王元清,王 兢,朱 波,陈 燕,徐凌洋,王泽昭,张路培,高会江,李俊雅,高 雪
(中国农业科学院北京畜牧兽医研究所,北京 100193)
动物育种工作的核心任务在于选种和选配,即选择具有突出性状的亲本,通过人为确定个体或群体间的交配系统,有计划地选择公母畜配对,以期获得理想型的后代或群体。在早期的育种工作中,人们往往利用观察到的表型值和亲缘关系进行选种选配,也就是表型选择(phenotypic selection,PS)。PS主要分为同质选配和异质选配,即优秀公母畜交配和优秀公畜与相对较差母畜交配[1-2]。这两种选配方法虽然有概率产生优秀个体或对表型值较差个体的后代进行改良,但会导致群体中纯合子的频率增加,杂合子频率降低,进而使群体快速达到纯和状态。20世纪后期,随着遗传学和统计学的不断发展,最佳线性无偏预估(best linear unbiased prediction,BLUP)方法被提出,育种者们开始利用BLUP方法估计育种值(estimated breeding value,EBV)[3],并在此基础上进行选配。1985年,Jansen和Wilton[4]首次将线性规划方法(linear program, LP)加入育种工作中,将选配问题转化为数学模型。即利用系谱信息,在线性方程或线性不等式的约束之下,对所有可能的选配个体进行后代期望育种值的计算,构建目标函数求最优解[5]。它采用同时求解的方式,而不是顺序求解从而避免存在相关。Weigel和Lin[6]利用LP和系谱信息在荷斯坦牛和娟珊牛群体中进行选种选配,选配方案采用了最小近交,且将近交水平分别控制在5%和8%,后代群体近交水平分别减少了1.8%和2.8%,而利润分别增加了37.37和59.77美元·头-1。1994年,Woolliams和Thomas[7]及Lindgren和Matheson[8]提出了遗传贡献理论,其理论认为当亲本个体实际的孟德尔抽样与其对后代群体的遗传贡献之间存在一定的线性关系时,在对亲本间的亲缘关系进行约束的情况下,可以最大化后代群体的遗传进展。基于此理论,1996年之后,包括Caballero等[9]、Meuwissen[10]和Wodliams等[11]提出最小共祖选配(minimum-coancestry mating,MC)和最小化祖先间遗传贡献的协方差(minimizing the covariance between ancestral genetic contributions,MCAC)两种选配方法。这两种选配方法主要使用系谱和表型信息,常用于没有基因组信息的育种计划中[12-13]。1997年,Meuwissen[14]基于遗传贡献理论还提出了一种非线性规划方法,最佳遗传贡献选择法(optimal contribution selection, OCS)。