陈紫媚 罗平


摘要:针对图像模糊以及隐藏物品特征不明显问题,研究了一种更有效的被动毫米波雷达图像隐藏物品检测方法。该方法首先使用超分辨卷积神经网络对原始低分辨图像进行超分辨重建,然后使用直方图阈值分割技术对图像进行二值化处理,最后使用YOLOv3进行目标检测,被动毫米波雷达图像处理结果验证了提出方法对隐藏物品检测的有效性。由结果可见,通过SRCNN算法对图像进行超分辨率重建后,图像质量得到了改善,再利用深度学习算法可较准确地识别隐藏物品的位置、类别和置信度。
关键词:被动毫米波; 超分辨卷积神经网络;YOLOv3;目标检测;深度学习
中图分类号:TP183 文献标识码:A
文章编号:1009-3044(2020)28-0182-03
Abstract: Aiming at the problem that the image is fuzzy and the features of hidden objects are not obvious, a more effective method of detecting passive millimeter-wave radar image is studied. In this method, the original low-resolution image is reconstructed by using the super-resolution convolution neural network, then the image is binary processed by histogram threshold segmentation technology, and finally, the target is detected by using YOLOv3. The results of passive millimeter-wave radar image processing verify the effectiveness of the proposed method for detecting hidden objects. It can be seen from the results that the image quality is improved after super-resolution reconstruction by SRCNN, and then the location, category, and confidence of hidden objects can be identified more accurately by using a depth learning algorithm.
Key words: passive millimeter-wave; SRCNN; YOLOv3; object detection; deep learning
1引言
被动毫米波[1-2]与太赫兹[3]是安全检测仪成像方式之一,它们相比于传统的X光与红外成像,既能够穿透纤薄的衣服、布袋、脂肪等遮盖物,又可以吸收和反射金属片、爆炸物、液体等极性类型的物品,并且辐射的光子能量低不会危害人体的健康,更值得进行研究来开发性能更完善的检测设备。被动毫米波图像分辨率低和纹理难以区分是检测毫米波雷达图像的主要障碍,尝试使用超分辨率算法是解决这一缺陷的可取策略。
目前主流的检测算法主要分为两种:一种是单步端到端的检测算法,典型代表有SSD和YOLOv3,检测速度快但是对小目标的检测精度不高;一种是基于候选区的双步检测算法,比如Faster RCNN,检测的效果好但耗费的时间及计算资源量大。安全检测仪一般使用在人群流量大的场景,其检测效果直接与人身安全挂钩,所以被动毫米波雷达图像的检测模型既要满足速度又要追求精度,笔者采取单步检测算法YOLOv3检测前添加超分辨处理的方法来改善检测的质量。
2检测方法与步骤
2.1 SRCNN算法
SRCNN[4]由C.Dong等人提出,是第一种使用端到端的超分辨重建网络算法。SRCNN三层网络框架简练直白,首层有64个卷积核,尺寸为9*9,输出64维的特征图,下一层用32个1*1的卷积核过滤上一层的输出,生成高清特征向量,最后一层用1个5*5的卷积核合并高清特征成图。三层卷积的公式如下:
式中,W和B表示卷积的权重和偏置,×表示卷积。
