杨治学,黄 浩,3,胡 英,吾守尔·斯拉木,3
(1.新疆大学 信息科学与工程学院,新疆 乌鲁木齐 830046;2.新疆多语种信息术实验室,新疆 乌鲁木齐 830046;3.新疆多语种信息技术研究中心,新疆 乌鲁木齐 830046)
0 引言
随着互联网的发展,各种移动电脑设备和手机被广泛使用,人机交互系统已经运用在人们生活中的各个方面。指纹、掌纹和人脸识别已经广泛运用在各个行业领域,如安防、金融等。其中,基于语音的声纹特征,由于识别成本低,可以进行远程操控,而且随着移动设备和手机的普及,语料的采集也比较方便,得到了学术界和工业界越来越多的关注。除声纹识别之外,通过语音来识别性别和年龄等说话人属性的特征也越发受到关注。人的声音会随着年龄的变化而变化,如声带、声道等,还会随着身体状况和所处的社会环境不同而不同。说话人的年龄分类是基于上述原因,通过说话人的语音对说话人年龄的大致估计,从而提供更具有个性化设置的人机交互服务,可以将字体放大和放缓语速来方便老年和幼年人群的操作,提升用户的使用体验。
在说话人年龄分类任务中,主要研究工作集中在语音的特征提取和模型匹配这两个环节。从声学特征的提取来看,声学特征有线性预测(LPC)系数、感知线性预测系数(PLP)、梅尔频率倒谱系数(MFCC)以及滤波器组(Filter Bank)。从模型匹配环节来看,对说话人的年龄估计的研究包括支持向量机[1](SVM)和高斯混合模型[2](GMM)、在说话人识别方面提出的高斯混合模型⁃通用背景模型(GMM⁃UBM),以及文献[3]运用的联合因子分析(JFA)技术和i⁃vector[4]等。
近年来,由于i⁃vector 方法在说话人识别方面获得了巨大成功,在年龄识别方面,也开始使用i⁃vector 结合单独的神经网络后端来对说话人年龄段进行识别[5⁃7]。文献[7]结果表明利用i⁃vector 结合ANN 的年龄识别效果要优于传统方法SVR,但是对i⁃vector 的提取步骤多,计算复杂,随着深度神经网络(DNN)在各个模态智能识别领域,特别是在语音识别领域的广泛运用,DNN 已经逐步呈现对i⁃vector 的替代。在说话人识别中,基于深度神经网络的d⁃vector[8⁃9]和x⁃vector[10]的出现,通过深度神经网络提取语音特征进行分类识别,可以大大降低辨识的系统复杂度,提高分类速度。本文提出一种基于深度神经网络的说话人年龄分类的方法,通过深度神经网络来提取说话人更深层次的语音特征,并对其进行分类,实现了特征提取和后端分类器的联合参数调优,模型比i⁃vector 分类模型更加便捷高效。结果表明,这种基于深度神经网络的说话人年龄分类方法可以提高识别准确率。
