姜龙训 张玲
1.首都医科大学公共卫生学院,北京100069;2.北京市丰台区南苑社区卫生服务中心,北京100076
用于单核苷酸多态性数据聚类分析的方法比较
姜龙训1,2张玲1▲
1.首都医科大学公共卫生学院,北京100069;2.北京市丰台区南苑社区卫生服务中心,北京100076
对于目前用于单核苷酸多态性(SNPs)数据进行聚类分析的统计方法进行了比较说明,并在其中遴选出了5种具有代表性的统计方法,分别对每种方法具体进行分析。在每种聚类方法的论述过程中,均分为该方法的原理、计算方法和公式、优点与缺陷几个部分。并且在讨论部分对各种方法进行了总结归纳,提出了今后针对SNPs数据聚类计算方法的发展方向预测。
单核苷酸多态性;聚类分析;基因;数据挖掘
在人类的基因组中存在各种形式的变异,其中,单核苷酸多态性(single-nucleotide polymorphisms,SNPs),即单个的核苷酸变异所引发的DNA链序列的多态性,是这些变异中最普遍的形式。根据数据统计,在人类含有不低于30亿个含氮碱基对数量的基因组中,SNP出现的概率在1/1000左右[1]。如何利用这些信息,建立数字模型,探索这些基因与位点和疾病的关联,成为了摆在科学家面前的一个富有挑战意义的课题[2]。
科学家们在长期的研究中,根据“物以类聚”的原始思想,衍生出了对复杂数据或者试验对象等进行归类的一种多元统计学分析方法,即现在归属于统计学分支的聚类分析(cluster analysis),又称其群分析。这种统计方法的核心思想从诞生之日起就未更改,即在没有任何可用来参考的或者依从的规范下(即先验知识准备程度为零),按照被研究对象或者样品本身的特点或者性状,进行最大程度合理的分类。通过聚类分析的计算过程,不仅可以保证在最终所分的类别情况下,同一类别中的对象或者样品,能够具有最大程度的相似性,而且使不同类别中的对象或者样品,拥有最大程度的相异性。以大量相似为基础,对收集数据来分类,成为了聚类分析计算本身的最终目标[3]。从统计学的观点看,聚类分析计算是通过数据建模简化原有数据复杂程度的一种方法,而从实际应用的角度看,聚类分析计算亦是数据挖掘的主要任务之一。高维度高通量SNPs数据聚类分析,是近现代聚类分析中一个非常活跃的领域,同时也是一个非常具有挑战性的工作。
目前用于高维度SNPs数据聚类分析的方法有很多种,常用的几大类有Logistic回归、潜在类别分析(latent class analysis,LCA)模型、结构方程模型分析(structural equation modeling,SEM)、以决策树为基础的分类回归树(classification and regression trees,CART)和随机森林(random forest,RF)算法的分析[4]、基于贝叶斯网络(Bayesian networks,BNs)模型的分析、基于神经网络(neural networks,NNs)模型的分析和支持向量机(support vector machine,SVM)的方法等,上述种类的方法各有其适用性,在聚类计算的效能方面也广泛存在争议。本文从以上几类方法中,遴选出应用较广泛、理论相对成熟的潜在类别分析、分类回归树模型、贝叶斯网络潜变量模型、BP神经网络模型和支持向量机5种具体方法进行比较,阐述其在SNPs数据聚类分析中的意义。
1 潜在类别分析
诞生于20世纪50年代的LCA方法,其基本原理是通过引入潜变量概念,建立潜在类别模型(latent class model,LCM),在保证维持各个显变量的数据局部独立性的基础上,力图用少数的潜变量与各个显变量建立关系,然后以数量相对较小的潜变量进行对象关系解释。而争取利用最少数量的且关系上互相排斥的潜变量对各个显变量的概率分布进行最大程度的解释,就是潜在类别分析的基本假设,这种假设的思想倾向于各种显变量对其类别进行解释的潜变量都有反应的选择性[5]。潜在类别分析的统计原理建立在概率分析的基础之上。一个潜在类别模型是由一个(或多个)潜在变量和多个外显变量组成的Bayes网[6]。
