周 旋,邬云文,向长青,丁 雷
(1.吉首大学 通信与电子工程学院,湖南 吉首 416000;2.湖南省普通高校近地空间电磁环境监测与建模重点实验室,湖南 长沙 410114;3.吉首大学 物理与机电工程学院,湖南 吉首 416000)
0 引 言
RFID 技术具有远距离非接触且批量识别的特点[1-2],应用非常广泛。当前,RFID 技术的相关研究内容有很多,例如RFID 标签识别算法、RFID 通信模块的滤波电路等[3]。RFID 系统在进行多标签批量识别时,由于阅读器的性能和系统选用的算法限制,常出现标签的识别碰撞,以及部分标签因多次发生碰撞造成始终未被识别的“饿死现象”[4]。在当前的研究中,RFID 多标签识别算法是研究热点之一。
在RFID 算法研究领域,目前研究较多的是确定性算法(如树型类算法)和各种不确定性算法,不确定性算法以动态时隙ALOHA 算法为基础[4-9]。文献[10]提出了一种基于二叉树和多叉树的RFID 防碰撞算法,该算法单时隙内可同时识别两个标签,吞吐率达到65.7%,但是该树型算法纵深太大,耗用时间太长。文献[11-16]提出的6 个算法仍然存在吞吐率较低、吞吐率不稳定、空闲时隙多、资源过多闲置、纵深太大等问题。
本文提出一种结合伪ID 码,同时基于标签可并行识别技术的防碰撞算法(Pseudo ID Code Logistic DFSA算法,PILD 算法)。该算法结合伪ID 码分组和标签可并行识别技术,提高了RFID 标签识别传输的吞吐率,从而在占用相同传输频带的条件下,提升RFID 多标签识别系统的传输性能,有效地减少了单个标签因多次碰撞发生“饿死现象”的概率。本文对RFID 识别过程进行理论推导及数学分析,对算法的吞吐率、标签的总查询次数和标签的平均查询次数进行Mathematica 仿真,同时对仿真结果进行分析。另外,对比分析PILD 算法、基于伪ID 码的树型防碰撞算法,单纯的Logistic-DFSA 算法的信息传输性能。
1 PILD 算法过程的理论分析
对于待识别标签,首先通过伪ID 码分组,当出现选择同一个伪ID 码的标签数大于1 的情况时,采用标签并行识别算法进行识别。在本章中首先对利用伪ID 码将待识别标签分组的情况进行分析,接着分析碰撞ID 码的并行识别过程。
1.1 伪ID 码识别过程理论分析
设阅读器根据估算标签数产生一组伪ID 码,每个标签在伪ID 码的取值范围内随机选取一个伪ID 码作为自己的标识符。其中,某个伪ID 码被m个标签同时选中的概率为:
式中:L为阅读器所产生的伪ID 码的个数;n为识别范围内待识别标签的总数量;m为选中当前伪ID 码的标签个数。
当单个标签选中的伪ID 码(即识别成功伪ID 码)的期望和伪ID 码总个数的比值取极限值时,存在如下关系:
此时,识别成功的伪ID 码数量达到理论最大值。现实情况下,式中n的数量很大,1可忽略不计,故取L=n。
