何云山,王占刚
(北京信息科技大学 通信学院,北京 100011)
0 引言
由于我国国土面积大、人口基数大,使得我国土地资源面临着巨大的压力,土壤环境污染问题严重。目前我国大约有1 6的耕地面积受到了不同程度的重金属污染,使我国居民的粮食安全受到了严重的威胁。在土壤重金属污染治理方面,由于土壤重金属污染修复治理周期长、花费高,所以我国对土壤重金属污染采用的措施多以预防为主。因此准确预测一片土地的重金属污染状态,才能减少土壤重金属污染治理的花费成本,对土壤重金属污染预防和治理有着推动性的作用[1]。
目前我国的区域环境监测体系还处于构建阶段,数据种类比较单一,数据分析手段仍处于初级阶段,缺乏大数据融合及深度挖掘方法,亟需构建针对土壤污染预测的数学模型。文献[2]通过随机森林(Random Forest,RF)算法分析土壤中各个重金属元素的主要来源,效果较为明显;文献[3]将支持向量回归(Support Vector Regression,SVR)模型应用在了土壤pH浓度预测上,预测效果较好。所以可以通过使用RF-SVR模型提取土壤重金属污染特征,再对其相关特征进行回归预测,从而达到估计土壤综合污染指数的目的。然而,SVR模型在单独进行土壤重金属污染预测时,存在模型参数在训练过程中选取盲目的问题,若参数选择不当,往往会让模型出现过拟合或欠拟合的情况[4]。因此本文使用遗传算法(Genetic Algorithm,GA)代替SVR模型中传统的参数寻优法,可以有效避免上述参数寻优存在盲目性的问题。
1 研究区域概况
河北省隶属于我国北方大省,区域内矿产资源丰富,具有开采价值的矿高达30余种,黄精、铁矿石、煤矿含量丰富[5]。本文选取河北省张家口市的A区作为研究区域。
由于区域A矿产资源丰富,工业产业聚集,再加上其长期大规模、高强度的采矿挖掘、矿产冶炼,导致土壤重金属污染问题严重,所涉及的重金属包括镉、铅、锌、铜等,居民对该地区环境状况表示担忧,土壤重金属污染防范与治理迫在眉睫。
