于旭燕,刘建霞,薛文渲,袁晓辉,段淑斐,程永强
(1.太原理工大学 信息与计算机学院,山西 太原 030000;2.美国北德克萨斯大学 计算机系,德克萨斯 丹顿)
0 引 言
糖尿病视网膜病变(Diabetic Retinopathy,DR)是目前公认的最严重的致盲疾病之一。由世界卫生组织(WHO)发布的糖尿病报告可知,在1980 年仅大约为1.08 亿人,而在2014 年,糖尿病患者人数大约有4.22 亿人之多[1]。糖尿病正在成为全球流行病,并且随着糖尿病发展会引起各种眼部并发症。
目前,对糖尿病视网膜病变识别国内外已经做了很多研究工作[2⁃3],但大多数都是利用传统的模式识别方法。传统方法中,首先对视网膜眼底图像中,如微血管瘤、小出血点、硬性渗出、棉絮斑等病变区域进行特征提取,然后利用提取到的特征对分类器进行训练,从而实现图像的分类。虽然目前的传统方法已取得一定的成果,但视网膜图像内部本身结构的复杂性导致病变区域的特征提取相当困难。而且在病灶的分割研究中需要熟知大量的先验知识,一般的研究者往往很难捕获病灶区的所有特征。
近年来,对深度学习的研究已经取得一定的成果[4⁃5],深度学习的研究中最典型的卷积神经网络(CNN)已广泛应用在医学图像领域[6⁃7]。本文提出一种改进的CNN 算法—SupplementNet,操作者只需将搜集的眼底图片做一些简单的图像预处理,然后输入SupplementNet,网络将会自动提取特征,训练参数。最后将测试数据集输入已经训练好的SupplementNet,进行数据的自动分类,可有效提高DR 图片分类效率。
1 卷积神经网络
1.1 背 景
早在1998 年,Lecun 等人就提出了CNN,并搭建了LeNet 模型用于手写字母识别,但因为当时计算力的不足和数据量的缺乏,该模型并没有真正的应用于各个领域。2012 年,Alex 等人提出了AlexNet 模型,该模型以巨大的优势在图像识别大赛ImageNet 上夺冠,引爆了深度学习的应用热潮。近些年涌现出了许多优秀的卷积神经网络模型,如:VGGNet、GoogLeNet[8](2014)、ResNet[9](2015)、SENet[10](2017)等。目前,CNN 已广泛应用在语音识别及计算机视觉[11⁃12]等多类应用中,并取得了令人瞩目的成就。
1.2 基本网络架构
