谭台哲 傅美

摘要:图像翻译是目前计算机视觉领域一个比较重要的方向,其目标旨在学习两个不同图像域之间的映射,同时保留原始图像的特征和语义。当今,无监督学习的图像翻译利用生成对抗网络和比较多的训练数据能够取得不错的性能。但现有的图像翻译模型是采用一种一次性的方式形成,其中忽略了训练过程的学习经验,所生成的模型只能适用于特定的领域,不能适应一个未知的领域。该文在循环一致性生成对抗网络的研究基础之上,尝试从元学习的角度来处理这一类问题。
关键词:循环一致性生成对抗网络;元学习;图像翻译;生成对抗网络;计算机视觉
中图分类号:TP183 文献标识码:A
文章编号:1009-3044(2022)22-0070-02
1 引言
当今计算机技术的迅猛发展使得深度学习在相关领域产生了重要的作用,其中,计算机视觉结合深度学习产生了很多效果不错的算法,并应用于图形领域的各个方向。
图像翻译是指将一个图像的表征转换到另一个图像的表征,学习一种映射关系将源域图像映射到目标域图像。转换后的图像的内容由源域图像提供,目标域图像负责提供图像的风格特征或者属性。例如马转换到斑马,夏天转换到冬天。图像翻译可以应用于风格迁移、图像修复等。图像翻译在近些年来得到了迅速发展,这得益于深度学习的浪潮,特别是生成对抗网络(Generative Adversarial Nets,GAN) [1]的出现,使得图像翻译技术得到了更进一步提升。图像翻译在近几年有着诸多较为成功和经典的模型,例如Pix2Pix[2],CycleGAN[3]、StarGAN[4]等。
当今,无监督学习的翻译框架是使用不成对的训练数据学习一个映射,将给定类中的图像映射到不同类中的类似图像。然而,目前的研究偏向于学习一个特定的转换任务模型,而且需要在训练时使用到海量的源域和目标域中的图像数据,这类方法在某些特定领域取得了重大的成绩,但是对于一些新领域,并没有足够的数据来支撑模型的训练,如果只是简单地将模型应用于新的任务,即便使用数据增强技术来扩展新任务领域的数据,也无法获得好的效果,会产生严重的过拟合问题。在难于获取数据的背景下,小样本学习应运而生。小样本学习是以任务为基础,核心思想是让模型学会学习,主要分为度量学习和元学习[5]。度量学习是指通过在嵌入空间与样本产生一种映射,在嵌入空间中比较样本间的相似度。元学习是从很多任务的学习中获取丰富的先验知识,将获得的先验知识提供了归纳偏差,使得模型在不同的任务之间泛化。元学习亦称为学会学习[6]。通过学习相似任务之前的共性部分获得经验,利用学习到的经验对新任务进行微调,无需重新学习就可以很好地泛化到数据不足的新任务中。
本文运用CycleGAN作为研究基础,将元学习的概念扩展到图像翻译中,从元学习的角度改进CycleGAN,这个方法使得模型可以有效利用先前图像翻译任务中的学习经验。笔者方法的目标是首先利用不成对的数据进行有效的训练,然后将获得的模型应用于各种新的图像翻译任务。
2 相关工作
2.1GAN网络
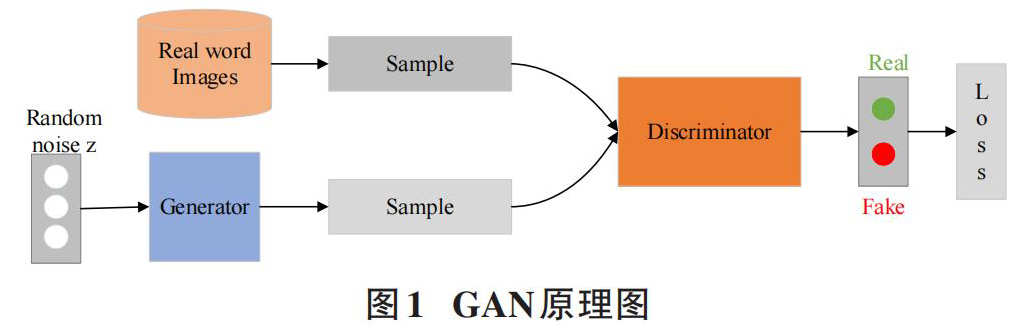
GAN是一种深度学习模型,是无监督学习领域具有广阔前景的模型之一。该模型由两个相互竞争的组件组成,一个生成器(Generator, G) 负责捕获样本数据分布并学习生成感兴趣的数据候选。一个判别器(Discriminator, D) 负责评估生成的数据是否满足真实数据分布的概率,原理如图1所示。
GAN的原理充分体现了博弈论的思想。生成器以随机噪声(通常是均匀分布或者高斯分布) 作为输入生成与真实样本相似的数据,判别器将生成的图像作为输入并评估它们以输出图像与真实图像的概率。G网络的目标是生成尽可能真实的图像来欺骗D网络,使得D网络无法分辨出真实图像与合成图像之间的区别,整个网络最终达到纳什均衡。两个网络之间的对抗关系如公式(1) 所示。
[minmaxV(D,G)=Ex~Pdata(x)[logD(x)]+Ez~Pz(x)[log(1-D(G(z))]] (1)
其中:x代表真实图片数据,z代表随机噪声,G(z)代表合成的图像,D(x)和D(G(z))是鉴别器对真实图像和合成图像的输出,[Ex~Pdata(x)]是真实数据的数学期望值。训练生成器最小化[ log(1-D(G(z))]同时训练判别器最大化[logD(x)]。
2.2 CycleGAN
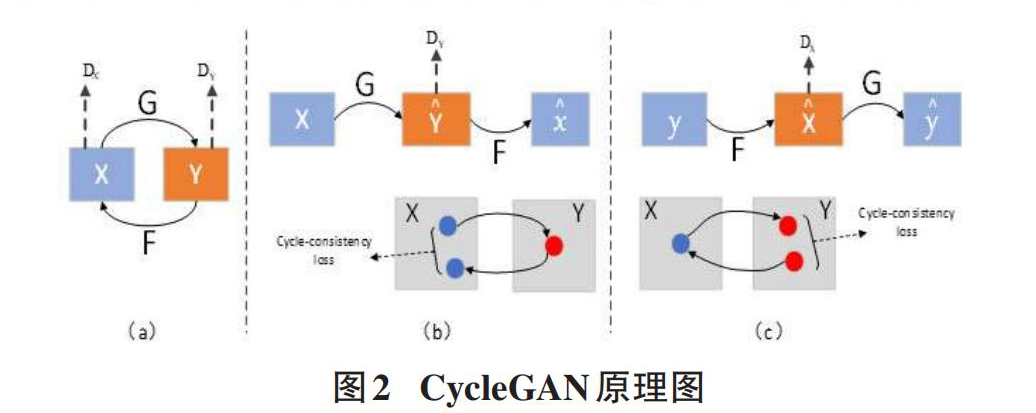
