李颖桃,续欣莹,谢珺,刘建霞
(太原理工大学,山西 太原 030600)
0 引言
图像分类是计算机视觉领域的一个重要研究课题。图像分类的目标是让计算机可以和人一样有快速准确识别复杂视觉图像的能力[1]。随着人工智能及模式识别的迅速发展,图像分类广泛应用于智能交通、目标识别和图像检索等方面。
空间金字塔模型(Spatial Pyramid Matching,SPM)[2]是目前主要的图像分类方法之一,在视觉词袋模型(Bag Of Words,BOW)的基础上,通过对图像进行多层次划分增加图像的空间位置以及形状信息。基于空间金字塔模型的图像分类方法主要包括4部分:特征提取、生成视觉词典、构建空间金字塔以及用统计合并直方图的方法生成图像视觉描述。特征提取和特征选择是图像分类的关键前提,传统的空间金字塔匹配模型(SPM)虽然在图像分类问题上取得了很大突破,但由于其提取的特征不能有效表达图像的信息,分类性能仍然不高[3]。
图像特征提取方法中,单一特征提取对图像的描述较片面,不能很好地表达图像中的内容[4]。多特征可以更全面描述图像信息,目前已有大量学者通过结合多个特征描述子来表达图像内容[5]。但是多特征在全面描述图像的同时也带来大量的冗余信息,如何在众多的特征中把不重要甚至冗余的特征去掉而不影响图像内容的表达,在图像分类中是至关重要的。邻域粗糙集(Neighborhood Rough Set,NRS)[6]特征选择在剔除连续型知识表达系统的冗余特征方面有很好的效果。特征提取后通过特征选择形成更有效的特征子集,图像信息得到简化,而图像所表达的基本信息也没有丢失。
本文结合SURF和HOG特征提取图像局部特征,并通过邻域粗糙集的特征选择算法[7]对冗余特征进行剔除;其次,对选择后的特征聚类分析,构建图像的视觉词典,通过统计合并直方图生成对图像的视觉描述。本文方法剔除了图像中的冗余特征,减少了视觉词典的大小,在常见的两类数据集Caltech101和Corel-1000上验证了该方法的有效性。
1 特征提取