完整的LCM分析过程包括数据概率变换参数化、模型参数估计与识别、模型评价指标选择、分类结果解释等[7-10]。
1.1概率参数化
潜在类别概率和条件概率构成了潜在类别模型概率参数化过程中的两种参数。假设某数据集含有三个彼此之间不相互独立的外显变量,以A、B、C表示,而且每一个显变量分别具有的水平数为I、J、K。按照假设,若寻找到合适的潜变量X,则X需满足一下条件:首先,要求合理解释A、B、C的关系;第二,在潜变量的各个类别之中所有显变量维持最大的局部独立性,则为潜在类别分析,如果潜变量X中含有T个潜在类别的话,用数学模型表达就为:


条件概率,用πitAX表示,其意义可以解释成:外显变量A的第i个水平更倾向于划归到第t个潜在类别的个体的概率。由于各个潜变量的各个水平处于相互独立的状态,所以各外显变量的条件概率总和为1,即:

1.2参数估计与模型拟合
在潜在类别模型的参数估计过程中,最大似然法(maximum likelihood,ML)是被最广泛使用且计算软件中默认的方法。EM(expectation-maximization)、NR(Newton Rapson)算法在计算迭代过程中为最常用的方法,而其中前者更为常用。在潜在类别模型评价方面,AIC评分(akaike informationcriterion)和BIC评分(bayesian information criterion)成为使用最为广泛的拟合评价指标。两者共同点为:其计算理论基础都为似然比χ2检验,对于模型对应的参数限制不一致的情况下,也可以用来横向比较,且结果简单直观,都是数值越小表示模型拟合越好。Lin与Dayton曾经指出,当研究的样本数量级达到或者超过千位级时,BIC指标更可靠,否则AIC更佳[11]。
1.3潜在分类
完成最优化模型的确定之后,就可以利用模型进行计算,将每个外显变量的数据值分配到判定的潜在类别之中,通过这个过程,完成数据的后验类别分析,即潜在聚类分析。上述分类的理论依据是着名的贝叶斯理论,分类的计算公式为:

潜在类别分析虽然理论建立时间较早,但是一直依靠着自身的优势在聚类分析领域有一席之地,其计算思想中融合了结构方程模型与对数线性模型的构思。该算法的目的明确,即数量众多的显变量之间的关系,可以用最优化的组合模式,使用最少的潜变量来解释。结构方程模型只能够对连续型潜变量处理的缺陷,在潜在类别模型问世后得到了相当程度的弥补,特别在设计思想范围中,使得研究者以概率论为基础,能够通过数据对分类结果之后所隐藏的因素做更为深刻的了解,这些都要归功于分类潜变量的引入这一有效提高分类效果的方法[12]。
但是,由于该方法的分析原理比较简单,只是脱胎于贝叶斯概率理论的概率参数化,所以使得该方法在聚类分析过程中,如果SNPS数量较少,则表现出不错的聚类效果,但如果SNPS数据维度过高,则有失水准。具体表现在高维度高通量的SNPS数据聚类分析过程异常复杂,时间消耗过长,而最终得到的聚类结果也容易在解释时发生阻碍。
2 分类回归树模型
CART[13]不仅可以在已经获得的数据库中通过一定的规则提炼出关联,而且是对隐藏在各种指标中的分类属性进行量化计算成为可能,其作为数据挖掘技术中的经典聚类分析方法,为高通量SNPs数据的聚类分析制造了一个科学而准确的平台。分类回归树的基本原理为:如果对于已经给定的待分类对象X,已知其可以进行Y个不同属性的分类,那么该模型将模拟把X逐级递归的分解为多个数据子集,并且认为Y在子集上的分布状态,是均匀并且连续的,而分解的方法为二叉树分类法。该方法如同自然界中的树木一样,数据集X由根部向叶部逐步分解移动,每一个划分点即树木分叉点的原因,由分支规则(splitting rules)确定,最终端的叶子表示划分出的最终区域,而且每一个预测样本,只能被分类到唯一的一个叶子,同时Y在该点的分布概率也被确定下来。CART的学习样本集结构如下:

其中,X1~Xm可以称之为属性变量,Y可以称之为标签变量。但在样本集中无论是X或是Y,其变量属性可以容许多种形式,有序变量和离散型变量都可以存在。若Y处于有序变量的数值情况时,模型被称为回归树;若情况相反,称之为分类树。
2.1分类回归树的构建
将给定的数据集L转化成与其对应的最大二叉树,这个过程称之为构建树为了寻找到对应数据集的最优分支方法,最大杂度削减算法被运用到构建过程之中。在进行分支时,数据中每个值都要纳入计算范围,只有这样才能计算出最佳的分支点进行分叉。CART的构建离不开Gini系数的使用。若数据集L中,含有记录的类别数量为N,Gini系数的表达式就为:

其中,Pj表示T中第N个分类数据的划分频率。对于任意的划分点T,如果该点中所包含的样本量非常集中,那么该点的Gini(T)值越小,从分类图上显示为该节点分叉角度越钝。欲构建最终的Tmax,就要重复操作,将根节点分支为子节点,而这种递归分类的计算,最好利用统筹学中的贪心算法。
2.2树的修剪
当Tmax建造好之后,下一步需要对其进行所谓的修剪操作,就是去掉那些可能对未知的样本分类计算精度上,没有任何帮助的部分,其目标是处理掉对给定数据集中的噪音干扰的问题,以便形成最简单最容易理解的树。通常对树进行修剪的方法是以下两种,先剪枝方法(prepruning)与后剪枝(postpruning)方法,两者都有助于提高已经建成的树,脱离开训练数据集后,能够正确地对未知数据进行分类的能力,而修剪方法都是通过统计计算,将理论上最不可信的分枝去掉。
2.3决策树评估
测试样本评估法(test sample estimates)与交叉验证评估法(cross-validation estimates)[15]是通常被用来对CART模型进行评估的方法,而前者的使用率更高。该评估方法的原理与多因子降维法有些类似,而且即时效率比较高,在学习数据集囊括的样本量比较大的情况下,该方法的优越性就更加突出,其原理可以解释为:将原始的数据集L随机分成两部分,分别为测试集L2与样本集L1,利用L1生成一系列的Tmax,而且按照序列T1>T2>T3>…>Tn,将测试集L2放到序列中的树模型之中,TK为L2中的每个样本逐个分配类别,因为L2中每个样本的原始分类是事先已经知道的,则树TK在L2上的误分情况可以利用公式(6)计算:

作为一种经典的通过数据集进行训练并有监督学习的多元分类统计模型,CART以二元分叉树的形式给出所构建出的分类的形式,这种方式非常容易解释,也非常容易被研究者理解和运用,并且这种方法与传统意义上的统计学聚类分析的方法构建完全不一样[16]。
但是CART方法对主效应的依赖程度很高,无论是每个分支的根节点还是后续内部的子节点,其预测因子都是在主效应的驱动下进行,并且每个节点都依赖于上一级的母节点分支的情况。而且CART方法对结果预测的稳定性上也有缺陷,具体表现在,如果所给数据集中的样本有小范围的更改,那么所产生的蝴蝶效应就会导致最终所构建的模型与原始模型的差别很大,当然分类结果也就难以一致。
3 贝叶斯网络潜变量模型
BNs是一种概率网络,它用图形的形式来对各种变量间的依赖概率联系做描述,经典的图形中,每一个随机变量利用节点的方式表达,而变量之间的概率依存关系则利用直线表达,直线的粗细表示依赖的强度。在BNs中,任何数据,当然也可以是高通量SNPs数据,都能够成为被分析的变量。BNs这种分析工具的提出,其原始动力是为了分析不完整性和概率性的事件,它可以从表达不是很精准的数据或信息中推理出概率结果。
网络的拓扑结构和条件概率分布作为构成BNs的两大核心组件,如果再将潜变量概念引入BNs,则成为了BNs潜变量模型。被包含在BNs中的潜变量数量,决定着这个模型的复杂程度,因为一般来讲,在实际工作中,研究者常常利用潜变量来进行聚类计算,所以BNs潜变量模型也成为了一个经典的潜结构模型(latent structure model)或潜类模型(latent class model)。
