张 建,张海飞,史洪玮
(1.苏州大学文正学院,江苏 苏州 215104;2.苏州大学东吴学院,江苏 苏州 215006;
3.南通理工学院 计算机与信息工程学院,江苏 南通 226002;4.宿迁学院,江苏 宿迁 223800)
0 引 言
图像识别大多在性能较高、资源丰富的通用计算机上进行,终端芯片性能的逐渐发展使得图像识别在嵌入式终端上得以实现,如Raspberry Pi、Jetson Nano 等高性能嵌入式芯片,但是在资源较低、性能不太高的一般嵌入式芯片中实现图像的识别是比较困难的。本文提出一种采用卷积神经网络的深度学习算法,在一般性能芯片上实现图像的识别。
基于图像识别的嵌入式物体认知系统是采用嵌入式计算机通过摄像头采集物体图像,利用图像识别相关算法进行标记、训练,训练完成后,可进行推理完成对图像的识别,从而实现人工智能中的“示教、学习、识别”基本过程。 卷积神经网络(Convolutional Neural Networks,CNN)是一类包含卷积计算且具有深度结构的前馈神经网络(Feedforward Neural Networks),是深度学习(Deep Learning)的代表算法之一。卷积神经网络作为图像识别领域的核心算法之一,在学习数据充裕的情况下具有稳定性,可以在精细分类识别(Fine⁃Grained Recognition)中用于提取图像的判别特征,以供其他分类器学习。
1 系统总体框架
嵌入式物体认知系统主要由图像识别终端、神经网络参数训练机、云端存储应用服务器及应用展示端等四个部分组成,图1 为系统的总体框架结构。图像识别终端通过摄像头将待识别的对象进行采集后送到MCU 进行推理与分类,LCD 实时显示摄像头采集到的图像,并将推理的结果显示在LCD 上;图像识别终端也收集用于神经网络参数训练的图像数据集,并通过通信模块将每次采集及识别的结果上传到云端以便用户访问。神经网络参数训练机根据图像识别终端采集的物体数据进行训练得到参数的值,并将参数值通过串口下发到MCU 中,以便后续对物体进行识别。
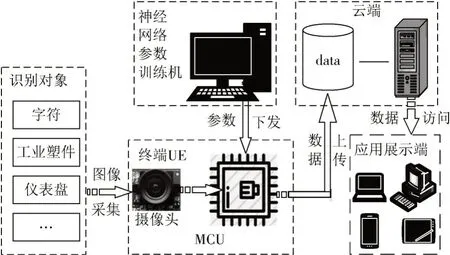
图1 系统整体结构
