赵 健,连 玮
(长治学院,山西 长治 046011)
0 引言
在创建智慧交通城市背景下,各设备在使用过程中产生的交通数据量比较大,此数据的主要特点是动态变化、复杂及多样化,缺少相应的存储规范与标准。所以,如何分析海量交通数据,以此提高数据使用率,提供给城市交通管理相应的依据就显得十分重要。在传统数据处理中,利用高性能方式进行计算,所使用的资金成本和时间成本比较多,Hadoop 技术能够提供大数据处理和存储方案,利用此技术能够通过低成本的运行处理大数据[1]。基于此,本文利用Hadoop 技术处理交通信息,并且存储在HBase 分布式数据中,实现高效实用城市交通数据存储平台的设计。
1 Hadoop 分布式并行计算框架
1.1 Hadoop
Hadoop 分布式框架能够存储超大型数据集,在处理数据过程中切分数据存储到集群子节点中,此框架的扩展性、容错性与可靠性良好,并且界面管理页面简单易操作。图1 为Hadoop 生态系统结构。
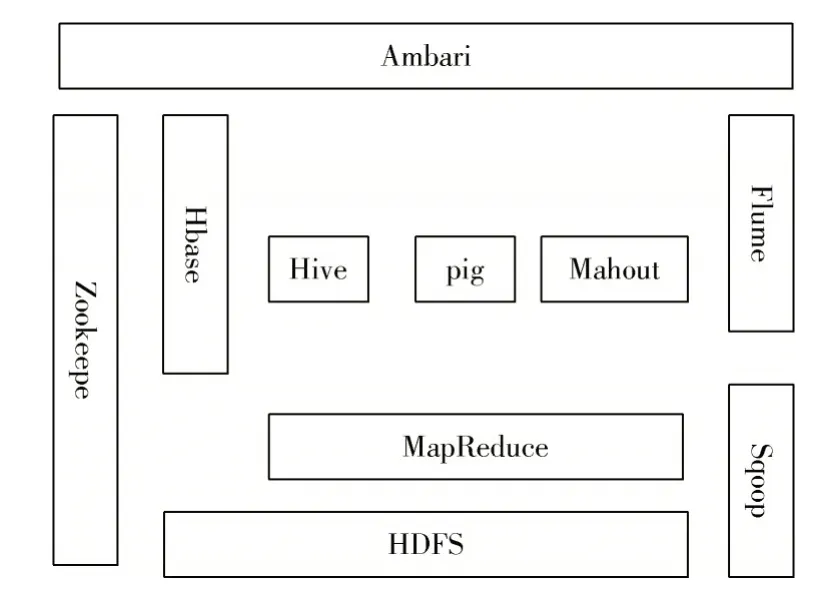
图1 Hadoop 生态系统结构
1.2 Hadoop 的体系结构
HDFS 分布式文件系统处于Hadoop 生态系统结构最底层,其能够存储大量分结构化数据,到上层提供计算资源。MapReduce 分布式并行计算框架能够将计算任务分布在多个节点中,写入到磁盘中保存。HBase 分布式数据库具有较高的效果,可靠性与伸缩性良好,能够批量写入数据,实现数据存储与并行计算。Zookeeper 能够管理数据,被广泛应用到各个集群中。Flume 能够对日志进行收集,并且实现数据预处理[2]。
1.3 HBase
传统数据存储处理系统已经无法满足大数据的需求,HBase 模块在Hadoop 生态系统中尤为重要,利用分布式存储方式进行存储,实现存储方式的创新,通过定义对规则进行查询,实现数据库自动索引,使其中的列存储数据有所增加。如果数据是空,那么就不存储,节约硬盘空间。以实现列字段数据的存储,从而提高查询效率。HBase 能够自动切分数据,还能够实现高并发读写。此特点能够使交通流数据的处理得到满足,使交通数据种类动态减少,并且将数据特征充分展现出来,从而实现实时查询数据[3]。
2 系统的架构设计