此方法以系谱信息为基础,通过亲本加权遗传价值的最大化来优化每个候选个体对下一代的遗传贡献来控制近亲交配,尽可能获得最大的遗传进展[15-17]。Srensen等[18]在丹麦荷斯坦奶牛中评估了OCS的使用效果,当使用OCS进行选配时,平均加性遗传关系可以从0.162 1减少到0.149 5。这说明OCS对于降低近交水平有所帮助,但前提要保证系谱信息的准确性。利用系谱信息的LP、OCS等方法,虽然能够加快遗传进展,减缓近交水平的上升,但由于系谱资料不能提供亲本实际的孟德尔抽样以及系谱信息记录的错误等问题,选配的效果并不是很理想。
自聚合酶链式反应的发明以及高通量基因分型技术的改进后,又有研究者提出了分子标记辅助选择(marker assisted selection,MAS),即利用与目标性状相关的分子标记进行选种选配,成为一种省时高效的育种策略,快速提高了选育的遗传进展(ΔG)[19]。之后,随着越来越多的基因组信息被挖掘和应用,国内外研究者们也开始使用基因组信息进行选配方法的优化。Liu等[20]利用系谱和基因组信息,使用随机模拟比较了MC和MCAC两种交配策略在5种育种方案中的近交增量和遗传进展。研究表明,当使用基于基因组信息的MC和MCAC交配策略时,预期的近交增量比利用系谱信息降低了6%~22%,而预期遗传进展并没有降低;并且与随机交配对照方案相比,这两种方案的近交增量降低了28%~44%,遗传进展提高了14%。2012年,Sonesson等[21]在OCS中利用基因组关系矩阵G来代替基于系谱信息的加性关系矩阵A来优化选配,这种方法被称为基因组最佳遗传贡献选择(genomic optimal contribution selection, GOCS)。利用G矩阵计算可以避免系谱的错误或者缺失,以及计算A矩阵时忽略了久远的世代所造成的偏差等问题[22-24]。但是GOCS不能直接控制与目标性状相关的近交增量组分,因此无法达到遗传进展和近交控制之间的最佳平衡。与此同时,全基因组选择(genomic selection,GS)这一策略被提出[25-30],即通过覆盖全基因组范围内的高密度标记估计基因组育种值(genomic estimated breeding value,GEBV),继而进行排序、选择。然而这种基于GEBV的截断式选择,虽然能降低孟德尔抽样误差,大幅度缩短世代间隔,显着提高ΔG,但通常GEBV高的个体间亲缘关系相关性也较高,同时被选留种的可能性较大,这会导致育种核心群近交水平(ΔF)的迅速上升和遗传方差的降低,甚至产生近交衰退,尤其在群体基数较小或繁殖力高的群体中表现尤为突出[31-36]。2016年,Akdemir和Snchez[37]提出了基因组选配(genomic mating, GM)的概念,相较于传统的选配方法,基因组选配利用基因组信息来追踪染色体片段的遗传,从而提高对亲本孟德尔抽样估计的准确性及其与亲本遗传贡献的关系,它将问题的焦点转移到交配上,更有助于实现高效育种的目标。本文综述了基因组选配的概念、原理与方法以及在畜禽育种中的研究进展,为推动畜禽育种的长期可持续发展提供参考。