3.1模型参数
在满足一定的假定条件下,才能对BNs模型进行参数学习的过程。根据文献记载,这些条件分别为:所有的样本处于独立状态;无论全局和局部,均处于独立状态;变量不能为连续变量,只能是分类变量。在上述条件得到满足的情况下,该模型可以利用数据,计算出网络拓扑结构中各个节点的条件概率θ,且服务于制订的BNs模型结构η和数据集D。计算的方法有最大似然估计法等[17]。
3.2模型选择
与LCA方法类似,BNs模型也利用函数来对模型的拟合优劣程度进行评价,衡量标准也是BIC、AIC、BICe等的评分,一般来说,分数低的模型更加优化。
3.3模型优化
在通过评分的方法来确定BNs潜变量模型后(需综合考量BIC、AIC、BICe三者的得分),该模型下一步就转化成了如何去搜索符合所给数据集的最优模型的过程。由于该网络的拓扑结构,使得该模型结构的数目的增长速度非常快,与纳入模型的变量数的增长呈指数级别比例,能够适应这种数量级的搜索算法是启发式的,其过程是比较不同的模型的评分,其中最常被使用的是爬山算法(hill climbing)[18]。
利用BNs模型进行高通量SNPs数据聚类,其优点之一就是在该模型中,所有遗传的模式都可以被忽略,无论是对SNPs的二分类变异赋值,还是三分类变异赋值,只要纳入模型中,就转变成纯粹的数学问题。正是由于这种优势的存在,使得该方法对原始数据的类型容许程度很高,由此扩展了此种模型的使用范围。BNs模型计算的过程虽然复杂,但是结果解读起来却是十分的简单直观。只要将各个类别的概率直方图呈现出来,那所有重要的且有意义的高维度SNPs的整体效应,就能直观的展现出来。BNs模型一旦被建立起来,就可以被用来对新纳入的患者进行分类,其过程如下:输入新加入样本的SNPs的状况,并且将这些状况进行数学化处理即赋予其数据值,并带入模型开始运行。模型会通过新加入样本的SNPs的状况,根据概率理论,将其归入相应类别。
但是BNs模型的理论比较抽象,公式比较复杂,如果让医学工作者去理解其中的数学机制,可能不太现实,若再要求对模型进行深刻解释,则更困难。该模型在优化过程中的搜索算法也有硬伤,爬山算法从出现开始,就一直受到一定程度的诟病,因为其有使模型偏离到局部最优的倾向。
4 BP神经网络模型
BP(back propagation)神经网络在所有的神经网络模型系列中,是被使用最多的模型之一,其核心原理为按照误差逆传播算法,对所给数据集进行多层的正向的反馈拟合,而这些层则包括输入层(input layer)、隐层(hide layer)和输出层(output layer)。
BP神经网络模型对于已经给定的数据集的训练过程可以解释为:各种数据由输入层负责接收,并且向内层进行传递,传递过程中需经过一定的中间层级,信息在隐层部分进行计算处理,处理完毕后向输出层传递,输出层的神经元接收到后,即完成了一次完整的训练信息的传播,其结果由输出层向外面释放。如果输出的结果与期望值差距没有达到要求,则进入信息的反方向运动过程,将误差信息通过输出层、隐层、输入层的顺序反向传递。在上述正向和反向的两种信息传递过程中,为了使整个BP神经网络模型的误差的平方和达到最小,就需要对各个层级的权重和反应阈进行相应调整,在一定次数的迭代过程中达到符合设定的要求范围内[19]。
BP神经网络模型建立流程:①建立高通量SNPs足够而可靠的数据信息样本数据库。②把SNPs样本数据进行处理,变成BP神经网络模型可以纳入的形式。③建造BP神经网络初级雏形,进行数据训练。首先确定神经网络所需层的数量,还有隐藏节点的数量,接下来完成各连接权值的初始化过程,将样本数据代入。④开始BP神经网络的迭代过程,按照误差逆传播算法,对所给数据集进行多层的正向的反馈拟合,最终确定各个层的权重。⑤利用训练好的BP神经网络测试样本。将样本输入训练好的BP神经网络,并输出结果[20]。
