提高了准确率,同时在音频场景分类中也得到广泛的应用。CNN 具有局部连接和权值共享的特点,大大减少了参数的数量,提高了训练速度,减少过拟合,提高了模型的性能。而传统的分类器模型,如支持向量机和随机森林分类准确率不高,所以以卷积神经网络模型的分类算法比较流行。文献[2]中提出CNN 在音频场景分类任务中的应用,通过训练好的CNN 直接用于声谱图对音频短序列进行分类。文献[3]提出一种时间延迟神经网络,是通过考虑声音信号在时间轴上比频率轴上更具有相关性而改进的网络模型。文献[4]中通过简化CNN 网络模型,模型复杂度降低,训练时间减少,分类准确率提高,相关文献可以看出CNN 已广泛应用于ASC。CNN 模型虽然可以直接提取谱图中的特征,但随着网络层数的增加,模型会出现梯度消失和过拟合等问题,模型分类的准确率不能得到提高,针对CNN 模型对音频场景分类的性能问题,对CNN 进行改进。
基于改进的CNN 算法模型应用到音频场景分类中,对音频文件进行重新采样,生成对数梅尔谱图,CNN对谱图进行特征提取,通过Softmax 分类器模型对音频标签进行分类。与其他传统的分类方法相比,提出的算法具有两个优点:对音频进行预处理,重新对音频数据采样,每类数据统一时长,输入卷积神经网络中谱图的大小相同;改进的卷积神经网络提取具有128 维语义信息的特征,分类准确率提高。
1 特征提取
音频预处理是将原始采样率为48 kHz 音频数据重新采样成16 kHz 的单声道wav 格式数据,为了得到平稳的信号,对输入的音频文件进行分帧处理。采用帧长N =25 ms,帧移M =10 ms 得到一个周期性的平稳信号。分帧之后进行加窗处理,窗函数对输入的信号进行振幅调制,减小截断边沿处信号突变产生的额外频谱,使每一帧信号幅度在两端趋近于零,保持信号的连续性。窗函数选择汉宁窗,汉宁窗又称升余弦窗,优于矩阵窗,它使主瓣加宽并降低,旁瓣减小,旁瓣衰减速度减慢。一般汉宁窗函数见式(1):

通过分帧和加窗得到连续平稳的音频信号,对信号进行短时傅里叶变化,求得其频谱,短时傅里叶变化可以得到时域和频域的特征,短时傅里叶变化公式为:
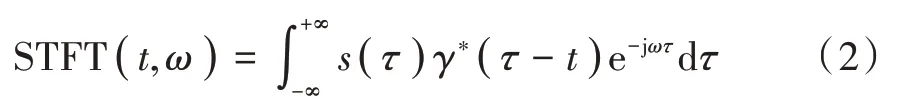
式中:S( τ )为原函数;γ( t )为窗函数。
将短时傅里叶变换得到的频谱映射到具有64 阶梅尔滤波器上,从而得到梅尔谱图,对其求log 得到需要的log-mel 谱图,提取过程如图1 所示。
2 改进CNN
Vggish 卷积神经网络是由Google 声音理解团队发布的VGG 模型的变体模型[5],VGG 属于CNN 的一种,CNN 主要通过卷积核对谱图进行卷积操作,即矩阵乘以权值,加上偏移,然后用激活函数处理,每个卷积核在每一层卷积层都使用同一组权值,大大减少了权重的数量,池化层普遍采用最大池化层,对输入的特征图进行下采样,舍弃一些没有的特征,减小特征图的大小,达到降维的效果,防止过拟合问题。其特征映射为:
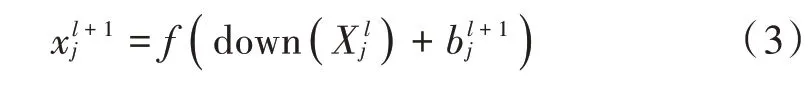
式中down 为下采样函数,一般有最大池化和平均池化。
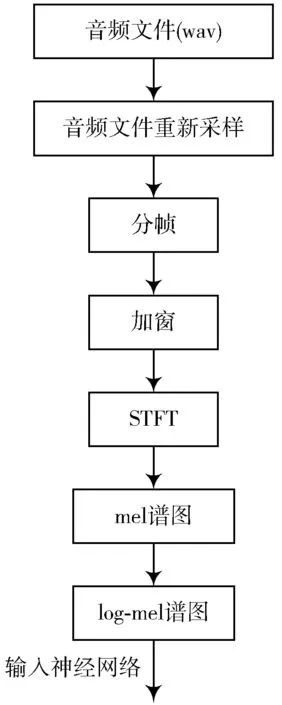
图1 特征提取过程
改进的卷积神经网络由5 个卷积层、4 个池化层、3个全连层、1 个embedding 层和softmax 层组成。输入神经网络的对数梅尔谱图大小为94×64,卷积核为3×3,步长为1。在第4 个卷积层和池化层直接加上dropout 函数,训练时丢失一些神经元,防止神经网络模型的过拟合。卷积层之后使用ReLU 激活函数,它的一般形式为:

ReLU 激活函数与其他激活函数相比,能克服梯度消失的问题并且加快了训练速度,减少了参数的相互依存关系,缓解了过拟合。池化层的池化核为2×2,步长为2。全连层神经网络个数为256,256,128。全连层之后加一个embedding 层,主要是通过权重矩阵降低维度,Softmax 输出层神经元为10。网络结构模型如图2所示。
Softmax 适用于二分类和多分类的问题[6],这里用于解决音频场景的10类分类问题。假设输入每一个类别j 估算出概率值,类别标签则期望概率p( y=j| x )是估计x 的每一种分类结果出现的概率,假定函数hθ( x )的形式如下:
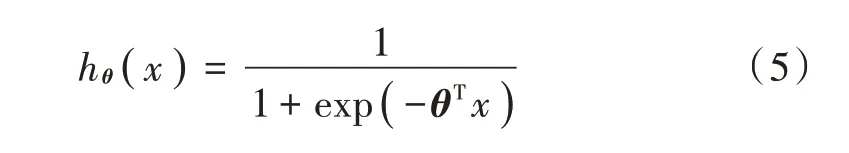

