姜永超
(燕山大学 国际教育学院,河北 秦皇岛 066004)
基于数据挖掘的学生选课及学习行为分析算法研究
姜永超
(燕山大学 国际教育学院,河北 秦皇岛066004)
依据教育数据挖掘技术,通过关联规则挖掘中的确定因素法和序列模式挖掘,分别对学生课程选择的最小关联规则和学生的临时兴趣学习模式进行挖掘,以此进行学生的行为分析。首先,通过最小关联规则挖掘中的确定因素(DF)法,从课程数据库中挖掘学生课程选择的最小关联规则。其次,通过临时兴趣序列模式(TIPS)技术,在学习活动序列中发现短期的学习行为模式。最后,通过数据实验验证该算法具有实际意义。
数据挖掘;关联规则;确定因素法;序列模式
近些年,围绕着大数据可被用于造福教育与学习科学这一共同利益,两个方面的技术逐渐得到了发展,这两个方面就是教育数据挖掘(EDM)以及学习分析[1]。随着教育数据挖掘的快速发展,数据挖掘中的各项技术,诸如关联规则挖掘,序列模式挖掘等技术都相继得到了应用,这也进一步促进了教育数据挖掘技术的发展。同时,通过教育数据挖掘对教育数据进行的数据挖掘而得到的潜在信息或是关联规则也得到了更多的应用,通过这些潜在信息和关联规则,管理者可以更好地制定管理策略和教学策略,这对提高学校的管理和教学有着非常重要的意义[2]。
1 学生课程选择的最小关联规则的挖掘
学生的课程选择是大学生日常学习生活中必须接触到的,并且会直接影响到学生在校学习,所以课程选择显然是一种重要的学生行为[3]。因此,采用确定因素法,从课程数据库中挖掘学生课程可以采用最小关联规则挖掘技术。
1.1关联规则
(1)关联规则的挖掘
关联关系可以采用置信度、支持度、期望置信度、作用度四个标量进行表述。通常来说,置信度就是关联规则下准确度的衡量标准,而支持度则体现了重要性标准。支持度越大,说明这个关联规则就更加重要。如果在数据挖掘中,存在关联规则的置信度较高,但是支持度却相对较低,那么这种规则的实际应用效果就很难保障[4]。
(2)关联规则挖掘的过程
关联规则的挖掘需要通过两个阶段来实现:第一个阶段就是从现有的数据集合中找到高频项目组,并进行整合;第二个阶段就是通过这些高频项目组构建关联规则。
在第一个阶段中涉及到的高频项目组中的高频内涵指的是其中某一个具体的项目组出现的频率,只有这个项目组在记录中出现的频率达到了某一个水平,那么就叫做高频项目组。而且一个项目组出现的频率实际上就是支持度。比如以包含了物品集合A和物品集合B的项目为例,通过式(1)就能够获得{A,B}的项目支持度。
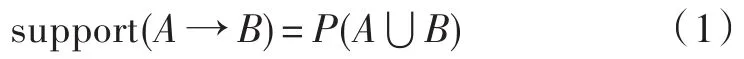
通过式(1)计算出来的支持度如果大于设定的最小支持度,那么{A,B}这个项目组就可以称作高频项目组。比如某个项目组K-满足了这个最小支持度,就说明这个项目组K-是高频项目组,可以使用Large k表示这种高频项目组。然后关联算法就从Large k中进行延伸,从而产生Large k+1,直到找到了所有的高频项目组。
关联规则的第二个阶段自然就是找到关联规则。实际上很多高频项目组就是产生关联规则的摇篮。利用第一个过程中的项目组K-获得关联规则。在设置最小置信度的门槛下,如果每一个关联规则超过了这个置信度,那么这个规则就能够作为有意义的关联规则进行评估和可视化。
1.2教育数据挖掘中的最小关联规则