1 基因组选配
1.1 基因组选配的概念
基因组选配是利用基因组估计育种值、风险指数(有效性)、交配亲本互补信息等概念来优化配对,通过改进后的遗传算法求得最优解,并且在三维有效前沿面(efficient frontier surface,EFS)中确定最优的交配组合[38-39]。如图1所示,不管是PS或是GS都没有给出选留后的个体如何配对,因此需要进一步制定选配计划来获得最佳的交配组合。而基因组选配在估计标记效应和基因组育种值的同时,利用估计的标记效应来决定哪些基因型应该杂交以获得性能更佳的群体[40]。与基因组选择不同的是,基因组选配是从候选的育种群体里直接选择最优的交配组合,而不是基于GEBV进行截断选择。它将配对双亲之间的互补信息考虑在内,寻求亲本对后代的遗传贡献比例,更加全面的利用了基因组信息。通过对表型选择、基因组选择和基因组选配的模拟研究,表明基因组选配在复杂性状的改良上比表型选择和基因组选择有更大的优势[41-47]。因此,使用GM代替GS能够实现高效的遗传增益,提高遗传多样性,避免有害基因纯和,保留一些稀有基因,从而实现长期可持续的遗传进展。
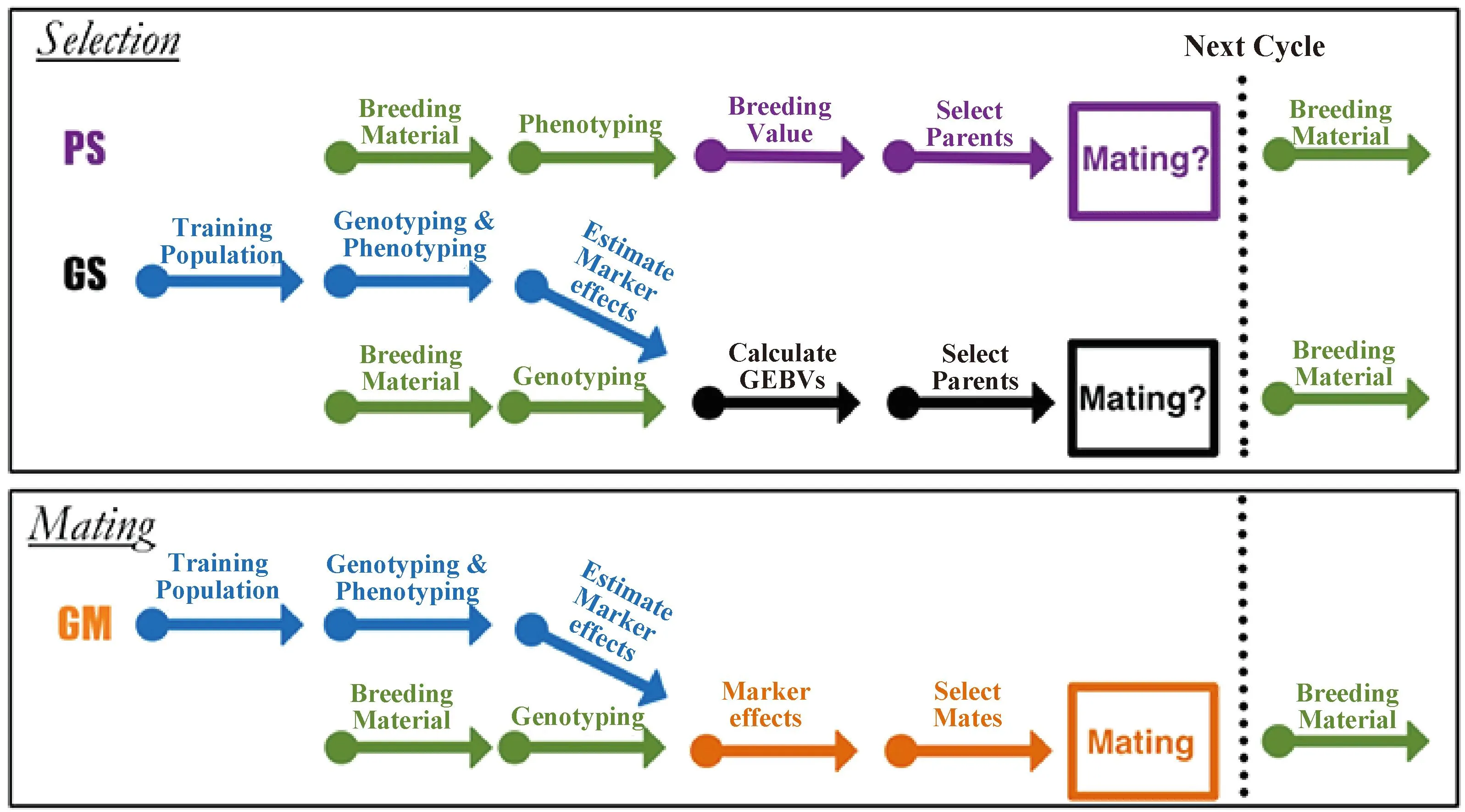
图1 不同育种途径示意图[37]Fig.1 Diagram for the different breeding approaches[37]
1.2 基因组选配的原理与方法
Minimizer(λ1,λ2,P)= —Risk(λ1,P)+ λ2*Inbreeding(P)。
式中,λ2≥ 0,是控制子代中近交程度的参数;P为最小化配种矩阵;λ1是控制等位基因杂合度的参数,此处的杂合度是按照标记效应加权的杂合度;λ2是控制等位基因多样性的参数。当λ1=0时,风险估计与预期进展相同,即只考虑子代的期望育种值。当λ1>0时,后代中预期方差较高的配对在相同期望育种值的配对中具有更高的风险值。当其余条件不变时,这些预期方差高的配对具有产生高育种值后代的潜能,但由于分布是围绕着平均值对称的,相同的配对也有产生低育种值后代的可能性。所以,将其命名为“风险指数”。
在GM的目标函数中只需要考虑遗传进展和近交系数来优化选配,其中近交、遗传进展、家系间方差、风险指数的计算公式如下:
Var(b)=PGP′+D;
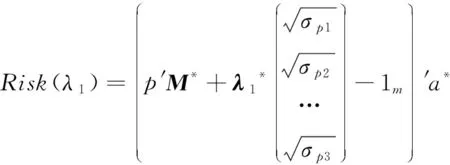
基因组选配也可以表示为以下二次优化的形式:
约束条件R(P,λ1)=ρ。
式中,P为Nc×N的交配矩阵,其中N为亲本的数量,Nc为后代的数量;G为基因组关系矩阵;D为孟德尔抽样离差;M为基因型矩阵;a为标记效应;σp为有益等位基因数量的方差。
