热衣扎·哈那提,努尔布力
(新疆大学信息科学与工程学院,新疆乌鲁木齐 830046)
0 引 言
语音合成技术作为人机语音交互的核心技术,被越来越多的研究者给予关注和重视。语音合成技术的发展已有几十年的历史,取得了很多优秀的研究成果。虽然国内很多专家从不同的视角对语音合成进行了总结和综述,但还没有从知识图谱的角度对语音合成领域进行总结分析。鉴于此,本文利用CiteSpace 工具对通过Web of Science 平台收集到的关于语音合成的核心文献进行计量分析并绘制知识图谱,从宏观角度阐述以下两个问题:国内外近20 年来在语音合成领域的研究概况以及主要研究热点。
1 数据来源和研究方法的说明
1.1 数据来源
本文研究的文献来源于信息检索平台Web of Science的核心数据库,数据采用以下的方式收集:
1)标题词检索方法:TI=“speech synthesis”OR“text to speech”OR“voice synthesis”OR“concept to speech”OR“intention to speech”OR“text to voice”;
2)时间跨度:1999—2018 年;
3) 文献类型:期刊(ARTICLE)和会议论文(PROCEEDINGS PAPER)。共得到1 846 篇关于语音合成领域的核心文献并下载每个文献的28 条记录信息,包括标题、作者、摘要、关键词、参考文献等。
1.2 研究方法的说明
本文主要采用计量分析和图谱分析方法,通过它们揭示相关领域的知识来源和发展规律,并把知识结构关系和演化规律用图形的方式呈现出来。可视化工具CiteSpace 就是可以用于追踪研究领域热点和发展趋势的文献计量分析工具。本文通过CiteSpace 对1 846 篇文献进行研究机构的合作网络分析、研究热点的演化分析以及高共被引文献的统计分析。
2 研究概况
2.1 主要研究机构分析
