党志慧
(国网朔州供电公司)
0 引言
电力用电负荷对电力企业经营发展以及战略制定有着极大的影响,随着经济不断发展、产业结构改革,导致电力负荷用户数量快速增加,再加上企业升级转型,用户用电负荷不断变化,在一定程度上影响了电网稳定运行。对此,制定一套完善、有效、精准的用户电力负荷自动预测系统尤为重要。目前,国内外针对用户用电负荷预测的研究成果有很多,很多专家学者也提出了相应的解决方案。例如,Attention-GRU预测模型实现了用户用电短期负荷预测方案,该方案预测效率高,但精度有待进一步提升;结合数据挖掘、支持向量机提出一种用电负荷预测平台,该平台通过训练历史负荷序列得到训练集,极大地提升了用户用电负荷预测精度,但预测效率明显降低。针对这些情况,本文提出一种基于序列理论的电网用户用电负荷预测系统,旨在同时保证电网用户用电负荷预测的效率和精度。
1 系统整体方案
用电负荷是指电网用户所使用的用电设备在某个阶段向供电系统所获取的电力功率总量。本文所提出的基于序列理论的电网用户用电负荷自动预测系统,其运行原理是通过明确的用户用电负荷历史数据信息,掌握用户用电负荷变化规律,从而描述未来一段时间内该用户用电负荷的规律变化,并构建时间序列模型,实现用户用电负荷的精准预测[1]。基于序列理论的电网用户用电负荷自动预测系统主要包括三个方面:一是电网用户历史用电负荷数据预处理,二是用电负荷序列分解,三是构建预测模型。
2 系统设计
2.1 用户历史用电负荷数据预处理
本设计是以用户历史用电负荷数据作为自动预测系统的基础,以用户历史用电负荷数据建立模型,从而预测未来用电负荷。因此,为了保证预测模型的质量,就必须要确保历史用电负荷数据的精度,这就需要做好用户历史用电负荷数据的预处理工作。预处理流程为:
(1)采集用户历史用电负荷数据、用户历史用电费用。
(2)数据集成、归纳。
(3)数据清洗,将异常值、重复值剔除,填补缺失的数据信息。
(4)数据归一化,在历史用电负荷数据样本X中找出最大值Xmax和最小值Xmin。
(5)验证。
(6)高质量历史用电负荷数据输出。
将用户历史用电负荷数据进行预处理后,可以得到更加规范、更高质量的历史用电负荷数据信息,将预处理之后的数据传输到预测模型中,从而得到更加精准的预测值。
