郭原东,雷帮军,聂 豪,李 讷
(三峡大学,湖北 宜昌443000)
0 引 言
随着计算机计算能力的增长,深度学习算法已在图像处理、图像识别领域有了广泛应用。算法的应用除了算力的支持,还需大量的图像样本,但对于高精度的图像样本,通常存在数量的缺失带来的问题。当使用较少样本数量的图像进行深度网络训练时,容易使网络陷入局部最优点,从而产生过拟合现象。此时,训练得到的网络虽然在训练集上有较优的识别精度,但算法在测试集上的泛化能力差,无法满足工业界的使用标准[1-6]。近年来,学术界通过对样本缺失条件下的深度学习理论进行了众多研究,文中在这些理论的研究基础上引入了随机隐退机制[7-10]。该方法的思想是在某些迭代过程中,随机地选择一定数量的隐含层单元使其失效,此方法的引入可以避免过拟合现象。本文还引入了降采样机制,用来降低引入随机失效方法后算法时间复杂度过高的问题。
1 理论基础
1.1 深度学习
本文使用的深度学习算法为深度置信神经网络(Deep Belief Networks,DBNs)。在该网络中,引入受限制玻尔兹曼机(Restricted Boltzmann Machine,RBM)改变算法的训练结构,并改善卷积神经网络(Convolutional Neural Networks,CNN)训练效率低的问题,在图像识别领域有较广泛的应用。该网络中的RBM结 构如图1所示[11]。
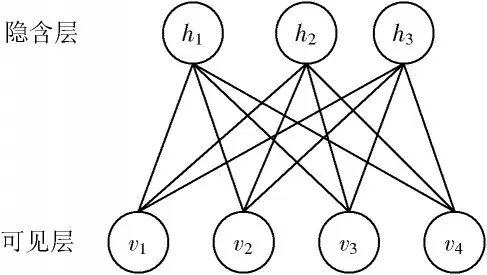
图1 RBM基本结构
其训练与学习方法如下,一个RBM的能量分布为:
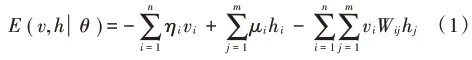
在训练中,其目的在于确定RBM的参数三元组θ=(ηi,μi,W)。本文通过极大似然函数法进行学习,首先定义目标函数l(θ),如下:
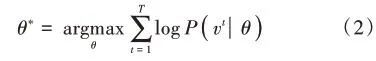
根据对比散度计算规则,对式(2)中的参数三元组计算偏导如下:

当RBM中包含n个可见单元与m个隐含单元时,在算法迭代的过程中,其参数更新的方法如下:
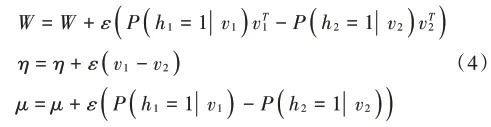
式中:vi代表可见层的单元;hi代表隐含层的单元。
1.2 随机隐退
当深度网络的结构较为复杂,而图像样本的数量较少时,网络的训练容易产生过拟合现象,且网络不具备泛化能力。此时,可以引入随机隐退机制,其原理如图2所示。
图2 给出随机隐退机制的示意图。该机制为了避免过拟合现象,在训练的过程中,随机地删除隐含层中的神经元数量。当节点被删除后,视作已“隐退”。该节点在每次迭代中只保留当前的权重,不再进行更新。
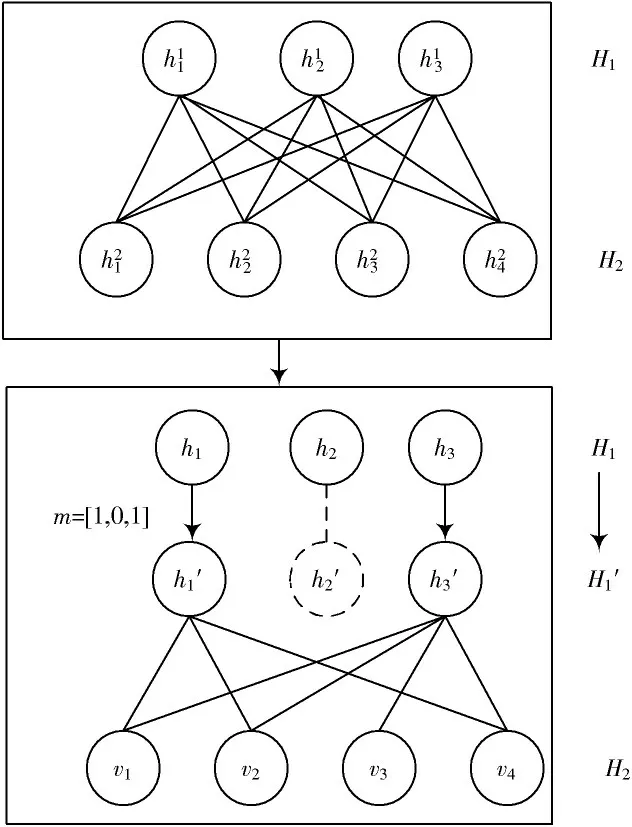
图2 随机隐退机制
随机隐退时,在隐退层引入过滤函数,过滤函数直接作用于隐含层H1,过滤后得到新的隐含层[12-13],如下:

