王潇天
(西安市航天中学,陕西西安,710100)
0 引言
目标检测(Object Detection)作为计算机视觉的重要应用,其主要目标是从给定的图像或者视频中定位感兴趣的目标并进行目标分类[1],这就需要从图像中对目标进行特征提取从而进行目标分类,而且需要对目标进行边界框的提取。近年来,随着卷积神经网络、深度学习等方法的应用,目标检测在速度和精度上都有了较大的进步,并广泛的应用在安防、自动驾驶等领域。

图1 目标检测流程图
如图1所示,目标检测一般包括区域选择,特征提取和分类三大步骤。区域选择主要产生检测使用的边框,由于目标出现的随机性,最初采用滑动窗口的方式实现。特征提取则直接影响了分类的准确性,传统方法是使用人工的方式提取特征,但往往由于目标形态、环境、光照的多样性导致结果不够稳定从而影响最终的效果。在此理论基础上,传统的方法主要使用图像预处理、待评价滑动窗口、目标特征提取、目标分类等。这些方法其研究的核心是基于机器学习的方法,主要关注特征工程的提取方面。
随着深度学习的发展,相比于人工设计的特征,通过模型自动提取和学习的特征可以更好的表达图像中的目标。而且在传统的方法中,手动提取的特征泛化能力较弱,不能很好的适应大规模的目标检测任务。随着深层次的卷积神经网络的广泛应用,通过多层级的卷积核,实现由低层次抽象到高层抽象的组合,从而将图像的特征进行更精确的提取。尤其是2012年在ImageNet挑战赛使用深度卷积神经网络以来,图像分类精度日益提高,并在2015年ImageNet挑战中首次超越了人类识别分类的能力[2]。
1 卷积神经网络
目标检测本质上属于有监督的机器学习问题,因此对于模型的输入,需要图片信息以及该图片的label信息[3]。图像在计算机中的存储使用三原色的方式,即每个像素点通常使用三个0–255的数值进行存储,在实际模型运算中,需要将三维的图像数据进行拼接,并添加对应的标签信息,随后将该数据作为输入进入到神经网络模型中。本文先简要介绍全连接神经网络,并在此基础上引入深度卷积神经网络。
■1.1 全连接神经网络
如图2所示的全连接神经网络,假定模型的batchsize为1,其输入节点数为图像的总维度(3×224×224),输出为要提取的特征向量的维度,或者是目标分类的个数,输出的节点总数与对应的输入的标签信息是一致的。中间部分是0–n个串行连接的隐藏层,使用多个网络层次的根本原因是增加模型的非线性,从而提高其拟合效果。
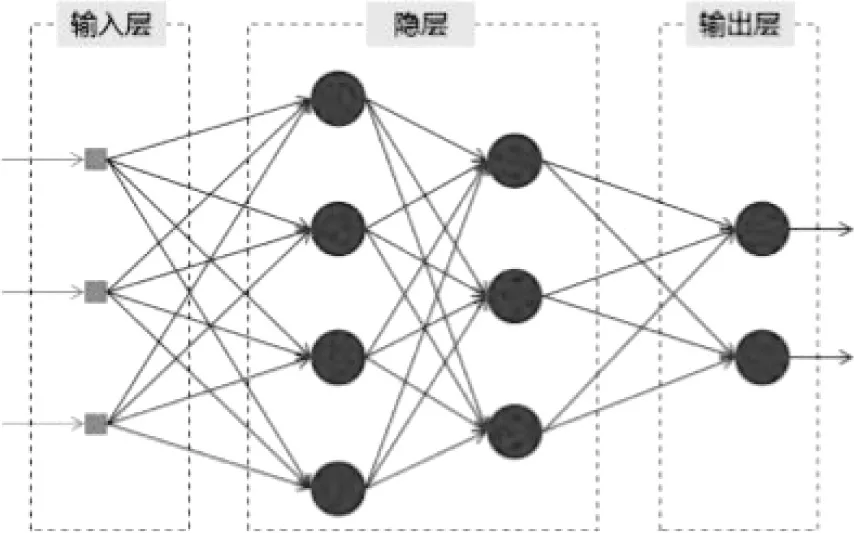
图2 全连接神经网络