2.2 用电负荷序列分解
按照时间序列分布用户历史用电负荷数据,得到用电负荷时间序列。由于该序列波动性强,且带有周期性特点,如果直接应用则无法被预测模型识别,这就需要二次分解该序列,再进行预测模型的识别。
用电负荷时间序列可采用经验模式分解法进行分解,将用电负荷时间序列分解成多个高频分量和一个低频分量,并从中提取用电负荷时变特性,以便于后期应用在预测模型中[2]。经验模式分解法的应用流程为:
(1)从用电负荷时间序列中选出极小值、极大值两组数据。
(2)采用三次样条函数拟合用电负荷时间序列中的极大值数据、极小值数据,得出序列当中的上包络线、下包络线。
(3)计算上包络线、下包络线的均值。
(4)计算首位用户历史用电负荷序列的首个分量。
(5)判断用户历史用电负荷首个分量是否是用电负荷时间序列当中的首个内涵模态分量(Intrinsic Mode Function,IMF)。判定方法为:①局部极值点与过零点差距不超过1;②任何点位上的上、下包络线均值都等于0。
(6)同时满足(5)中2个条件的用户历史用电负荷首个分量作为第一个IFM,否则重新从流程(1)开始,并重复上述条件,直到可以满足(5)中2个条件为止。
(7)记录满足上述条件的用户历史用电负荷首个分量。
(8)用用电负荷时间序列减去(7)的首个分量,得到剔除掉高频的剩余分量。
(9)重复上述所有过程n次,每次将上一步所得出的剩余分量作为原始数据,直到得到第2个IFM、第3个IFM…第n个IFM。
(10)判断是否得到最终所需的终止条件,也就是要求n个剩余分量为单调函数。一旦满足条件,则停止用电负荷时间序列分解,从高到低将用电负荷时间序列分为不同频段。
通过上述十个步骤得出分解后的用电负荷时间序列,相比原始用电负荷时间序列更具规律性以及线性,有助于提高后期用户用电负荷预测精度。
2.3 基于时间序列模型的用电负荷预测
结合时间序列理论,选择相对应的模型,并在模型中输入分解后的用电负荷时间序列,即可得出未来某个时间段、时间点的用户用电负荷量,即未来预测值。本文所选用的预测模型为基于ARMAX搭建的预测模型,该模型是多输入、单输出的系统,用户历史用电负荷为输入量,用户未来用电负荷为输出量。基于ARMAX建立的未来用电负荷预测模型中主要参数包括:某个时间段用户对电力需求的数值、残差、滞后算子、常数项、负荷量、负荷平方的滞后阶次、待估计参数[3]。其主要应用过程如下:
(1)设定用户用电的假设条件,在预测模型中设定残差序列、参数。
(2)结合已经分解得出的某个时间点的用户历史用电负荷参数、电力续期参数,确定负荷平方的滞后阶次的初始值。通过自相关函数、偏自相关函数确定负荷值、残差值;通过回归系数显着分析确定负荷值、负荷平方滞后阶次。
(3)采用最大拟然法估计各个参数值。
(4)校验上述(2)和(3)所估计得出的参数、残差序列,根据最终校验结果判定该预测模型是否符合本次设计条件,确认符合设计条件即可直接应用于未来用户用电负荷预测工作。
3 系统应用效果仿真分析
为了测试本次设计的用户未来用电负荷自动预测系统的实际使用效果,对本系统进行了应用效果仿真分析。仿真平台采用MATLAB,为了让仿真测试结果更加直观,本次仿真设计采用了其他预测平台进行对比,包括Attention-GRU预测平台、数据挖掘与支持向量机的预测平台、NW-FLNN预测平台[4]。
3.1 用户历史用电负荷数据来源
本次仿真测试从PJM电力市场获取用户历史用电负荷数据,用电负荷采集频率为1次/h,数据集为2020年整个8月份,共计采集了720h(1~30日)、得到720个数据,并将这720个用户用电负荷数据作为历史数据,根据1~30日的用户历史用电负荷数据预测31日用户用电负荷量。
3.2 用户历史用电负荷序列分解
采用上文提到的经验模式分解法对1~30日用电负荷序列进行分解,其结果如图所示。
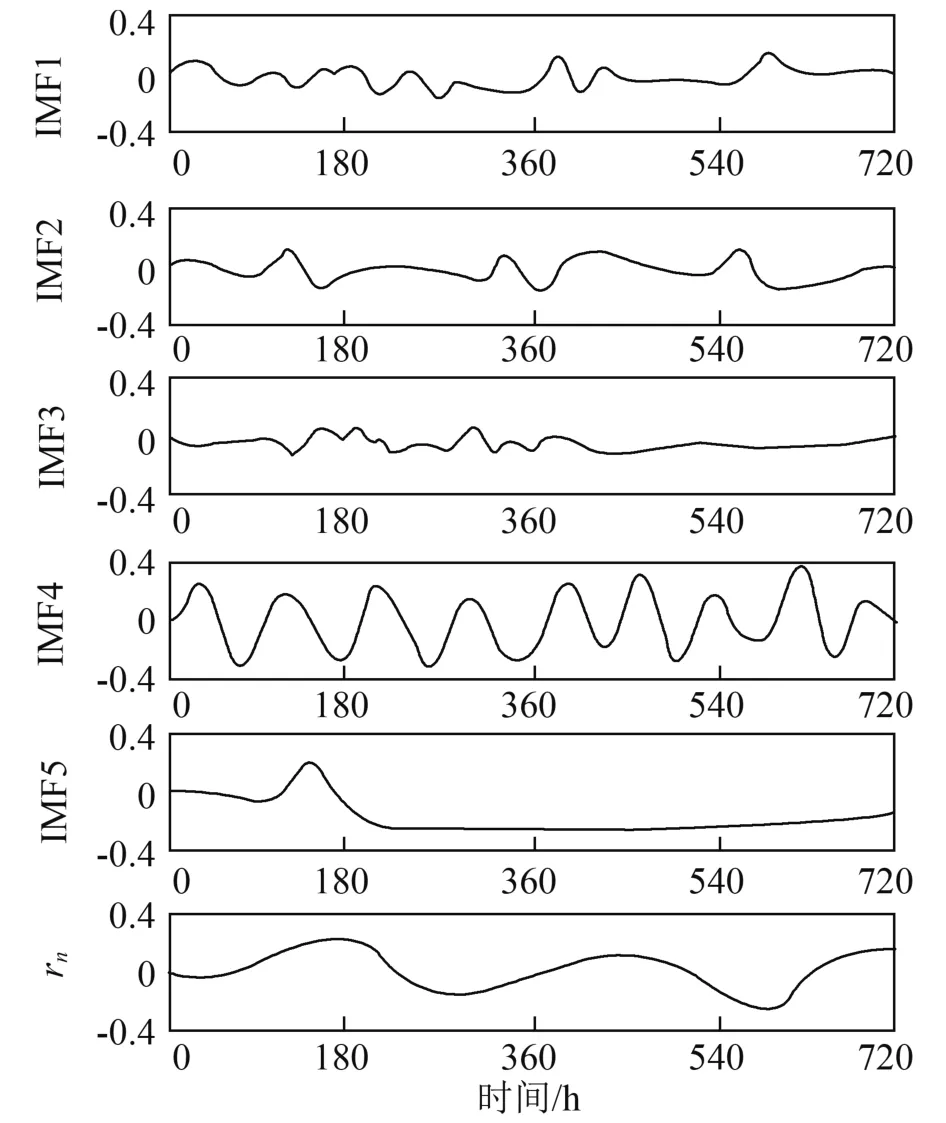
图 负荷序列分解结果
3.3 设置模型参数
通过回归系数显着性分析获取基于ARMAX的用户未来用电负荷预测模型参数,并对预测模型参数进行校验,校验合格之后将用户历史用电负荷数据出入到预测模型当中,得出最终该模型输出的用户未来用电负荷的预测值。
3.4 评价指标
本次设计的用户用电负荷自动预测系统主要有两大核心评价指标,即平均绝对误差值、平均绝对百分比误差值。