图2 网络模型
由期望概率将式(5)转化成:
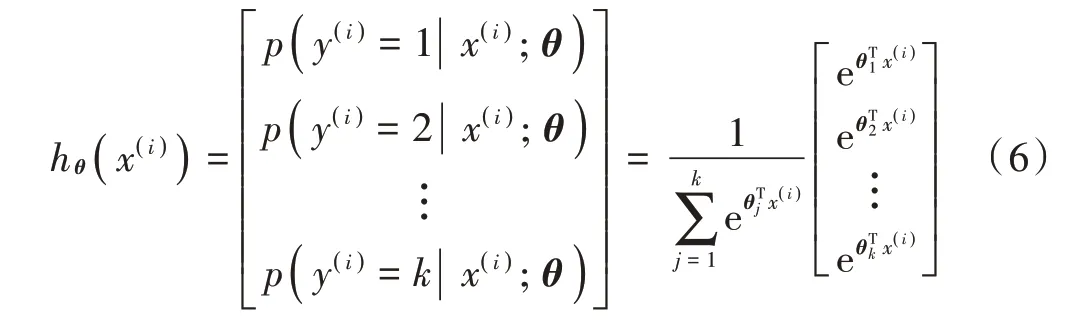
式中:θ1,θ2,…,θk∈Rn+1,是模型的参数量,对于单个样本所属类别的期望概率如式(7)所示:
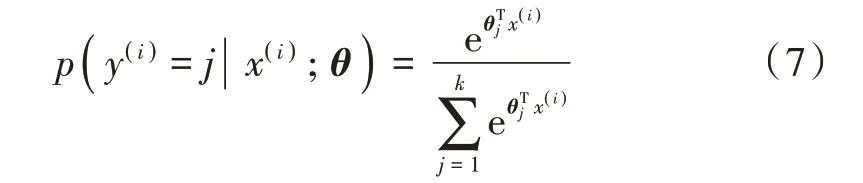
式(7)表示对概率分布进行归一化,使得所有概率之和为1。加入正则化后Softmax 代价函数定义为:

式中m 代表样本数量。
3 实验与分析
3.1 实验数据集
实验采用纽约大学公开的城市声音数据集UrbanSound8K[7],它是由8 种732 个声音片段组成,其持续时间最长的为4 s,取自现场的录音。数据集分为10个不同的环境声音场景包含了空调、汽车喇叭、儿童游戏、狗叫、钻孔、发动机空转、枪击、手提钻、警笛和街头音乐。音频文件保存格式为wav,采样率为44.1 kHz,每个场景的数据集样本个数如表1 所示。实验过程中使用规定好的10 个文件夹进行十折交叉验证。9 个作为训练数据集,用1 个子集作为验证集。进行10 次实验取平均值。
3.2 实验环境与参数设置
深度学习中常用Tesorflow 框架,实验硬件环境为Intel Core i7-8700@3.70 GHz-CPU,16 GB 内存,GTX 1080ti 显卡。改进的CNN 归一化网络参数权值和偏移使用Adam 作为优化器对网络模型进行优化,实验中所有的网络采用均方误差作为损失函数,网络模型的学习率设置为0.001,输入数据采用小批量样本,设置为256。

表1 UrbanSound8K 数据集
3.3 实验结果对比
为了验证算法的优势,在相同的音频数据集UrbanSound8K 中与现有文献中的方法进行对比。以分类准确率作为评判模型的准则,主要对比VGG 网络[8]、SB-CNN[9]、CNN[10]、EnvNet-v2[11]和2DCNN[12],对比结果如表2 所示。实验主要以分类准确率作为衡量性能的指标。

表2 不同方法对UrbanSound8K 数据集的分类精度
从表2 中可以看出:对于特征输入普遍采用mel 谱图,说明梅尔谱图在音频中应用广泛,可以很好地表达出音频的特性,适用于大多数模型;网络的最终结果与模型的复杂程度没有直接的关系,模型的好坏主要取决于特征的处理方式以及模型的参数优化设计;而改进算法对音频文件进行预处理可提取有效的音频特征,经过改进的卷积神经网络训练,分类准确率提高,不管是在特征提取还是在分类器模型上都对系统模型进行了优化,使系统模型的准确率比其他方法模型的准确率高很多。
选取每类音频场景进行单项测试得到分类准确率结果如表3 所示。从表3 中可以发现汽车喇叭分类准确率相对较低,由表1 看到汽车喇叭音频数据集个数太少,模型没有提取到有效的音频特征,导致分类准确率低,钻孔的分类准确率不是很高,大多数把钻孔识别成手提钻的声音,它们之间存在一定的相似性,从mel 谱图(图3)也可以看出,log-mel 谱图是对其做了log 运算。警笛准确率也很低,在于狗叫和警笛持续时间短、音调高,分类时容易识别错误。

表3 分类准确率

图3 mel谱图
4 结 语
基于改进卷积神经网络模型对音频场景分类,一方面主要在特征提取时,通过分帧加窗等预处理转成logmel谱图,提取有效的特征,另一方面对Vggish 网络进行优化,实验结果显示准确率有很大的提高,满足分类任务的需求。对于存在一定相似性的音频应该考虑提取混合特征,这样可以充分学习到音频特性,更好地提高分类准确率。