非线性问题的解决能力是BP神经网络模型区别于其他的能够自我学习、自我训练的模型的特点之一,该模型以简单的结构模仿神经组织的构成和信号传导通路,根据提供的数据进行学习和自适应,最后可以对复杂的问题求解[21]。该模型的运行模式也很简单,一旦模型建立,则直接将数据带入,BP神经网络就可以对诸多影响因素和结果之间的复杂关系进行统计,超越传统聚类模型,也有能力提供更多的信息量[22]。
但是BP神经网络模型的缺陷也十分明显,首先该种聚类方法迭代次数比较多,计算收敛的速度比较慢;标准的BP神经网络算法各个层的权重值的确定是完全随机性的,容易形成局部最优化;在模型建立的初始阶段,各个节点的确定也没有确凿的理论支持[23]。
5 支持向量机
1995年Comes等[24]提出了一种新型机器学习方法,该方法的数学理论基础雄厚,被称之为SVM。这种方法问世之后,就以其在小样本、高维度数据方面处理的独特优势,被迅速推广到数据聚类分析领域的各个方面[25]。SVM的基本原理如下:利用非线性映射的方法φ(x):Rn→H,将待聚类数据集首先映射到高维空间H中,试图在高维空间中寻找最优化的一个超平面,此超平面的作用为对数据进行分类。达到最优超平面的要求为:对于数据来说,要求分类的间隔最大而且置信区间最窄;达到最少的数据样本错分数量,以上两条的原则为分类风险最低。
SVM的计算流程为:
在高维空间中,如果被映射数据具有二维线性且可分时,则一定存在一个分类超平面:

此超平面令样本均满足如下条件:

“支持向量”就是通过使(8)、(9)式等号同时成立的样本向量来命名。分类间隔用2/‖ω‖表示,如果欲使分类间隔最大,保证模型大范围推广,就要最小化‖ω‖2,此时拉格朗日方程被引入:
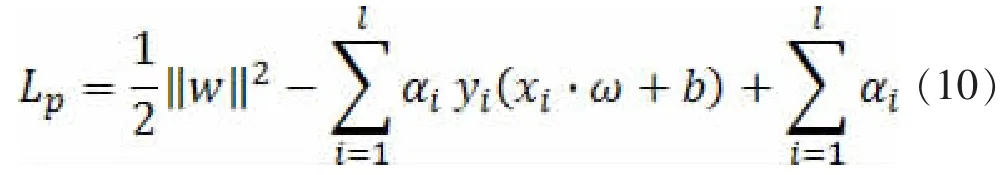
其中αi≥0称为拉格朗日系数,该函数对ω和b最小化,对αi最大化。将该问题转化为其对偶形式,求得最优分类函数为:

其中,K(x,xi)=φ(xi)·φ(xj)被称之为核函数,其作用是将原始数据集映射到高维H空间。而核函数有很多种形式,多项式形式、径向基形式等等。但是如果原始数据集经过转换后,确实为线性不可分时,方法会不可避免的产生错分点,此时非负松弛变量ξi≤1,i=1,…,l被引入,而式(8)、(9)合并为:

在上述条件下,求下式目标函数的最小值:

在式(13)中,用C来作为惩罚因子,对错分点来进行一定程度的惩罚,当然是人工定义的,其主要作用是在限制数据集偏差和该方法的推广范围两者间,维持一个平衡。
SVM模型作为一种经典的处理小样本的自我学习、自我组织的分类方法,虽然其基础理论依然与神经网络模型类似,均为通过对给定样本的统计学习,建造模型,而且对非线性数据的处理能力很强,但是很大程度上避免了陷入局部最优化,维度过高限制,拟合过度等缺陷,拥有更广阔的发展空间[26]。虽然该方法出现时间比较晚,但是研究者已经在包括预测人口状况[27]、婴儿死亡率前瞻[28]、金融产业[29]和工业产业[30]前景推断等方面进行了有效使用,当然也包括在高通量SNPs数据聚类,均取得了不错的效果。
但是SVM一样存在短处,由于其分类过程是基于对原始数据集的再次规划来寻找超平面,而再次规划的计算就有n阶矩阵(n为样本个数),如果n的数量很大,则电脑的内存将难以承受巨大的矩阵信息。而且原始的SVM模型只能对数据集进行二分类计算,有一定的局限性,由于在实际工作中,很多情况下分类数量要大于二,为了解决这个问题,只能去在其他方面想相应的解决方法。
6 讨论
