张妮妮 孙胜娟 张永健
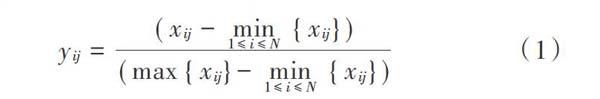

摘 要: 随着人们对知识产权的重视,作为其重要表征的专利的数量呈现爆发式增长,然而专利的质量却没有随之增长。大量的低质量专利不但作用有限,反而会造成社会资源浪费和遏制创新。对于专利质量的评价,目前还没有统一的标准。文中首先对国内外的专利质量指标进行分析,选取出对专利质量影响较大的指标,构建专利质量评价指标模型。同时,以钢铁行业相关专利为目标数据集,分别采用未确知聚类和模糊均值聚类算法对目标专利质量进行分析评价。最终,将目标专利数据聚类出不同的级别,得出高质量专利。在聚类过程中,发现未确知聚类算法在效率和准确率上都有良好的表现。
关键词: 专利质量评价; 未确知聚类; 专利数据分析; 评价模型构建; 数据集聚类; 对比实验
中图分类号: TN911?34; TP311.52 文献标识码: A 文章编号: 1004?373X(2020)08?0143?04
Application of unascertained clustering in patent quality evaluation
ZHANG Nini, SUN Shengjuan, ZHANG Yongjian
(School of Information and Electrical Engineering, Hebei University of Engineering, Handan 056001, China)
Abstract: With people′s attention to intellectual property, the quantity of patents, as an important symbol of intellectual property, has increased explosively, but the quality of patents has not increased with it. A large number of low?quality patents not only play a limited role, but also lead to the waste of social resources and inhibit innovation. Nowadays, there is no unified standard for the evaluation of patent quality. The domestic and foreign patent quality indicators are analyzed, from which the indicators that have a greater impact on the quality of patents are selected to build the patent quality evaluation index model. With the related patents in steel industry as the target data set, the analysis and evaluation of the target patent quality are performed by means of the unascertained clustering algorithm and fuzzy mean clustering algorithm, respectively. The target patent data is clustered into different levels to obtain high?quality patents. During the clustering process, it is found that the unascertained clustering algorithm has good performance in efficiency and accuracy.
Keywords: patent quality evaluation; unascertained clustering; patent data analysis; evaluation model building; dataset clustering; contrast experiment
0 引 言
随着科学技术的进步与发展,人们对知识产权的重视程度越来越高[1]。根据2018年12月3日世界知识产权组织发布的《2018年世界知识产权指标》显示,我国在全球专利、商标和工业品外观设计等专利申请量上均位居第一。专利总数越多,质量就会参差不齐,大量的低质量专利反而会为社会带来许多弊端。
国内目前对专利质量评价的研究中,有学者研究显示专利引证指标和专利权利范围指标所占权重最高,其次是专利地域范围指标、技术应用范围和科学关联度指标[2]。在对具体领域的专利质量进行分析的时候,包英群等学者遵循普适性、简洁性和可行性的原则选择出针对液晶显示产业的质量评价指标为专利引证指标和同族专利数指标[3]。