2 实验数据及数据处理
2.1 土壤重金属数据
本实验中数据来源于相关研究院提供的2020上半年区域A土壤重金属含量汇总状况表,其中包含124组土壤采样信息。研究区域土壤重金属As、Cr、Cu、Cd、Ni、Pb、Zn、Hg的含量信息如表1所示,其平均含量分别为9.89 mg·kg-1,53.56 mg·kg-1,21.31 mg·kg-1,1.73 mg·kg-1,28.71 mg·kg-1,31.00 mg·kg-1,104.48 mg·kg-1,0.032 mg·kg-1,分别为河北省土壤背景值[6]的1.009倍、0.847倍、1.065倍、2.247倍、1.048倍、1.39倍、1.669倍、0.941倍。
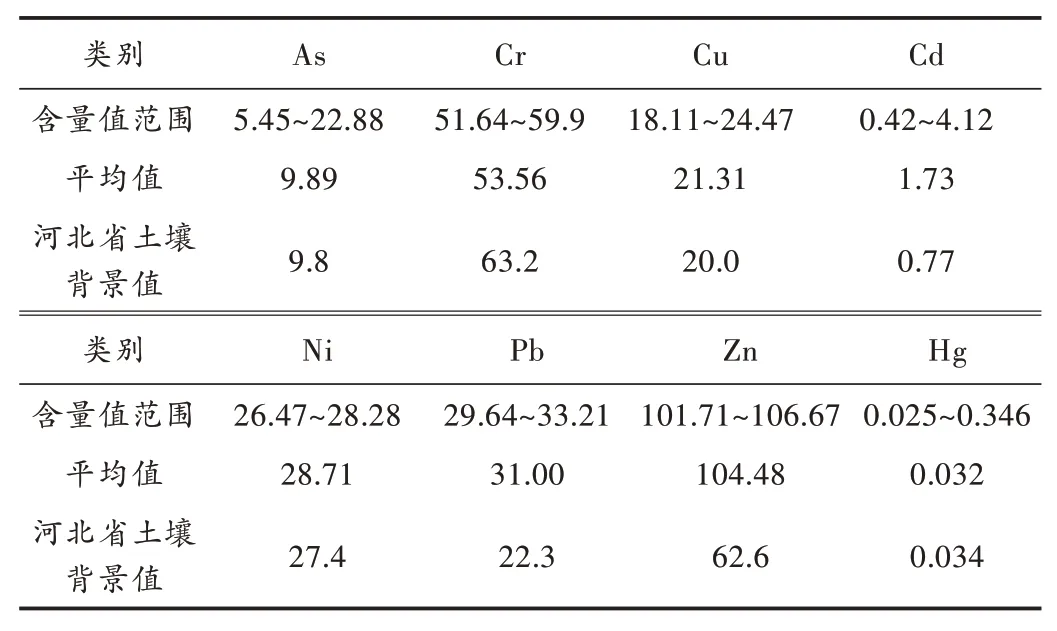
表1 研究区域土壤重金属的含量信息 mg·kg-1
2.2 评价土壤重金属污染的方法
在评价一块土地的重金属污染程度时,常采用的方法有单因子指数法和内梅罗综合污染指数法[7]。单因子指数法和内梅罗综合污染指数法表达式如下:
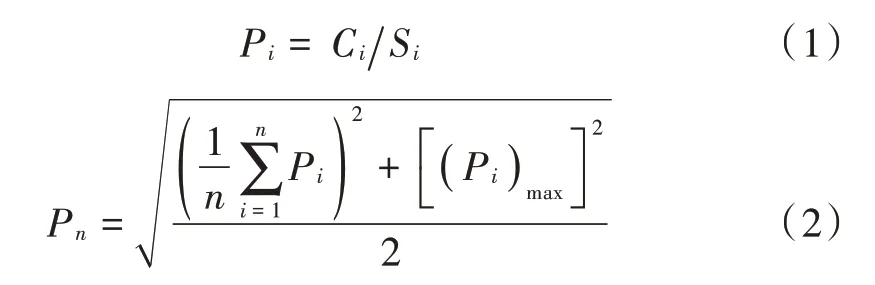
式中:Pi表示土壤中重金属i的单项污染指数;Pn为土壤重金属的内梅罗综合污染指数;Ci表示土壤中重金属i的含量;Si表示土壤中重金属i的含量标准数据。
在处理大规模土壤样本时,因单因子指数法无法反映土壤环境污染的综合情况,且点位数目较多计算量大,所以使用单因子指数法的实操性不高[8]。内梅罗综合指数法在面对大规模土壤样本时可以更直观地描述土壤环境的综合质量水平,可以给出较为全面的评价。因此本实验采用内梅罗综合指数法评价土壤重金属污染状况。