1 基于i⁃vector 的说话人年龄分类
传统的基于GMM⁃UBM[11]的识别方法,由于说话人语音的录制环境和测试的环境不匹配,常常会导致系统性能不稳定,鲁棒性差。为了解决该问题,文献[3]运用联合因子分析(JFA)的说话人识别方法,该方法认为说话人的GMM 模型的差异是由说话人的差异和信道差异这两个部分组成的,即说话人相关的超矢量和信道相关的超矢量两部分。JFA 方法将这两个超矢量分开表示,但是在JFA 模型中信道因子和说话人因子是不可能完全分开的,信道因子中有可能会含有说话人的信息,强行将其分开就会造成说话人信息的损失。针对该问题,随后出现了i⁃vector 模型,将说话人信息和信道差异作为一个整体,可以大大降低计算复杂度和对训练语料的要求。
1.1 声学特征提取
i⁃vector 以 语 音 的MFCC(Mel Frequency Cepstral Coefficents)特征作为输入,MFCC 是Mel 频率倒谱系数的缩写,是一种模拟人耳听觉频率的语音特征量,广泛应用于自动语音识别和说话人识别,也在说话人年龄估计中有着较好的表现。它与频率的关系如下:
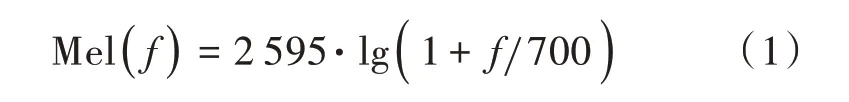
在说话人年龄分类问题中,首先对语音进行语音的端点检测(Voice Activity Detection,VAD),也就是通过语音的端点检测来去除语音的静音部分,主要通过语音的短时能量和过零率来去除静音部分再提取MFCC 特征。MFCC 特征提取的流程有预处理阶段,主要包括预加重、分帧、加窗函数。预加重其实就是将语音信号通过一个高频滤波器提升高频部分,突出高频共振峰。分帧是将N个采样点合成一个观测单位,称为帧。将每一帧乘以汉明窗,以增加帧左端和右端的连续性。然后进行快速傅里叶变换(FFT)得到频谱的能量分布,再计算通过Mel 滤波器的能量,主要作用是对频谱进行平滑化,并消除谐波的作用,突显原先语音的共振峰。然后经过log 的对数能量变化,再求DCT 倒谱。MFCC 参数提取的原理框图如图1所示。
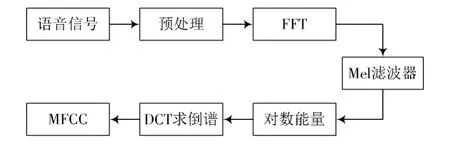
图1 MFCC 特征提取原理框图
1.2 i⁃vector 提取方法