对具体的每个计算节点,主要包括线性部分和激活函数部分,如图3所示,线性部分WTX+b 为每个输入节点匹配一定的权重并进行线性加权,激活函数部分σ(WXT+b)则为模型添加了非线性,从而更好的拟合真实数据分布。
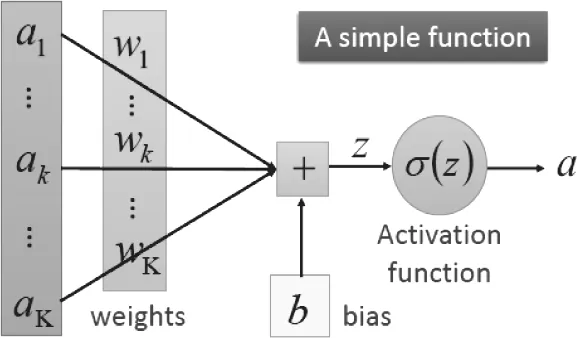
图3 单个神经网络节点
通过增加隐藏层的数目,可以实现更加复杂函数的拟合。但是在图像处理领域,简单的增加网络层次有一定的局限性:全连接神经网络对图像输入数据来说,数据维度过大,导致神经网络参数过大。在此基础上提出了使用卷积神经网络(CNN)的方法进行图像数据处理[4]。
■1.2 卷积神经网络
由于全连接神经网络存在权重参数冗余的问题,在此基础上提出的卷积神经网络通过使用权值共享和局部感受视野的方法,实现了权重数量的大幅度降低,同时将多个卷积层级联起来构成一定深度的网络模型,可以使图像抽象层次得以逐步提高,从而可以较好的实现图像的特征抽取。
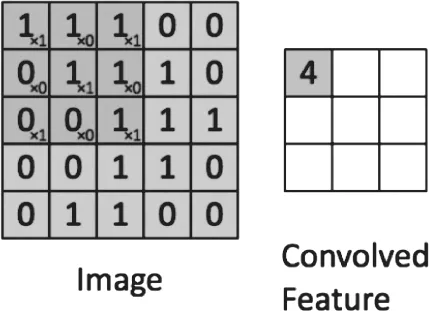
图4 卷积操作
卷积神经网络的核心即局部处理和参数共享。如图4所示,通过使用卷积核对输入数据的局部进行统一处理;并且共享同一个卷积核从而实现参数的共享。这样,大大降低了权重参数的数目,同时由于图像数据本身带有局部特性,因此这种方法也有利于提取图像的局部特征而不是孤立的以像素点的方式对待数据。
另外,卷积神经网络还使用了池化的方法进一步降低参数的维度并进一步提高抽象能力。如图5所示,在经典的vgg16模型中,将卷积、池化、全连接操作有机的组织在一起,从而实现降低参数维度、提取局部特征最终实现图像的特征分类。
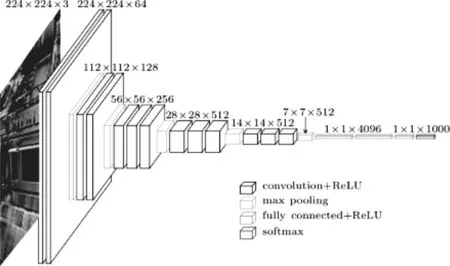
图5 典型的卷积神经网络VGG16
综上,使用CNN进行图像分类操作是基于深度神经网络、反向传播、卷积操作、池化、Softmax分类等操作最终实现了数据集的划分。而随着正则化、参数更新优化算法等新技术的不断完善,深层次的卷积神经网络模型取得了超越人类识别精度的表现,这也带来了其巨大的应用价值。
2 卷积神经网络在目标检测中的应用
在目标检测领域,我们不仅需要找出图片中感兴趣的物体,而且要知道它们的位置。位置一般由矩形边界框来表示,可以通过中心点坐标,高度,宽度(x,y,h,w)来表述,这也是数据标签组成的一部分。在分类问题的基础上,针对边框的预测需要相应的增加对边框的预测和回归。通常的做法是在输入的图片中采样大量的区域作为边框,然后判断这些边框中是否有我们感兴趣的物体,并通过回归的方法进一步调整区域边缘该来预测真实的边框位置。