通过对语音合成领域的文献发表量的研究机构进行基本情况统计后发现发文量超过9 篇以上的机构有18所。表1列出的是文献量排名前10的研究机构。图1是研究机构直接的合作网络关系图,其中连线代表两个研究机构之间有合作关系;文字大小代表发文量的多少,文字越大发文量越多,文字越小发文量越少。
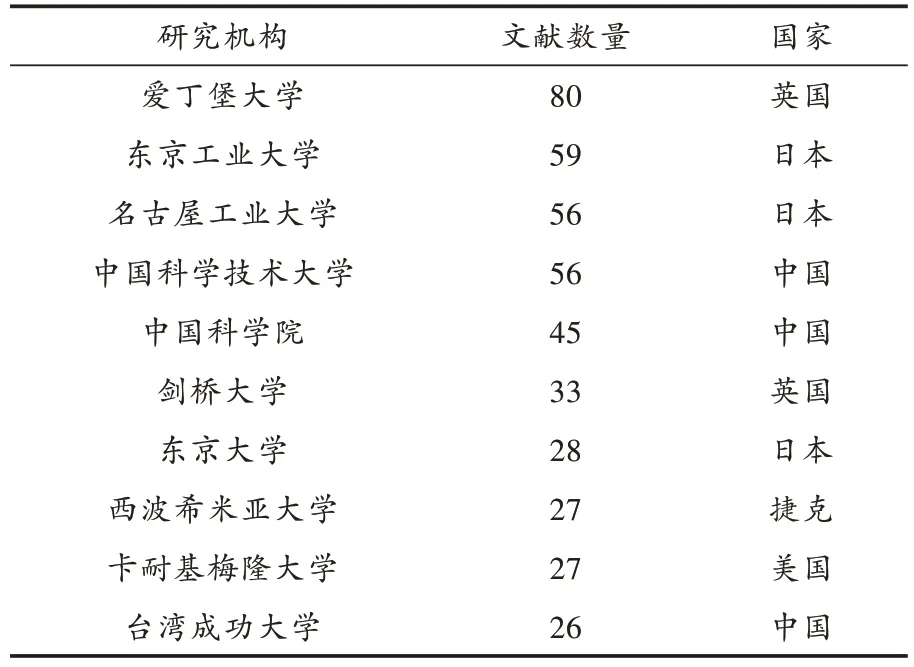
表1 发文量Top10 的研究机构Table 1 Publications of Top10 research institutions
通过表1 得知,Top10 榜单里的研究机构共来自5 个国家,分别是日本3 所,中国3 所,英国2 所,捷克和美国各1 所。通过对国家发文量的统计,发现日本在语音合成领域里发表的文献量居世界首位,中国和美国的发文量分别排在第二位和第三位。
2.2 主要作者分析
根据基本统计分析,研究文献共涉及到的作者中,发文量超过10 篇的作者有58 位,发文量超过20 篇的作者有16 位。发文量排名前10 的作者如表2 所示。
通过表2 的首次发文年份的分布来看,高产作者的首次发文年份最早是从2003 年开始的。发文量最多的作者是Yamagishi J,表3 列出的高被引文献里该作者的文献有3 篇,该3 篇文献都与隐马尔科夫模型有关,并结合他的其他文献分析发现,该作者的研究重点主要集中在基于隐马尔科夫模型的语音合成,而从他近几年的文献分析发现他现在的研究重点转向神经网络的研究,该作者在2018 年与Wang X 等人合著的一篇文献主要研究了深度神经网络在统计参数语音合成中的性能[1],特别是深层网络能否更好地产生不同声学特征的问题。排在第二位的是作者Tokuda K,该作者在2018 年发表的文献[2]里提出了一种基于梅尔倒谱的量化噪声整形方法,提高了基于神经网络的语音波形合成系统的合成语音质量。作者Kobayashi T 发文量排在第三位,文献[3]是他近几年与Nose T 等人合作的一篇文献,该文献里提出了一种用于语音合成和韵律平衡的紧凑记录脚本的句子选择技术,与传统的句子选择技术相比,该技术所生成的语音参数更接近自然语音的语音参数。
