熊露露,年 梅,张 俊
(1.新疆师范大学,新疆 乌鲁木齐 830054;2.新疆铁道职业技术学院,新疆 乌鲁木齐 830000;3.中国科学院新疆理化技术研究所,新疆 乌鲁木齐 830011)
0 引 言
大数据时代以来,从大数据资源中高效准确地挖掘并利用有价值的信息已成为研究热点。然而,现实中的数据集往往是不完整的。基于不完整数据的挖掘工作严重影响着信息的准确性和可利用性,会降低后续模型的性能。因此,缺失值填补已成为数据挖掘中重要的基础性研究工作。
目前,已有学者提出了一些填充不完整数据的方法。最简单且常见的填补方法包括均值填补法、全局常量填补法等。在此基础上文献[4]提出了混合填补方法,即运用缺失森林填补缺失率低于5%的缺失值,用马尔科夫链蒙特卡洛填补缺失率低于10%的缺失值,但该研究并未考虑缺失率较高的情况;文献[2]对比了不同缺失率下逻辑回归模型和多重插补方法的填充效果,但未考虑多变量缺失率有差异的问题。为了提升多变量缺失且缺失率不同数据集的填充效果,本文做了以下几方面的研究:
1)运用BostonHousing 数据集对比了单变量不同缺失率下RandomForestRegressor(rf)、GradientBoostingRegressor(gbr)、XGBRegressor(xgb)三种回归模型的填充效果,通过实验证明:当单变量缺失率低于1%,rf 模型填充效果最佳;缺失率高于1%,低于5%,xgb模型填充效果最佳;缺失率高于5%,低于10%,rf 模型填充效果最佳;缺失率高于10%,低于50%,gbr 模型填充效果最佳。基于以上研究,本文提出了RXGRegressor集成模型。
2)对多变量缺失率不同的就业预测数据集运用多种方法填充缺失值,并基于随机森林分类器对填充后的完整数据集进行就业预测,就业预测准确度证明了RXGRegressor 集成模型填充效果的优势和实用性。
1 数据集缺失值的填补方法
本文利用BostonHousing 公开数据集,分别评价了RandomForestRegressor、GradientBoostingRegressor、XGBRegressor 三种缺失值算法在单变量不同缺失率下的填充效果。
1.1 RandomForestRegressor(随机森林回归)填补算法
随机森林回归算法对已观测值训练出一个随机森林,再预测缺失值,重复迭代处理缺失值问题。由于其具有较高的准确性和稳健性,随机森林回归已在一些复杂研究中得到充分应用。其建模思路如下:
1)从原始训练集中有放回地随机抽取数据组成多个样本集(>1);