综合污染指数P直观反映土壤中重金属的超标倍数和污染程度。根据内梅罗污染指数评价标准,当P≤0.7时,土壤状况为安全;当P范围处于(0.7,1.0]时,土壤状况为尚且安全(警戒值);当P范围处于(1.0,2.0]时,土壤状况为轻度污染;当P范围处于(2.0,3.0]时,土壤状况为中度污染;当P>3.0时,土壤状况为重度污染。
经过计算,在124组土壤采样数据中,有43组样本的综合污染指数P<1.0,处于无污染尚且安全状态;另有81组样本的综合污染指数P范围处于(1.0,2.0],为轻度污染状态。
3 研究方法与研究技术路线
3.1 随机森林算法
随机森林(RF)算法是机器学习中集成学习算法中的一种,集成学习算法通过把多个模型进行组装,从而得到更好的性能[9]。由于随机森林的最终结果是由多棵决策树投票表决决定,并且每棵决策树的投票权重是相同的,这在一定程度上可以避免模型过拟合问题,其抗噪能力和鲁棒性能比较稳定。
RF算法中的决策树是根据CART算法生成的,分类树分裂基于基尼指数。基尼指数表示数据集纯度,其公式如下:
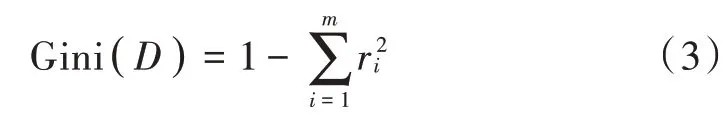
基尼系数表明从数据集中随机抽取两个数据不属于同一类别的概率,所以数据集的基尼系数越小,则表明数据纯度越大,最后选择基尼系数小的属性为最优划分属性。
RF算法中包含多个决策树,每棵决策树的输出结果都占有相同的权重,整个RF的输出结果由每棵决策树投票决定,最后取多数的分类结果作为输出结果。
其应用在本文中的算法步骤如下:
1)从土壤重金属污染数据D中随机抽取训练数据Dk;
2)用随机森林CART算法训练数据Dk,生成模型Mk;
3)输出结果由每棵决策树投票表决,少数服从多数。
3.2 遗传算法(GA)
遗传算法是一种模拟自然界生物进化过程的随机搜索最优解的智能算法,最早由Holland在20世纪70年代提出,由Goldberg与Dejong对其做了全面系统的总结。GA算法根据优胜劣汰原则,通过复制、交叉和变异等操作,逐代演化产生出越来越好的近似解。GA算法根据适应度函数进行优化搜索,并根据适应度函数值评价个体的好坏。GA算法的运算过程如下:
1)设置最大迭代次数T与进化迭代计数器t=0,并随机生成N个群体作为初始群体Q(0);
2)计算群体Q(t)中各个个体的适应度;
3)对群体进行选择运算,把优化的个体通过配对交叉产生的新个体遗传到下一代,不断迭代更新优化种群的质量;
4)对群体进行交叉运算,利用交叉运算产生新的子代个体;
5)对群体进行变异运算,即是对群体中的个体串的某些基因座上的基因值做轻微的变动。群体Q(t)经过选择、交叉、变异运算之后得到下一代群体Q(t+1);
6)重复步骤2)~步骤5)。若t=T,则以进化过程中得到的具有最大适应度个体作为最优解输出,终止计算。
3.3 支持向量回归算法
支持向量回归是基于统计学理论的一种数据挖掘方法,它属于支持向量机(Support Vector Machine,SVM)的一种推广[10],专门用于处理回归分析问题。其基本原理是把样本数据的特征向量从低维映射到高维,从而在高维对其进行回归分析。支持向量回归机的回归函数表示为:

式中:ω为函数x的系数;x为输入特征向量;b为偏置常数。为找到最值回归函数,需要建立最小化函数:
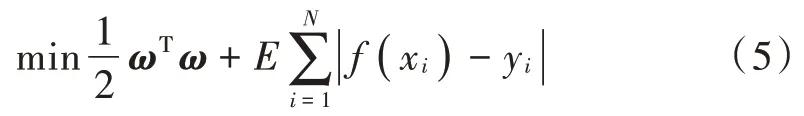
式中:E为惩罚函数;N为样本数;f(xi)表示第i个样本特征向量的预测值;yi表示第i个样本特征向量的真实值。通过建立Lagrange方程对参数求偏导数,可求得SVR模型的对偶模式。最后决策函数表示为:
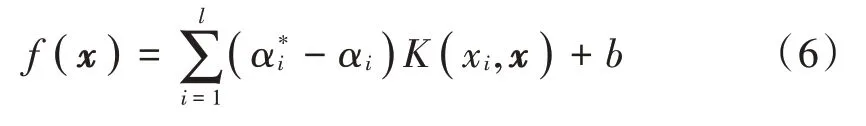
式中:l为支持向量回归机的个数;αi表示最优解;K为核函数。选择较优的核函数,通过在低维空间计算把结果映射到高维空间,有效地避免了高维空间中维数爆炸的问题[11],因此核函数选择高斯核函数,其核函数参数j=1(2σ2),通过调整σ使得高斯核函数具有很高的灵活性。本文中惩罚函数E与核函数参数j通过遗传算法优化获得。