教育类数据是挖掘明显的最小关联规则中的一种潜在资源,这些规则对于协助高校的管理者或是高校的教师在做出正确的决策和制定完善的教学方案时有着非常好的作用。这一研究的重要性在于,它能够发现所选的课程中不寻常的关联[5]。进一步而言,它还可以反映在大学的课程问题上频繁和最低规则的结合中可能存在的规则。这一研究的结果可以让学校老师给某一类的学生提供合适的课程作出指导。事实上,它可以帮助大学政策制定者理解和提高目前的教学水平,整体提升管理流程水平[6]。
采用确定因素(Definite Factors,DF)法检测学生已选择的大学课程之间的不寻常关系。事实上,确定因素法可以考虑到大学课程之间的频繁和最低的结合因素,用以生成想要的最低管理规则。在生成这些规则之前采用LP-3和LP-增长算法。
1.3确定因素法
设I={i1,i2,…,i|A|},|A|>0指的是一系列称为常数值的项目,W={w1,w2,…,w|A|}指的是一系列非负实数称为权重的项目,|U|>0指的是业务中的数据集,而业务中的t∈D是一系列特别的项目,t={i1,i2,…,i|M|},1≤|M |≤|A|,每个业务可以由一个特殊的识别码TID进行识别。
(1)定义
针对本文中所使用的算法,为了使其易于理解,在这里,先给出一些定义。
定义1设X⊆I为一个项目集,该项目集合为项目K-,称为项目集K-。
定义2该项目集的支持值是X⊆I,即supp(X)被定义为一项包括了业务X的项目数据。
定义3设X,Y⊆I为一个项目集,X和Y之间的关联规则是在X⋂Y=∅的情况下,X⇒Y。其中,X和Y分别表示原因和结果。
定义4关联规则支持值X⇒Y,即supp(X⇒Y),则定义为包括了业务D中X⋃Y的数据。
定义5关联规则X⇒Y的置信区间,即conf(X⇒Y),定义为包含X⋃Y的业务D中的数据的一种概率。所以,conf(X⇒Y)的计算公式如下:
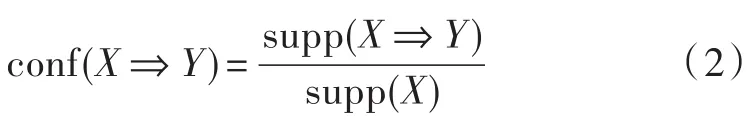
定义6确定因素是在不同的项目集里,通过一个项目集的频繁程度与基准频率进行对比,开发支持值的公式。项目集的基准频率应假设为统计上是独立的。
确定因素,即DF,且:
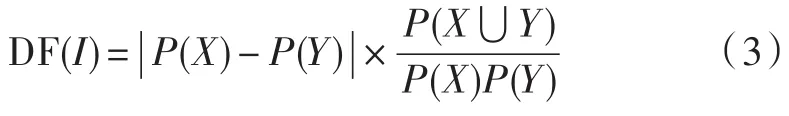
(2)最低关联规则的构造定义
若一个规则符合以下两个条件归类为最小相关规则定义(SLAR)。一是,相关规则的DF必须大于预设的最低DF。最小DF是在0~1之间。二是,相关规则的因果条件必须既不是最低项目也不是频繁项目[7]。每个相关规则DF的计算都应该采用定义6的方法确定。DLAR算法构建的完整过程如下:
1:Specify DFmin
2:for(DIa∈DefiniteItemset)do
3:for(DFIi∈DIa∈FrequentItems)do
4:for(DLIi∈DIa∈LeastItems)do
5:ComputeDF(DFIi,DLIi)
6:if(DF(DFIi,DLIi)>DFmin)do
7:InsertDLAR(DFIi,DLIi)
8:end if
9:end for loop
10:end for loop
11:end for loop
1.4实验结果
用确定因素方法取得实验文本,所有关联规则的权重都会根据这一方法进行分配。在此,学生可以在原始图表中根据固定定位选择8个课程。每个课程的实际定位是根据固定课程进行设置的。在某大学里,共计为某届学生提供822个本科课程。根据这些数据,160名学生选择了342个本科课程,可以归类为47个类型领域。从中抽出了5个课程列在表1中。同时,在实验中还用到了确定因素法中的LP-树和LP-成长算法。