不仅上述5种具体方法,而且在前文中所提出的几大种类中的具体聚类分析方法都各有其优缺点,研究者们已经针对上述几类聚类方法的缺陷进行了深入的研究,并提出了许多改进方法,提高了在高通量SNPs数据聚类分析时的计算效能。董国君等[31]提出了将仿生学算法中的退火算法引入到神经网络模型中,能够有效地避免该模型收敛到局部最优的状态。胡洁等[32]更是经过改进,建造了一种能够快速收敛而且全局最优的神经网络模型算法,将BP神经网络的计算效率大为提高。而Leo Breiman在2001年提出的随机森林(random forest)算法,本质上就是对分类回归树算法的一种组合改进,其计算原理为:利用多个树的模型对数据进行判别与分类,其在对数据进行处理的同时,还可以给出各个变量的重要性得分,评估变量在分类中所起的作用[33]。2012年提出了混合潜变量模型(structural equation mixture modeling,SEMM),本质上是一种结构方程模型衍生出的改进版,其设计思想中汇合了潜在类别分析、潜在剖面分析以及因子分析的因素,将潜变量分析与结构方程进行协调组合,创造出的一种新型SNPs分析方法。这种新的方法,将结构方程的缺点——只能分析连续潜变量和潜在类别分析的缺点——只能分析分类潜变量,进行有效的补充,而且把一种全新的探索式的思路引入了高维数据分析的领域。在实际进行聚类分析时,也可以将几种方法结合使用,分别在计算的不同阶段利用效能最高的方法,做到优势互补。现已经出现基于神经网络算法和蚁群算法进行结合使用的报道。
尽管用于高通量SNPs数据聚类分析的方法有多种,但目前没有任何一种方法可以适用于所有的情况。因此,研究者们依旧没有停下寻找更为合适的方法的脚步。不可否认,在基因组相关研究中,SNPs数据的分析对于研究复杂性疾病和遗传因素的联系是一项挑战,但也是机遇。如果能正确合理地运用各种复杂的统计学方法,就可以提高聚类分析的效能,提示研究者们未来应在寻找更适用的高通量SNPs数据聚类分析方法方面付出更多努力。
[1]Jakobsson M,Scholz SW,Scheet P,et al.Genotype,haplotype and copy-number variation in worldwide human population[J].Nature,2012,451:998-1003.
[2]马靖,张韶凯,张岩波.基于贝叶斯网潜类模型的高维SNPs分析[J].生物信息学,2012,10(2):120-124.
[3]张家宝.聚类分析在医院设备管理中应用研究[J].中国农村卫生事业管理,2014,34(5):510-513.
[4]袁芳,刘盼盼,徐进,等.基因-基因(环境)交互作用分析方法的比较[J].宁波大学学报:理工版,2012,25(4):115-119.
[5]张洁婷,焦璨,张敏强.潜在类别分析技术在心理学研究中的应用[J].心理科学进展,2011,18(12):1991-1998.
[6]曾宪华,肖琳,张岩波.潜在类别分析原理及实例分析[J].中国卫生统计,2013,30(6):815-817.
[7]Kaufman L,Rousseeuw PJ.Finding groups in data:an introduction to cluster analysis[M].New York:Wiley,2015.
[8]Hagenaars JA.McCutcheon AL.Applied latent class analysis[M].New York:Cambridge University Press,2012.
[9]邱皓政.潜在类别模型的原理与技术[M].北京:教育科学出版社,2011.
[10]张岩波.潜变量分析[M].北京:高等教育出版社,2011.
[11]Lin TH,Dayton CM.Model selection information criteria for non-nested latent class models[J].J Educ Behav Stat,2012,22(3):249-264.