本文所设计系统是将Hadoop 分布式架构作为基础,Hadoop 框架核心为HDFS 与MapReduce,HDFS 能够实现底层数据存储,MapReduce 能够实现海量数据计算。Hadoop 的主要特点就是可靠性、高效性与可扩展性,以交通大数据特点设计交通信息并行处理云系统,图2 为系统的结构。此系统总体架构包括应用层、采集层、分析层与存储层[4]。数据采集层包括静态与动态的数据收集,动态数据主要包括线圈收集流量数据、车速数据与车型数据,卡口数据主要包括采集时间、车牌数据等。静态数据主要包括路段信息等,并且信息不会由于不同采集时间对数据改变。动态数据通过整合后到分布式数据库中存储,静态数据以后期本体模型映射成为RDF 数据实现存储。
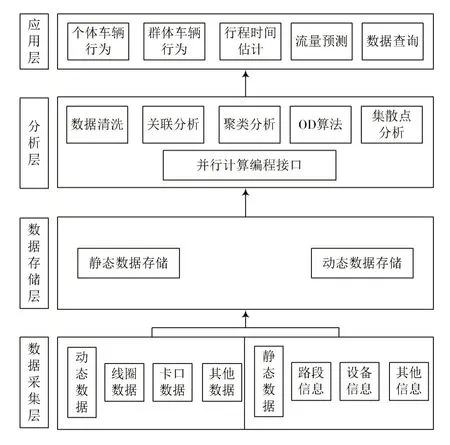
图2 系统的结构
数据分析层以交通大数据的不同分析需求,使用MapReduce 编程模型实现数据计算与处理,在系统中使用聚类分析、关联分析、数据清洗等模块。因为外界因素干扰与数据采集设备的问题,首先就要清洗数据,将异常与不合理的数据去除[5]。
关联分析与聚类分析为数据挖掘主要分析方法,并且能够在交通拥堵中充分使用。比如关联分析,对于拥堵瓶颈点、选择车辆属地、型号和天气情况等信息实现关联挖掘,对交通拥堵影响的主要因素进行确定。聚类分析能够利用迭代运算寻找合适中心值,划分交通流量密度等级,方便出行者参考[6]。数据存储层能够使收集的数据在Hadoop 计算机集群中存储,计算机集群使用主从架构,主节点指的是管理节点,具有一个记录数据存储位置。在此框架中,动态数据整合成为达标数据,在Hive 数据仓库中存储;静态数据以本体模型实现映射RDF 数据,之后在HBase 分布式数据库中写入。
通过数据分析层的计算结果,通过接口提供给交通行业各用户服务,根据用户不同需求提供不同计算结果,并且在数据分析层设置全新计算模块,使全新需求得到满足。比如,OD计算结果能够实现个体出行行为与群体出行行为的分析,聚类分析结果能够估计行程时间[7]。
3 系统的模块设计
3.1 数据的接入设计
3.1.1 实时数据处理
启动消息队列服务,在系统缓冲池中接入用户数据源,将数据源层数据源和模组接入,从而有效读取配置,对外服务。用户将任务发送给系统后,系统能够对任务进行解析,之后发送数据并且存储。系统外部应用程序接口对系统发送数据,缓存到消息队列,通过在线处理方式处理数据。