HOG(Histogram Of Gradient)特征利用相互重叠的局部对比度归一化技术来表征图像局部目标的表象和形状,是描述边缘和形状信息最好的特征之一。HOG特征的提取通过计算图像局部区域的梯度方向和统计直方图来构成特征。首先,将图像分成相同大小的像素块(cell),计算每个cell中各像素点的梯度大小及方向;然后,连接相邻的几个单元(如2×2个)形成block块,统计每个block块的直方图,对每个block内的直方图归一化,以进一步消除光照和阴影影响;最后,将整幅图像的所有特征串联得到图像的HOG特征。图像的HOG特征描述子如图1所示。

图1 图像的HOG特征描述Fig.1 HOG feature description of image
SURF(Speeded Up Robust Features)是一种局部特征描述子,通过每个像素点Hessian矩阵判别式的正负以及该像素点是否为极值点来确定图像中的特征点。SURF算法和SIFT算法类似,同样拥有尺度不变特性,但计算速度和鲁棒性比SIFT好。SURF最大的特点在于运用了积分图像的概念以及统计特征点区域范围内的harr特征,这大大加快了程序的运行时间。图像的SURF特征描述子如图2所示。

图2 图像的SURF特征描述Fig.2 SURF description of image
2 本文提出的方法
2.1 基于邻域粗糙集图像特征选择算法基本定义
传统邻域粗糙集只能处理m×n二个维度的知识表达系统(m表示样本的个数,n表示每个样本特征的个数),但本文图像特征表达系统是m×n×k三个维度的(m表示图像个数,n表示每张图像特征的个数,k表示每个特征描述子个数)。因此需要将传统的邻域粗糙集的知识表达系统扩展,使其特征选择方法也可用于图像特征表达系统中。将邻域粗糙集的基本概念扩展到图像知识表达系统中,基本定义如下。
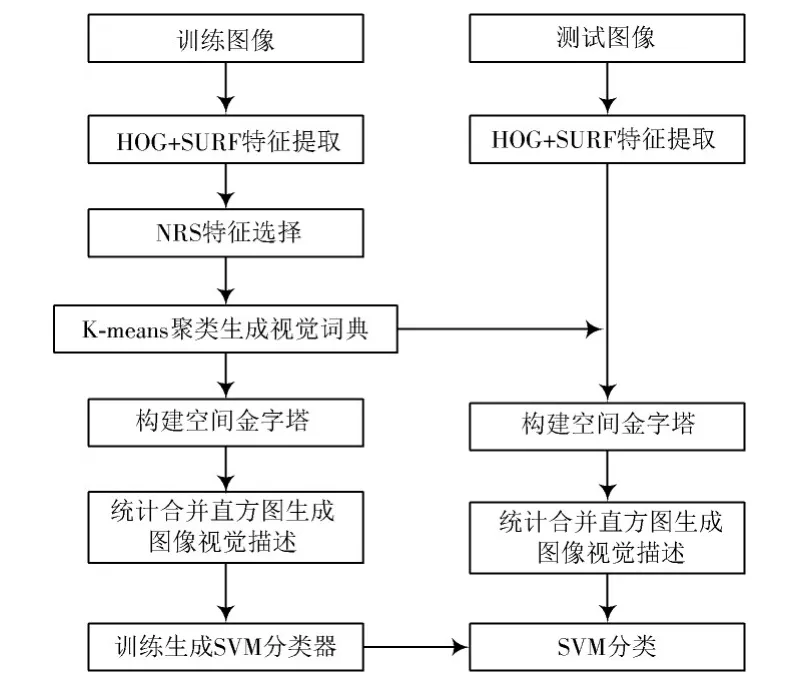
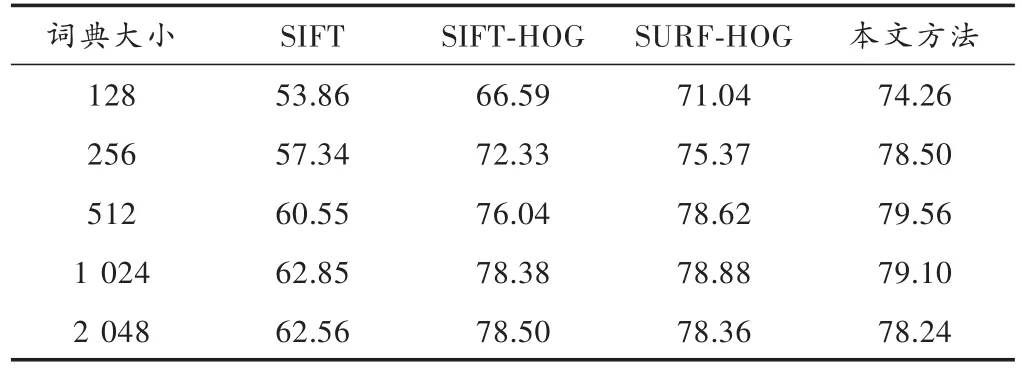
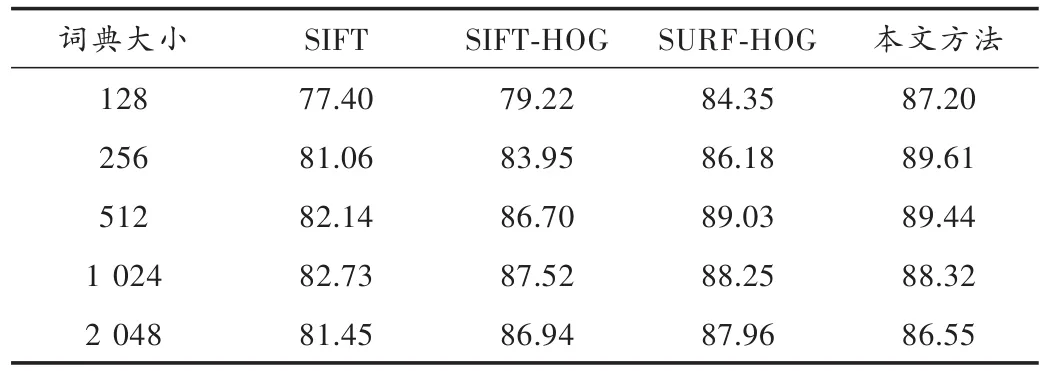
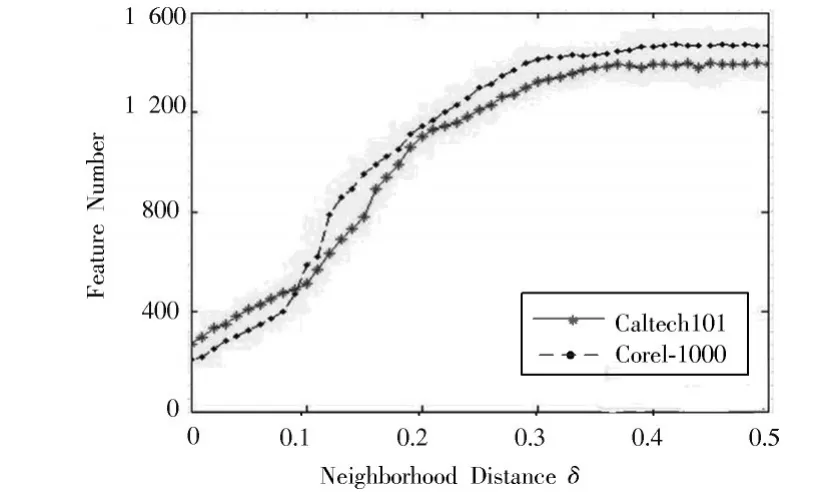
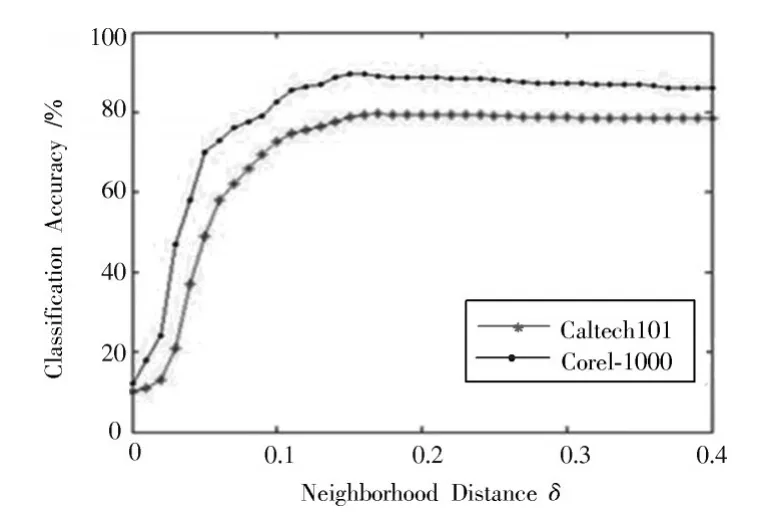
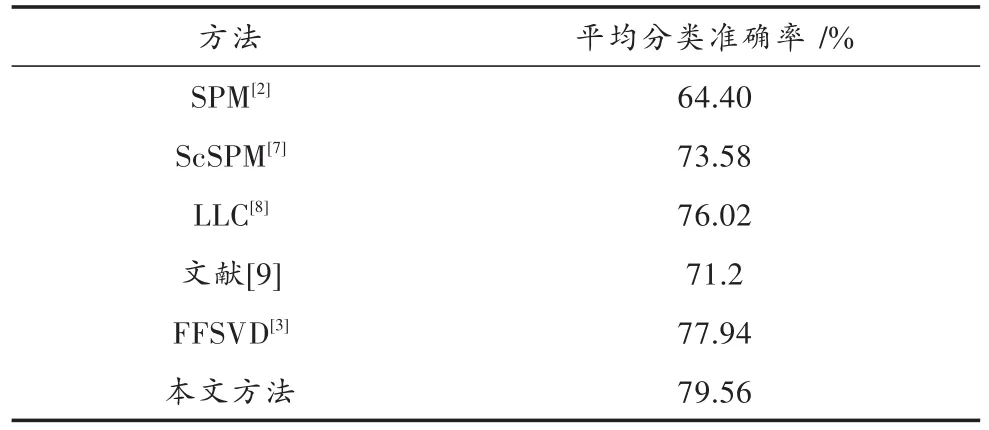