[12]裴磊磊,郭小玲,张岩波,等.抑郁症患者单核苷酸多态性(SNPs)分布特征的潜在类别分析[J].中国卫生统计,2010,27(1):7-10.
[13]邵峰晶,于忠清.数据挖掘原理与算法[M].北京:中国水利水电出版社,2013.
[14]王立柱,赵大宇.用分类与回归树算法进行人才识别[J].沈阳师范大学学报:自然科学版,2014,23(1):44-47.
[15]温小霓,蔡汝骏.分类与回归树及其应用研究[J].统计与决策,2010,(23):14-16
[16]符保龙,陈如云.分类回归树在高校计算机联考数据分析中的应用[J].计算机时代,2011,(1):33-34.
[17]Dempster AP,Laird NM,Rubin DB.Maximum likelihood from incomplete data via the Em algorithm(with discussion)[J].J Royal Stat,2012,39(1):1-38.
[18]José A,Gámez,Juan L,et al.Learning Bayesian networks by hill climbing:efficient methods based on progressive restriction of the neighborhood[J].Data Min Knowl Disc,2012,22:106-148.
[19]张凡,齐平,倪春梅.基于POS的BP神经网络在腮腺炎发病率预测中的应用[J].现代预防医学,2014,41(11):1924-1927.
[20]张晶.BP神经网络在图书馆信息处理中的应用研究[J].图书情报,2014,(9):132-133.
[21]徐学琴,孙宁,徐玉芳.基于BP神经网络的河南省甲乙类法定报告传染病预测研究[J].中华疾病控制杂志,2014,18(6):561-563.
[22]马晓梅,隋美丽,段广才,等.手足口病重症化危险因素BP神经网络模型预测分析[J].中国公共卫生,2014,30(6):758-761.
[23]任方,马尚才.基于条件对数似然的BP神经网络多类分类器[J].计算机系统应用,2014,23(6):183-186.
[24]Comes C,Vapnik V.Support vector networks[J].Mach Learn,1995,20:273-297.
[25]张学工.关于统计学习理论与支持向量机[J].自动化学报,2011,26(1):32-42.
[26]解合川,任钦,曾海燕,等.支持向量机在传染病发病率预测中的应用[J].现代预防医学,2012,40(22):4105-4112.
[27]刘崇林.人口时间序列的支持向量机预测模型[J].宁夏大学学报:自然科学版,2013,27(4):308-310.
[28]张俊辉,潘晓平,潘惊萍,等.基于支持向量回归的5岁以下儿童死亡率预测模型[J].现代预防医学,2014,36(24):4601-4603,4605.
[29]陈诗一.非参数支持向量回归和分类理论及其在金融市场预测中的应用[M].北京:北京大学出版社,2014:104-106.
[30]Li P,Tan ZX,Yan LL,et al.Time series prediction of mining subsidence based on a SVM[J].Min Science Technol,2014,21(4):557-562.
[31]董国君,哈力木拉提.基于随机退火的神经网络算法及其应用[J].计算机工程与应用,2013,46(19):39-42.
[32]胡洁,曾祥金.一种快速且全局收敛的BP神经网络学习算法[J].系统科学与数学,2014,30(5):604-610.
[33]武晓岩,李康.随机森林方法在基因表达数据分析中的应用及研究进展[J].中国卫生统计,2014,26(4):437-440.
Contrasting the methods of data clustering analysis of single nucleotide polymorphisms
JIANG Longxun1,2ZHANG Ling1▲
1.School of Public Health,Capital Medical University,Beijing100069,China;2.Fengtai District Nanyuan Community Health Service Center of Beijing City,Beijing100076,China
Statistical methods currently used for single nucleotide polymorphisms(SNPs)data cluster analysis are explained,and select five kinds of representative statistical methods,make specific analysis to each method separately.In the discussion process for each method,all divided into 5 parts:principle of the method,calculation methods,formulas,advantages and defects.In the discussion section of the article,all the methods are summarized,and propose future development direction of the cluster method for SNPs data.
Single nucleotide polymorphisms;Cluster analysis;Gene;Data mining
R181.2+3
A
1673-7210(2015)09(a)-0036-06
2015-04-01本文编辑:程铭)