2)使用CART 函数,对抽取的样本集建立对应的回归树模型。计算方程为:
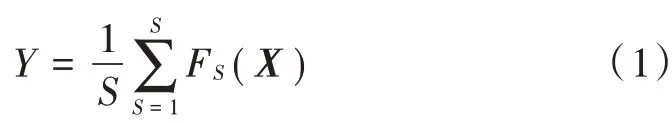
式中:为预测结果;是输入的特征向量;为回归模型个数;F()为单个回归树模型。
1.2 GradientBoostingRegressor(梯度提升回归树)填补算法
梯度提升回归树是Boosting 算法的一种改进。将训练过程阶梯化,每轮训练使用全部样本,但改变样本权重,采用损失函数拟合残差,使上一轮模型中的残差在梯度方向上进一步降低,从而得到新的模型。梯度提升回归树可减少模型偏差。
1.3 XGBRegressor 填补算法
XGBRegressor 是GradientBoosting 算法的一种改进,在目标函数中加入树模型复杂度作为正则项,训练中每次迭代先对样本进行抽样,使用部分样本的部分特征进行训练,大幅提高了模型的预测精度。
2 单变量不同缺失率填补算法的实验及分析
2.1 实验环境与数据
使用Python 语言,运用Sklearn.datasets 中的BostonHousing 数据集进行实验和结果分析,将数据集中的第九列RAD 数据分别按照1%,5%,10%,30%,50%的缺失率随机置空。
2.2 实验结果分析
本部分实验结果使用MSE(均方误差)、MAE(平均绝对误差)和分析填充效果。
MSE 是回归任务最常用的性能度量,其中y表示真实值,f表示预测值,MSE 值越接近0 拟合越好。MSE 的计算如式(2)所示:
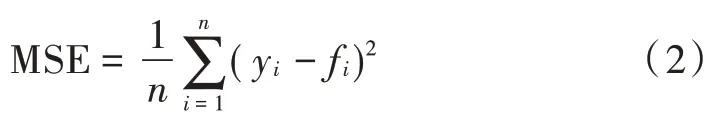
MAE 是绝对误差的平均值,能较好地反映预测目标与实际目标误差之间的实际情况,MAE 值越接近0拟合越好,MAE 的计算如式(3)所示:
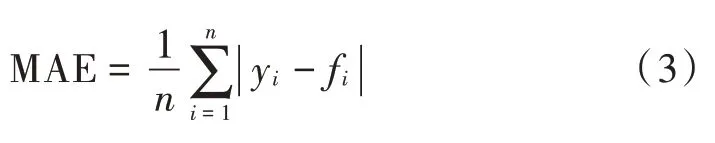
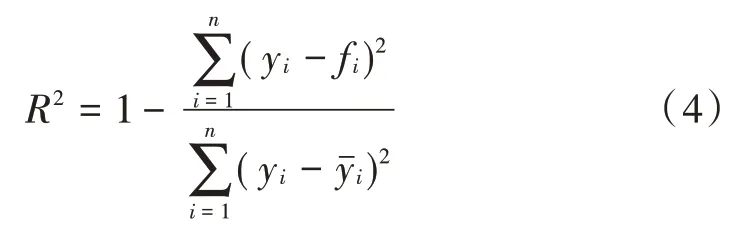
实验可视化结果如图1 所示。从图1 可得单变量不同缺失率值下的最佳填充算法,即当单变量缺失率低于1%时,用RandomForestRegressor(rf)填补后MSE、MAE最小且均为0,(R_2)最大为1;当单变量缺失率低于5%,10%,30%,50% 时,用XGB Regressor(xgb)、Random Forest Regressor (rf) 、Gradient Boosting Regressor(gbr)、填补后MSE,MAE 最小,最大。