定义1图像知识表达系统NTD= 邻域粗糙集中可以通过特征之间的距离来度量样本的相似性即样本的邻域,同样图像特征表达系统中也可以通过特征之间的距离来度量图像的相似性。图像决策系统的邻域及距离函数公式见定义2,但是相似的图像不一定属于同一类图像。定义3根据邻域中图像样本类别的差异,将其分为一致邻域和不一致邻域。 定义2图像特征表达系统中图像ui的δ邻域为:δ(u|Δ(u,ui)≤δ)。Δ为距离函数,本文采用的距离函数为切比雪夫距离(无穷范数): 相同的邻域半径下,切比雪夫距离(无穷范数)表示的邻域范围最大,且计算简单。 定义3图像样本u的一致邻域定义为:图像样本u的邻域中类别相同的图像,即对于∀ui∈δC(u),δC(u)∩δD(u);反之,图像样本u的不一致邻域定义为:图像样本x的邻域中类别不同的图像,即对于∀ui∈δC(u),δC(u)-δD(u)。 定义4文献[6]定义了NTD= 条件熵: 由定义3和定义4可知,图像特征表达系统的条件熵和其图像样本的不一致邻域相关。在每个特征下图像的不一致邻域个数越多,条件熵越大,该特征就与图像的类别越不相关;反之,条件熵越小的特征,就和图像类别越相关。通过条件熵可以反映出特征与图像之间的相关程度。基于邻域粗糙集的图像特征选择算法的具体步骤如下。 输入:图像知识表达系统NTD= 输出:图像知识表达系统的特征约简集red。 步骤1:依据式(3)可计算出图像知识表达系统NTD= 步骤2:依据式(3)计算E(D|red∪{Xi})的条件熵,找出条件熵最小的特征Xi,将Xi加入到red中; 步骤3:计算E(D|red∪{bi})是否等于E(D|C),若相等则输出特征约简集red,若不等,则返回执行步骤2。 本文的图像分类方法在特征提取阶段,通过HOG描述子和SURF描述子相结合,实现优势互补形成SURF和HOG特征集来构造图像知识表达系统。用基于邻域粗糙集的特征选择算法对图像知识表达系统中的冗余特征进行剔除,得到新的特征集。利用K-means聚类方法对训练图像的新特征集进行特征聚类生成视觉特征词典,每个聚类中心为视觉特征词。构建三层空间金字塔模型,根据生成的视觉特征词典,统计合并训练集和测试集每幅图像空间金字塔的加权视觉特征直方图(权重依次为[14,14,12])训练线性SVM分类器对测试图像进行分类。图像分类结构框图如图3所示。 