CycleGAN是由两个GAN网络组成,旨在实现两个图像域(X,Y) 之间的相互映射,为了避免所有的X都被映射到同一个Y,所以采用了一对生成器和判别器的结构,既能进行X到Y的映射,也能进行Y到X的映射,原理如图2所示。模型通过训练后,可以在不同的图像之间进行转换。在这个过程中,要保证循环的一致性,所以在其中引入了一个循环一致性损失。
图2中,(a) 是CycleGAN模型总览图,X和Y可以通过生成器网络G和F相互转换。(b) 、(c) 是CycleGAN模型两个循环的迭代步骤。
2.3 与模型无关的元学习(MAML)
与模型无关的元学习(Model-Agnostic Meta-Learning,MAML) [7]是一种独立于模型的元学习算法,可用于基于梯度下降的各种学习问题和模型。不像之前的元学习方法需要学习更新函数或学习规则,MAML既不增加模型参数的数量,也不对模型的结构设置任何限制。MAML可以轻松地与全连接网络、卷积网络和循环网络进行交互。
MAML算法的训练以任务为训练单元,将对应的数据集划分为训练集、验证集和测试集。整个算法分为元训练阶段和元测试阶段。在元训练阶段,从给定的分布[Ti~p(T) ]中选择任务,其中每个任务包含K个类别,每个类别包含N个样本。元学习试图通过训练所有的任务来获得一个良好的广义模型,从而快速适应新的任务。元训练阶段,首先使用训练集得到原始模型参数[θ]在[Ti]上的损失值[ LTi(fθ)],然后使用梯度下降得到[θi],如公式(2) 所示。
[θi=θ-α?θLTi(fθ)] (2)
其中[α]是在内循环中使用的元训练学习率,然后使用测试集来验证期望参数,从而获得一个新的损失,这里的损失值只能看作是一个元损失的一部分,在整个内部循环结束之后计算的累计和就是最终的元损失。计算总损失的梯度并做随机梯度下降更新模型的原始参数值,如公式(3) 所示。
[θ=θ-β?θTi~P(T)LTi(fθ'i)] (3)
其中[β]是外循环中使用的学习率。MAML在一个小样本数据集上进行训练后,基础模型将学习到良好的初始化参数,并能使用这个良好的参数有效地完成小样本学习任务。
3 网络结构和具体算法
本文在CycleGAN图像翻译算法中引入了元学习的方法,构建了基于MAML与改进CycleGAN的图像翻译方法。
3.1 改进CycleGAN网络结构
CycleGAN的生成器采用的是由步幅为2和卷积核大小为3*3的两个卷积层,6个卷积核大小为3*3的残差块和两个步幅为0.5和卷积核大小为3*3的转置卷积层组成,通过全卷积网络连接。整个生成器网络都是采用的残差网络,残差网络的优势需要在足够深的网络中才能体现出来,而在CycleGAN中输入图像为256*256时采用的是9层网络,网络并不是深。受到马赫等人[8]的启发,使用Inception模块代替原始单一的ResNet模块,并保持原始一致的结构。
3.2 元学习的任务设定
在元学习的训练中,训练样本包含从P(T)提取的有限的一组任务Tn,训练任务数量是N。具体而言,每个训练任务Tn是一个[Tn=(STn,QTn)]的元组,其中S表示支撑集,Q表示查询集,S和Q不相交。算法将Tn作为输入,并为元学习器产生学习策略。元学习器可以根据支持集数据迭代地调整参数,并通过使用查询集数据计算元目标值来评估其泛化性能。然后通过测试误差相对于参数的变化来改进元学习器。
3.3 元训练过程
Algorithm 1 Training process
Require:[P(T)]:distributionovertasks
Require:[α,β]:stepsizehyperparameters
1:randomly initialize [θ]
2:while not done do
3: Sample batch of tasks [Ti~P(T)]
4:for all [Ti]do
Meta-training:
5: Evaluate [?θLTifθ] with respect to K examples
6: Compute adapted parameters with gradient descent:[θ'i=θ-α?θLTi(fθ)]
7: end for
Meta-testing:
8:Update [θ←θ-β?θTi~P(T)LTi(fθ'i)]