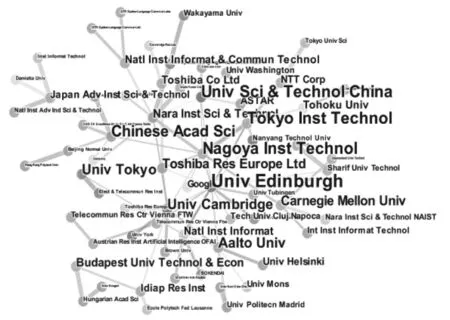
图1 研究机构合作网络图Fig.1 Co-research network graph of institutions
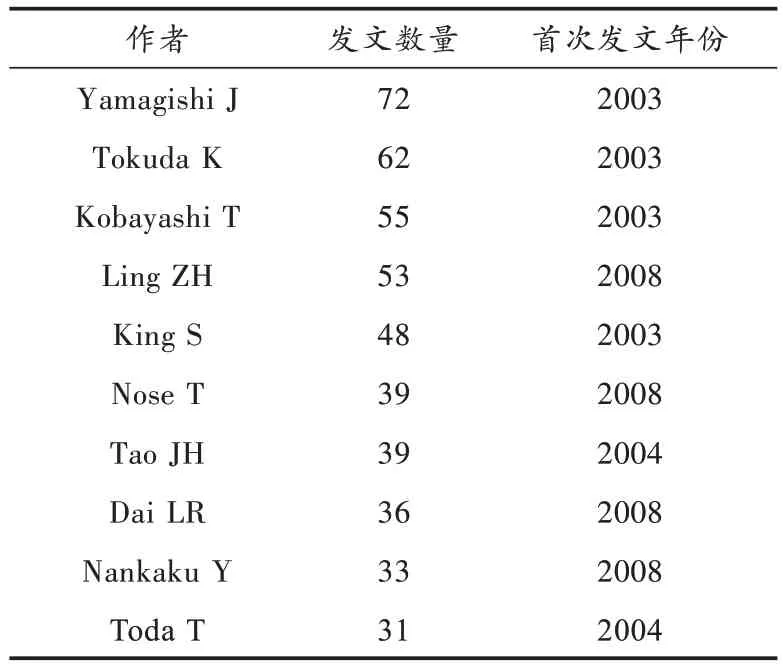
表2 高频作者Table 2 High frequency authors
2.3 高被引文献分析
高被引文献是一个研究领域的重要知识来源,反映某一学科的研究水平、发展方向,是探究热点主题、研究演化的重要依据[4]。表3 列出的是被引频次较多的10 篇文献,被引频次主要来自于本论文研究的数据。
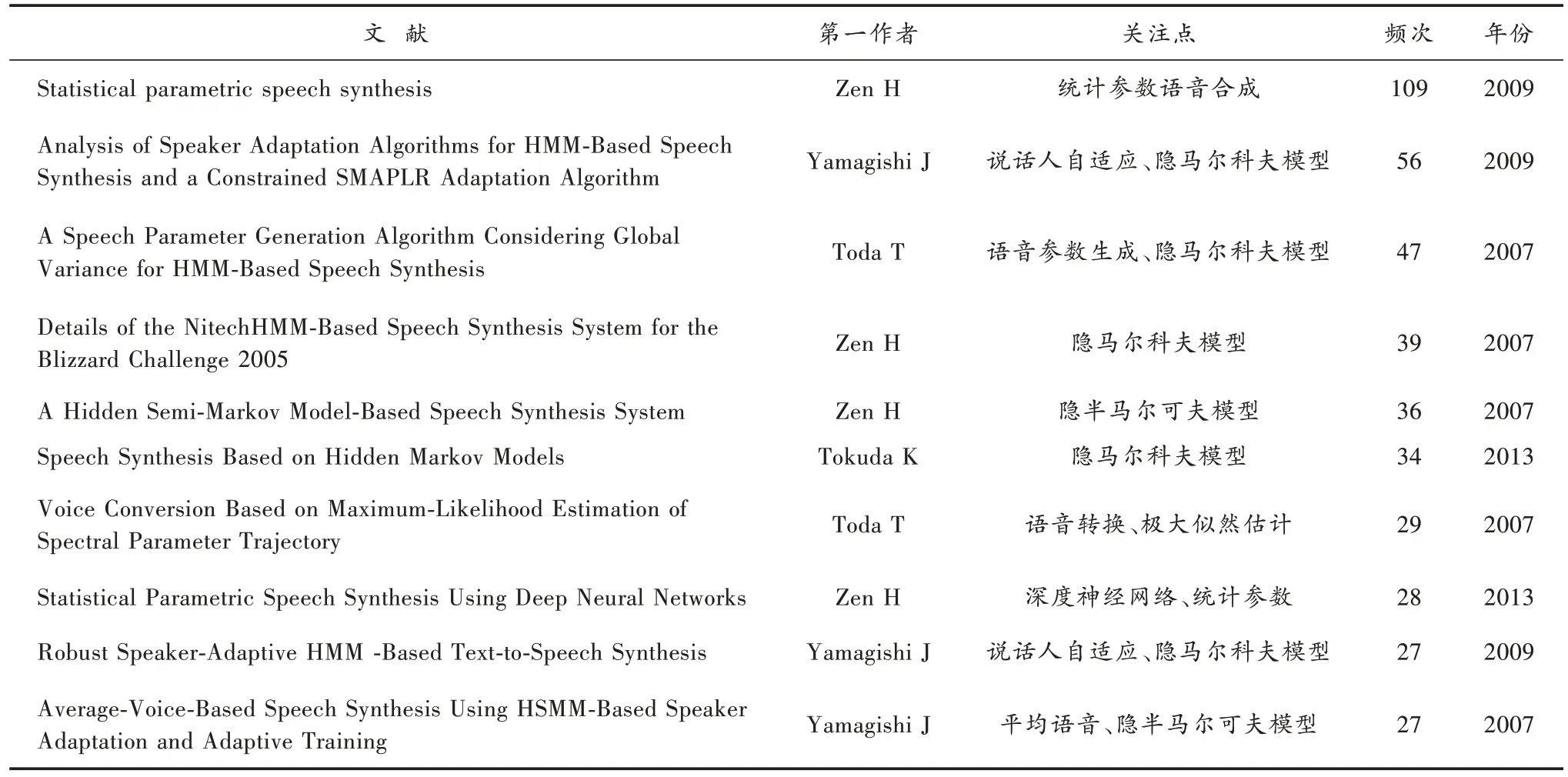
表3 被引频次较多的文献Table 3 Literatures that has been cited frequently
作者Zen H 等人发表的文献《Statistical parametric speech synthesis》的被引次数最多[5],该文综述了统计参数语音合成中常用的技术,对统计参数语音合成技术和传统的单元选择合成技术进行比较,总结了统计参数语音合成的优点和缺点并对未来工作进行展望。作者Yamagishi J 等人发表的文献[6]排在第二位,本文提出新的适应算法约束结构最大线性回归,该方法在语音合成中获得了更好、更稳定的说话人自适应,具有很强的实用性和有效性。文献[7-8]是表3里2013年发表的两篇文献,文献[7]讨论了基于隐马尔科夫模型的语音合成技术在改变说话者身份、情感和说话风格方面的灵活性;文献[8]提出基于深度神经网络的统计参数语音合成方法,使用深度神经网络来解决传统统计参数语音合成方法的一些局限性。