CNN 主要由五种结构组成:
1)输入层。使用CNN 处理图像时,它通常表示图像的像素矩阵。输入的眼底图片是在RGB 三通道模式下,长和宽代表了图像的大小,图像深度是3。
2)卷积层。卷积层是CNN 的核心部分。在卷积层中,每一层的输入是上一层输出的一小部分,这一小部分的尺寸与卷积核大小相同,卷积层对每上一层的小部分进行再分析,从而得到更加抽象的特征。卷积层形式为:
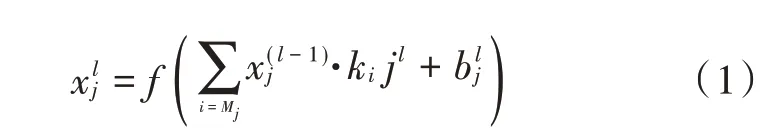
式中:l为网络第l层;M j表示上一层输出的感受野;b表示偏置;k为卷积核;f(·)是非线性激活函数。
目前,CNN 中常用的非性激活函数是ReLU 函数,数学表达式为:
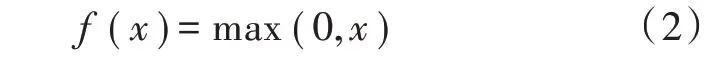
3)下采样层。其作用是缩小输入特征图的尺寸,以简化神经网络计算复杂度。它主要有两种实现方法:一种是最大池化,即输出输入特征的最大值;另一种是平均池化,即将输入特征和求平均。下采样形式如下:
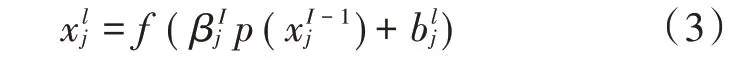
式中:p(·)为池化函数;β为权重;b为偏置。
4)全连接层。之前的卷积与下采样操作本质上是在提取和压缩特征,这样十分容易造成特征丢失,所以使用全连接来进一步加强特征。
5)分类器。CNN 一般采用Softmax 作为分类器,将全连接层加强的特征输入该分类器中,即可得到分类结果。
2 本文算法流程
将收集到的眼底图像一部分作为训练集,输入到CNN 结构框架进行参数训练,最后用测试集来测试网络性能,观察分类效果。具体算法流程如图1 所示。
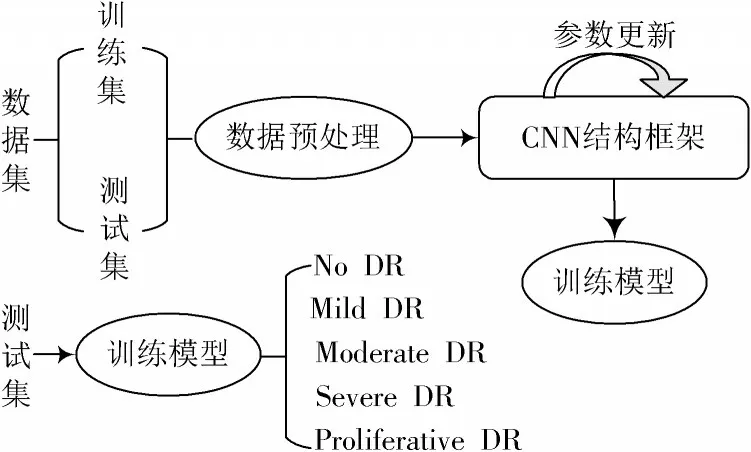
图1 算法流程
2.1 数据集获取
本文数据集来自于目前针对DR 检测最大的开放数据源Kaggle[13]的DR 检测竞赛(Kaggle diabetic retinopathy detection competition)平台。最新的《美国眼科协会临床指南:糖尿病视网膜病变》(2016 版)中临床医生将视网膜病变程度分为0~4 个等级,数据信息如表1 所示。
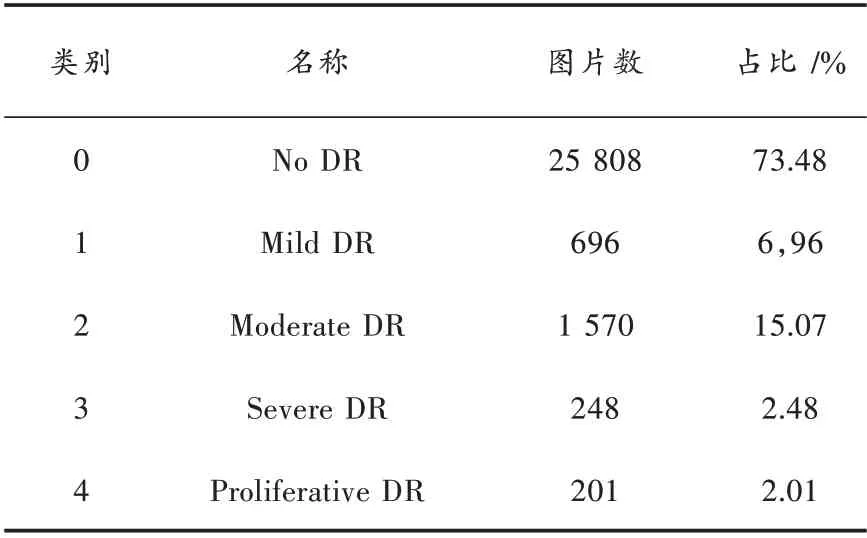
表1 数据信息
2.2 数据预处理