通过GM方法求得最优解后,可以在一个三维有效面(EFS)中确定最优的交配组合,如图2所示。曲线上的点是风险值、近交和风险与遗传进展之差的值,其中,蓝色面表示目标函数的最优解,沿着曲面的点是平衡进展、风险值和近亲交配的最优点,该表面之下的点对应次优解区域。绿色面是后代的平均期望遗传进展,橙色面是交叉方差的值,绿色和橙色两个表面加起来就是蓝色面。通过改变λ1和λ2的值,选配的最优解在这个表面上移动。
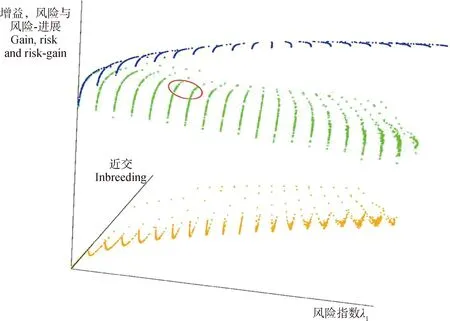
图2 模拟群体的三维边界曲面[37]Fig.2 Frontier surface for a simulated population[37]
通过三维边界曲面,育种者可以了解到交配计划的预期风险如何随近交水平而变化。对于给定的风险值,育种者可以选择能够接受的近交水平,从图2可以看出,随着λ1的增加,风险值以平滑的方式增加,同时对应的增益以不均匀的速率下降,因此,风险值和增益之间的差异以不均匀的速度增加。如图2红色椭圆标记所示,确定一个合理的λ1和λ2的组合可以将最优解定位在增益随着λ2的增加而缓慢增长,随着λ1的增加而加速下降的点附近。在获得一定遗传进展的情况下,采用GM最优算法,可以增加交叉方差、减少近交系数,取得更高的加性方差,提高预期收益。
当λ1的值确定时,蓝色面将变成一个二维切面,如图3所示。其中每一个点都对应着两个指标下的一组交配组合,在没有限定条件时,曲面上的每一个点都可以作为获得下一代群体的交配方案。图3中可以看出遗传进展随着近交水平的变化趋势,育种者可以根据边界曲面选择符合预期的最优解。从长远来看,利用GM方法进行选配能够获得长期可持续的遗传增益。
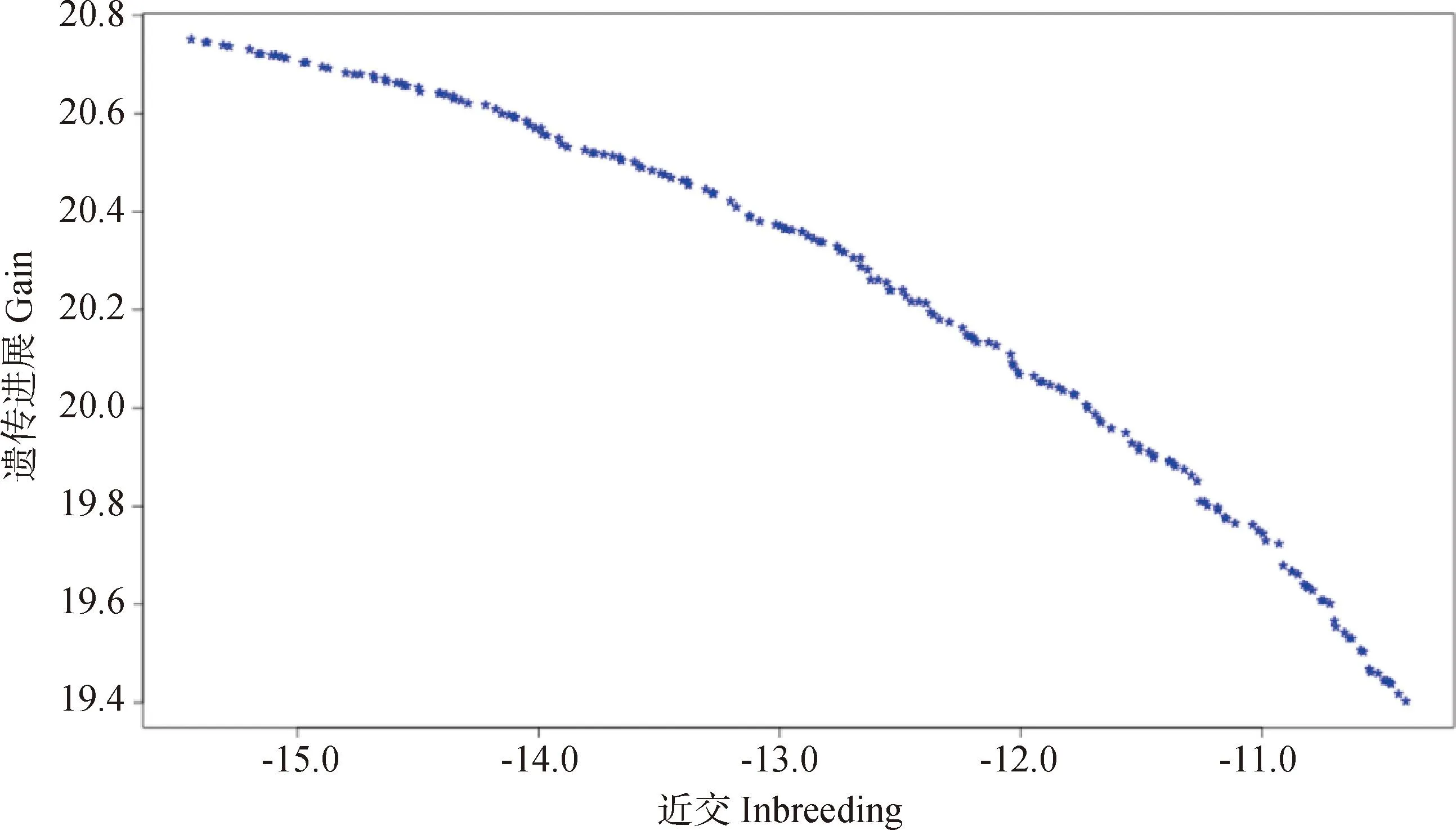
图3 基因组选配得到的最优解[59]Fig.3 The optimal solution of genomic mating[59]
2 基因组选配在畜禽育种中的应用
目前已有多项研究表明,利用基因组信息进行选配比利用系谱信息具有更大的优势,使用基因组选配可以增加后代遗传的多样性和在快速提高后代遗传进展的同时有效的控制近交水平,达到高效育种的目标。
2.1 加性效应的基因组信息优化选配应用
Clark等[48]利用模拟数据和真实数据,将基因组信息加入到奶牛的OCS中,结果表明,对GEBV的优化选择提高了估计的准确性和保留了更多群体内的变异,在控制近交率的情况下,使用基因组信息代替传统的系谱信息能够提高16%的遗传进展。Pryce等[49]利用系谱、基因组和长纯和片段(runs of homozygosity, ROH)信息的3种交配方案,对荷斯坦奶牛群体选配后代的预期遗传进展、近交水平以及纯和有害基因等的变化进行比较。