通过表3的关注点来看,基于隐马尔科夫模型的语音合成技术是语音合成领域的重点语音合成技术,说话人自适应技术成为语音合成领域较为重要的研究技术,而深度神经网络是近几年语音合成领域里使用的新兴技术。
3 研究热点
关键词是文献主题内容的高度提炼,对关键词出现的变化进行分析可以了解各时期的研究热点[9]。表4 列出的是频次较多、中心性较高、激增值较大的按首次激增年份排序的关键词。
1)频次(Freq)指标计量分析
通过图2,频次较多的关键词“hidden markov model”“text to speech”“unit selection”的首次研究年份集中在1999—2002 年,这些研究为语音合成技术的发展奠定了基础。到2005 年,关键词“hmm-based speech synthesis”出现,隐马尔科夫模型被用到语音合成研究里面,基于隐马尔科夫模型的语音合成技术从该时期开始研究。到2006 年,语音转换技术应用到语音合成领域里,进一步促进了语音合成技术的发展。
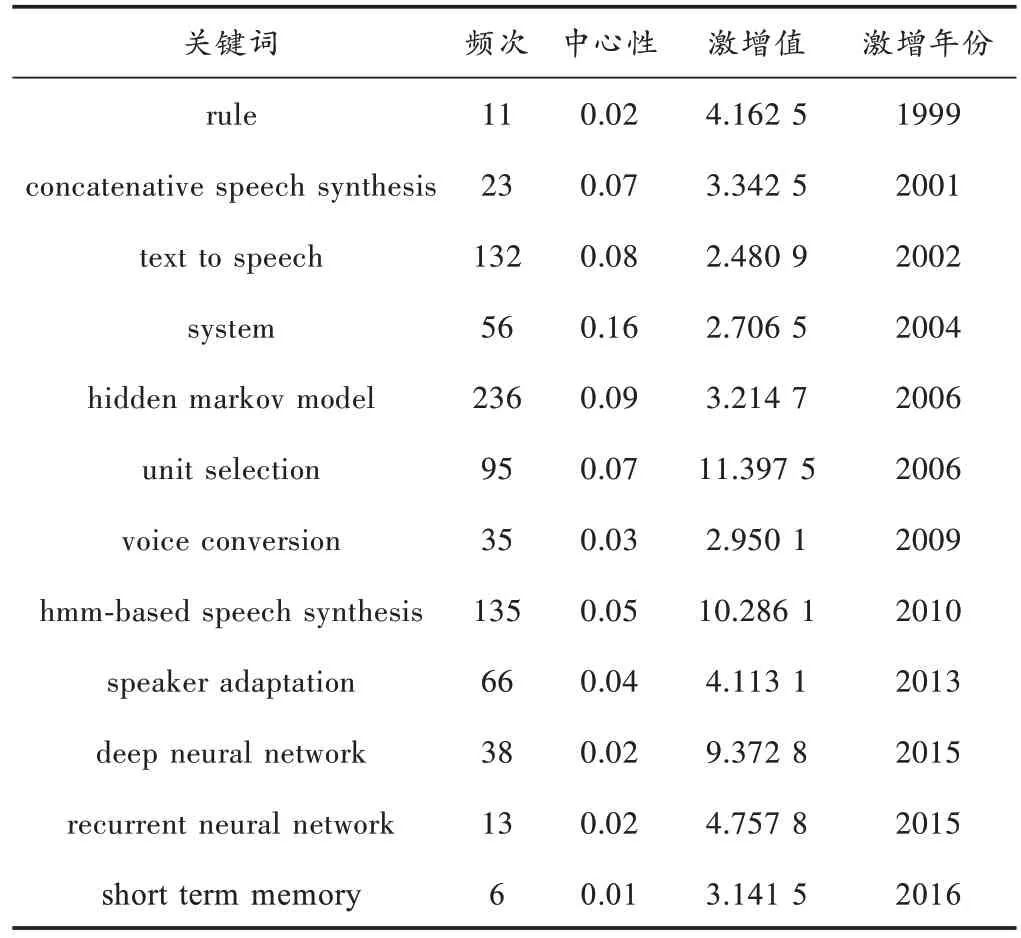
表4 关键词Top12 的排名统计Table 4 Rank statistics of keywords in Top12
2)中心性(Centrality)指标计量分析
通过表4 的关键词的中心性结合图2 发现,“system”“hidden markov model”“text to speech”等关键词的中心性相比其他关键词的中心性较高,首次出现的年份较早,该结果表示系统、隐马尔科夫模型和文本到语音的研究在语音合成领域里研究的时间较长,是较为重要的研究方向。关键词“speaker adaptation”“concatenative speech synthesis”“unit selection”的中心性都大于0.02,说话人自适应是语音合成技术的核心研究部分,级联语音合成受单元选择中使用的单元的库存支配达到高度自然的合成语音质量,单元选择是语音合成领域一个较为重要的研究热点,文献[10]提出的基于隐马尔科夫模型的语音合成方法就用到单元选择。