3.5 预测结果
本次仿真测试以2020年8月1~30日的用户用电负荷数据作为历史值,通过预测模型对当月的31日进行用户用电负荷预测,通过将31日真实值与预测模型输出的预测值进行对比分析,从而判定本次电网用户用电负荷自动预测系统是否满足使用标准[5]。最终预测结果见下表。
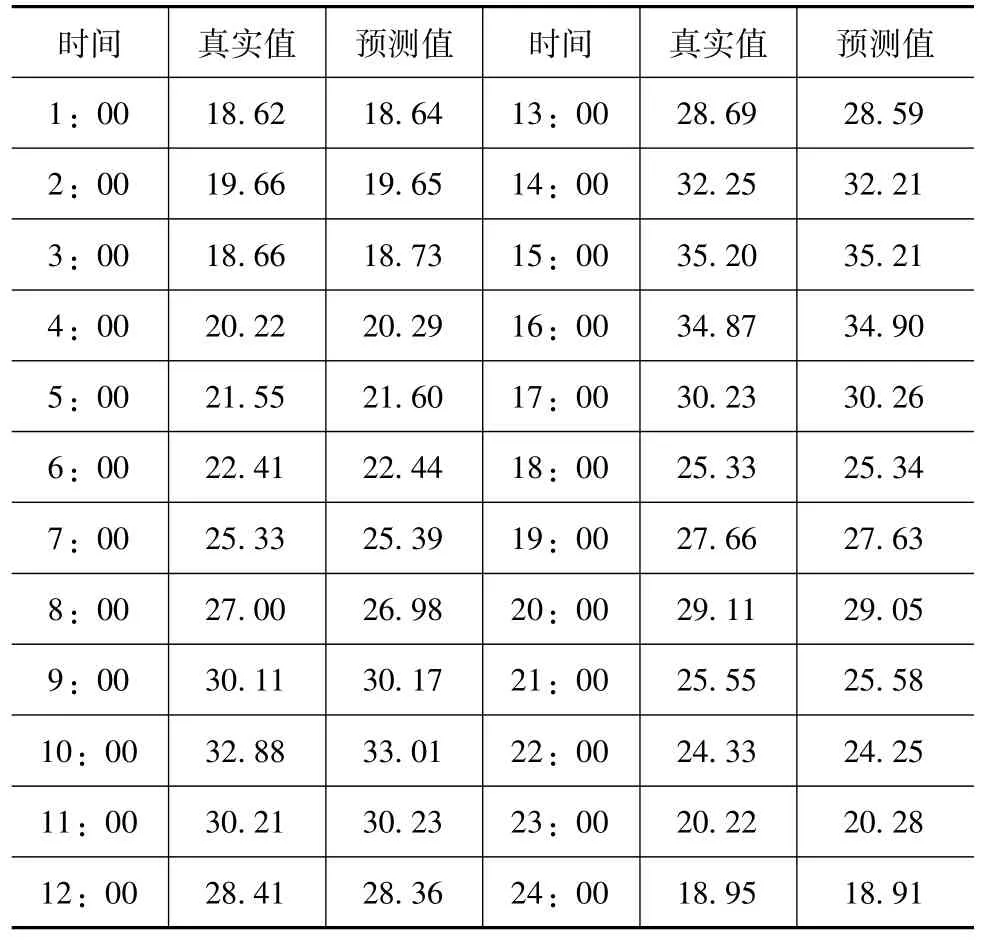
表 电网用户用电负荷情况对比表(单位kW·h)
在相同的用电负荷数据条件下,分别进行了Attention-GRU预测平台、数据挖掘与支持向量机预测平台、NW-FLNN预测平台的用户用电负荷量预测,并得出最终的预测结果。
3.6 预测结果对比分析
本次设计采用了基于MATLAB的用户用电负荷自动预测系统,同时与Attention-GRU预测平台、数据挖掘与支持向量机预测平台、NW-FLNN预测平台最终预测结果进行对比分析。根据平均绝对误差值、平均绝对百分比误差值两大指标判断最终预测效果[6]。最终测试结果表明了基于MATLAB的用户用电负荷自动预测系统平均绝对误差值、平均绝对百分比误差值均小于其他三个预测平台,也就表示相比于Attention-GRU预测平台、数据挖掘与支持向量机预测平台、NW-FLNN预测平台,基于MATLAB的用户用电负荷自动预测系统预测误差更小,即所得到的预测结果更加精准。
4 结束语
综上所述,电力能源关乎到社会经济发展以及人民日常生活,所涉及到的影响非常大,因此如何保证电网供电的稳定性是需要重点考虑的问题。电力定价关乎到社会发展的多个方面,同时也会对电力企业日常盈利情况造成直接影响。对此,本文提出了一种基于MATLAB的用户用电负荷自动预测系统,该系统是以序列理论作为基础,通过采集用户历史电力负荷数据预测未来一段时间的用户用电负荷量。对基于MATLAB的用户用电负荷自动预测系统仿真测试表明,该方法相比于Attention-GRU预测平台、数据挖掘与支持向量机预测平台、NW-FLNN预测平台更具优势,在保证预测效率的同时预测精度更高,达到了预测模型设计标准。基于MATLAB的用户用电负荷自动预测系统的应用,有助于电力定价决策,让电力定价更加符合市场需求,满足供电、用电均衡。