终端通过摄像头模块采集到图像并实时显示在LCD 面板上,用户给出标记或推理指令以进入不同的流程。进入标记流程,则通过串口将采集到的图像数据传输至神经网络参数训练机进行训练,并将训练的参数下发到终端。进入推理流程,需要判断终端程序中是否已经存在相应的神经网络算法参数,不存在的话,则需要和用户确认是否进入标记流程,否则直接跳转至图像采集;如果存在神经网络参数,终端运行图像识别程序对采集到的图像数据进行识别,并将识别结果显示在LCD上,上传识别结果到云端。应用展示端通过访问云端服务器查看已识别的相关图像信息。图2 为系统的整体数据处理流程。
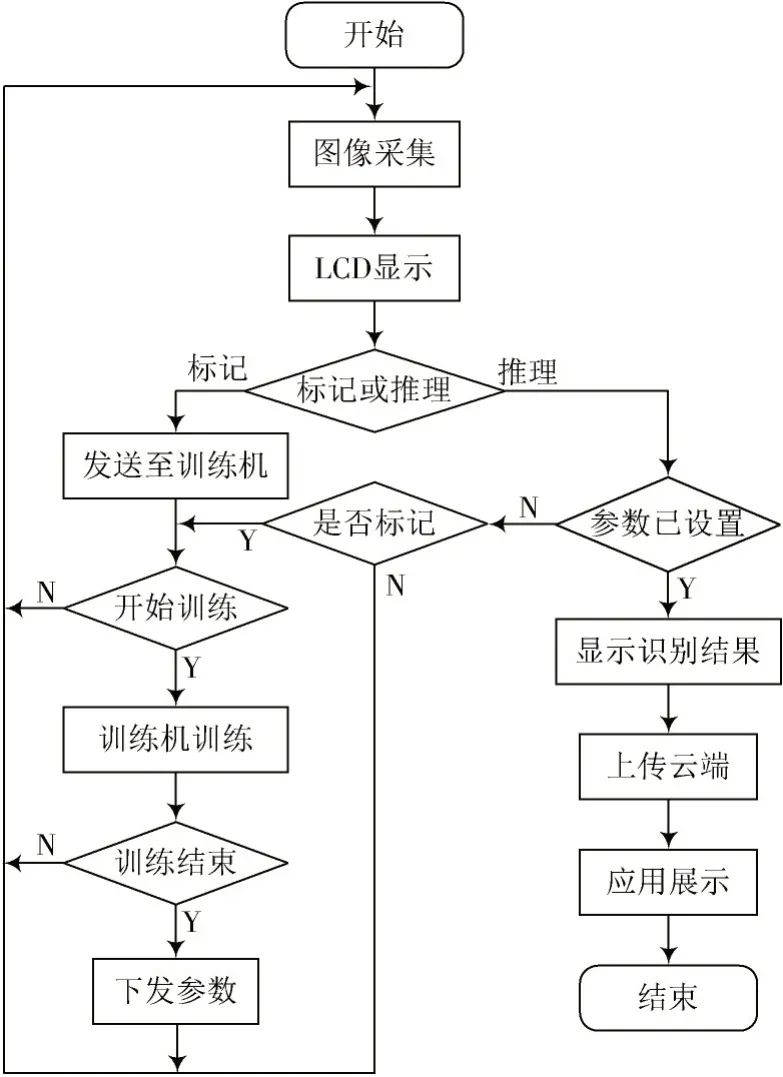
图2 系统数据处理流程
2 硬件系统设计
图像识别终端主要包括MCU、摄像头、LCD 液晶屏及通信模块四部分,其中通信模块包括串口模块、窄带通信模块及其他满足数据传输的通信模块。
主控芯片STM32L431RC 的主频为80 MHz,拥有64 KB 大小的RAM 空间以及256 KB 大小的FLASH 空间,并提供UART、SPI、IC 等多种外设接口,拓展方便,既能满足稳定运行推理模型的需求,也能满足嵌入式开发的需求。LCD 屏主要用来实时显示摄像头采集到的图像及显示识别的结果。LCD 屏选取ST7789V,该屏为2.4 寸TFT 液晶彩色显示屏,16 位插接24PIN,分辨率为240×320。扩展板通过SPI 接口方式与LCD 显示传输数据,使得LCD 显示屏实时显示图像。图像采集为系统提供输入数据。系统选取OV7670摄像头作为终端图像采集设备,该摄像头成本低、成像分辨率可达30 万像素。由于OV7670 的最低发送帧率超过了主控芯片的承受范围,因此为匹配二者之间的收发速度设计了外围驱动电路,通过添加AL422B数据缓冲芯片将图像数据手法方式从原有的MCU 被动接收变为主动获取,保证了每一张图像的质量。摄像头外围电路设计见图3。
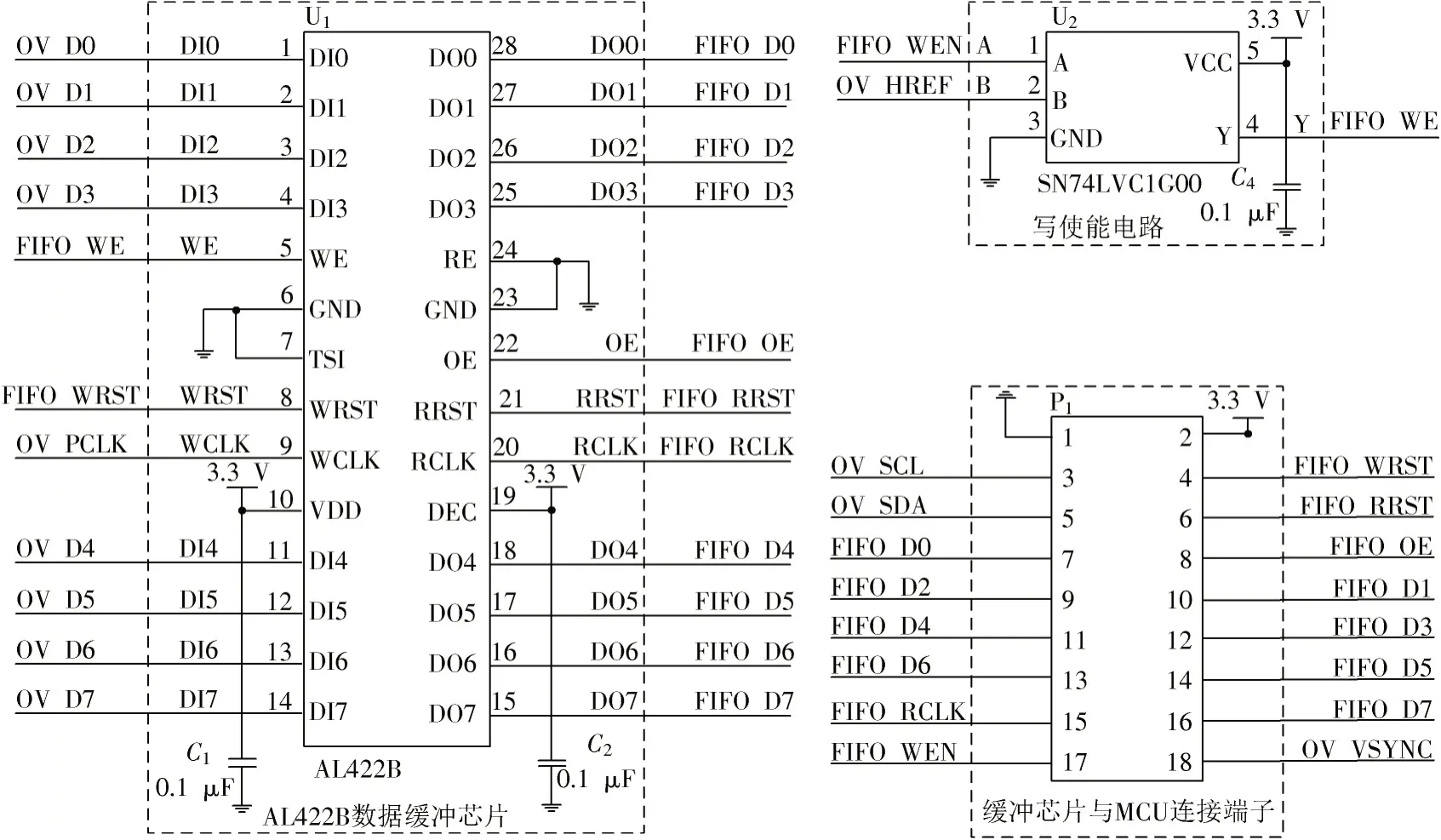
图3 摄像头外围电路设计