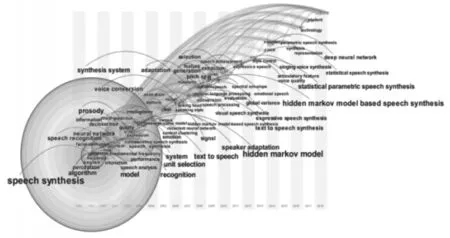
图2 关键词时间分布图Fig.2 Time distribution diagram of key words
3)激增(Burst)指标计量分析
激增指数的关注点是单个主题的自身发展变化过程,可以展示热点主题的凸显性。通过表4 关键词的激增值和开始激增年份发现,1999—2005 年主要的研究主题是围绕规则、文本到语音和语音处理等,该时期的大部分研究工作都在基础的核心部分研究;2006—2014 年,研究主题的关注点在语音合成技术的模型,基于隐马尔科夫模型的语音合成技术成为重点,语音转换和说话人自适应技术受到了前所未有的重视;2014—2018 年,神经网络成为语音合成领域重要的研究方向,深度学习在语音合成领域的应用进一步促进该领域的快速发展。
通过前文的分析和研究发现,数据可视分析研究的发展分为三个阶段:1999—2005 年,初步发展时期;2006—2014 年,快速发展时期;2015 年—至今,深入发展时期,如表5 所示。
4 结 语
国际语音合成领域的研究文献质量不断在稳步提升,日本、中国和英国的一些研究机构在国际上发文量多,与其他研究机构合作关系较密切。基于隐马尔科夫模型的语音合成是该领域的研究重点,而近几年语音合成领域开始使用神经网络技术,解决传统语音合成方法遇到的问题。目前,语音合成领域的研究越来越多,分支越来越细,在未来的发展上,语音合成领域的研究将不断深入,会有越来越多不同领域的技术应用到语音合成领域。

表5 阶段分析表Table 5 Stage analysis list



