熊晗
(重庆工商职业学院软件教研室,重庆,400052)
1 研究背景
目前深度学习框架针对训练样本有较高的要求,常见的自然语言处理可以使用普通文本语料,比如bert可以使用预训练的词向量做fine-tune,但在一些特定领域,比如法律、公安、金融领域等等,有较多的专业名词,且标注语料通常不多,使用普通语料训练的词向量进行下游任务效果不佳,针对这些场景的自然语言处理,存在如下的一些问题:
(1)专业领域文本的内容少部分词语比较专业化,但又非常关键。使用预训练的词向量来做fine-tune,很可能没有很好的挖掘出专业词汇的信息特征,导致效果不好。
(2)针对部分短文本使用CNN、RNN这类依靠位置顺序关系的模型,可能对非连续性以及短距离的语义信息建模能力不足。
(3)文本数量巨大,针对模型训练需要大量的标注样本也是困难点之一。
近年基于图卷积神经网络在自然语言处理中的应用目前相关的研究内容主要为以下两种:①针对图卷积神经网络在自然语言处理中的综述。介绍图神经网络的核心思想,以及如何运用图结构表示语言模型,并如何将相关的自然语言处理任务场景结合起来。②基于图卷积神经网络的框架研究与改进,这部分文章,结合现实的自然语言处理实际问题,重点研究图卷积网络的构架改进以及自然语言的图表示模型。
通过研究调查,图卷积神经网络与自然语言处理结合已经有理论基础认证,并有部分实际工作。本文重点将结合图卷积神经网络的结构特点,并针对具有图结构关系的文本场景(比如社交评论,微博关注等等),提取文本之间的关系信息,提升自然语言处理任务效果。
2 研究内容
■2.1 文本的图模型结构表示
作为图神经网络来说,如何将图结构的数据进行表示,是能否将该结构用于图神经网络进行深度学习的关键问题。同样,我们针对自然语言处理任务中的文本,就需要研究图嵌入方法,即旨在将图的节点表示成一个低维向量空间,同时保留网络的拓扑结构和节点信息,以便在后续的图分析任务中可以直接使用现有的机器学习算法。
本项目将以下两个思路进行文本图结构表示:
第一类,将每个文本作为顶点,将顶点之间的实际拓扑关系作为边条件与权值,例如文本作者与粉丝之间的关注关系,文本相互链接的关系等等。
第二类,是基于文本的实体与共指关系连接构建。将文本中的实体作为节点,并把实体之间的共指,同现,邻近实体连接作为边。从而使用图结构进行表示。
■2.2 图卷积神经网络模型的研究
图卷积神经网络直接将多层神经网络应用在图结构数据之上,并且根据邻接点与邻边信息生成进行图嵌入表示。假设一个图结构为G=
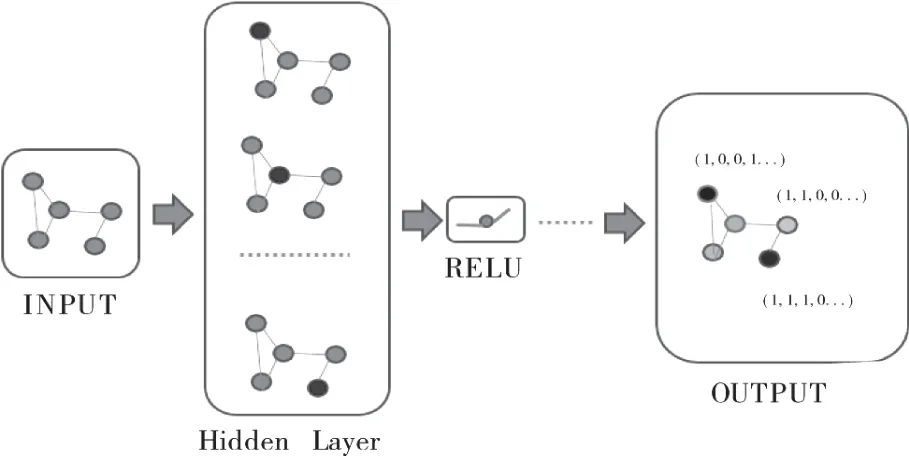
图1 图卷积神经网络构架

输入为图结构的数据,每次选取一个点作为中心点,按照公式1进行一次计算,当遍历完所有点后,一层计算完成,经过多层堆叠,直到所有的点计算出来的图嵌入向量收敛则训练完成。构建好图模型后,后续根据下游任务添加相应神经网络层即可:

其中ƒ(.)表示通过图卷积神经网络学习的状态更新函数,X表示所有顶点的特征集,A表示顶点对应的邻接矩阵。
3 实验设计
本次实验选取自然语言处理任务中的分类任务来进行对比,分类任务是自然语言处理中的基本任务之一,实现简单,验证相对容易且清晰。