将提取出来的语音特征(MFCC)映射成一个混合高斯GMM 的均值超矢量,但是可能由于训练语音不足,拟合的GMM 代表性不强,所以提出了通用背景模型[12](UBM)的说话人识别方法,所谓UBM 就是将一大部分人的语音数据看成一个人的,来拟合一个更大的GMM模型,而目标说话人的GMM 在UBM 模型上,通过MAP(Maximum A Posterior)参数估计算法得到。i⁃vector 将说话人和信道相关的超矢量统一建模,不区分说话人信息和信道信息。i⁃vector 建模的基本思想是利用提取的GMM 超矢量来提取一个更加紧凑的向量,即i⁃vector 向量。对于语音信号而言,GMM 的均值超矢量定义如下:

式中:M~N(m,TTT);ω∼N(0,I)。各个变量的维度关系如下:
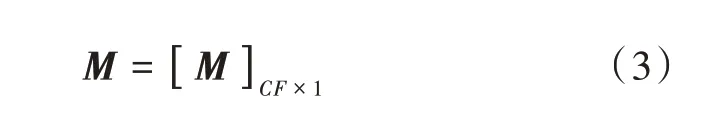
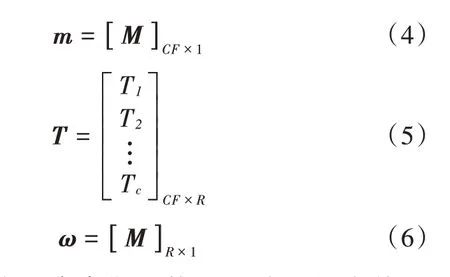
式中:C表示GMM 中混合高斯的数量;F表示语音特征的数量;M是提取的GMM 均值超矢量;m是一个与说话人和信道无关的超向量,是由通用背景模型(UBM)提取得到,表示语音数据中所有的语音变化;T是全局差异空间(Total Variability Space),它既包含了说话人之间的差异又包含了说话人信道之间的差异。T矩阵通过最大期望算法(Expectation⁃Maximization algorithm,EM)来得到,通过式(3)~式(6)就可以将GMM 均值超矢量映射到一个低维空间,就是i⁃vector,用ω表示。提取i⁃vector 的框图如图2 所示。
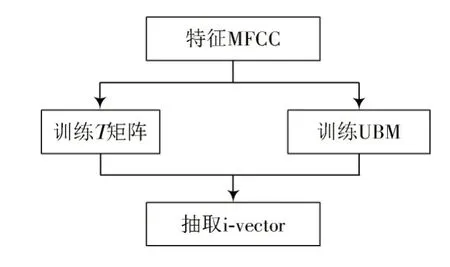
图2 i⁃vector 提取原理框图
1.3 基于DNN 的后端年龄分类器
本文利用kaldi 语音工具箱提取得到i⁃vector 特征之后,用人工神经网络(ANN)来做年龄的分类。该神经网络共5 层,包括一个输入层,输入提取的i⁃vector 特征向量,三个隐含层和一个输出层,输出为各个说话人年龄类别。分类神经网络构造图如图3 所示。
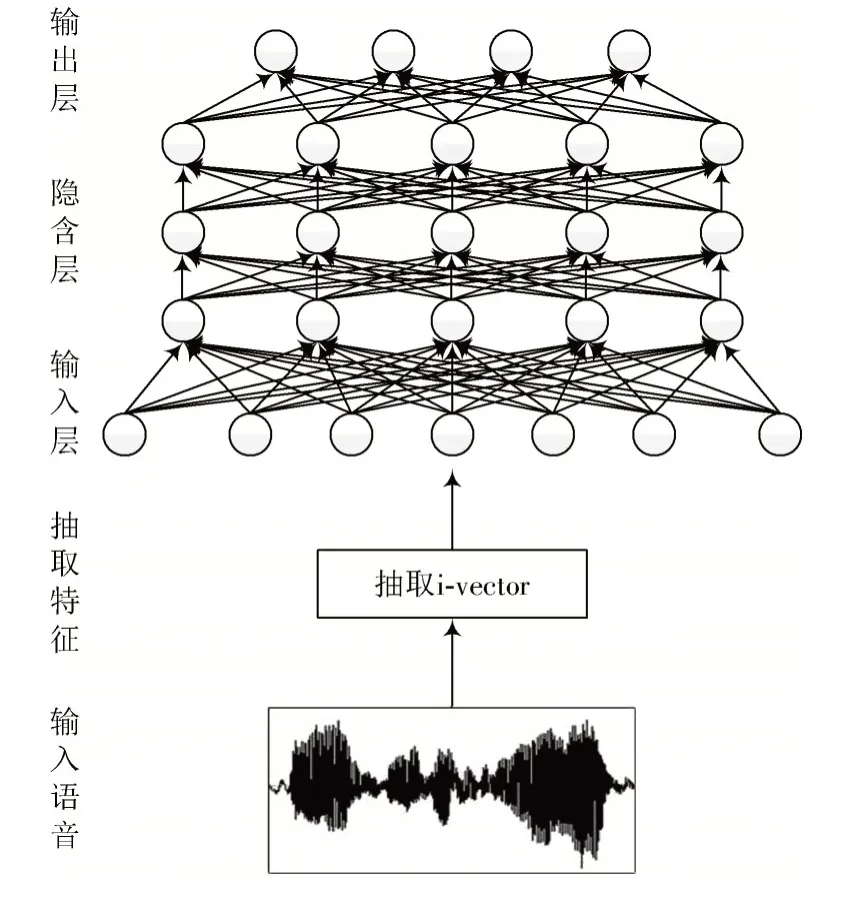
图3 分类神经网络构造图
2 基于深度神经网络的说话人年龄分类
基于深度神经网络(DNN)[13]强大的特征提取能力和近年来在语音识别和说话人识别中的成功应用,通过用深度神经网络(DNN)来找到一个更深层的语音特征。在之前的说话人识别领域,约翰霍普斯金大学和谷歌提出了d⁃vector 的说话人识别方法,d⁃vector 方法是使用DNN 来作为说话人特征的提取器,寻找一个更有代表能力的说话人识别特征来表征语音中的说话人信息。受到d⁃vector 说话人识别方法的启发,在说话人年龄识别中,直接用深度神经网络来做说话人年龄特征的提取,然后对其进行分类。