经过实验,共有4 177个相关规则被成功提取出来,如图1所示,学生一共选择了一些(或没有选择)相关的计算机课程,大约有32%的学生没有申请计算机科学课程,大约有36%的学生选择了4门计算机课程。如图2所示为采用不同支持范围的相关规则的总数。较高的相关规则数支持值低于1%,而最低值相关规则的支持范围应为2%~3%,进一步分析表明,专注于支持值大于3%的规则。3%的最小支持值相当于在本项目中必须至少出现五次的项目集。表2列举了前十位最小值为3%的相关规则。

表1 一部分本科课程
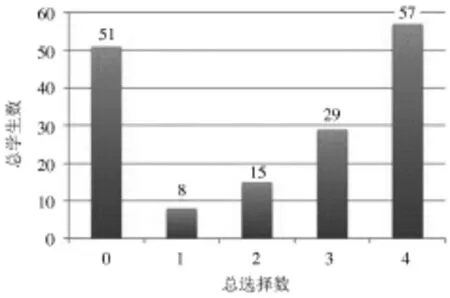
图1 根据兴趣选择计算机科学课程的学生总数
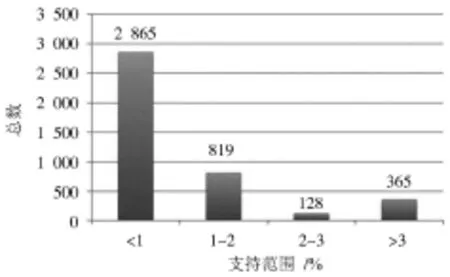
图2 基于不同支持范围的关联规则总数
表3给出了根据表2的相关规则的意义。由于课程领域的矛盾,第一个规则到第五个规则是比较奇怪的。第六个规则就非常真实,因为在基础要求上两个项目有着相似之处。第六到第十个规则,解释起来则比较难比较复杂,因为这些课程中并无相关的兴趣。据此,可以看到,学生们在选择大学课程的过程中混淆了他们的几种兴趣。总之,在大学选课数据库中现存的相关规则是有例外的。这一信息对全面了解学生的兴趣以及如何引导他们选择更合适的大学课程是非常有意义的。
2 挖掘具有临时兴趣的学习行为模式
2.1识别临时兴趣模式
在这一环节里,使用序列技术展现临时兴趣序列模式(TIPS)技术并使其与兴趣方法相符,从而辨识出学生行为中最具临时兴趣的部分,然后对其进行视觉化处理[8]。每名学生的一系列不同行为都具有与其相关的序列,TIPS技术主要由四个基础步骤组成:
(1)通过在学生的学习活动序列中应用序列模式挖掘法并生成候选模式(频率底线为50%);
(2)通过把每个候选模式映射到它在活动序列中发生的位置,算出其临时覆盖区域;
(3)使用一种被应用于每种模式的临时覆盖范围中的理论兴趣方法来提供候选模式的排名;
(4)对于那些排名较高的模式,使用热量地图对其临时覆盖范围做出视觉化处理,从而更轻易地获取其用法趋势和峰值。
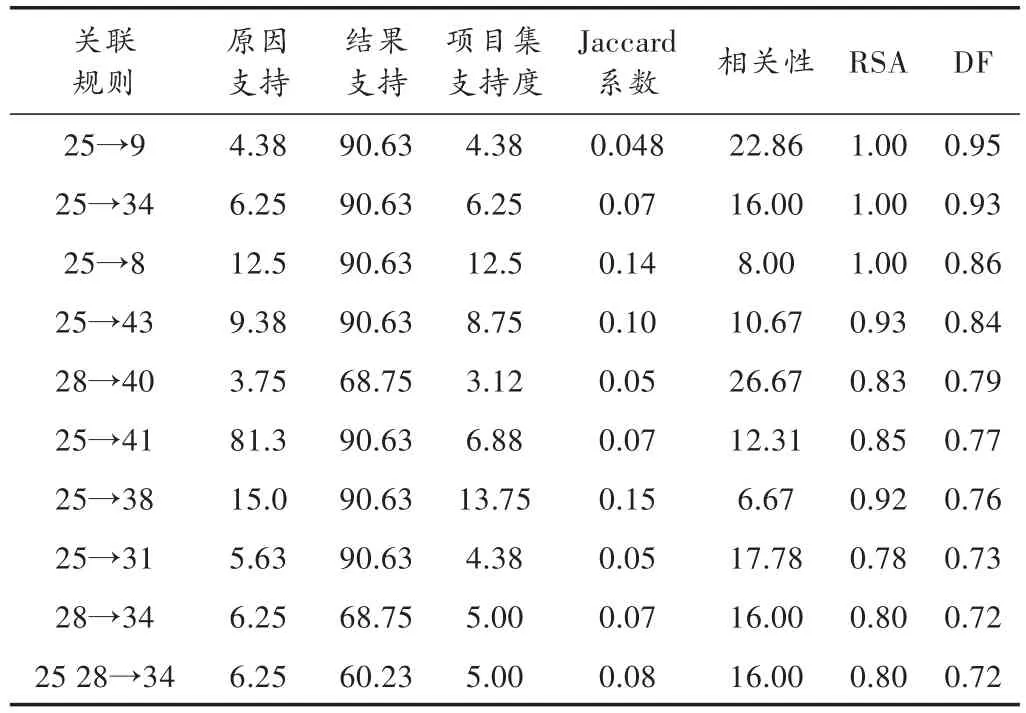
表2 由确定因素方法算出的相关规则前十位降序排列,100%的置信度
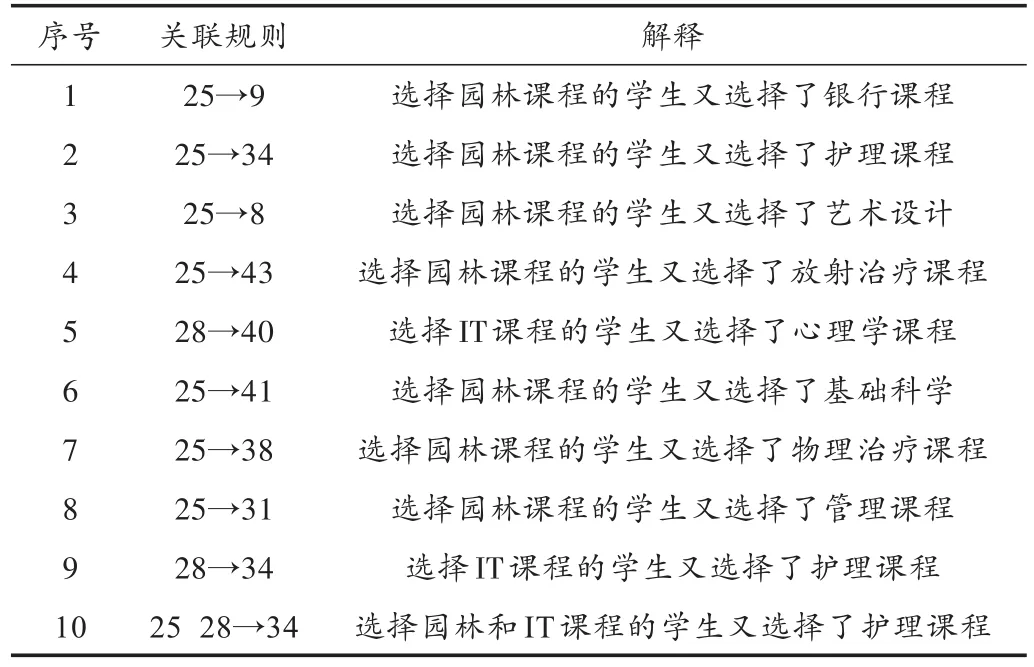
表3 正相关规则的前十位
为了定义TIPS技术的信息增益应用表现出了两个重要观点:
(1)当使两种模式的总发生几率相同时,更具时间特异性(即特定时间域内具有更多独特活动)的模式则会具有更高的排名;
(2)当使两种模式在相临时域内总发生几率相同时,总计频度更高的模式则会具有更高的排名。2.2Betty的大脑数据
在“Betty的大脑”这款软件中,学生的学习和教导任务主要围绕以下7种展开:阅读相关材料获取信息;在因果联系图中添加或移除联系以组织联系,然后把这些信息教授给Betty;询问Betty对基于因果联系图域的看法;让Betty参加由导师制作出的小测验以检验其对于当前图中各种联系的正误理解;让Betty说明她会使用哪种关系来回答小测验中的问题;记下笔记以供日后参考;标注出联系以记录下通过测试与阅读环节决定的正确性。
2.3实验结果