本文通过对专利的各个指标分别进行讨论分析,从理论上评选出与专利质量相关性较大的指标,建立专利质量评价指标体系。选取Derwent数据库的钢铁行业相关专利为目标数据集,用未确知聚类算法对目标专利进行评价,得出核心专利。
1 专利质量评价指标
对于专利质量的评价,国内外目前还没有一套相对科学合理的专利质量指标评价体系[4]。
1.1 专利引证指标
专利引证信息是专利发展的“脉络”,从中能看出被引用专利和引用专利,国外论文通常称前引(Forward Citation)和后引(Backward Citation),以当前专利为标准点,当前专利被其他专利引用称为前引,当前专利引用其他专利称为后引。国内外把专利引文分析当作专利价值和技术地位的重要指标,对专利引文的研究层出不穷[5]。其中包括对专利引文地图的研究和引文次数的探讨[6?7]。所以,本文选取前引用专利指数和后引用专利指数作为专利质量评价的两个指标。它们与专利质量正相关,即前引用指数或后引用指数越大,说明专利质量越高。
1.2 专利权利范围指标
专利的权利范围指标通常是指权利要求的数量。学者在对专利价值和质量的研究中用到了专利权利要求数这一指标,乔永忠等选取部分专利文献信息并构建回归模型进行分析,证明专利权利要求数量对专利价值有正向影响,与专利的价值正相关[8]。所以,专利权利要求数量与专利质量正相关,即越重要的专利其权利要求数量越多。
1.3 专利地域范围指标
专利地域范围指标是指专利族的大小,同一个专利在不同国家申请的专利保护称为一个专利族。在企业全球化和地球村的影响下,专利拥有人或企业为了提升自己的竞争力,会将核心专利技术在多国申请专利法的保护。基于经济价值角度来看,只有在专利的价值和质量相对较高的时候,申请人才会考虑在不同的国家申请该专利的法律保护,这样成本和价值才匹配。可见,专利族的大小同时反映了专利的质量和价值的高低[9]。
所以,结合科学性、可行性和可比性的原则,评选出有效的专利价值评价指标为:专利引文数、同族的专利数和专利的权利要求数。
2 专利质量评价算法
在对专利质量指标权重的确定中,通常是以统计方法去计算每个指标对专利质量的影响程度或采取专家打分的方法。这两种方法为专利质量评价做出了很大的贡献,可也有其局限的地方。前者的权重可能与所选取的样本专利直接相关,后者的结果会与专家的主观意识相关,得到的权值数据也会有差距。在核心专利之间,应该存在着某些共同特征。由于数据量的巨大,没办法用人工的方式来对专利等级进行区分,所以采用聚类来研究。
在聚类算法中,选择了对数据离群点有较好处理能力并不需要人为干预的未确知聚类算法,同时,用经典的模糊均值聚类算法与其进行分析对比实验。未确知聚类是一种无监督的聚类算法,该算法基于未确知理论而提出[10]。
3 对比实验
实验的计算机环境为:处理器Intel 酷睿(TM)i7 2.6 GHz,运行内存为 16 GB,硬盘为160 GB,操作系统为 Windows 10,编程语言为 Python 3.6,数据库为MySQL 5.0。
3.1 数据集
本文实验数据来源于Derwent数据库中的钢铁行业相关专利共45 146条,专利时间从1967年到2013年,检索出与本文相关的字段。
3.2 实验步骤
该实验步骤如下:
1) 首先,输入目标专利数据集,随机打乱该数据集的顺序;
2) 分别用UMC算法和FCM算法对该数据集进行聚类,通过对数据中的被引用次数、引用次数、同族专利数和权利要求数4个指标判断目标专利属于哪一个等级,将所有数据分为5类;
3) 输出聚类结果;
4) 计算并输出程序运行时间。
未确知聚类的计算过程如下:
1) 数据标准化。将专利数据的4个质量指标用以下公式取值界定在0与1之间,具体如下:
式中:[xij]为专利i的第j个特征指标的原始值;运算结果[yij]为专利i的第j个特征指标的标准化值。
2) 给出专利数据的一种初始分类并计算出类中心。
式中:
sum(i)为专利i的所有特征指标的标准值之和。
计算出和J+1距离最近的正数k,且将专利[yi]分配到第k类,最终,将N个专利样本分为C类,即给出一种初始分类方式,并根据该初始分类方式计算出各类的类中心[m(0)k(1≤k≤C)]。
3) 根据这C个专利数据初始类的类中心[m(0)1,m(0)2,…,m(0)C],计算得到专利数据集初始分类的均值类。在该步骤中,根据已经给定的初始分类方式,计算出j专利特征属性对专利分类所做的分类贡献度:
由式(3)得到的专利分类贡献度计算每个专利属性的分类权重:
通过得到的专利属性的分类权重,根据式(5)计算出每个专利属性特征的加权距离:
由式(5)计算得到各个专利属性的加权距离大小后,需要计算出其相应的基本隶属度:
式中,取[ε=0.01]。