3.4 GA-SVR算法流程
本文利用GA算法对基于训练集建立的SVR模型中的惩罚函数E和核函数参数j进行优化,其优化步骤如下:
1)初始化参数与种群,设置惩罚函数与核函数参数的取值范围,给随机产生的一组SVR参数编码;
2)计算群体中各个个体的适应度函数。通过计算误差函数计算适应度函数值,取误差函数值小即适应度函数值大的遗传个体遗传至下一代;
3)对当前群体进行交叉、变异等遗传操作,从而产生下一代;
4)重复步骤2)~步骤3),直至其满足收敛条件;
5)得到SVR模型最优的惩罚函数E和核函数参数j,从而建立GA-SVR模型;
6)若GA-SVR模型没有达到应有的精度,则重新设置惩罚函数与核函数参数的取值范围,从步骤2)开始重新寻优。
利用GA算法优化SVR预测模型的参数,能够降低人为选取参数时的主观性,从而提高模型预测的精度[12]。图1为本文中GA-SVR模型算法的流程图。
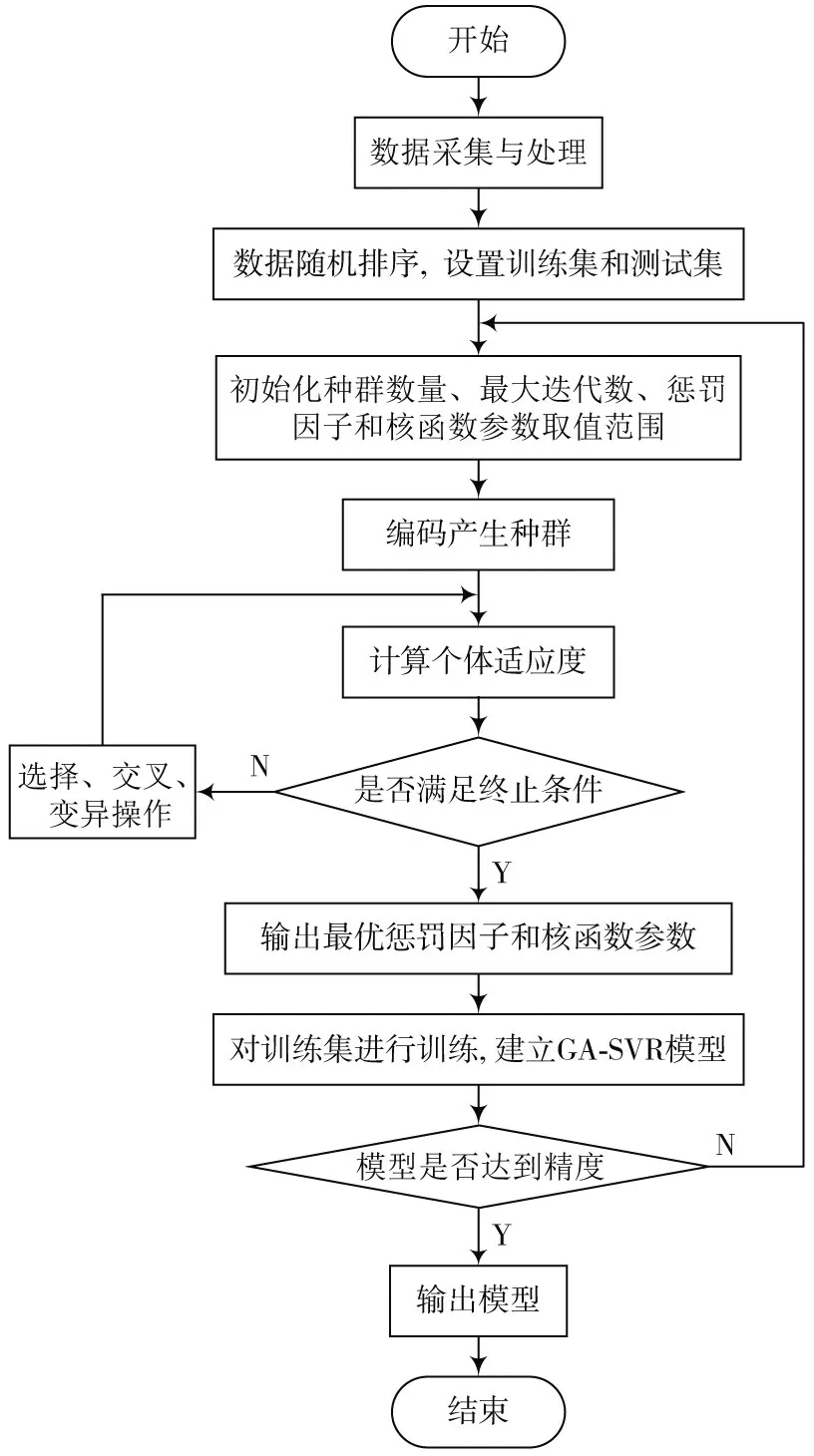
图1 GA-SVR模型算法流程
3.5 本文技术路线及实现方法
本文提出一种结合了RF-GA-SVR算法对区域土壤重金属污染进行预测的模型。获取在不同污染状态时土壤重金属含量数据,计算区域A土壤各个重金属的含量参数向量Z以及土壤重金属污染状态G(定义无污染为状态g1、轻度污染为状态g2、中度污染为状态g3、重度污染为状态g4),以参数Z和污染状态G作为随机森林训练样本集,构建在当前污染状态下的RF污染分类模型。为了进一步预测污染状态G下的土壤综合污染指数P,需要基于SVR建立重金属在土壤中的含量与污染状态的回归模型,利用GA算法对SVR模型中的惩罚函数E和核函数参数j进行寻优,采用GA-SVR模型实现对土壤综合污染指数P的预测。为了得到泛化性高的模型,需要利用测试集数据验证模型的泛化能力,当SVR模型的泛化能力较差时,还需重新调整惩罚函数E和核函数参数j的初始化寻优范围。