通过调用封装函数读取采集的图像所需时间过长,比如摄像头在读取一张112×112 像素大小的图像并显示在LCD 上需4.2 s,这导致整体系统推理时间的延长。所以本文系统驱动的设计重点放在了提升图像读取与显示速度。图4 为重新设计的驱动流程。
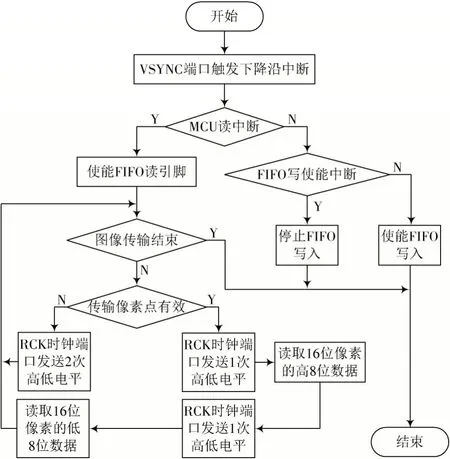
图4 摄像头读取流程
摄像头分辨率为320×240,每次需要76 800 次读取像素的操作,每个像素有效性判断及摄像头与缓存芯片通信方式的优化所消耗的时间是巨大的。因此,需要从通信方法、显示流程及取特定位置等方面进行优化降低时间消耗。
1)改进通信方法。图4 表明系统对时钟引脚进行了4 次改变电平输出的操作,总共需要76 800×4 次。通过封装的GPIO_Set 函数对时钟引脚RCK 进行高低电平操作、引脚状态判断及解析,将调用GPIO_Set 函数修改为通过GPIO 引脚对应寄存器地址的引用来缩短访问时间,进而提升整体速度。程序修改如下:
gpio_ptr⁃>BSRR =(uint32_t)(1u<<10);//输出高电平时钟信号
gpio_ptr⁃>BRR =(uint32_t)(1u<<10);//输出低电平时钟信号
修改后程序读取320×240 的图像时间变为3.9 s,访问速度提高了6.6 倍。
2)改进显示流程。系统不再将图像完整地保存在指定数组之后再显示图像,而是在读取完每个像素点数据之后直接显示在LCD 对应的位置上,利用缓存芯片获得发送像素命令并发送下一个像素数据的时间间隔,将显示时间减小至2.7 s。
3)特定位置判断。通过对320×240 大小的图像进行归一化截取的方式,将其缩小到56×56 像素大小,经本次优化后,刷新图像时间减少到1.7 s。
经过以上流程的优化,在保证成像的前提下,图像的接收速度缩短至之前的6.61%,同时减少了占用的内存空间,满足了本文系统的实时性需求。
3 软件系统设计
系统终端按照图像处理流程分为了3 个代码文件,分别是用于图像预处理的“modelPreprocess.c.h”、用于模型推理的“modelPredict.c.h”以及用于模型参数配置的“model_init.c.h”,图5 为系统实现的软件部分结构及处理流转。PC 端训练工程所生成的“model_init.c.h”文件通过重新烧录的方式实现终端模型的更新,终端在推理图像后,将分类结果输出。系统的开发采用模块化、组件化、构件化的思想进行开发,以提高代码的重用度,降低开发难度与工作量,提高开发效率。