结果表明,使用基因组信息能够大幅度降低后代的期望近交系数,在获得相同遗传进展的情况下,利用基因组信息比系谱信息使后代的期望近交程度降低了几乎两倍。Carthy等[50]使用奶牛的模拟数据,对随机交配、顺序选择和线性规划3种利用基因组信息优化选配的方法进行了比较。结果表明,在构建的指数框架控制下,利用基因组信息结合线性规划的方法来优化选配,后代群体中的近交水平降低了18%,而且降低了目标性状遗传进展在后代中的变异率。Henryon等[51]利用模拟数据比较了采用BLUP选择后使用MC、MCAC以及随机交配3种方法的效果。结果表明,使用MCAC方法产生的近亲繁殖比MC少4%~8%,同时遗传进展没有减少。与随机交配相比,近亲繁殖减少了28%,遗传进展增加了约3%。这表明在MC和MCAC的策略中加入基因组信息能够更好地控制近亲繁殖,也意味着基因组信息不仅仅是用来预测育种方案中的育种值,更可以应用于基因组选配。He等[52]对湖南省地方品种宁乡猪进行了GOCS和没有近交控制的GS两种交配策略。结果表明,在前几代采用GS获得的遗传进展要大于GCOS策略,但是在之后的几代中,GS和GCOS的差异迅速减小,甚至最终使用GOCS的后代群体遗传增益略高。同时GOCS的近交率在每个子代基本保持在5%以内,而GS每代的近交率高达10.5%~15.3%。除了将基因组信息加入到LP、OCS等方法中,探究后代收益提高的幅度,还有些学者也尝试将基因组信息整合到以往应用系谱信息选配的计算机程序中。Schierenbeck等[53]开发了一个计算机程序,该程序利用系谱和基因组关系的半确定规划(semi-definite programming,SDP),从而控制近交水平和最大化遗传进展,与之前使用GENCONT软件和其它基于系谱关系的应用程序相比,其专注于SDP和SNP数据构建的关系。对于中低遗传力性状,利用此程序可在约束最大亲缘关系条件下,获得遗传增益最大化的配对。Bérodier等[54]比较了3种交配策略(随机交配、顺序交配、线性规划)在蒙贝利亚牛群体中的差异,同时研究了仅使用母牛基因组信息的选配方案和同时使用公、母牛基因组信息的等效策略的选配效果。结果表明,不论是加入母牛还是公母牛基因组信息,都比单纯使用系谱信息更有效地最大化遗传效益。且利用线性规划方法能够较好的控制对后代预期近交水平和致死隐形基因纯和风险。Bengtsson等[55]在北欧红牛群体中利用线性规划的方法整合基因组信息,同时考虑遗传水平、精液成本、隐性遗传缺陷的经济影响,建立了最优选配方案。与前人不同的是,该研究将重点放在线性规划和不同的经济得分上,而不是比较不同的选配方法。结果表明,使用线性规划方法不仅能够在对遗传水平影响较小的情况下,减少亲本间的遗传差异关系,消除了隐性遗传缺陷表达的成本,同时控制群体的近交水平。