1)将下载好的数据集分类(Kaggle 数据集是带有标签类别的,但并未分类整理),并去除数据集的黑色背景。
2)将图片分辨率降低到512×512×3,以提高模型的训练速度。
3)删除低对比度、模糊或低分辨率视网膜图像。
4)对第3 类和第4 类视网膜图像进行直方图均衡化处理,以改善图像效果偏暗的情况。
5)对视网膜图像作数据归一化,将不同类别图像的色调、亮度都归一到同一范围内,以提高模型的训练效果。
6)对数据集量少的类别(3 类和4 类)进行数据扩增,以改善数据集不均衡的情况。
2.3 模型设计
首先,由式(2)可知,当CNN 使用ReLU 函数作为分类问题的激活函数时,被训练图像中对分类有用的负值特征信息也会被完全舍去,这势必会造成有效信息的丢失,本文为此采用Leaky ReLU 非线性激活函数来解决这一问题。其数学表达式为:
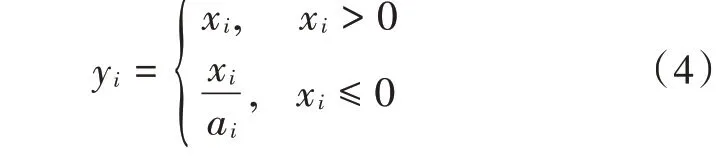
其次,为了提高训练速度和泛化性能,本文在网络构建的过程中加入了批量标准化:BN(Batch Normalization)算法[14],该算法本质就是在上一层提取特征输入该层网络之前做一个归一化处理,之后再进行下一层的特征提取。
最后,参考VGG 网络结构框架,设计网络结构SupplementNet 卷积神经网络,如图2 所示。该网络结构采用了两个模块,分别为type1 和type2。每一个模块都是将几个小型卷积核串联叠加起来,在取得同样卷积效果的同时减少参数数量。网络中的非线性函数使用Leaky ReLU 函数代替原先的ReLU 函数,用来提取视网膜图像中有价值的负值特征,提高图像特征的利用率。每一个模块(type 1 和type 2)后都添加了BN(Batch Normalization)算法,用来提高网络对于训练数据集与测试数据集的泛化性能。在每一个模块里都有一层池化层与前一层卷积层相连接。最后三层为全连接层,并在其后添加Dropout 层来控制过多的参数量,增强网络的泛化性能。
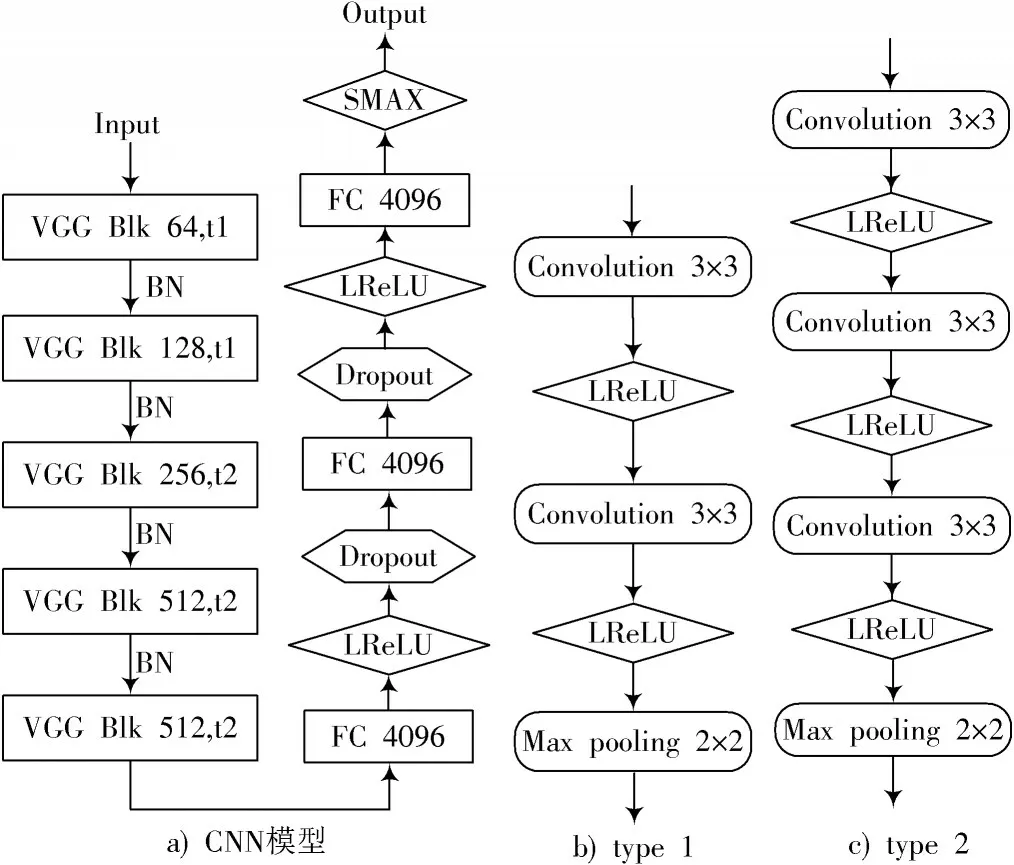
图2 SupplementNet 结构
3 实验验证
3.1 实验环境
硬 件:双GPU,NVIDIA Quadro P4000 和NVIDIA GeForce GTX 1080 Ti;