利用C/S 架构在数据源接入层实现数据接入,外部应用指的是Client,并且发送到Server 后进行确定,或者不通过确定对数据发送的方式实现数据传输[8]。图3 为数据的介入流程。
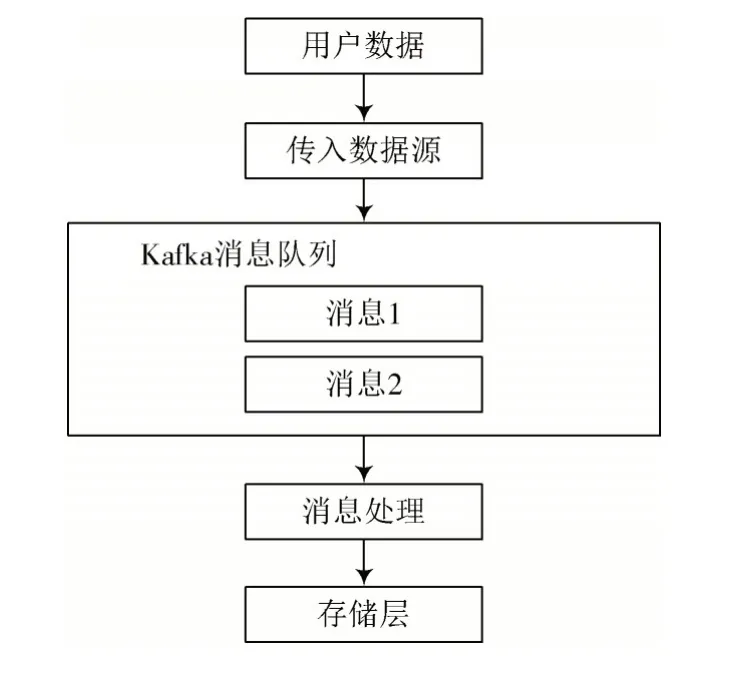
图3 数据的介入流程
3.1.2 数据处理模式
通过数据过滤、统计、提取和聚合实现数据处理。图4 为数据处理的流程。
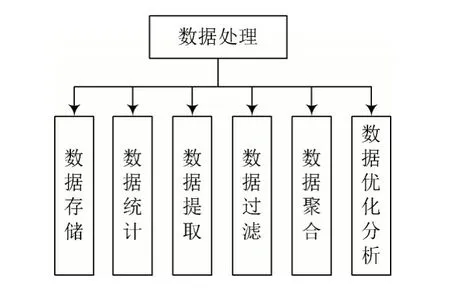
图4 数据处理的流程
3.1.3 实时处理模块
通过核心计算、数据接入和存储创建实时处理模块[9],数据接入的工作流程见图5。
通过消息队列、服务器、消息通信和客户端创建模块,客户端流式发送数据到服务器中,为了提高消息传输的效率和质量,将Retey 机制添加到客户端中,在调用5 次失败之后就会失败[10]。
客户端在调用失败后会出现异常,处理异常化处理器,响应客户端请求。所以,利用线程池模式让服务器工作,设置最小最大的线程数为8 和256,使服务器响应速度得到提高,降低资源消耗。在Linux 机器中部署Kafka 消息队列,使同一个数据源消息默认分区数量为10。生产者在Kafka 中的产生消息,发送至服务器,供消费者使用。
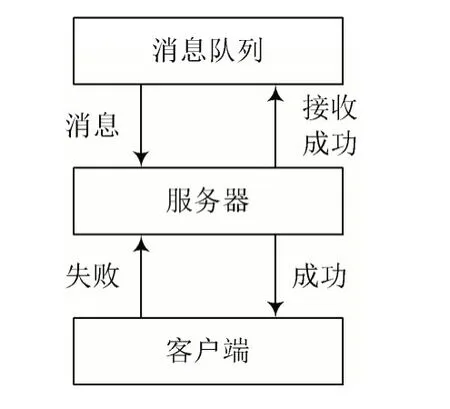
图5 数据接入的工作流程
3.2 数据存储模块
数据存储模块能够通过数据缓存、写入与预处理等数据[11]。存储公交浮动定位器中数据、刷卡信息等数据。图6 为数据存储模块的结构。
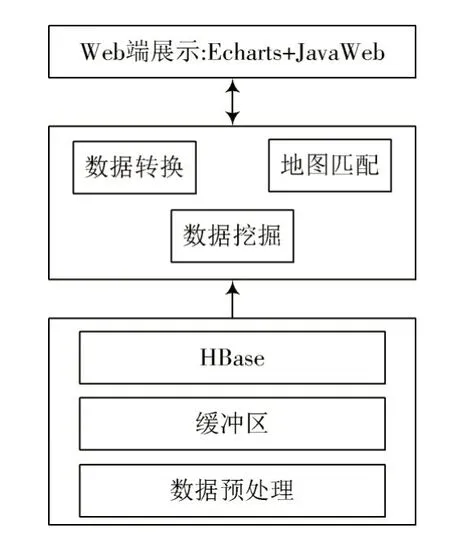
图6 数据存储模块的结构
数据预处理:能够处理不同来源的交通数据,保证数据的有效性。GPS 实时定位数据能够分析关键数据,但因为数据发送端中的设备不同于数据格式、载体,可对数据接收格式进行统一。公交卡的数据格式包括卡号、刷卡时间等,数据格式包括时间戳、经纬度和瞬时速度等,以此将不规范的数据排除。
以下为数据存储的实现代码:


数据缓存区:由于实际需求和通信成本,客户端中的周期设置为30~60 s。为了提高数据的写入速度,充分考虑磁盘读/写的吞吐率、缓存数据,将时间戳作为标记,满1 h 实现数据缓冲,也就是通过时间戳对数据进行标记且缓冲。