除此之外,还有些对于基因组选配算法优化的探索。Ganteil等[56]探究了在新的合成猪系的前几代进行多样性管理以及在不同时间点开始选择的效果。该研究使用来自新系第一代(G0)猪的基因组和表型数据,进行了不同选择方案的模拟来评估在新系的前几代进行多样性管理的效果,并测试了在G3和G4两个不同时间点开始选择的影响。结果表明,利用基因组数据从G4开始选择同时结合多样性控制的管理策略能够产生较大的遗传进展并保持多样性。Tang等[57]提出了一种猪的基因组选配新方法,并且首次应用到三元商品猪的实际生产中,该研究使用 875 头纯种杜洛克公猪、350头长大二元母猪和 3 573 头杜长大三元商品猪的基因型和表型数据进行基因组选配分析。该研究提出一种快速估计标记效应的算法,其构建了一个V矩阵,无需求解MME方程来获得先验育种值,无论模型中包含多少随机效应,V矩阵的维数都保持不变。该算法能够在不损失计算精度的条件下大幅降低计算复杂度,尤其适用于加性、显性等遗传效应的多随机效应模型计算。与随机交配相比,使用基因组选配方案所产生的后代,其料重比下降了0.12、眼肌面积增加2.65 cm2、30~120 kg测定日龄缩短4.64 d。该方法为畜禽利用基因组信息进行选配提供了新思路。
而对于最新的GM方法,相关研究还较少。张鹏飞等[58]利用大白猪的模拟数据,在通过GS选留后使用了基因组选配、同质选配、异质选配、随机交配4种不同的选配方案。在基因组选配中,选择了遗传进展最大、家系间方差最大和近交最小的解进行选育。结果显示,3种基因组选配方案的遗传进展显着高于随机交配和异质选配。其中,选择遗传进展最大的基因组选配方案的遗传进展比同质选配高出4.3%,3种基因组选配方案的近交率比同质选配低22.2%~94.1%,而遗传方差却比同质选配高出10.8%~32.2%。这表明GM不仅可以获得比同质选配更高的遗传进展,同时有效的降低了近交水平,并且减缓了遗传方差降低的速度。Zhao等[59]基于猪的遗传背景,模拟了3种不同遗传力(0.1、0.3、0.5)性状下9 000头纯种猪的基础群数据,分别使用G矩阵和ROH亲缘关系矩阵构建了基因组选配方案,同时与随机交配、同质选配、异质选配3种常规选配方案进行了比较,评估了基因组选配的效果,并且在大白猪的真实数据集上做了验证。结果表明,在使用ROH亲缘关系矩阵选择最大遗传进展方案时,无论遗传力高或低,都比同质选配后代的遗传增益提高了0.9%~8.9%,近交率降低了13%~83.3%。与传统的选配方式相比,GM不仅可以实现可持续的遗传进展,而且可以有效的控制种群近交率。
2.2 非加性效应的基因组信息优化选配应用