图3 基于邻域粗糙集特征选择的图像分类框架Fig.3 Image classification framework based on feature selection of neighborhood rough set 为了验证本文图像分类方法的有效性,在Caltech101数据集和Corel-1000数据集上进行验证。在这两个数据集上分析了不同特征提取算法与不同视觉词典大小对分类准确率的影响,以及特征选择算法邻域距离对特征个数和分类准确率的影响,对比本文算法与其他主流算法的分类结果。 Caltech101数据集共有9 144幅图像,共101个目标类和一个背景类。每类的图像个数并不相同,目标大多都在图像的中间部分,占图像的比例较大,且部分图像是通过平移、旋转等变化形成的。 Corel-1000数据集包含10个不同语义类的自然图像,每类均有100幅,共1 000幅图像。图4和图5分别展示了Caltech101和Corel-1000数据集的部分图像。 图4 Caltech101部分图像Fig.4 Partial images of Caltech101 图5 Corel-1000部分图像Fig.5 Partial images of Corel-1000 将所有图像都处理为灰度图像,然后将图像像素大小统一调整为256×256。本文从Caltech101数据集每个类中随机选择30幅图片作为训练图像,其余作为测试图像;从Corel-1000数据集每个类中随机选择70幅图片作为训练图像,其余作为测试图像。 3.3.1 空间视觉词典个数及特征提取方法对分类准确率的影响 本次实验分别采用128,256,512和1 024这4种不同大小的视觉词典。从表1可看出,在数据集Caltech101上视觉词典大小为512时获得的准确率最高,256时次之,128时最低。这是因为数据量大,数据集种类多,相似的特征词的种类较多,造成准确率较低。视觉词典大小为1 024与512结果略低,是因为字典太大会使相似的特征表示为不同的特征词,分类结果反而有所下降。词典大小对数据集Corel-1000实验结果的影响原理同上所述,影响结果见表2。不同的是该数据集数据少,类别也少,因此在视觉词典大小为256时取得的分类效果最好。 