然而,实际数据集中往往存在多变量且缺失率不同的问题。
应用图1 得出的结论,本文提出用RXGRegressor 模型解决以上问题,即某变量缺失率低于1% 使用RandomForestRegressor 算法;缺失率低于5% 使用XGBRegressor 算 法 ;缺 失 率 低 于 10% 使 用RandomForestRegressor 算法;缺失率低于50% 使用GradientBoostingRegressor 算 法 。 为 了 验 证RXGRegressor 模型的缺失值填充效果,将该算法和常规的填充算法对多变量且缺失率不同的就业数据集进行数据填充,利用准确度进行缺失值填充效果的评价。
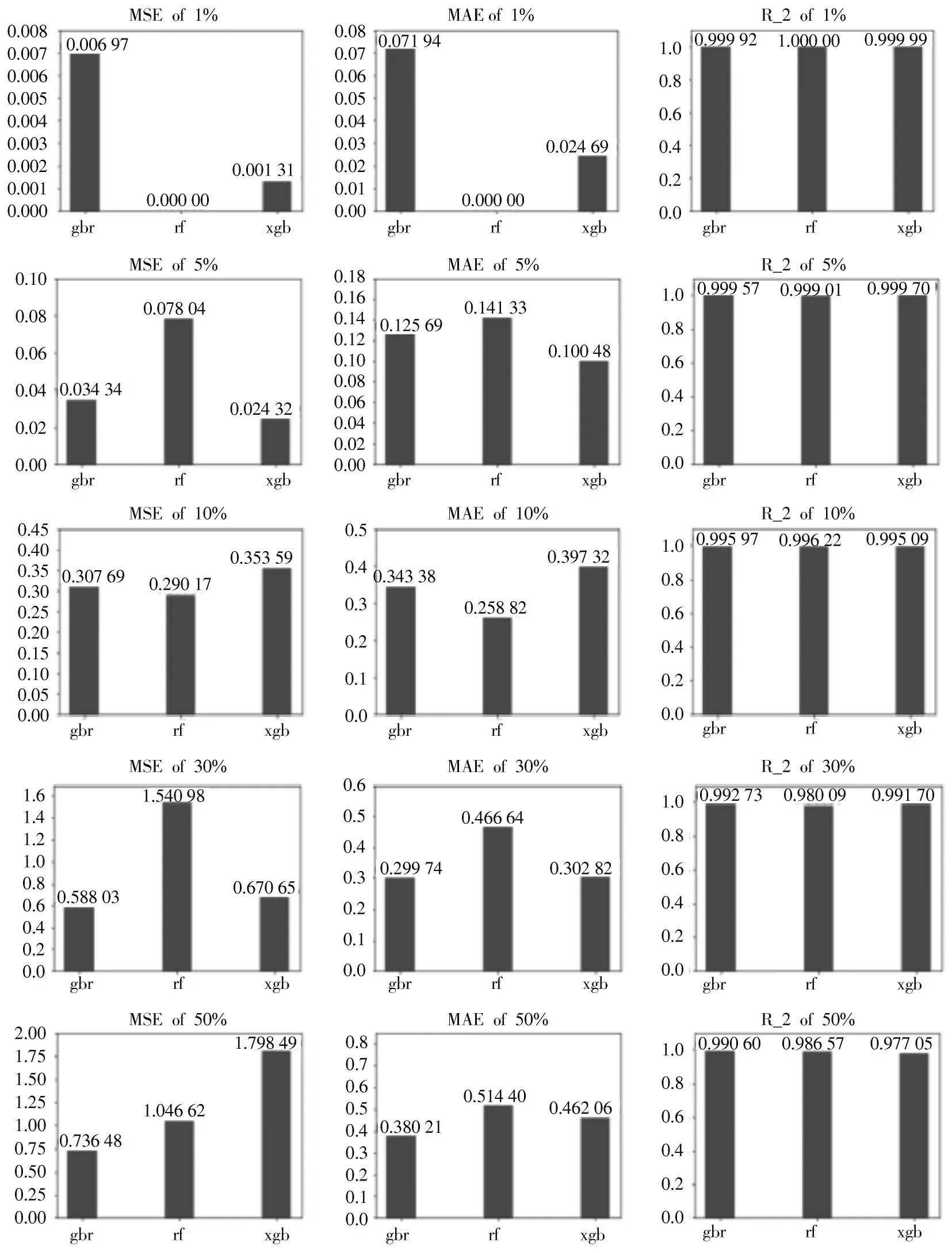
图1 单变量不同缺失率下3 种填充方法的结果可视化
3 多变量缺失率不同填补算法的实验及分析
3.1 数据来源
以某高职院校的毕业生就业和成绩数据为研究对象,从学校招生就业系统中提取2016—2020 年毕业生就业数据3 778 条记录,从教务管理系统中提取相应毕业生成绩数据3 778 条。将就业数据和处理后的成绩数据通过“学号”关联合并。选择“性别”“民族”“专业”“政治面貌”“毕业时间”“学历”“户口所在地”“基础课成绩(jc)”“专业基础课成绩(zyjc)”“专业课成绩(zyk)”“专业核心课成绩(zyhx)”“技能鉴定成绩(jnjd)”“实习成绩(sxi)”“实训成绩(sxun)”“职业生涯成绩(zysy)”“毕业论文成绩(bylw)”16 个变量构成特征矩阵,以就业情况作为标签,以就业成功为‘0’,否则为‘1’。由于学生存在转专业等情况,所获取的数据集中含有缺失值,缺失情况如表1 所示。
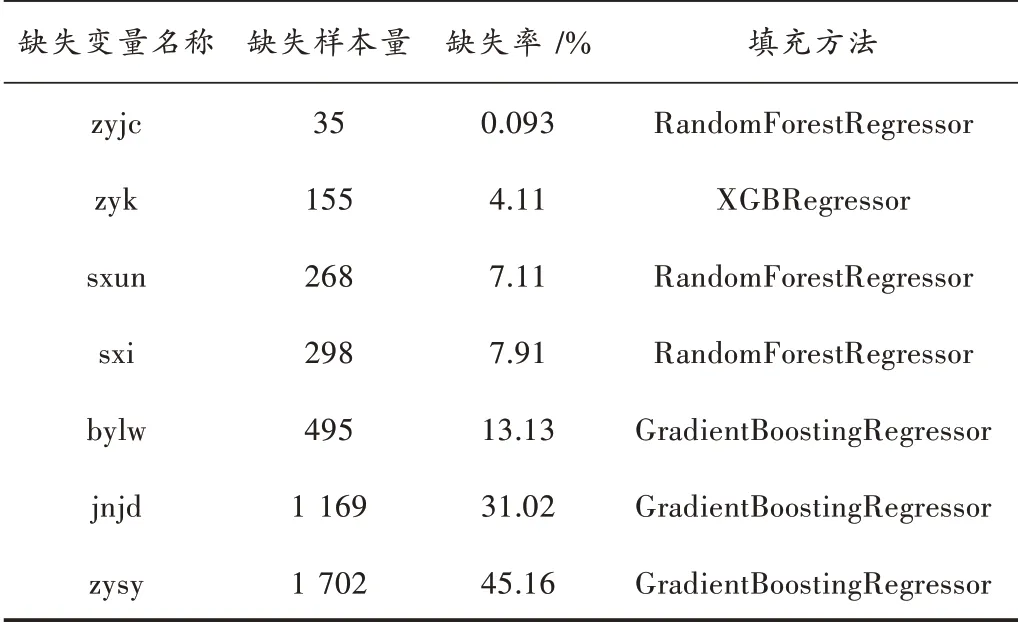
表1 不完整就业预测数据样本缺失情况
3.2 RXGRegressor 填充算法
就业预测数据中特征矩阵和标签之间有一定联系,可以交换位置来预测某变量的缺失值,将含有缺失值的特征矩阵记为_missing。具体填充过程如下:
1)遍历所有特征,对含有缺失值的变量从小到大进行排序,记为sortindex,从缺失值最少的变量开始填充,因为其所需要的准确信息最少;若特征属于sortindex,执行步骤2)~步骤8)循环。
2)用矩阵df保存_missing 信息。
3)构建新的特征矩阵df 和标签。对于一个有个特征的矩阵df 来说,如果特征有缺失值,可将特征作为标签,其他-1个特征和原标签组成新的特征矩阵df。