在使用Logistic-DFSA 算法对标签进行识别之前,首先,阅读器估算识别范围内标签总数n,然后阅读器把n发给标签,标签的随机数生成器在1~n之间生成一个数作为伪ID 码。此时,伪ID 码有以下几种情况:
1)该伪ID 码无标签选择,即m=0;
2)有1 个标签选择该伪ID 码,即m=1;
3)选择该伪ID 码的标签数大于等于2,即m≥2,此时发生了传统算法中的碰撞现象。
当m=0 时,由式(1)推导可得识别过程中出现空ID码概率为:
当m=1时,由式(1)可得成功识别伪ID码的概率为:
当m≥2 时,该伪ID 码即为通常意义的碰撞ID 码,由式(1)、式(2)推导出m≥2 时的标签碰撞概率Pm公式为:
设某个伪ID 码同时有m个标签选中的情况,出现了碰撞,运用公式(5)并结合标签并行识别算法给出该标签出现m个碰撞问题的算法实现方法,并计算标签查询次数和吞吐率。
1.2 标签可并行识别过程的算法实现
通过采用Logistic-DFSA 算法实现标签的并行识别。算法Logistic-DFSA 是一种基于Logistic 映射和DFSA 算法的可并行识别算法,该算法将Logistic 混沌映射应用于扩频通信,实现了动态帧扩频标签识别。Logistic 映射是一种常用混沌映射,具有较好的遍历性、自相关性和互相关性,且该映射应用于扩频通信中可以满足大容量系统的要求[16]。该算法每个时隙中的标签数nslot计算公式为:
式中,F为初始帧长,通常选取F=8。
某个时隙能够识别m个标签(即同时选中同一个伪ID 码的标签数)的概率为:
当扩频码数量为M时,由式(6)和式(7)可得一帧中可识别的标签数量为:
式中:ncg为一帧中可成功识别的标签数量;nsx为每个时隙中的标签数;扩频码数量M可选用16、32 或64。
前文对伪ID 码识别过程及并行识别过程进行了分析,给出了标签并行算法的方法——PILD 算法,来解决出现碰撞的问题。下面从理论上对PILD 算法的实现及该算法的性能进行分析。
2 PILD 算法的实现及性能理论分析
基于伪ID 码的树型算法存在每个时隙只能识别一个标签的限制。标签可并行识别算法(Logistic-DFSA)存在的问题是:当标签数量过多时,会造成标签帧过长,导致算法的吞吐率急剧下降。本文定义吞吐率为吞吐量总数和查询总次数的比值。针对以上一系列问题,提出结合伪ID 码和Logistic-DFSA 算法的PILD 算法,该算法可以极大地降低标签查询次数,增大吞吐率。在本章中将阐述算法流程的实现和对算法的性能进行分析。
2.1 算法实现
首先,由预测算法估计得出识别范围内标签的总数量,然后对所有标签使用伪ID 码进行分组。如果出现多个标签选择同一个伪ID 码,则采用标签并行识别算法——Logistic-DFSA 算法进行处理。PILD 算法具体流程如下:
步骤1:阅读器通过使用标签预测算法预测识别范围内待识别标签的数量n。
步骤2:阅读器向标签发送数值n,n为步骤1 中阅读器预测的待识别标签数量。标签在接收到数值n后,利用随机数生成器随机产生1~n内的任意一个数作为自己的伪ID 码。