本文RF-GA-SVR算法流程如图2所示。
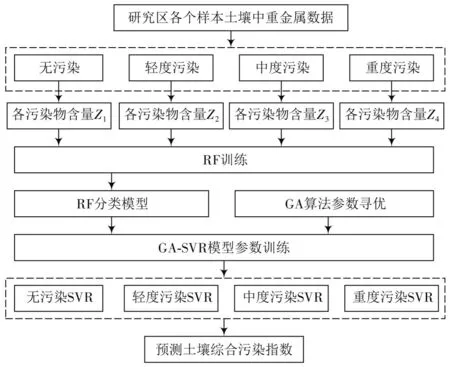
图2 本文RF-GA-SVR算法流程图
4 实验过程及结果
RF模型输出的实验结果表明,输出的准确度在93.7%,并且未出现决策树大量决策失误的情况,泛化性能较好。经过随机森林的特征选择,对7种土壤重金属元素进行评分。实验表明,区域A在无污染g1状态下元素Cd、Zn以及Hg对土壤综合污染指数P的贡献率较高,如图3所示。在轻度污染g2状态下元素Cd、Pb以及Zn对土壤综合污染指数P的贡献率较高,如图4所示。随机选择Cd、Zn、Hg三种元素以及无污染状态g1和Cd、Pb、Zn三种元素以及轻度污染状态g2作为GA-SVR模型的主要输入参数,对GA-SVR模型进行训练,从而对土壤综合污染指数P进行预测。
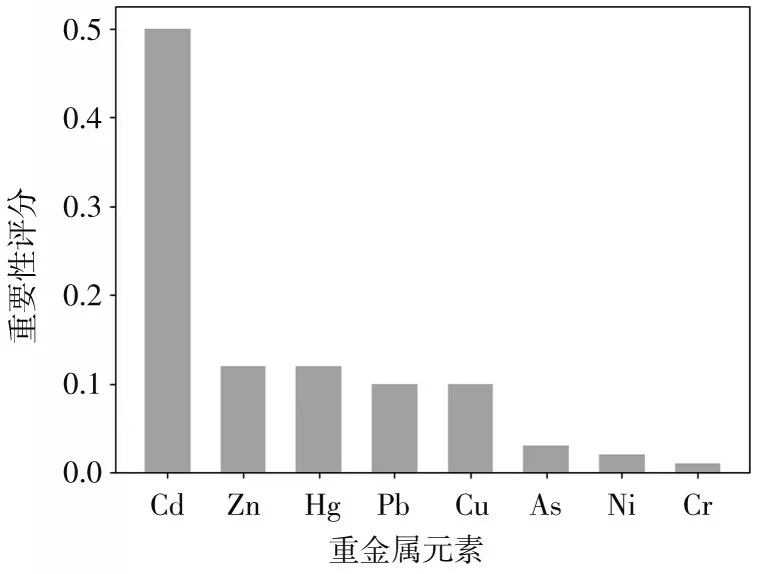
图3 无污染状态下各重金属变量重要性评分
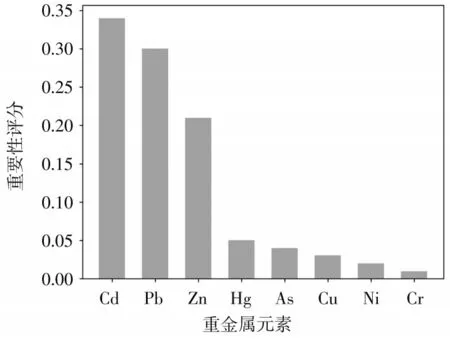
图4 轻度污染状态下各重金属变量重要性评分
GA-SVR模型方面,设置GA算法的种群规模为20,惩罚函数E的范围为[0,80],核函数参数的范围为[0,15],最大进化迭代数为150(终止代数次数为50),交叉变异概率分别为0.5和0.01,令算法独立运行多次,选出出现频率比较高的结果作为SVR模型的参数。图5为采用GA算法对惩罚函数E和核函数参数j进行优化时,其迭代次数与适应度关系图。大约迭代到15次时,模型趋于稳定,最终取惩罚函数E为4.432,核函数参数j为9.819。
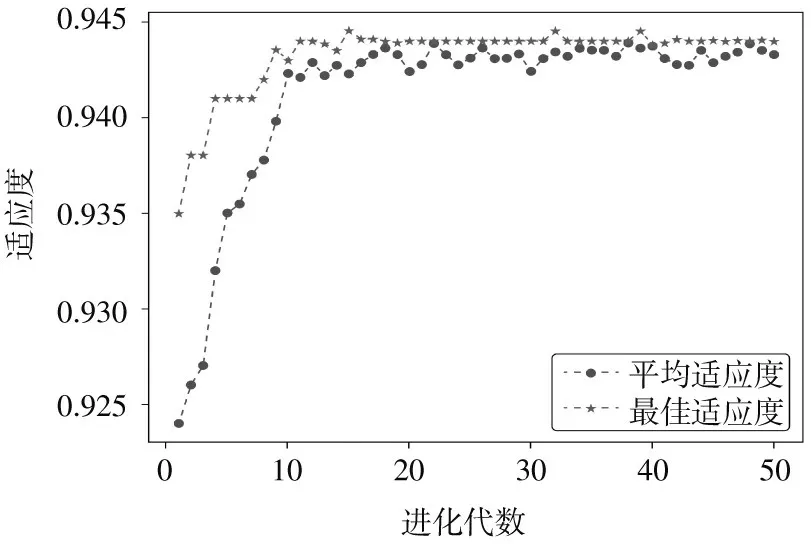
图5 迭代次数与适应度关系图