9:end while
上述算法是元学习结合改进CycleGAN方法的预训练算法,主要目的是对先验知识的积累。MAML的训练过程可以看作是一个由内环和外环组成的双层优化,也称为元训练和元测试。
4 实验结果与分析
4.1 实验环境和数据集
本文实验采用的硬件配置为Inter Xeon E5 2680 v3(3.3GHz)处理器,GPU为NVIDIA GeForce GTX2080Ti、RAM16GB。软件配置采用Pytorch深度学习框架,操作系统为64位Ubuntu16.04LTS。数据集使用horses2zebras, summer2winter, apple2orange, monet2photo。
4.2 实验结果
本文收集了4种双域翻译任务,分别是马到斑马,夏天到冬天,莫奈风格到照片和苹果到橙子。笔者随机选择3个作为训练集,并选择其他一个任务作为测试数据集来模拟元翻译场景。
从左到右,这些列分别表示来自源类图像的输入、CycleGAN的结果和本文的结果。
从图3中可以看出,本文所提出的方法在数据样本数量不足的情况下仍然有着良好的输出图像。在只有10个训练样本的情况下,基本能够成功地输出目标域的图像,在输出图像的某些细节方面优于CycleGAN生成的图像。
5 总结
本文从元学习的角度研究图像翻译问题,旨在利用先前领域的翻译先验知识,经过实验证明,本文所提出的方法能够在数据样本不足的情况下对新任务领域的翻译产生较好的输出。当然,此方法还有更好的改进,在今后的工作中将对MAML的结构进行改进,更好地保留图像的原始特征。另外,在MAML训练过程中由于梯度减小问题而引起的训练不稳定问题没有得到解决,这为今后的工作提供了方向。
参考文献:
[1] Goodfellow I,Pouget-Abadie J,Mirza M,et al.Generative adversarial networks[J].Communications of the ACM,2020,63(11):139-144.
[2] Isola P,Zhu J Y,Zhou T H,et al.Image-to-image translation with conditional adversarial networks[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition.Honolulu,HI,USA.IEEE,2016:5967-5976.
[3] Zhu J Y,Park T,Isola P,et al.Unpaired image-to-image translation using cycle-consistent adversarial networks[J].2017 IEEE International Conference on Computer Vision (ICCV),2017:2242-2251.
[4] Choi Y,Choi M,Kim M,et al.StarGAN:unified generative adversarial networks for multi-domain image-to-image translation[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition.Salt Lake City,UT,USA.IEEE,2018:8789-8797.
[5] 陈瑞敏,刘士建,苗壮,等.基于元学习的少样本红外空中目标分类方法[J].红外与毫米波学报,2021,40(4):554-560.
[6] 朱应钊,李嫚.元学习研究综述[J].电信科学,2021,37(1):22-31.
[7] Finn C,Abbeel P,Levine S.Model-agnostic meta-learning for fast adaptation of deep networks[C]//ICML'17:Proceedings of the 34th International Conference on Machine Learning - Volume 70,2017:1126-1135.
[8] 马赫,张涛,卢涵宇.基于CycleGAN的图像风格迁移[J].电脑知识与技术,2020,16(27):18-20.
【通联编辑:唐一东】