在这里提取说话人语音的对数频率滤波器组(Log Filter Bank,Fbank)特征。Fbank 特征较MFCC 特征的优点主要在于两点:一是计算量,Fbank 特征的计算量要小于MFCC 特征的计算量;二是特征区分度,MFCC 具有更好的判别度,可直接用于分类,而Fbank 特征却具有更好的特征相关度,多用于深度神经网络的特征输入。Fbank 特征的提取流程和MFCC 特征的提取少了DCT 求倒谱的环节,所以Fbank 的计算复杂度要低于MFCC 的计算复杂度。Fbank 所携带的信息量要大于MFCC,因为MFCC 在做DCT 的时候可能造成信息的丢失。通常MFCC 和混合高斯模型(GMM)能更好地结合使用,因为GMM 假设是三角协方差矩阵,而MFCC 中的倒谱系数也符合这种假设。
图4 描述了使用Keras 实现的进行年龄区分的深度神经网络结构,该网络结构的出发点来自d⁃vector 方法和语音识别模型,d⁃vector 的隐含层是全连接层,考虑到语音信号有时延的效果,利用卷积的时间平移不变性能够更好地克服语音的连续时间性和多样性。本文使用Fbank 特征,首先使用两层一维卷积和Maxpooling 层,然后是一个Flatten 层,将卷积网络的数据转化为一维,再进入四层全连接,每层512 个神经元,最后通过softmax层输出结果。DNN 的网络构架图如图4 所示。
3 实验与分析
3.1 实验数据
本实验采用AISHELL2 大规模连续语音识别数据库。该数据库包含了1991 个人的发音语音数据,共计1000 h。数据库对每个发音人的年龄段进行了标记。由于AISHELL2 的数据集年龄分布不均匀,16~25 岁人数远多于16 岁以下和41 岁以上的说话人,为了数据均衡,选择丢弃一部分数据,并使得男女比例均衡。训练数据一共选择272 人,其中,男性129 人,女性143 人,每人约500 句语音。测试数据选择一共31 人,其中,男性15 人,女性16 人。数据分布如图5、图6 所示。

图4 DNN 原理框图
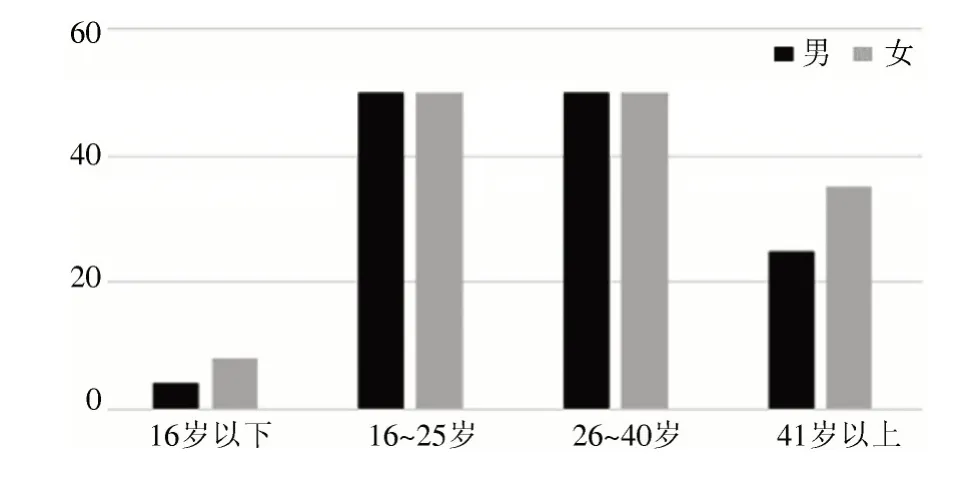
图5 训练数据分布图
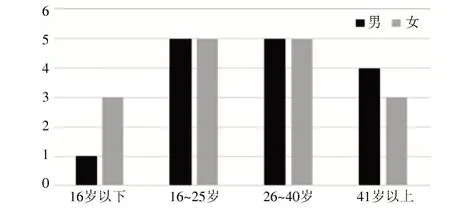
图6 测试数据分布图
3.2 i⁃vector 结合分类器的两阶段方法结果
i⁃vector系统使用说话人语音的MFCC特征,训练阶段分别使用了512,1024和2048个混合高斯模型,i⁃vector的维度分别设置为400维、600维。训练数据和测试数据没有说话人重合。神经网络后端的输入维度和i⁃vector 维度保持一致。说话人年龄分类结果如表1 所示。