GA-SVR模型的训练样本需要有代表性,因此每一个样本应具有相同的属性。本文选取经RF模型筛选出的重金属元素及污染状态为主要参数,土壤样本采样点坐标、采样点pH值为辅助参数。由于本样本集中参数的量纲和数量级不同,因此首先需要对样本参数进行标准化处理[13],本文采用MinMax标准化法,转换公式如下:
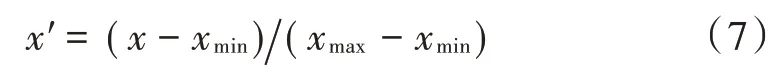
式中:xmax为样本数据最大值;xmin为样本数据最小值。
根据GA算法寻优得到SVR模型最优参数E和j,再用GA-SVR模型预测土壤综合污染指数,之后对结果进行反归一化处理。
经RF模型进行特征选择,再经GA-SVR模型进行预测,故将此算法模型称为RF-GA-SVR模型。比较RF-GA-SVR模型的预测结果与传统SVR模型的预测结果,其结果与误差分析如表2所示。
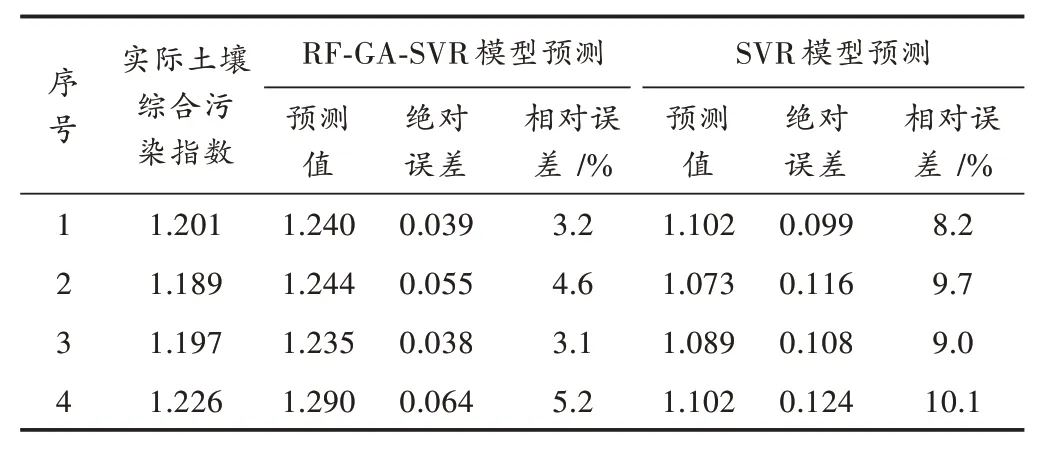
表2 两种不同方法预测结果
由表2可知,由RF-GA-SVR模型预测结果的相对误差小于传统SVR模型预测结果的相对误差,表明RF-GA-SVR预测模型预测的效果更好,有较好的泛化能力,可以达到预测土壤重金属污染的目的。
5 结论
本文以我国河北省某区域的土壤重金属污染情况作为研究对象,提出了RF-GA-SVR土壤重金属污染预测模型,基于GA算法代替传统SVR模型算法中使用的参数寻优方式。得出以下几点结论:
1)本文使用RF模型对SVR模型的输入特征进行选择,选出主要特征,剔除无用特征,提高了模型的精度。
2)人为选取SVR模型的惩罚函数与核函数参数会存在一定的随机性和盲目性,模型易陷入过拟合或欠拟合状态,使得模型效率变低。采用GA算法对样本数据进行训练选择最优参数,从而建立GA-SVR土壤重金属污染预测模型。通过实验分析,发现RF-GA-SVR模型预测结果的相对误差比传统SVR模型预测结果的相对误差低5.225%。