这种超分辨重建方法需将图像转化成Ycbcr的格式,选取Y通道的像素,也就是根据图像的亮度进行重建,并将高清图像转换成低清图像,用SRCNN训练低分辨率图像到高分辨的映射。具体流程是这样的:首先得到图像Y通道数据后,采用Bicubic双三次插值方法依次进行1/n、n倍缩放得到低分辨图像并维持图像的大小,然后用SRCNN网络训练插值后的图像进行3次卷积操作。3次卷积的意图是先提取低分辨图像的表征,然后用非线性投影映射出高维的分块表示,最后聚集分块表示得到高分辨图像。接着拟定原始图像作为高分辨图像,计算训练得到的结果与高分辨图像的均方误差MSE,然后反向传播,采用随机梯度下降法更新权值,迭代上百次后得到端到端的映射关系。SRCNN的测试操作很简单,将一张低清图像输入网络便可得到高清图像。
超分辨重建的质量可以使用峰值信噪比PSNR(Peek Signal-to-Noise Ratio)来评价,在超分辨场景下,PSNR/(单位为dB)可由像素点取值范围的上界值L和图像间的MSE均方误差表示,即:
2.2 YOLOv3算法原理
YOLOv3[5]是继检测速度[6]颇快的YOLOv2[7]之后的改进版本,它的一个突出亮点就是处理小问题的检测更准确。YOLOv3使用53个连续的1*1和3*3的卷积网络,即Darknet-53,比YOLOv2选取的Darknet-19多了近2倍的卷积层数量,这也是为什幺YOLOv3比YOLOv2慢的原因之一。YOLOv3网络先经过5次下采样从第79层提取图像的32倍缩略图,然后与61层融合提取图像的16倍下采样,再与36层融合提取图像的8倍下采样,得到3种大小的特征图。假设原图大小为416*416,则小特征图被分成13*13个网格,中特征图被分成26*26个网格,大特征图被分成52*52个网格。网络结构可见下图1:
借鉴特征金字塔(FPN)[8]的多尺度检测方法,YOLOv3预测使用九个不同大小的锚定框,锚定框大小由k-means聚类算法对标注数据计算得出,每个锚定框分为大中小三种尺寸,大尺寸锚定框检测小特征图,中尺寸检测中特征图,小尺寸检测大特征图。边框回归主要任务是从特征图中预测出目标框的位置和尺寸,使用最小二乘法训练。YOLOv3分类方法使用的是逻辑回归的方法,计算边界框与各个真实标签的IoU大小来预测是否含有目标,若最大的IoU大于阈值,则预测框涵盖检测物体,边界框被识别成最大阈值的类。最后三层会输出每个网格预测的3个边界盒位置大小、类别概率和对象预测值。YOLOv3的损失函数主要分为三个部分:目标置信度损失[Lconf(o,c)]、目标分类损失[Lcla(O,C)]以及目标定位偏移量损失[Lloc(l,g)]。公式如下:
其中,[oi∈{0,1}]表示预测目标边界框i中是否真实存在目标,存在为1,[ci]表示预测目标矩形框i内是否存在目标的Sigmoid概率,[Oij]表示预测目标边界框i中是否真实存在第j类目标,[Cij]表示网络预测目标边界框i内存在第j类目标的Sigmoid概率,[l]表示预测矩形框坐标偏移量,[g]表示与之匹配的真实框与默认框之间的坐标偏移量,[(bx,by,bw,bh)]为预测的目标矩形框参数,[(cx,cy,pw,ph)]为默认矩形框参数,[(gx,gy,gw,gh)]为与之匹配的真实目标矩形框参数。
2.3 检测步骤
第一步:将样本数据划分成训练集和测试集,训练集通过训练得到重构图片,测试集作为高分辨图片来计算损失,然后用SRCNN重构的模型预测。
第二步:对超分辨后的图像根据直方图进行阈值分割,由于图片数据较多,使用双峰法对图片进行批量处理,然后对个别划分不准确的图片进行手动调整,从而得到目标边界清晰并且有效的二值化图片。
第三步:对图片进行标注,逐张框选样本图片中的目标,生成与图片对应的标注文件。建立VOC文件夹,VOC下分Annotations、JpegImg和Set三个文件夹,将样本标注数据、图片和数据集放入相应的文件夹中。其中数据集是指将样本按照8:2的比例划分为train、val、trainval、test四个部分,以提供训练及测试。
第四步:加载训练集和测试集,接下来根据训练集的数据生成标注文件annotation.txt,记载图片的路径和标注框的xmin,ymin,w,h,以及类别对应的序号。数据准备好后进行训练,训练的初始学习率设置为0.001,batch_size为64,epoch为100。训练完成后,加载训练的权重,完整的检测步骤流程如下图2所示:
3实验结果和分析
本实验选取了手机和小刀两个类别的被动毫米波图像,图像中的物品分别位于胸前以及裤袋两个位置。其中,小刀的图片数量有230张,手机的图片数量有280张。实验使用的操作系统为Windows 10,Python版本为3.7,CUDA版本为9.0,cuDNN版本为7.0,Keras版本为2.1.5。
