周金泽
(昆明理工大学 信息工程与自动化学院,云南 昆明 650500)
0 引 言
近年来,随着互联网的飞速发展,国内外各大软件厂商也迅速发展起来,软件平台层出不穷。虽然这为用户提供了更多的选择,但同时也使得软件市场竞争日益激烈。为了竞争用户资源,不同软件公司会推出不同的优惠政策,以吸引用户并扩大推广其公司平台。这样做可以提高公司的竞争力和市场份额。然而,这种优惠政策也吸引了一些以盈利为目的的APP 虚假用户。
APP 虚假用户[1]发布虚假用户体验,引诱其他用户下载,或恶意诽谤其他有竞争关系的软件。因此,识别并剔除APP 软件中的虚假用户变得尤为重要。开发者可以通过数据分析和机器学习等技术手段,识别出那些存在虚假行为的用户,并在后续的运营中进行更精准的用户分析。对于真实的用户,可以帮助开发者更好地了解用户需求,以便更好地改进软件性能和用户体验。
1 相关工作
在虚假用户识别领域,学者们提出了许多基于用户评论与行为特征的虚假用户识别方法。例如,文献[2]指出通过批量采购物联网卡,并通过未进行实名认证的漏洞进行短信诈骗等行为的用户,将其认定为虚假用户,为了实时识别潜在的虚假用户,可以建立异常行为监控模型。这些模型能够有效识别虚假用户并提高平台的安全性。文献[3]采用集成学习算法Adaboost、随机森林和提升树,通过收集用户的通信行为和平台使用行为等统计特征,并将其与集成学习基础和简单基本分类算法(如逻辑回归、K 最邻近法等)相结合,以实现高精度的用户识别分类。
虽然这些方法可以识别出虚假用户,但是忽视了用户之间的关联性,并且在模型选择上忽视根据APP 虚假用户关联特征选择适合的特征提取办法与分类模型。针对上述不足之处,本文提出了一种基于用户关系与HCM(Joint HetGNN and CNN-based Model)的APP 虚假用户识别。
2 基于用户关系与HCM 的APP 虚假用户识别
本文提出了一种基于用户关系与HCM 的APP 虚假用户识别算法。首先,构建APP 用户关系图;接着,构建HCM 模型进行APP 虚假用户的识别。整体算法流程框图如图1 所示。
2.1 APP 用户关系图构建
为了识别出APP 虚假用户,首先要构建APP 用户关系图(APP User Relationship Graph)。
定义1APP 用户关系图:APP 用户关系图是一种特殊类型的用户关系图,用于表示一个APP 软件应用市场中用户与用户、用户与软件、软件与软件之间的关系。由用户节点、软件节点和关系属性组成。用户节点表示APP 应用市场中的注册用户,每个用户节点包括用户IP、用户名两种信息。软件节点表示APP 软件本身,用APP 的名称来表示,每个软件节点包括软件名称与软件类别两种信息。关系属性包括用户与用户、用户与软件、软件与软件之间的关系属性类型和权重。
本文定义了六种关系属性,如表1 所示,分别为:用户与用户之间的用户名相似度、用户与软件之间的好评占比、用户与软件之间的评价时间重合度、用户与软件之间的前后评价逻辑一致性、用户与软件之间的用户评价软件次数、软件与软件之间的软件类别是否相似。

表1 实体关系属性定义
通过上述关系属性对APP 用户关系图进行构建。
2.2 HCM 模型构建
为了识别APP 虚假用户,在用户关系图构建的基础上,提出了一种基于异构图神经网络(Heterogeneous Graph Neural Network, HetGNN)[4-5]与卷积神经网络[6]的联合模型(HCM)。该模型主要分为两个部分:
1)用户关系特征学习。该部分使用异构图神经网络(HetGNN)来学习用户关系图的用户关联特征,并完成用户节点的嵌入,得到用户节点向量。
2) 决策分类。 该部分使用卷积神经网络(Convolutional Neural Network, CNN)来学习用户节点向量的特征,从而完成APP 虚假用户的决策分类。基于HCM 模型的APP 虚假用户识别流程如图2 所示。