图5 软件结构处理流转
3.1 图像预处理
为了减少图像存储空间以及降低滤波算法的复杂度,首先将16 位彩色图像转为8 位灰度图像,将图像数据降为原来的50%;再对图像背景进行滤波。
采用均值滤波算法、边缘滤波算法、双峰均值法以及双峰谷底法等方法对采集的图像进行滤波操作,过滤无关背景干扰,降低对资源的需求。针对同一幅图像选用不同算法进行采集,将图像数据转换成为28×28大小的数字矩阵,其中每一个坐标上的数字代表相应位置像素的灰度值。经过对采集到的图像进行对比实验,表1 给出了几种算法优缺点的对比。

表1 滤波算法对比
结合表1 对比结果,双峰均值法背景滤波能力较好、稳定性好,适合作为本文系统的背景滤波算法。双峰均值法的实现是一个迭代的过程,每次处理前需对灰度频率直方图进行判断,看其是否已经是一个双峰的直方图,如果不是,则对直方图数据进行半径为1 的平滑。如果迭代了一定的数量,比如1 000 次后仍未获得一个双峰的直方图,则函数执行失败;如成功获得,则取两个双峰灰度值的平均值作为阈值。
在对背景的滤波效果上,双峰均值法可以将背景像素点置0,同时保留采集图像的特征,符合使用数据集的要求。双峰均值算法的代码为:
输入:28×28 大小的图像二维数组
输出:滤波后28×28 大小的图像二维数组
1.获得图像数据origin_pic[28][28]
2.遍历图像数组,得到灰度分布图,用数组gary[256]表示;第个数组成员的值表示灰度值为的像素点出现的次数
3.for=0 to 28 do
4.for=0 to 28 do
5.获得第行第列成员的灰度值:G=origin_pic[][]
6.将数组gary 第G个成员数值加1:gary[G]+=1
7.end for
8.end for
9.while 图像灰度分布没有两个峰值do
10.//对分布图进行平滑操作
11.for=0 to 255:
12.取gary[]前后两个成员数据,求出平均值gary_avg