边框的生成方法可以有多种,经典的方式通过图像中的纹理,边缘,颜色等信息产生候选区域(region proposal),经典的R–CNN就使用region proposal + CNN的方式替代了传统的滑动窗口+手工设计特征[5],开启了基于深度学习进行目标检测的热潮。在此基础上,改进的方法通过统一使用神经网络产生候选区域(Region Proposal Networks),更高效的利用了卷积后的feature map,从而大幅加快了速度和性能。
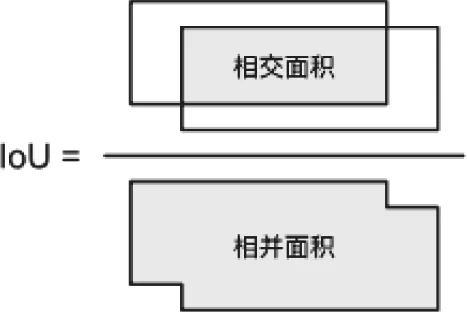
图6 IoU计算示意图
另外,神经网络可能会产生多个边框,如何评价预测边框的好坏并对其进行筛选是一个重要的评价指标。目标检测中主要使用交并比(IOU)即交集比并集对边框的好坏进行评价。在预测中,我们需要给定预测概率的阈值,只保留概率大于阈值的边框,但是仍有可能导致对同一物体产生大量相似的预测边界框。为了使得结果更加简洁,我们需要消除相似的冗余边框。常用的方法是非极大值抑制(Non–Maximum Suppression,NMS),对于产生的比较相近的预测边框,NMS只保留置信度最高的边框。通过不断的移除较小的IOU的边框,最终实现对每个物体只保留置信度最高的边框,从而实现高精度的对目标的识别和检测。
目前较为主流的检测框架主要有R–CNN系列和YOLO,SSD等,通过使用更高效的边框生成策略和卷积神经网络,使得目标检测的精度逐渐提高,并得以广泛应用。
3 应用领域与展望
通过机器实现目标检测的本质是模拟人的视觉感知能力,随着深度学习方法的大放异彩,目标检测取得了理论和应用上的突破。因此在安防,无人驾驶,机器人领域有着丰富的应用场景。比如在无人驾驶领域,对行人、道路、交通标志的准确识别直接影响到自动驾驶汽车的感知能力,并影响汽车的决策和判断,从而直接关系到其驾驶安全。在安防领域,通过大规模的目标检测应用,可以及时的发现可疑物体,并可以广泛的应用在智慧园区、智能城市中。同时,高精度的目标检测技术也是机器人领域必备的技能,物流机器人、无人机避障、机器手等高科技高度依赖于物体检测与识别技术。
高精度与实时性是当前物体检测领域的重点研究方向,也是进一步影响目标检测能否取得广泛应用的关键。其中R–CNN系列得益于更复杂的网络在精度方面不断取得佳绩,尤其是Mask R–CNN的提出,将R–CNN系列推向了一个高峰;另一方面,以YOLO为代表的精简网络则在实时性方面不断取得进展,同时融合了各方面的优势,目前在精度上也不断提高。总之,随着精度和实时性的不断进展,目标检测将更广泛的应用在诸多领域。