图2 基于HCM 模型的APP 虚假用户识别流程
2.2.1 用户关联特征学习与节点嵌入
在构建完用户关系图之后,本文将多个用户和多个软件进行关联。接下来,需要学习APP 用户关系图的关联特征。为此,可以使用图卷积神经网络(Graph Convolution Neural Network, GCN)来抽取图的关联特征[7]。然而,使用GCN 会遇到以下几个问题:
1)异构图中的大多数节点并不会连接所有类型的其他节点,而且节点能够连接的邻居数也不同。大多数GCN 模型直接汇聚邻居节点的信息,但是由于节点信息随距离增加而减弱,节点会受到弱相关邻居节点的干扰,从而影响信息表达。
2)对于冷启动节点来说,由于邻居节点数量不足,无法进行充分表示。
3)不同类型的邻居节点对生成节点Embedding 的贡献也会有所不同。
4)在使用GCN 处理异构图时,APP 用户关系图的权重值无法纳入计算,会导致特征丢失。
鉴于GCN 的缺点,本文提出使用异构图神经网络(HetGNN)进行用户关联特征的学习。HetGNN 是一种用于处理异构图数据的图神经网络模型,它可以对具有不同节点类型和边类型的异构图数据进行建模和表示学习,以便更好地理解和利用异构数据之间的关联。相对于传统的图神经网络模型,HetGNN 采用了多层注意力机制[8]和混合邻居信息聚合[9]的方法,以更好地捕获异构图中不同节点类型之间的关系和相互作用。
HetGNN 是一种基于异构图的节点嵌入方法,其工作原理如下:
1)采用一个基于重启策略的随机游走方法,对每个节点进行采样以获取其固定数量的强相关异构邻居。
2)根据邻居节点的类型将其进行分组。
3)使用双向长短期记忆网络(Bidirectional Long Short-Term Memory, BiLSTM)[10]对异构内容的特征进行编码,从而获得每个节点的内容嵌入。
4)使用另一个BiLSTM 对不同邻居(类型)的内容嵌入进行聚合,得到该类型的特征表示。并且利用注意力机制来衡量不同异构节点类型的影响,然后将它们组合起来,生成最终的节点嵌入向量。
5)使用一个基于图的上下文的损失函数和小批量梯度下降的方法来训练模型[4]。
使用HetGNN 进行节点向量化,可以将上一章节得到的APP 用户关系图中的用户节点之间的关联特征通过向量化的形式进行展现。具体地,通过邻居聚合与关系传播的方法,将每个用户节点嵌入8×16 的二维向量V,V=[v11,v12,…,v26;v21,v22,…,v36;…;v81,v82,…,v96]。用户节点向量可以根据公式(1)得到:
式中,ℱCθx(xi)为x的映射函数,也可为自身,θx是需要学习的参数。
该向量充分考虑了用户关联特征,因此可以更准确地挖掘出隐藏在不同用户之间的虚假用户行为。通过大量数据的综合分析,这种方法可以有效地提高识别的准确性和覆盖率,挖掘深层次的关联特征,从而更好地应对APP 虚假用户问题。接下来,本文将对得到的用户节点嵌入向量[11]进行进一步的处理。
需要注意的是,在进行进一步处理之前,本文需要选择合适的处理方法和算法,需要考虑具体问题的特征、数据的规模和性质等因素,并进行充分的评估和验证。这样才能充分发挥用户节点嵌入向量在应用中的优势,实现更加精准和高效的数据处理和分析。
2.2.2 基于卷积神经网络的决策分类
在2.2.1 节中,本文基于APP 用户关系图得到节点嵌入向量。对于用户节点向量,表示为一个矩阵,其中每个元素表示向量中的一个值。同时,该向量并不是有着时间顺序关系的向量序列,而是具有空间位置信息的二维向量。在这种情况下,CNN 可以利用卷积操作来提取向量中的局部特征,并通过池化操作将特征降维。这些操作可以有效地提取用户节点向量中的关联信息,从而实现APP 虚假用户的识别。
经过实验与分析,本文基于APP 虚假用户识别任务,设计了如下的卷积神经网络结构:
1)输入层:输入为用户节点嵌入向量,尺寸为8×16×1。
2)卷积层1:第一个卷积层包含32 个卷积核,每个卷积核大小为4×4×1,卷积步长为1,进行填充。卷积操作后使用ReLU 激活函数和归一化来增加非线性特征,并减少过拟合。ReLU 激活函数的表达式如公式(2)所示:
式中:x表示输入值,当输入值x>0 时,该函数返回x;当输入值x≤0 时,该函数返回0。
3)最大池化层1:最大池化层可以减少卷积层输出的尺寸,并且对于旋转、平移和缩放具有一定的不变性。使用3×3 的池化窗口进行最大池化操作,池化步长为1。
4)卷积层2:第二个卷积层包含64 个卷积核,每个卷积核大小为3×3 进行填充。该卷积操作使用ReLU 激活函数和批量归一化处理。
5)最大池化层2:再次进行最大池化操作,以进一步减少卷积层输出的尺寸。
6)全连接层1:将卷积层的输出展平为一维向量,并输入到具有128 个神经元的全连接层中。该层使用ReLU 激活函数和批量归一化。
7)全连接层2:将上一层的输出输入到具有2 个神经元的全连接层中,这些神经元对应于两个类别:真实用户和虚假用户。该层使用Softmax 激活函数来生成输出。Softmax 函数如公式(3)所示:
式中:zi为第i个节点的输出值;C为输出节点的个数,即分类的类别个数,本文方法是基于虚假用户识别的二分类任务,故分类个数为2。通过Softmax 函数就可以将多分类的输出值转换为范围在[0,1]、和为1 的概率分布。
3 实验与分析
3.1 APP 虚假用户识别
为了统一HCM 模型的输入格式,将得到的APP 用户关系图使用节点矩阵来表示关系图中的节点信息,利用邻接矩阵来表示用户关系图的拓扑结构。将数据分20 批次送入HCM 进行模型训练,模型准确率变化如表2 所示。