对于线性网络,其h层的第i个单元的表达形式如下:
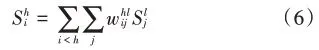
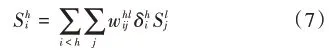
式中δ是一个服从伯努利分布的变量。此时,可以得到这个单元的数学期望,如下:
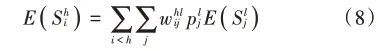
由于神经网络是一个非线性网络,需要引入激活函数,本文使用的激活函数为Sigmoid函数,引入该函数后,网络的输出如下:
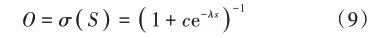
2 方法实现
2.1 数据预处理
对于高精度的图像识别场景,训练样本通常不足,本文使用的样本库为ORL人脸库。在该人脸库中,共包含400张图片,这400张图片对应了40个不同个体,每个个体有10张不相同的图片。图3给出了其中1个个体的部分人脸图像。
首先,将ORL人脸库的图像划分为训练集与测试集,训练集与测试集中包含每个个体的各5张图像,每个集内有200个图像样本。由于本文算法引入随机隐退与降采样机制,因此需要分别评估这两个方法对于算法性能的影响。

图3 ORL人脸库
在引入随机隐退机制时,设置网络的参数,如表1所示。
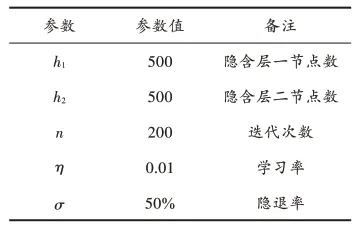
表1 引入隐退机制的网络参数
图4 中的虚线给出了引入50%隐退机制后,DBN网络的错误率随着迭代次数增长的变化情况。为了更优地评估隐退机制引入后的效果,使用普通的反向传播网络进行对比。由图4可以看出,普通的反向传播在迭代次数为50次时,可达到最优的错误率43%;50%隐退网络的错误随着迭代次数的进行不断降低,最终可达到5%。
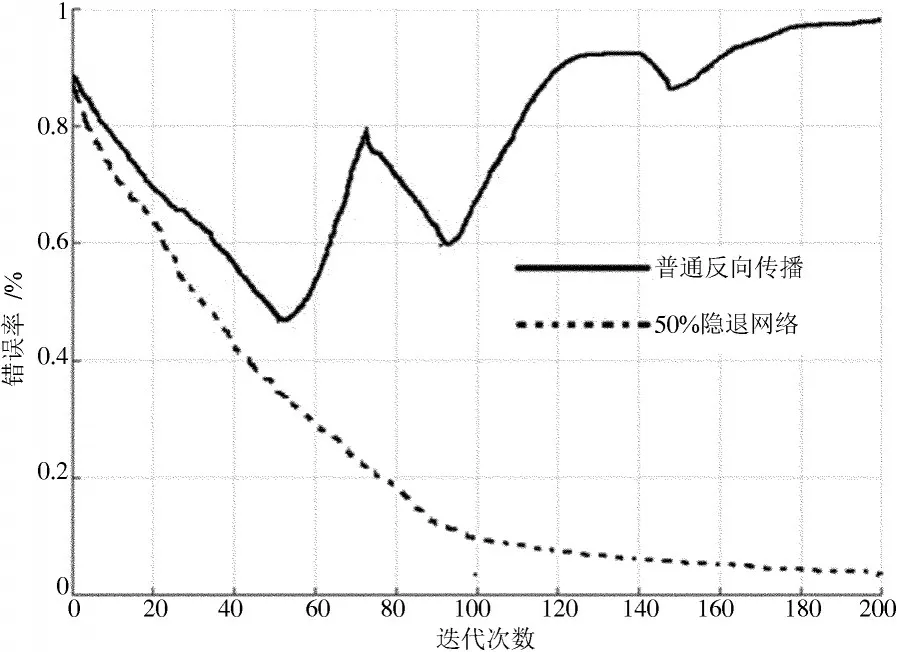
图4 算法错误率和迭代次数的关系
随后,在隐退网络上加入降采样机制,由于图像进行了降采样处理,每个输入样本包含的样本信息也随之降低。因此,网络的学习率可以根据采样率降低为0.005,隐退率也可以降低为25%。在使用相邻近算法进行ORL库的降采样时,会消耗约1 s的计算时间。
2.2 仿真结果
通过前期的处理,共获得了3个不同网络,分别是普通的DBN网络1、引入隐退机制的DBN网络2、引入降采样与隐退机制的DBN网络3。在训练过程中,其错误率与计算时间的模型参数,如表2所示。
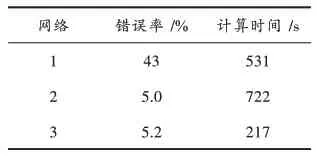
表2 模型参数
由表2可以看出,普通的DBN网络在本文的图像训练样本缺失的高精度图像识别场景中,错误率与训练的时间均较高。当在该网络中引入随机隐退机制后,网络的错误率有明显的改善,由43%降低到5.0%。但该机制的引入另一方面降低了网络的训练效率,网络的训练时间由531 s提升到722 s。然后通过再次引入降采样机制,使得网络的性能与训练效率均有明显的改善。虽然网络的错误率由5.0%略微增加到5.2%,但网络的训练时间由722 s降低到217 s,降低了69.9%。最终,文中将本文方法与现有的一些图像识别方法在OLP数据集上的计算结果进行了对比,算法对比结果如表3所示。
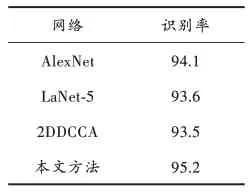
表3 算法对比结果%
由表3的结果可以看出,本文算法的识别率可达到95.2%,相较当前识别率较优的AlexNet网络,可以提升约1.1%,具有在工业界进行应用与推广的潜力。
3 结论
高精度的图像识别算法在训练前首先需要搜集大量的训练样本,这是一个耗时、耗力的过程。本文设计的算法中引入了随机隐退机制,使得深度学习算法对于样本数量的需求大幅度降低。从算法的测试结果可以看出,本文算法较大地开拓了深度学习算法的适用范围,对于算法在工业界的深入应用具有较强的推动意义。