13.gary[]= gary_avg
14.end for
15.if while 执行次数超过1 000 次then
16.判定图像无法进行双峰均值法操作
17.end if
18.end while
19.得到分布图上的分布两个峰值low_gary、high_gary
20.取两个峰值灰度的均值shreshold 作为滤波阈值
21.对图像进行阈值过滤处理
22.return 处理后的数组指针
3.2 终端推理模型设计
本系统选取的STM32L431RC 芯片存储资源为64 KB 大 小RAM 空 间,以 及256 KB 大 小FLASH 空 间,对于模型参数以及推理过程中所涉及的运算方法需要进一步适配,以达到资源最大化利用。
3.2.1 参数存储方法设计
采用分散存储替代层次顺序的几种存放方式,将每层参数以常量数组的方式分别存储,减少在推理过程中对有限资源的使用。通过使用CONST 关键字来定义每一层的参数数组,将其放入存储空间相对较大的FLASH 中。处理后RAM 空间占用从43 KB 降为7 KB,图6、图7 分别为优化前后MCU 占用资源的情况。从中可看出RAM 的占用率从77.20%降低到13.78%,空间利用率提高了6 倍左右。

图6 未优化前MCU 资源占用情况

图7 优化后MCU 资源占用情况
3.2.2 模型更新方法设计
由于终端主控芯片资源限制,故将模型的训练过程放在PC 上进行,系统通过调用Keras库训练模型并生成可以直接在嵌入式工程下编译的C 语言构件文件,通过构件的更替再重新编译烧录,实现对终端推理模型参数的更新。
3.2.3 模型层次结构设计
本文模型基于传统LeNet5 的网络传播结构,针对嵌入式低资源图像识别的场景进行参数以及相关数据处理方式的适应性优化,在硬件终端上实现模型推理。终端模型在每层的传播过程中需要使用前一层输出的特征图像、本层的权重和偏置数组,以及输出的特征图像数组。因为芯片存储资源为64 KB 大小,所以这3 个数组的占用空间之和不能超过64 KB。根据此原则本文设计出终端推理模型架构,模型共采用7 层网络结构,依次为第一层卷积层、第二层池化层、第三层卷积层、第四层池化层、第五层卷积层、第六层全连接层以及第七层全连接输出层,共包含8 824 个float 型参数,内存占用大小为35 KB。表2 为模型各层结构信息。