考虑到图卷积神经网络的处理特点,实验选取的语料需要专业领域较强,标注量不大,并且具有一定图结构关系的文本。本次实验爬取知乎上相关文章5400篇,内容包括计算机技术类、金融投资类、旅游类等共8类别,采用人工取其中400篇文章进行类别标记,平均每种类别标记50篇。同时爬取文章之间的链接跳转关系,文章作者之间的关注关系,以及粉丝关系,建立文章之间的拓扑图关系如图2所示。
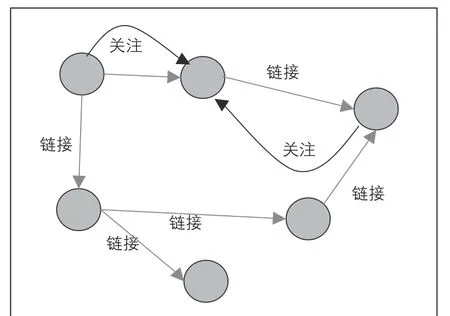
图2 文章之间的关系拓扑
将关系图转换成邻接矩阵N,则可以带入到公式1进行迭代计算。最后加上softmax层采用公式2,即可在迭代收敛时,判断出文章类型。总体流程图如图3所示。
观赏竹栽培品种整理。主要开展牡竹属、慈竹属等观赏竹栽培品种的整理与新品种定名工作,现阶段已完成牡竹属1种新品种的定名,取得国际登录号;以及川牡竹1号、硬头黄7号新品种登录的申报工作。
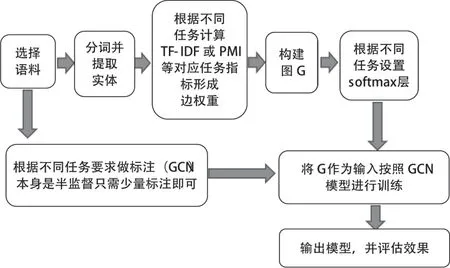
图3 实验任务处理流程图
损失函数,我们使用交叉熵来进行计算,如公式3所示:
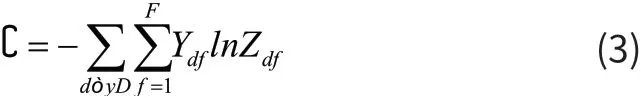
其中DY表示有标签的文章集合,F表示文章所有的特征值集合,Y是所有文章的标注矩阵。结合公式2的结果,即可计算损失函数。
结构采用两层GCN结构,直接将爬取到的文本关系网络作为输入,进入两层GCN隐藏层,最后加上softmax进行输出,该结构能将文本的链接关系放入神经网络中,对这部分信息进行有效挖掘,也是后续观察分类效果的关键点。整体网络结构如图4所示。
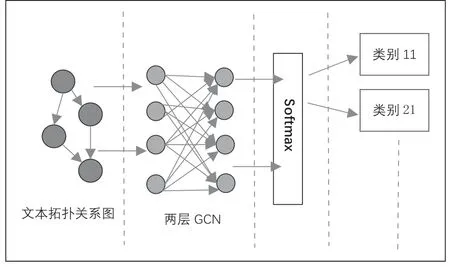
图4 图卷积神经网络构架
4 实验分析
为了测试图卷积神经网络针对选取文本的分类效果,本文选择了几种常见的自然语言处理的机器学习构架来进行比较,选取的几种常见模型介绍如下:
TF-IDF+LR:采用词袋模型的经典分类算法,其主要的思想是将每篇文章的关键词提取,通过词频与逆词频的处理,找到主要关键词,在进行逻辑回归算法分类。
LSTM:LSTM是一种典型的RNN构架算法,采用长短期记忆模型,对每个文本的字进行学习处理,来理解文本内容。
FastText:fasttext是facebook出品的一种快速的文本分类算法,其中新思想与Word2vector思路一致,都是通过深度学习中间变量来表示文本向量。
Bert:Bert作为自然语言处理近年来的佼佼者,在各项任务都取得了不错成绩,但前期的大量训练只有大型公司才能完成,使用fine-tune进行迁移学习,但针对特定领域,效果有待提升。
加上本文使用的GCN针对文本的分类,5中方法的实验效果如表1所示。
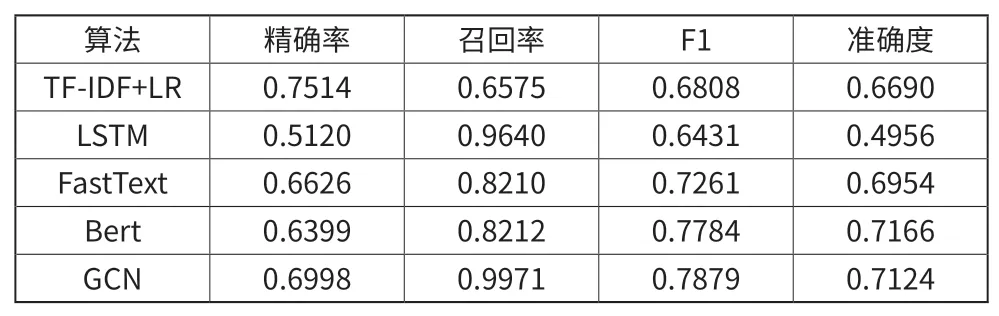
表1 真实数据上5中分类算法的指标比较结果
通过结果可以看出在本次实验选择的语料文本特点下,使用GCN图卷积神经网络模型的结果相对于其余4中经典的文本分类常用算法框架来说,效果有一定的提升。
5 结束语
本文针对目前近年来流行的图卷积神经网络框架为研究对象,结合了图卷积神经网络的特点,选取自然语言处理中的分类任务为目标,设定了在特定场景下的一些具有图网络关系的语料进行研究。使用实验证明,在专业词汇较多,文本简短、文本之间有丰富连接关系,且标注数据量较少的语料场景下,图卷积神经网络的学习效果更好。