表1 Caltech101上词典大小和特征提取方法对分类结果的影响Table 1 Influence of dictionary size and feature extraction methods on classification results of Caltech101 表2 Corel-1000上词典大小和特征提取方法对分类结果的影响Table 2 Influence of dictionary size and feature extraction methods on classification results of Corel-1000 3.3.2 特征选择算法参数选取对图像分类的影响 特征选择的结果与邻域距离δ的选取有关。邻域距离δ取不同值时,特征选择的个数也会不同。根据图像SURF和HOG特征值的范围,本次实验δ的取值从0~0.5,步长取0.01,来验证邻域距离δ的选取对特征选择个数以及对分类准确率的变化趋势。特征选择之前每幅图片SURF特征个数范围为:200~600,HOG特征961个,图像的SURF特征归一化长度为600。 图6和图7分别表示图像特征知识表达系统的特征选择后的特征数量及分类准确率随δ的变化趋势。由图可知,当δ在0~0.1时,图像在每个特征下的不一致邻域个数较少,条件熵也较小,剔除的特征比较多,这样会造成图像分类准确率不高;当δ在0.3~0.5时(δ在0.3以后分类准确率大致保持不变,故图7中δ的范围取0~0.4),图像在每个特征下的不一致邻域个数较多,每个特征的条件熵都较大,因此剔除的特征较少,分类结果与没有使用特征选择相似,没有达到剔除冗余特征的效果。可以看出,δ的范围取0.15~0.2时分类精度较高,剔除的冗余特征也较多,在0.17时取得最好效果。综上分析,δ选0.17比较合适。 图6 特征数量随δ的变化情况Fig.6 Variation of feature number with δ 图7 分类准确率随δ的变化情况Fig.7 Variation of classification accuracy with δ 3.3.3 本文方法与其他主流方法平均分类准确率对比 本文方法是将更具互补性的SURF和HOG特征融合后,通过信息观下基于邻域粗糙集的图像特征选择算法剔除图像中的冗余特征。表3和表4分别表示其他主流方法及本文方法在Caltech101数据集上和Corel-1000数据集上的平均分类准确率。特征选择算法邻域距离函数δ选择为0.17,视觉词典大小分别为512,256。 