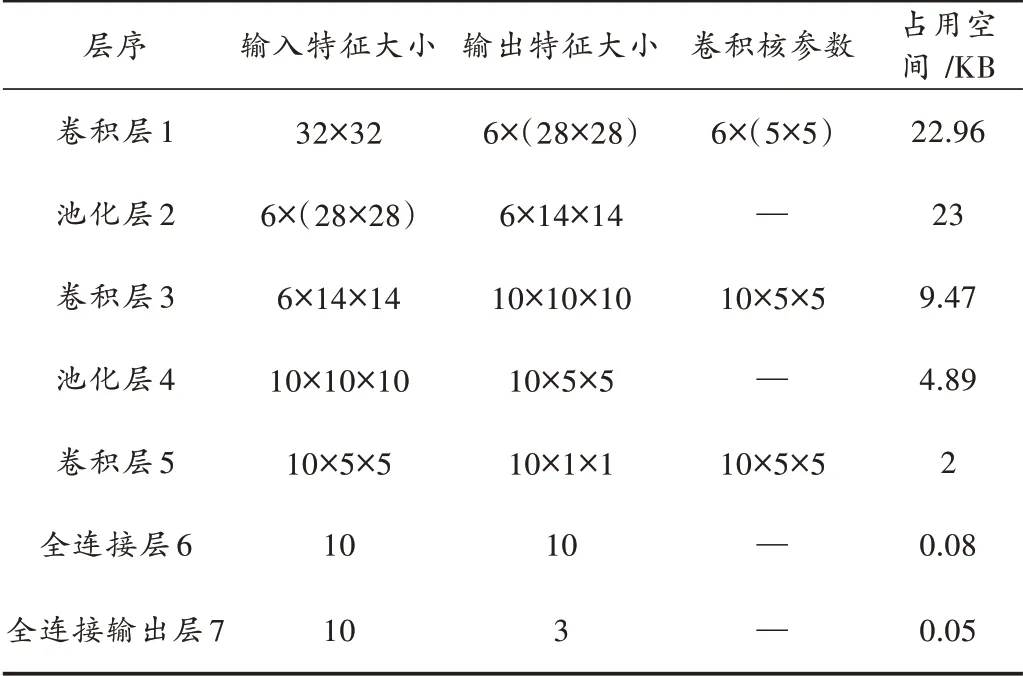
表2 模型结构表
4 实验分析
系统通过在神经网络参数训练机上进行推理、终端数字、实物等识别测试,识别准确率均达到90%以上。
4.1 推理模型性能测试
系统通过Keras 库在PC 端搭建推理模型,并通过MINST 数据集对模型进行性能测试,经过测试得到模型的准确度在92.56%。
4.2 终端对于数字的测试
选用数字卡片1,2,3 进行图像识别,图8 为终端识别到的数字卡片3。表3 为终端对数字卡片上数字1,2,3 进行识别的测试结果。从表3 中可看出终端对数字的识别准确率不低于92%。其中,系统对模型推理的输出值进行Softmax 回归,将原本的输出激励值转变为概率,将概率低于80%的预测值归为无效推理次数。

图8 终端识别数字3 示意图
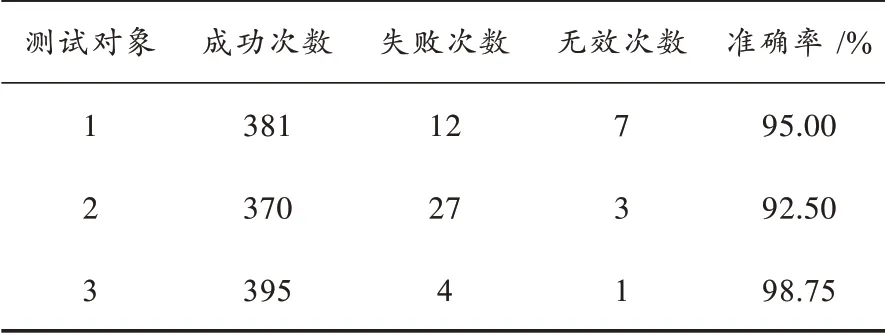
表3 终端对数字的识别准确率测试结果
4.3 终端对实物的测试
系统对嵌入式开发过程中常见的PCB 板、排针以及USB 接口进行识别准确率测试,图9 为用于终端识别的实验室内三类常见的实验配件。
图9 实验室内三类实物
对每一个物体进行不同位置、距离下的400 次推理识别,最终在终端上的测试结果如表4 所示。表4 为终端对三种不同的实物进行识别的统计,从中可看出终端对实物的识别准确率不低于93%,模型识别准确率保持在较高水平。
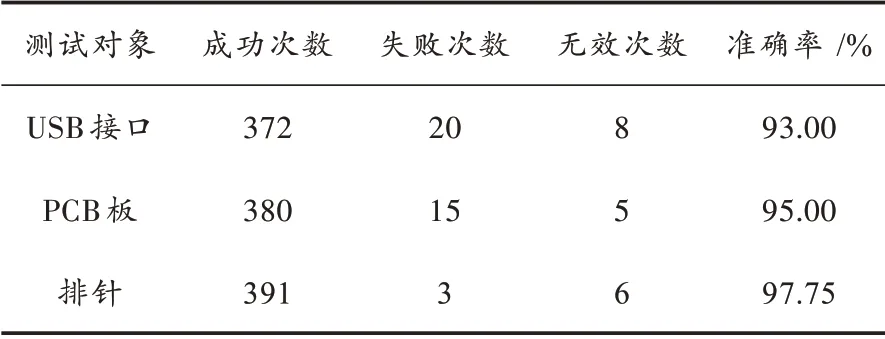
表4 终端对三类实物的识别准确率测试结果
5 结 语
本文设计一套低资源嵌入式图像识别系统,对图像分类算法进行适应性优化,并对终端中的算法推理过程进行改良,以满足低资源下终端硬件的运行需求。同时在PC 端设计模型训练软件生成可直接在嵌入式编程框架下编译的模型参数配置文件,通过重烧录的方式实现对终端模型的更新,并实现模型的快速更新。嵌入式端的硬件设计、软件训练以及物体识别的测试用例证明了本文系统的有效性。