步骤3:阅读器设立初始值为0 的变量a和i,变量a用于判断是否识别完所有的标签,变量i用于判断并记录当前伪ID 码的使用情况。
步骤4:若a<n且i≤n,则执行步骤5;否则算法结束,完成所有标签的识别。
步骤5:当i≤n时,阅读器向识别范围内所有标签发送判断数值i,i为阅读器产生的伪ID 码。标签在接收到i后,判断自己的伪ID 码是否与接收到的伪ID 码i相等,如果相等表明该标签选择了当前阅读器发送的伪ID 码,此时该标签进行响应。
步骤6:阅读器在相应的时间内判断是否有标签进行响应。若没有标签响应,则表示当前伪ID 码为空伪ID 码,执行赋值语句i=i+1,转到步骤4 进行下一个伪ID码识别;若有标签响应,则继续执行步骤7。
步骤7:阅读器判断响应的标签是否发生碰撞,即选择当前伪ID 码的标签个数m是否大于等于2(本文m为同一时间选中同一伪ID 码的标签数。m的取值在2≤m≤3 范围内概率大)。若有发生碰撞,则利用标签并行识别算法(Logistic-DFSA 算法)进行识别,并向识别完成的标签发送静默指令,接下来执行公式(9)所表示的程序赋值语句,同时执行赋值语句i=i+1;若响应的标签没有发生碰撞,则直接识别回应响应的标签,识别完成后,向其发送静默指令并执行a=a+1。最后执行赋值语句i=i+1,转到步骤4。
PILD 算法流程如图1 所示。

图1 PILD 算法流程
2.2 性能分析
PILD 算法的识别次数为:
每个伪ID 码最多有m个标签同时选中,出现m≤6情况的概率较大,故Logistic-DFSA 选用32 个扩频码即可完成识别。由式(5)可得在本算法中Logistic-DFSA的查询次数,即伪ID 码识别后的碰撞次数QLogistic,公式如下:
由式(3)、式(4)、式(11)推导出伪ID 码识别次数QID的表达式为:
由式(10)~式(12)得PILD 算法识别总次数公式为:
由式(13)可推出PILD 算法的吞吐率为:
式中:T为吞吐率;Q为PILD 算法的总查询次数;n为预测标签总数。
由2.1节可知,当L≈n时,吞吐率最大,由式(14)得:
n趋近无穷大时,对式(14)求极值得到该算法吞吐率的最大值Tmax为0.791092。传统算法一次只能识别一个标签,存在某些标签因多次发生碰撞而未被识别的饿死现象,而本文算法运用可并行识别算法很好地缓解了这种情况。下文对PILD 算法的标签饿死概率进行分析。
2.3 PILD 算法的标签饿死概率
RFID 标签识别过程中,传统算法会发生有些标签因多次发生碰撞而未被识别的现象,即标签饿死现象。PILD 算法的标签饿死概率定义式为:
式中T为PILD 算法的吞吐率。在本文中,对比算法的标签饿死概率也由该公式得出。由公式(15)得PILD 算法的标签饿死概率为20.89%。
3 对比算法的吞吐率和查询次数
对比基于伪ID 码的树型防碰撞算法和单纯使用Logistic-DFSA 算法识别标签的性能。