数据写入与存储:接收缓冲区发送数据,自动生成数据脚本并且执行,写入到分布式数据库中。单位设置为天,实现表格的创建,当天写入的数据追加到当天表中。
3.3 数据处理模块
由于公交车GPS 设备位置信息存在偏差,不同于本地路网坐标系,以此转换信息坐标并且匹配地图。数据处理能够处理HBase 中的数据,之后存储HBase 中的结果。
通过大规模定位数据计算道路的匹配信息,首先设置输入/输出路径,通过主函数启动作业,执行Map 任务,利用MySQL 数据库在内存保存数据。Map 通过接收键值对,以方向、经纬度和时间等信息对数据解析。调用数据,利用逐级网格索引匹配,得出匹配结果。处理步骤为:
1)Map。读取公交车的位置信息,从而能够得出速度值、公交车ID、时间属性和经纬度;
2)Reduce。利用路网坐标体系的转换公式对信息进行转换,并且对坐标进行匹配,得出精准信息后对经纬度坐标进行匹配,将公交车信息进行输出。
3.4 交通应用架构
承载平台指的是并行交通信息处理云平台,运行交通应用能够对数据进行计算,应用计算结果,通过可视化角度提供给用户查询、预测和分析等服务。利用承载服务处理原始数据为系统设计中的重点,交通应用服务架构见图7。
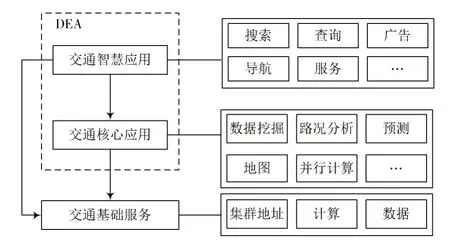
图7 交通应用服务架构
基于此,在设计系统中划分交通云平台为智慧应用和核心应用。底层为交通基础服务,能够将原始数据服务、计算中心地址提供给上层应用。中层为交通核心层,通过服务实例对原始数据进行计算。应用架构中层为交通核心,通过服务实例计算原始数据并且存储,对整体平台功能可行性、正确性进行验证。交通智慧应用处于顶层,且对用户展示,得出交通核心结果,利用可视化展现。
3.4.1 交通核心应用
通过计算机MapReduce 框架实现开发,以出行服务、交通指导、公路网络监控等为主要需求,和数学分析算法结合,分析收集的交通海量信息,从而对交通系统道路通行的情况随时掌握,实现交通疏导、道路拥堵预警等智能交通行为。
设计交通信息并行处理平台对外接口使用原始JAR 包上传到平台,通过平台功能创建数据库表,并且导入原始数据,云平台后台在底层Hadoop 集群中拷贝应用在多节点中实现任务的分发,利用HDFS 原始数据计算节点,汇聚信息并存储。