第一,由于卷积神经网络中色彩、缩放或明暗等不会改变结果,可以对原始图像做旋转或翻转操作,加强数据样本的多样性,得到更多角度的数据集。然后将采集的图片输入到SRCNN网络中,训练低像素图片到高像素图片的映射模型,结果使用模型重建后的图片与原图的PSNR均值为29.37。
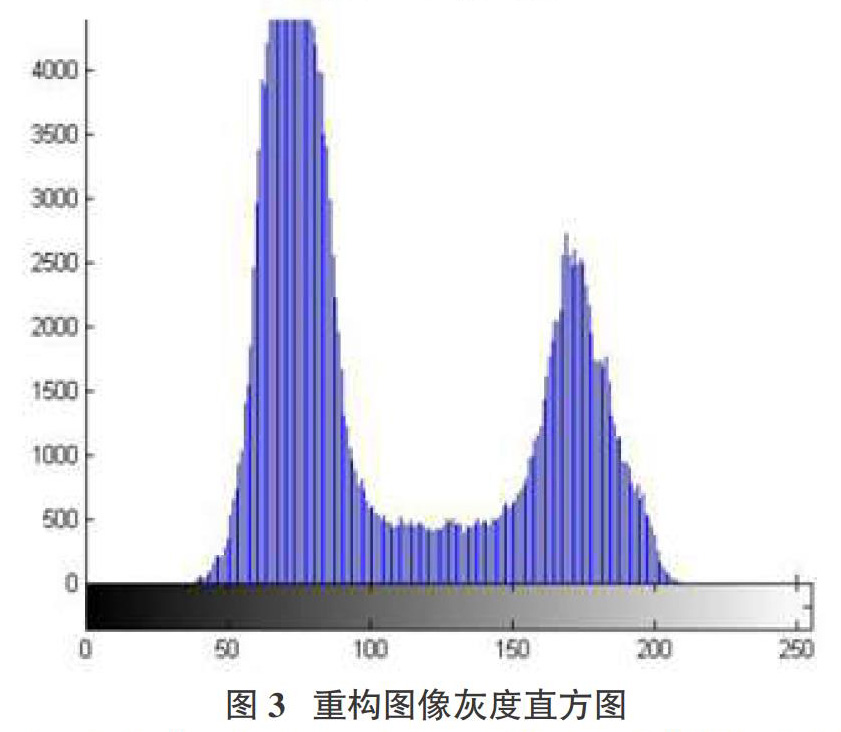
第二,绘制图像经超分辨重建后的灰度直方图如图3所示,观察直方图可以发现,灰度直方图呈出处双峰的特征,为了分割出物品、人体和背景三个部分,选取两峰之间的最小值作为阈值将被动毫米波超分辨图像二值化。
第三,使用标注工具LabelImg框选目标并设置标签类别,标注的类别有三个:小刀、手机、人体,标注后生成xml格式的数据文档。
第四,使用训练100轮后的模型,输入一张测试手机在胸前的图片进行检测,可以得到以下结果如图4所示。
多次测试后可以发现,人体的检测精确率基本高达98%,手机预测的精确率在80%以上,小刀精确率在50%以上。YOLOv3在手机的被动毫米波图像数据集上表现出更好的预测结果,其中一个原因是手机的被动式毫米波图像比较明显,二值化后的轮廓比较相似,小刀的特征还不够明显。
为验证本方法的效果,使用Faster-RCNN两步检测算法检测被动式毫米波雷达图像,检测结果如图5所示。
经计算,手机和小刀的平均精确率如表1所示。
4结论
本文阐述了使用卷积神经网络加强图像特征的超分辨重构框架,并说明了使用YOLOv3检测的方法,比较了不同目标及不同检测算法的检测效果。对比本文的方法与其他检测算法的结果可知,两种方法对大目标的检测结果都表现较好,而本方法对小目标检测还存在不足,还需要再调整网络设置的参数,进一步优化才能提高准确度。从总体看来,使用YOLOv3检测分辨重构好的被动毫米波超图像是可以应用于安检领域的,而且强化目标特征是提高检测的准确率的关键因素之一。
参考文献:
[1] Gonzalez-Valdes B,Allan G,Rodriguez-Vaqueiro Y,et al.Sparse array optimization using simulated annealing and compressed sensing for near-field millimeter wave imaging[J].IEEE Transactions on Antennas and Propagation,2014,62(4):1716-1722.
[2] Farhat N H,W R.Millimeter wave holographic imaging of concealed weapons[J].Proceedings of the IEEE,1971,59(9):1383-1384.
[3] 成彬彬,李慧萍,安健飞,等.太赫兹成像技术在站开式安检中的应用[J].太赫兹科学与电子信息学报,2015,13(6):843-848.
[4] Dong C,Loy C C,He K M,etal.Image super-resolution using deep convolutional networks[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2016,38(2):295-307.
[5] RedmonJ,FarhadiA.YOLOv3:an incremental improvement[EB/OL].2018:arXiv:1804.02767[cs.CV].https://arxiv.org/abs/1804.02767
[6] Chang Y L,Anagaw A,Chang L N,et al.Ship detectionbased on YOLOv2 for SAR imagery[J].Remote Sensing,2019,11(7):786.
[7] RedmonJ,FarhadiA.YOLO9000:better,faster,stronger[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition(CVPR).21-26 July2017,Honolulu,HI,USA.IEEE,2017:6517-6525.
[8] Lin T Y,Dollár P,Girshick R,et al.Feature pyramid networks for object detection[C]//2017IEEEConference on Computer Vision and Pattern Recognition(CVPR).21-26 July 2017,Honolulu,HI,USA.IEEE,2017:936-944.
【通联编辑:唐一东】