表2 HCM 识别准确率 %
表2 展示了第1 批次、第5 批次、第10 批次、第15 批次、第20 批次的模型准确率。HCM 准确率曲线如图3所示。可见随着模型的不断训练,性能也随之在不断提升,直到到达一个平台期。

图3 HCM 模型识别准确率曲线变化图
3.2 对比实验
当前在虚假用户识别领域,文献[12]提出了一种增强的基于图的半监督学习算法(EGSLA)来识别推特(Twitter)上的虚假用户。文献[13]提出了一种基于用户关系与情感特征的虚假用户识别算法(UFIRA)来识别网上商城的虚假用户。为了进一步验证本文算法对APP 虚假用户识别的有效性,本文使用EGSLA 算法与UFIRA 算法进行APP 虚假用户识别,与本文算法形成对比实验,对比实验的识别准确率如图4 所示。

图4 文献算法识别准确率对比
根据实验对比,针对APP 虚假用户的识别,因为APP 软件用户的独特性质,本文算法识别准确率最高。EGSLA 算法与UFIRA 算法对于特定领域的虚假用户识别准确率较好,但是对于APP 虚假用户的识别效果较差。
3.3 跨领域实验结果
本文算法的处理对象是APP 软件用户,通过实验结果分析,证明了本文方法对识别APP 虚假用户的有效性。然而,处理对象的不同会导致模型在识别准确率上出现较大差异。为了验证本文提出的模型算法的泛化性能,使用开源的推特(Twitter)用户数据集[12]与开源的中文酒店用户数据集[13]来验证本文提出的基于用户关系的APP 虚假用户识别算法的泛化性能。本文算法对于其他领域用户数据的识别准确率如图5 所示。
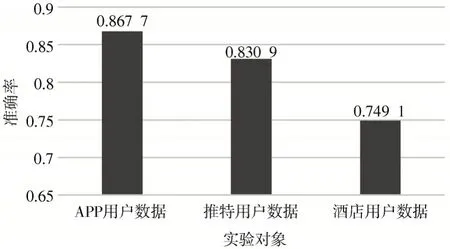
图5 跨领域对象对比实验
根据结果分析,对于推特用户数据,本文算法具有较好的泛化性,然而,对于酒店用户数据,因其数据内容的缺失,用户关系属性抽取不完整,导致构建的用户关系图不够完善,所以其识别准确率最低。
综上所述,本文算法对于其他领域的虚假用户识别也具有较好的识别效果,证明了本文算法具有较好的鲁棒性与泛化性。
4 结 语
本文提出了一种基于用户关系与HCM 的APP 虚假用户识别方法。首先,通过APP 用户关系图的构建关联多个APP 用户;然后,构建HCM 模型进行用户关联特征学习与用户节点向量的学习;最后,进行APP 虚假用户的识别,通过相关实验验证了本文方法的有效性。通过APP 虚假用户的识别,提高了软件使用反馈的真实性,为开发者和软件下载者提供了真实有效的信息。