3.1 基于伪ID 码的树型防碰撞算法
该算法首先利用伪ID 码对待识别标签进行分组识别,若回应的标签无碰撞则直接识别,若发生碰撞则采用碰撞跟踪树型算法进行识别。
由文献[15]可得基于伪ID 码的树型防碰撞算法的总查询次数计算公式为:
由于在该算法中吞吐量总数为标签的总数量,故吞吐率计算公式为:
式中:T为吞吐率;Tmax为该算法吞吐率最大值;Q为标签查询总次数。该算法吞吐率最大值为0.614 1。由公式(15)得该算法的标签饿死概率为38.59%。
3.2 Logistic-DFSA 算法
由本文的1.2 节可知,Logistic-DFSA 算法某个时隙能识别m个标签的关系式为式(7),一帧中可识别的标签数为式(8),而m个标签出现在一个时隙中的概率为:
扩频码数量为M时,由式(8)可得查询次数为:
该算法的吞吐量总数[16]为:
式中Q1为Logistic-DFSA 算法的吞吐量总数。
当M>2 时,由式(20)可得:
由式(19)和式(21)可得该算法的吞吐率为:
当扩频码M=32,帧长F=8,标签数量为800 时,吞吐率T(n,F,M)=0.029 56;当扩频码M=32,帧长F=8,标签数量为1 200 时,吞吐率T(n,F,M) =0.00152。由此可见,在标签数大于800 时,该算法的吞吐率趋于0。
式(20)中T(n,F,M) 为Logistic-DFSA 算法吞吐率,该算法吞吐率最大值为:
由公式(15)得该算法的标签饿死概率最小值为24.47%。本文对PILD 算法的实现进行了理论推导,给出了算法流程图,对该算法的性能进行了理论分析,推导出了查询总次数和吞吐率的计算公式,同时,给出了吞吐率最大值。
4 仿真及性能对比分析
4.1 实验设置
为了验证PILD 算法的性能,对Logistic-DFSA 算法、基于伪ID 码的树型防碰撞算法、PILD 算法从系统吞吐率、总查询次数和平均查询次数三方面进行Mathematica 仿真,并对仿真结果进行分析。仿真环境采用普通智能仓库,以通用无源标签为例,初始帧长F=8,扩频码数量选取32,标签样本数量最大为2 000 个。由于选中同一伪ID 码的标签数m≥7 概率近似为0,所以仿真中以标签数碰撞数m≤6 为例。
4.2 吞吐率
PILD 算法的吞吐率计算公式为式(14),基于伪ID码的树型防碰撞算法吞吐率定义为式(17),Logistic-DFSA 算法的吞吐率计算公式为(22)。按照实验设置进行仿真,图2 所示为在待识别标签总数相等的情况下,PILD 算法、基于伪ID 码的树型防碰撞算法和Logistic-DFSA 算法三种算法的吞吐率对比图。