4)对df中的缺失值用均值填充,记为df_mean。
5)对df_mean 划分训练集和测试集。对于特征,没有缺失值的部分为_train,有缺失的部分为_test,特征没有缺失的部分对应的df_mean 为_train,有缺失的部分对应的df_mean 为_test。_test是需要预测的。
6)利用回归预测缺失值。根据的缺失率选择合适的填充方法计算缺失值。
7)将计算后的缺失值填充至矩阵_missing。
8)判断如果sortindex 中再无元素,则结束循环,否则,回到步骤2)。
3.3 实验结果与分析
为了验证本文填充算法的效果,对就业数据集中的缺失值分别用均值、RandomForestRegressor、Gradient-BoostingRegressor、XGBRegressor、RXGRegressor 算法进行填充,填充后的数据集分别记为:_mean、_rf、_gbr、_xgb 和_RXGR。将填充后的数据集均按照8∶2 的比例划分为训练集和测试集,使用随机森林分类器模型对训练集进行训练,用测试集进行测试,用Accuracy指标评价分类器模型的预测性能,Accuracy 值越接近于1 越好。将_mean、_rf、_gbr、_xgb 和_RXGR 完整数据集上的随机森林分类器的Accuracy 值分别记为:score_mean、score_rf、score_gbr、score_xgb 和score_RXGR,其可视化结果如图2 所示。
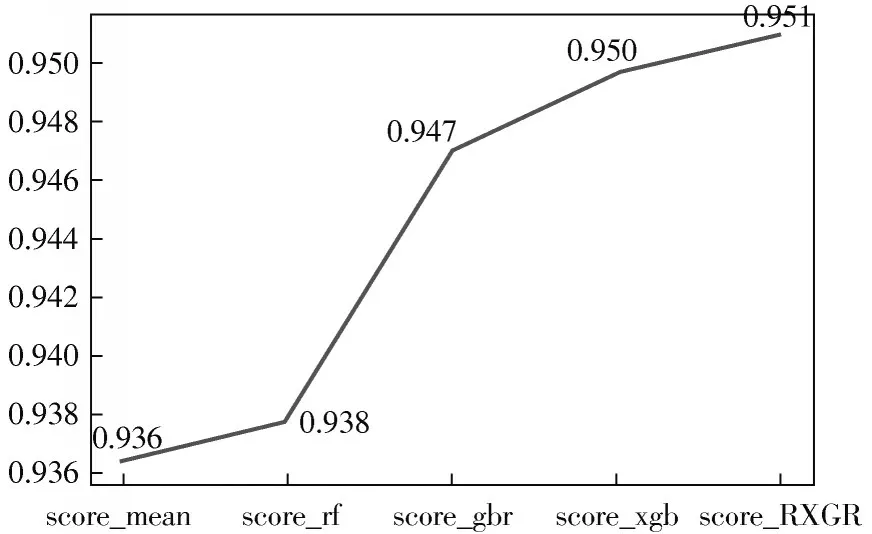
图2 不同缺失值填充法填充后的数据分类评分
图2 表明,运用相同的分类器模型,参数均已调整为最优的情况下,用均值填充的就业数据分类预测准确率最低,回归填充的就业数据分类预测准确率高于均值填充算法,本文提出的RXGRegressor 集成模型填充后的就业数据分类预测准确率最高,此结果充分说明RXGRegressor 集成模型对多变量及各变量缺失率不同数据集填充的有效性和优势。
4 结 论
本文首先在BostonHousing 数据集上,利用实验和分析对比方法研究了单变量不同缺失率值对应的最佳缺失值填充算法;然后针对实际数据集中多变量缺失率不同导致的分类准确度低的问题,提出了RXGRegressor集成模型,用该模型填充学生就业预测数据集中的缺失数据,用随机森林分类器对填充后的完整数据集进行就业预测。实验结果表明,用RXGRegressor 集成模型填充缺失值可以有效地提升数据挖掘的准确度,从而证明本文算法在数据填充方面是有效的。