从68名学生活动的序列来看,序列模式挖掘法识别出了超过一半的学生都具有的215种行为模式。为了获取关于其用途随着时间变化而发生演变的广泛性,把各模式的出现值归入活动范围的15以内。
表4给出了由TIPS技术识别出的每位学生身上最常见的30种行为模式中的3种,以及依照出现频率对TIPS排名和基线排名进行对比。归纳出来的TIPS模式中近一半模式(30个中的13个)在发生率上的基线排名超过50;大多数模式(30个中的9个)的基线排名超过100。如果没有TIPS技术的存在,那么此类低排名(在发生率上)模式将很容易被忽视。这种模式具有较高的发生率排名(因为它具有较高的平均发生率)和较高的TIPS排名(因为它还具有强烈的时间变化)。学生们倾向于以这种模式展开学习活动,这种模式在学生的整个活动过程中最多占到了20%~40%的比例。
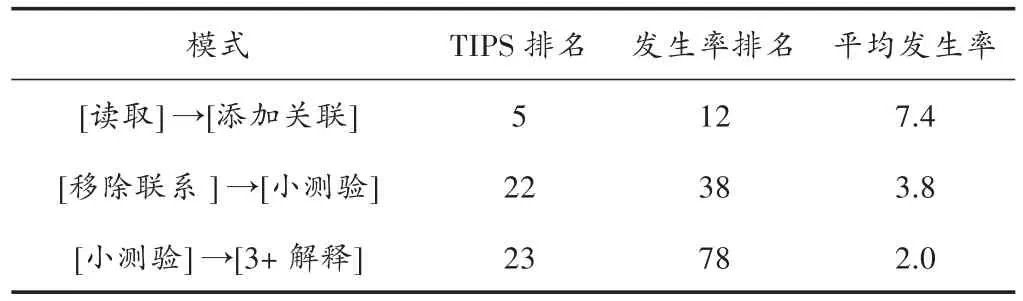
表4 选定模式的TIPS和发生率排名
另一项通过TIPS技术识别出的临时兴趣模式是紧随小测验之后的移除错误因果联系环节,学生们通常在后期使用这种行为模式。通过这种行为模式可以发现被学生用来在小测验中确定关联是否错误以及是否应该被移除的监管行为。随着学生们添加越来越多的错误关联,这种形式的出现呈现出超出预期的上升趋势。
TIPS在对普通模式和具有高发生率模式的认知过程中也同样发挥着重要的作用。发现那些随着时间的变化具有临时性用处演变的模型对于教育以及其他领域的研究者和专家也具有极为重要的作用。
使用此项技术挖掘“Betty的大脑”中数据的结果体现出随着时间的变化具有演变的认知行为的潜在利益,同时也具体化了TIPS排名和发生率基线排名的差别。尽管考虑到系统条件和学习活动的限制,发生率排名的总体趋势只能代表一些特定模式;但TIPS技术可以通过强有力的时间演变特性识别出这些模式,并确定一些预期模式;同时它也能辨识出与预期不符的一些模式,如果没有TIPS技术,那么这些模式很容易就会被忽视。总体上讲,这些结果阐释了TIPS技术的效用,同时还说明TIPS排名和发生率排名中排名较高的模式是对重要学习行为模式的初期分析和鉴定最为有用的。
3 结 论
本文主要依据教育数据挖掘技术,通过关联规则挖掘中的确定因素法和序列模式挖掘,分别对学生课程选择的最小关联规则和学生的临时兴趣学习模式进行挖掘,以此进行学生的行为分析。其中,通过挖掘学生课程选择的最小关联规则,以此确定学生选择的大学课程中的特殊联系,帮助管理者制定教学和管理策略,提高学生学习成绩。其次,在基于电脑的学习环境下,识别出学习活动数据中的序列模式能够帮助大家发现、理解和研究学生学习行为,通过TIPS技术在学习活动序列中发现具有临时兴趣的行为模式。通过对学生课程选择和学生学习行为模式的教育数据挖掘对学生行为进行分析,帮助管理者和老师提高教学管理水平。
[1]徐维.RFID在学生行为分析系统中的应用[J].孝感学院学报,2010(z1):22-25.
[2]李婷,傅钢善.国内外教育数据挖掘研究现状及趋势分析[J].现代教育技术,2010(10):13-16.
[3]孙云帆,齐美玲.数据挖掘在教育应用中的浅析[J].商场现代化,2012(24):55-57.
[4]杨永斌.数据挖掘技术在教育中的应用研究[J].计算机科学,2006(12):78-80.