利用基因组信息选配时,一般只考虑了加性遗传效应,而没有考虑非加性效应,但这一部分也携带着十分重要的遗传信息。Sun等[60]提出了一种基于基因组关系和显性效应的选配优化模型,结果表明,荷斯坦奶牛的产奶量增加了64%,娟珊牛的产奶量增加了73%,且使用基因组信息比使用谱系信息可以进一步降低预期后代的近交程度,从而获得更高的遗传进展。Gonzlez-Diéguez等[61]利用基因组信息将非加性遗传效应加入到线性规划交配策略中。结果表明,整合了非加性遗传效应的基因组选配方案,对达100 kg体重日龄、背膘厚度、仔猪平均初生重三个指标均有所提升,分别为缩短0.79 d、减少0.04 mm和增加11.3 g。李佳芮[62]利用生猪的真实数据,整合了非加性效应对生猪基因组选配进行优化,在遗传评估时纳入近交作为协变量,分别使用加性效应的G模型和加性显性效应的GD模型,利用同质选配和线性规划两种方法进行选配。结果表明,两种选配策略在整合显性效应时均优于仅考虑加性效应的选配方式。但由于这种选配方式要求对所有待配公母畜进行基因分型,所需成本过高,目前还很难用于实际生产。Aliloo等[63]提出了将非加性效应(显性和杂合性)纳入基于基因组信息交配方案中。结果表明,采取非加性效应(显性和杂合性)的模型优于仅使用加性效应的方案,而且使用非加性效应的交配方案明显改善了产奶量、乳脂肪以及乳蛋白质的含量,分别增加了38、1.57和1.21 kg。与随机交配相比,加入非加性遗传效应(显性和杂合性)的交配方案使产犊间隔缩短了0.70 d。同时与随机交配相比,在产犊间隔和生产性状上,使用非加性遗传效应模型得到的后代近交幅度分别减少0.25%~1.57%和0.64%~1.57%。随着这种近交幅度的降低,每次交配能增加8.42 澳元的平均利润。但是,使用非加性遗传效应的交配方案只能在实施的那一代提高后代表现,并且一些特定组合产生的增益不会累积,需要不断地调整选配方案,才能长期受益于非加性遗传效应。
3 结语和展望
基因组选配比以往的方法考虑了更多的因素,以期实现育种过程中最佳的配对组合。与GOCS、LP等方法相比,GM可以根据标记效应,给出一个精确的选配组合列表用于获得后代育种种群。同时与GS相比,基因组选配不仅将配对亲本间的互补关系考虑了进去,并且还包括品种特征、近交水平、种群基因频率,这为近交率较高、群体样本数较少的物种改良提供了理论基础。但是基因组选配是一个十分复杂的问题,除了自身的遗传特性,也要考虑到配对个体间的遗传信息和互补情况。基因组选配的研究目前大都在牛、猪、羊等大动物中展开,而在禽类育种中,由于群体规模大、世代间隔短,更新快,选配在禽领域几乎没有开展相关研究。同时目前的研究大多考虑了单性状的加性遗传效应,对于非加性遗传效应以及其他生物学先验信息考虑的较少,未来这将是一个比较重要的研究方向。此外,当前的基因组选配研究仍处于计算机模拟阶段,采取实际数据进行研究应用的较少,而且对于算力的要求较高,如何将基因组选配的算法进一步优化,以及将基因组选配应用于生产的遗传改良,也是一个需要继续探讨的话题。