3.4.2 交通智慧应用
图8 为交通智慧应用结构,为处理平台提供可视化入口,服务于互联网用户。利用平台底层服务体系对交通核心计算结果相互绑定,利用Web 服务进行发布。开发者利用平台中的服务与交通核心应用结果,对外提供路况分析、导航、购物、预测等应用。
4 系统的验证和使用
将本文系统在某交通平台中运行,以GPS 数据处理应用为例,充分展现数据处理组件集成开发环境、系统管理工具与处理应用开发工具。
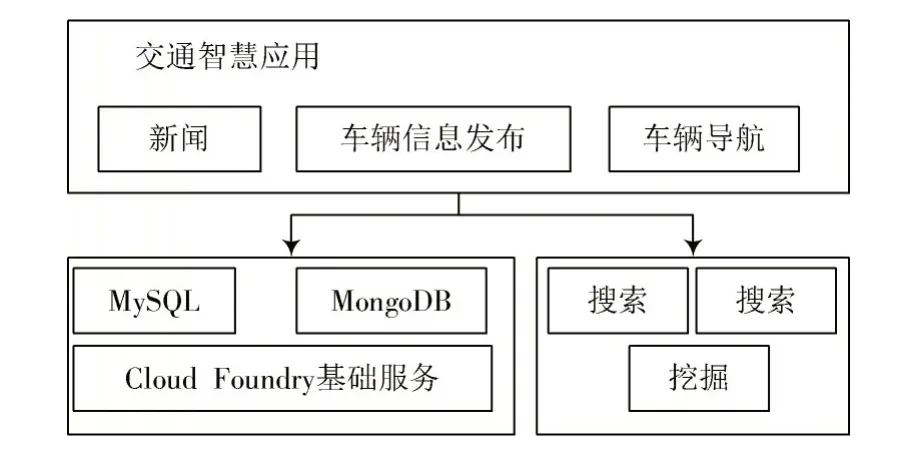
图8 交通智慧应用的结构
开发者在集成环境中使数据处理组件到云平台中提交,利用云平台数据对组件管理工具进行处理,管理组件。图9 为数据处理组件的部署。
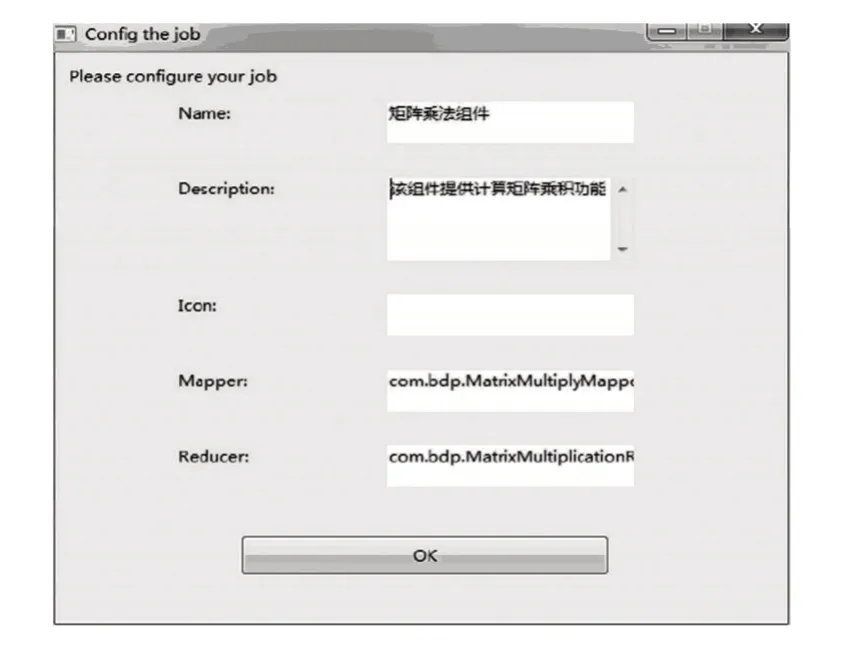
图9 数据处理组件的部署
开发者在对数据处理组件部署后,数据分析专家通过可视化数据处理应用模板开发工具,为数据处理应用制定执行计划。图10 为交通信息并行处理系统的主页面,左侧为导航页,右侧为显示内容区域,主要包括数据处理组件管理、模块管理、应用模板开发等。
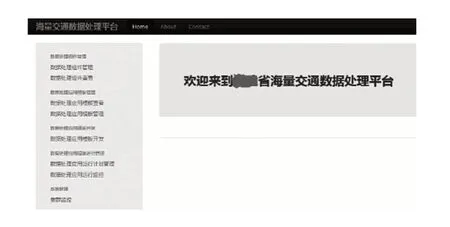
图10 交通信息并行处理系统的主页面
通过本省实际使用情况表明,集成开发环境能够提供给数据处理组件开发者一体化程序开发、部署与测试的工具,提高应用执行效率,有效分析交通信息,提高集群监控管理功能。
5 结语
本文基于城市交通现状与大数据发展的情况,提出了基于Hadoop 平台实现实时数据处理系统的设计,能够解决传统平台无法为多用户提供实时操作数据的问题。HBseBolt 组件能够在数据库中存储消息序列,使数据样例转变成为数据源组件,所发送的信息都能够被及时的捕捉和处理。系统所使用的信号量机制控制对于不同时间粒度能够控制数据的分流。利用系统的实现,本文所设计的系统能够使交通大数据应用需求得到满足,不仅实现离线数据的分析,还能够实时反映交通情况。通过此平台所得出的分析结果能够再次使用,以此为交通管理、研究与规划提供支持。在今后工作中,要充分挖掘异构交通数据,寻找数据深层次价值,使交通拥堵情况得到缓解,为侦破交通案件提供有利的支持。