在512 个混合高斯模型中,当i⁃vector 维度取600 维时得到的效果是最优的,准确率可达到89.18%。接下来进行了性别相关的年龄分类,将男性的语音和女性的语音分开之后,各自训练年龄分类模型,实验结果如表2 所示。
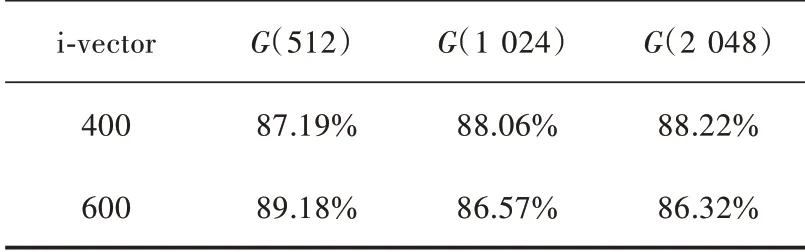
表1 i⁃vector 方法年龄分类准确率
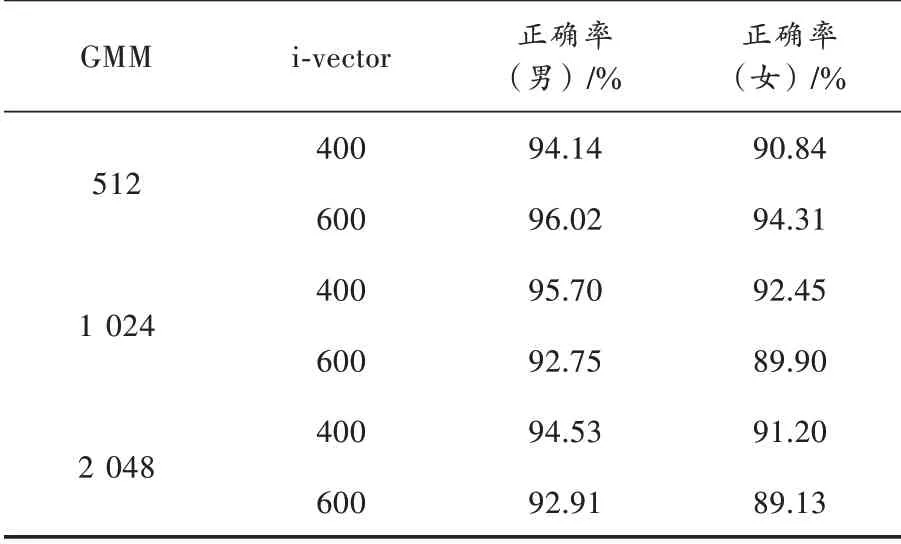
表2 i⁃vector 方法年龄分类准确率(性别相关)
实验结果与性别无关的模型结果基本保持一致,在512 个混合高斯,600 维i⁃vector 的情况下得到的效果最好。男性年龄分类最好能达到96.02%的准确率,女性年龄分类最好能够达到94.31%的准确率。通过以上的实验得到结论,提前对男女进行性别分类之后再按年龄分类能得到更好的效果。并且在本次实验选择的数据上,男性语音的分辨效果要比女性语音的分辨效果要好,男性的年龄分类准确率要比女性准确率高出2%~3%。
3.3 DNN 方法结果
本文利用深度神经网络模型的训练数据及测试数据和i⁃vector 基线模型的数据保持一致。通过提取语音的Fbank 特征,经过神经网路训练之后直接进行分类,这样减少了计算步骤,也减少了训练参数。还利用d⁃vector 网络模型做了对比实验。DNN 和i⁃vector 基线以及d⁃vector 模型的对比结果如表3 所示。
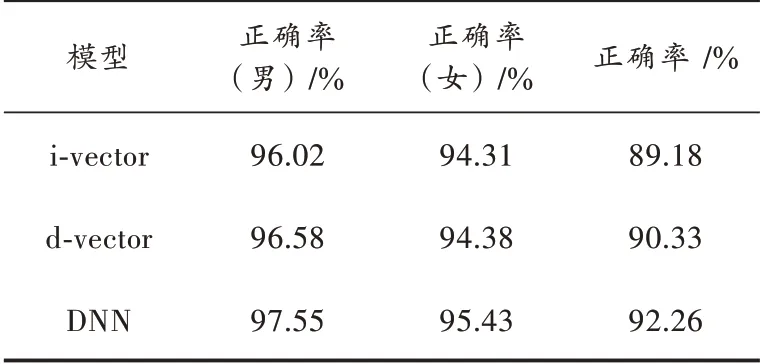
表3 DNN 对比i⁃vector 的准确率
由表3 可以看出,深度神经网络模型较i⁃vector 结合分类器系统和d⁃vector 模型的准确率都有所提升,深度神经网络模型较i⁃vector 系统中测试结果最优的准确率要高3.08%。性别无关模型的性能也要优于i⁃vector 基线方法。其中,男性年龄分类准确率要高出1.53%,女性年龄分类准确率要高出1.12%。与i⁃vector 两阶段年龄分类方法类似,男性年龄识别的准确率要高于女性。
4 结 论
本文提出一种基于深度神经网络的年龄分类方法,将声学特征直接送入深度神经网络来对说话人年龄分类,不仅提高了分类的准确率,而且降低了计算复杂度。在连续语音识别数据库上进行了性别无关和性别相关的年龄分类实验,实验结果都表明所提出的方法优于传统的i⁃vector 结合分类器的两阶段年龄分类方法。这种方法能够更加快速准确地运用于人机交互系统和金融安全领域。今后,将继续尝试使用不同类型的神经网络进行特征提取分类,并且尝试一些特征融合的方法。