4) 根据计算的N个专利样本的未确知隶属度之后,可以算出这N个专利样本对应每个特征指标所度量的确定分类。将[u(0)Γk(yi)]作为样本点[yi]关于[Γk]类的点质量赋予点[yi],最终,N个质点构成的质点组[{(y1,uΓk(y1)),(y2,uΓk(y2)),…,(yN,uΓk(yN))}]的质心可按物理方法确定,即每个质点对应的隶属度向量为:
根据这一步骤得到第一次迭代后的类中心[m(1)1,m(1)2,…,m(1)C]。以[m(1)k(1≤k≤C)]替代[m(0)k],再次返回步骤2),继续迭代。
当计算得到[maxm(t)k-m(t-1)k<δ]的情况下,停止上述的迭代,共迭代t次,输出结果为C个类的类中心[m(t)1,m(t)2,…,m(t)C,m(t)k]是[Γk]的类中心。至此,对N个专利的d维特征指标空间中的样本点,在没有其他分类信息条件下,完成了聚类,得出了C个类中心的中心向量。
3.3 实验结果
使用UMC和FCM两种聚类算法对目标专利数据集进行聚类的结果如表1所示。
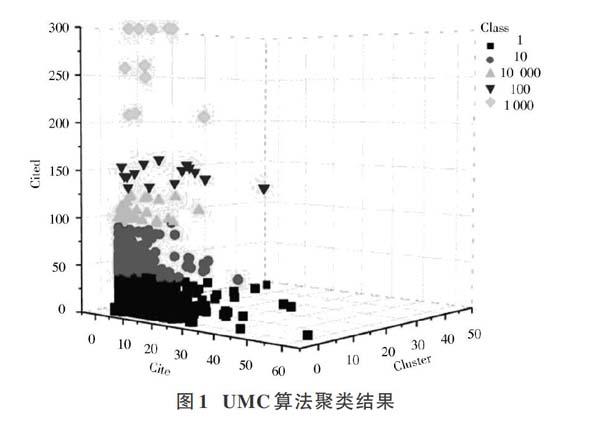
在表1中列出了两种聚类算法的聚类类别编号及该编号下聚类的专利数量。其中UMC算法的平均执行时间为:4.5 s,FCM算法的平均执行时间为:570.9 s。可以看出,UMC算法执行时间比FCM算法执行时间快了超过100倍,其主要原因是采用UMC算法收敛速度快,相应其迭代次数就少,所以运行速度比FCM算法快了两个数量级。同时,根据聚类输出的结果,用3D图的方式展示如图1、图2所示。
图中,分别选取Cited(被引用次数)、Cite(引用次数)和同族专利数为z,x,y轴,图中球体的颜色代表不同的类别。根据两种聚类算法的结果对比可以看出,由于被引用次数在目标专利的指标中的数字相对于其他三个指标(引用次数、同族专利数和权利要求数)较大,所以两种算法中被引用次数对分类所做的贡献都比较大,所占权值也较高。同时,除了被引用数在聚类中所占权值最大外,其次是专利引用数、同族专利数和各个专利的权利要求数。根据聚类结果的显示结果,编号为“1 000”的共11个专利为UMC算法聚类出来的核心专利,核心专利组的前引用数平均达到262.82次,专利的时间从1995—2009年都有分布,符合预期的质量指数标准。
4 结 论
本文通过对专利各指标的分析讨论及结合科学性、可行性和可比性的原则,建立专利综合评价指标模型。在对专利的综合评价中,通过对数据的分析得出结果,去除了人为的干扰,能较为客观地反应专利质量信息。在对核心专利进行评价的过程中,未确知聚类算法在运行效率和聚类结果方面都有良好的表现,是基于未确知理论应用的新探索,在专利分析与评价方面取得了有意义的创新成果。该课题研究所存在的问题是由于要符合计算机大量计算的前提,在评价指标方面对比人工处理有一定的局限性。
注:本文通讯作者为张永健。
参考文献
[1] 田立新,文尚胜.中国OLED应用专利态势分析与研究[J].现代电子技术,2014,37(19):153?156.
[2] 吕晓蓉.专利价值评估指标体系与专利技术质量评价实证研究[J].科技进步与对策,2014(20):113?116.
[3] 包英群,鲁若愚,熊麟.全球液晶显示产业专利质量评价[J].技术经济,2015,34(4):3?8.
[4] 谷丽,郝涛,任立强,等.专利质量评价指标相关研究综述[J].科研管理,2017(z1):35?41.
[5] 吴红,冀方燕.基于专利申请及审查制度的专利引文评价效能实证研究[J].图书情报工作,2017(19):89?95.
[6] NARIN F, CARPENTER M P, WOOLF P. Technological performance assessments based on patents and patent citations [J]. IEEE transactions on engineering management, 2017(4): 172?183.
[7] YOO S H, KIM B, JEONG M K. Modeling of technology lifetime based on patent citation data and segmentation [J]. Journal of the operational research society, 2015, 66(3): 450?462.
[8] 乔永忠,肖冰.基于权利要求数的专利维持时间影响因素研究[J].科学学研究,2016,34(5):678?683.
[9] 邱洪华,陆潘冰.基于专利价值影响因素评价的企业专利技术管理策略研究[J].图书情报工作,2016(6):77?83.
[10] 庞彦军,刘立民,刘开第.未确知均值聚类[J].河北工程大学学报,2010,27(4):98?100.
[11] 靳颜宁,李夕兵,刘彭金,等基于改进的未确知聚类模型的岩爆倾向性预测[J].安全与环境学报,2017(1):12?16.
[12] 苟尤钊,吕琳媛,陈永伟.专利质量分析的研究进展与述评[J].电子知识产权,2019(2):59?65.