[5]SCHEUER O,MCLAREN B M.Helping teachers handle the flood of data in online student discussions[C]//Proceedings of 2008 9th IEEE Conference on ITS.Montreal:Springer,2008:323-332.
[6]王爱平,王占凤.数据挖掘中常用关联规则挖掘算法[J].计算机技术与发展,2010(4):88-90.
[7]孙云帆,齐美玲.数据挖掘在教育应用中的浅析[J].商场现代化,2012(24):90-92.
[8]王登.数据挖掘技术及其在高校素质教育应用中的探讨[J].现代电子技术,2007,30(4):95-97.
Research on students course selection and learning behavior analysis algorithm based on data mining
JIANG Yongchao
(College of International Exchange,Yanshan University,Qinhuangdao 066004,China)
According to the educational data mining(EDM)technology,the minimum association rule of students course selection and student temporary interest learning pattern are mined respectively by means of definite factor method and sequence pattern mining in association rules mining to analyze the student behavior.The definite factors(DF)method in minimum association rule mining is used to mine the minimum association rules of students course selection in the courses database.And then,the temporary interest sequence pattern(TIPS)technique is used to find out the short-term learning behavior pattern in learning activity sequences.The experimental verification results show this algorithm has a practical significance.
data mining;association rule;definite factor method;sequence pattern
TN911-34;TM417
A
1004-373X(2016)13-0145-04
10.16652/j.issn.1004-373x.2016.13.035
2015-11-27
2015年河北省社会科学基金项目(HB15YY001)系列成果之一:信息技术下河北省对外汉语教学深度融合研究
姜永超(1980—),男,河南柘城人,博士,讲师。从事对外汉语教学、第二语言教育技术学研究。