在图2 中点划线为:基于伪ID 码的树型防碰撞算法的吞吐率和标签数量的关系曲线,实线为PILD 算法吞吐率和标签数量关系曲线,虚线为Logistic-DFSA 算法的吞吐率和标签数量关系曲线。由图2 可知PILD 算法的吞吐率变化为:随着标签数的增多,吞吐率迅速增加至0.791 092,保持稳定。基于伪ID 码的树型防碰撞算法的吞吐率特性为:呈现先迅速下降后稳定的趋势,稳定在0.614 1。Logistic-DFSA 算法吞吐率最大为0.755 3,这种算法的特性呈现为:随着标签数量的增加,算法的吞吐率先增大再减小。标签数目在126.86 个时吞吐率达到最大值0.755 3,在标签数目大于800 个时吞吐率趋于0,与理论计算结果一致。由此可见,PILD 算法性能比Logistic-DFSA 算法稳定,吞吐率比基于伪ID 码的树型防碰撞算法的吞吐率提高了28.82%,相比于Logistic-DFSA 算法吞吐率提高了4.74%。
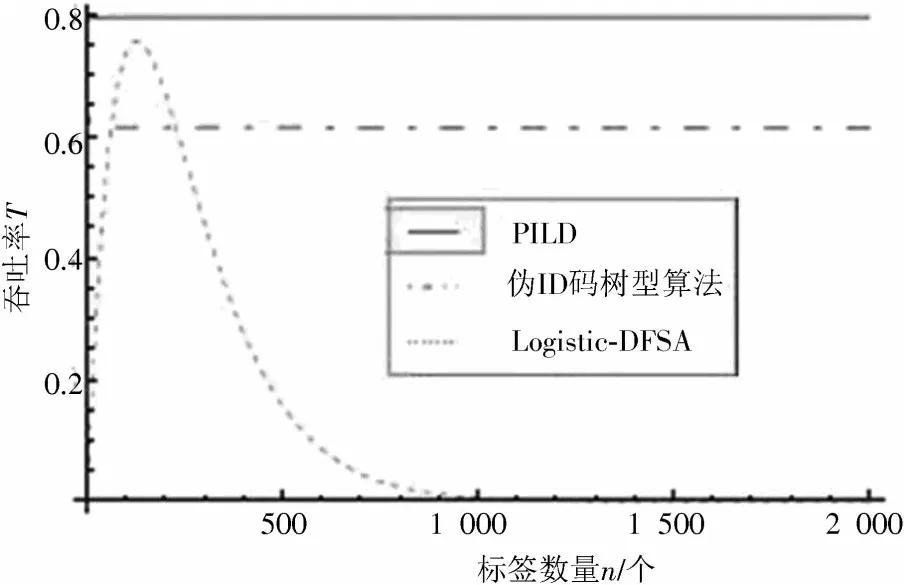
图2 吞吐率和标签数量关系图
4.3 查询次数分析
PILD 算法的总查询计算公式为式(13);基于伪ID码的树型防碰撞算法的总查询次数计算公式为式(16);Logistic-DFSA 算法的总查询次数计算公式为式(19)。平均查询次数计算方法为,即查询总次数与总标签数的比值。从图3的总查询次数对比结果可知,PILD算法的总查询次数明显少于基于伪ID码的树型防碰撞算法的查询次数,传输效率明显比基于伪ID 码的树型防碰撞算法要高。Logistic-DFSA 算法的总查询次数呈指数增长。当标签数大于1 400个时,PILD算法的总查询次数在三种算法中最少。
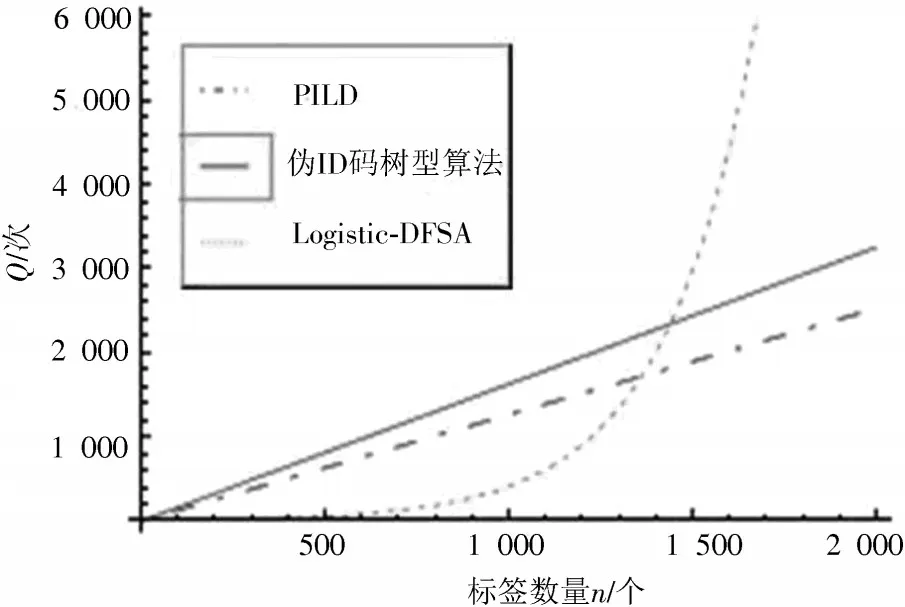
图3 总查询次数对比
由图4 所示的平均查询次数对比结果可知,PILD 算法的标签平均查询次数为1.26 次;基于伪ID 码的树型防碰撞算法的标签平均查询次数为1.6 次;Logistic-DFSA 算法标签的平均查询次数呈曲线变化,先逐渐减小后逐渐增大。当标签数大于1 400 个时,PILD 算法中的标签平均查询次数最小。
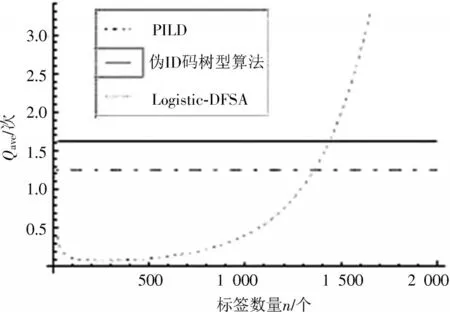
图4 平均查询次数对比
4.4 标签饿死概率对比
标签饿死概率计算公式为式(15)。图5 为三种算法标签饿死概率对比图。由图5 可知,三种算法中PILD算法的标签饿死率最低且保持不变,系统性能稳定。
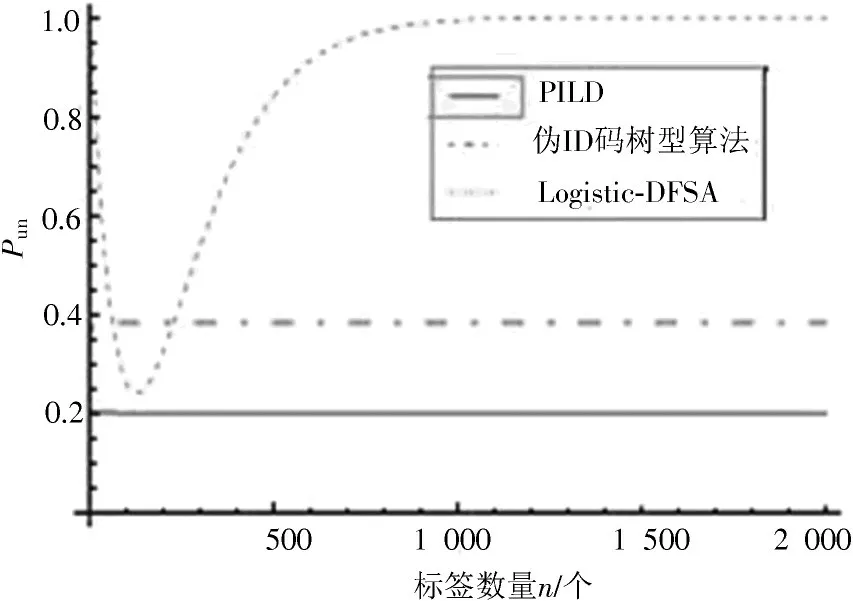
图5 三种算法标签饿死概率对比
5 结 论
已有的RFID 识别算法存在吞吐率较低、吞吐率不稳定、空闲时隙多、资源过多闲置、纵深太大等问题。针对以上问题,本文提出了PILD 算法,即结合伪ID 码分组和并行识别标签技术的算法,该算法稳定性好且吞吐率理论计算达到0.791092,相比基于伪ID 码的树型防碰撞算法提高了28.82%,相对于Logistic-DFSA 算法吞吐率提高了4.74%;平均标签查询次数为1.26 次,在标签数大于1 400 时,PILD 算法在三种算法中识别总次数最少;伪ID 码分组识别的应用有效地减少了“饿死现象”的概率。本文理论结论与仿真结果一致。