由表3可知:在Caltech101数据集上,SPM的平均分类准确率为64.40%;ScSPM平均分类准确率为73.58%;LLC平均分类准确率为76.02%;文献[9]方法的平均分类准确率为71.2%;文献[3]中的FFSVD的平均分类准确率为77.94%;本文方法的平均分类准确率为79.56%,优于其他主流方法。由表4可知:在Corel-1000数据集上,在文献[10]中的方法平均准确率为84.4%;文献[11]中的分类算法平均准确率为85.1%;文献[12]的W-MR-MS方法平均准确率为86%;文献[13]的分类方法平均准确率为86.57%;本文的图像分类算法的平均准确率为89.61%。因此,本文图像分类算法具有较高的准确率。 表3 Caltech101分类准确率对比Table 3 Classification accuracy comparison of Caltech101 表4 Corel-1000上分类准确率对比Table 4 Classification accuracy comparison of Corel-1000 本文提出一种SURF-HOG特征融合与邻域粗糙集特征选择相结合的图像分类方法。先提取图像的SURFHOG特征,然后采用基于邻域粗糙集的图像特征选择算法得到约简后的图像特征集,对约简后的图像特征集用K-means聚类算法生成视觉特征词典,统计空间金字塔模型每个尺度图像每个视觉特征词的个数,将获得的直方图都串联起来,并且给每个尺度的特征赋予相应的权重,将得到加权直方图放入线性SVM分类器中训练和预测。通过实验验证,该方法在图像目标分类中有很好的性能,并且在多分类的图像数据集上,仍具有良好的鲁棒性;但对于复杂场景下的多目标分类本文方法的结果不够理想,这是需要进一步解决的问题。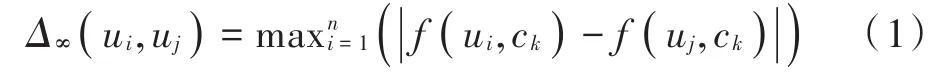
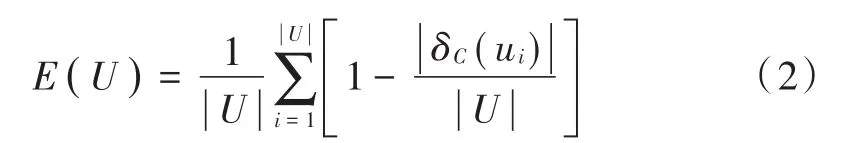
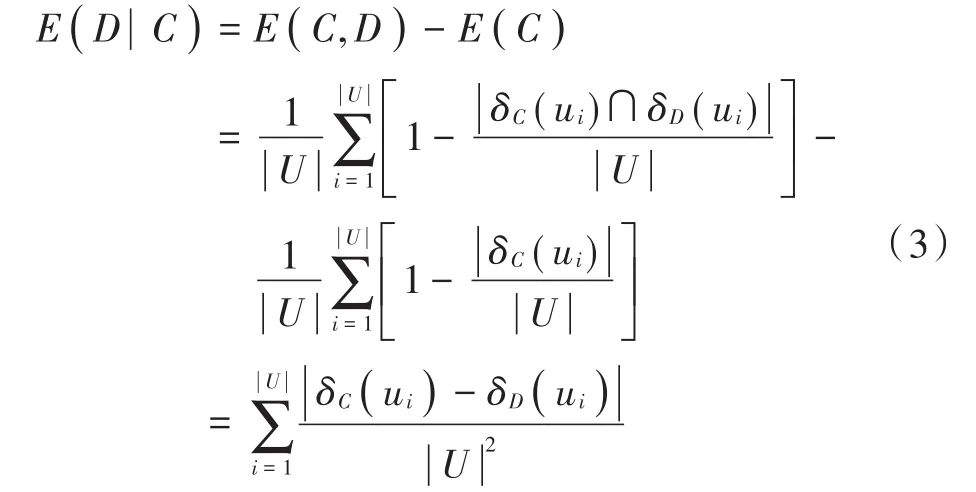
2.2 基于邻域粗糙集图像特征选择算法
2.3 基于邻域粗糙集图像特征选择的图像分类方法
3 实验与结果分析
3.1 实验数据集


3.2 实验设置
3.3 实验结果

4 结语