软件:CUDA8.0 加CUDNN6.0,Matlab 2018a。
3.2 实验设置
实验一:为了对比本文实验加入的BN 算法对于网络性能的积极作用,本实验使用了两种不同的经典CNN 结构,将加入BN 算法前后的结果作对比:
1)使用视网膜训练集对传统AlexNet 网络进行训练,简称Model T1;在AlexNet 网络的每个卷积层前加入BN 算法,简称Model F1,用视网膜训练集训练,然后用测试集进行网络性能测试。
2)使用微调VGG16 网络对视网膜图像进行训练,简称Model T2。在每两个或者三个卷积层后连接一个下采样层,然后在每个下采样层后加入BN 算法,简称Model F2,用视网膜图像训练,然后测试网络性能。
实验二:为了验证Leaky ReLU 能够对视网膜图像有价值的特征进行更全面提取,将ReLU 激活函数与Leaky ReLU 激活函数的网络进行对比:
1)直接使用SupplementNet 结构,用视网膜图像进行训练,简称Model F3;
2)将SupplementNet 中的激活函数替换为ReLU 函数,简称Model T3,用视网膜图像进行训练。
3.3 实验结果分析
3.3.1 实验一结果分析
实验一做了两组对比实验,充分说明BN算法对网络的性能和训练结果有一定的影响。实验一的Model T1,Model F1 和Model T2,Model F2 对视网膜分类结果的混淆矩阵如图3 所示。
图3a)和图3b)分别对应Model T1 和Model F1 的实验分类结果。由混淆矩阵可知,在对角线区域分布测试集的大部分数据,说明Model T1 和Model F1 都对视网膜图像分类有明显效果。两组实验结果表明,Model F1的分类能力要优于Model T1。Model T1和Model F1的准确率分别为62.5%和68.5%,Kappa指标分别为0.506 4和0.728 3。
图3c)和图3d)分别是Model T2 和Model F2 的实验分类结果。将两组实验结果做对比,Model F2 的分类效果明显比Model T2 的分类效果更精确。Kappa 指标分别为0.592 4 和0.711 2,分类准确率分别为61.1%和72.6%。
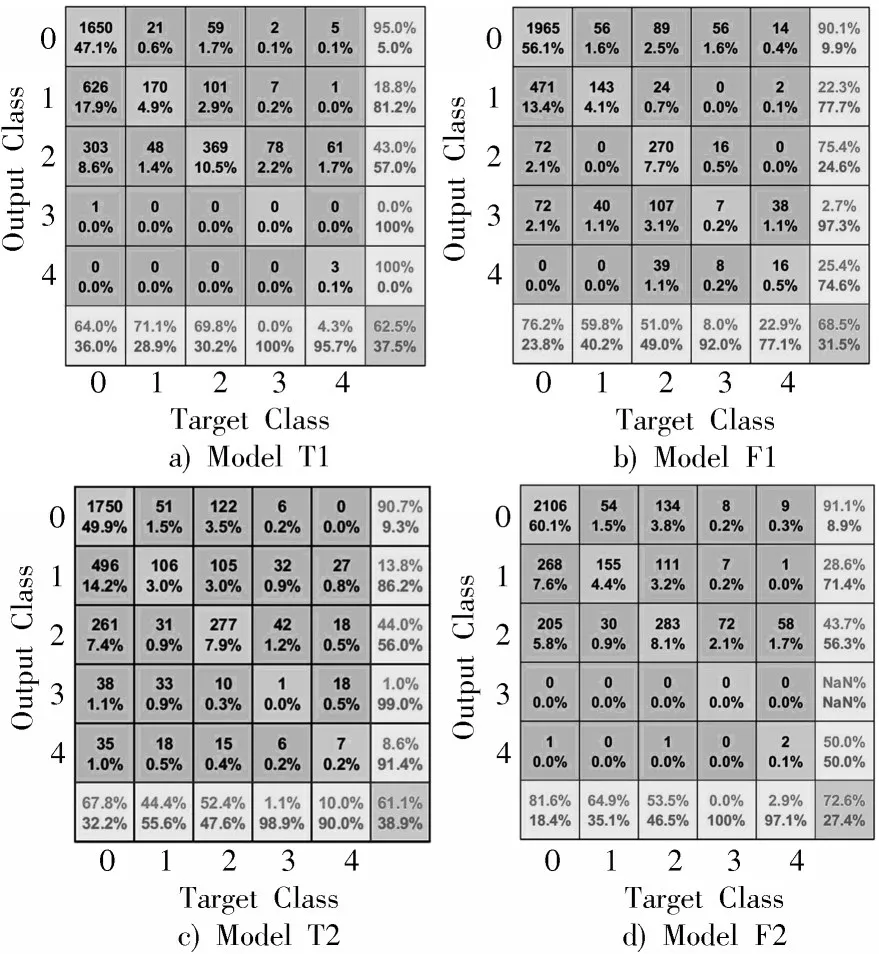
图3 混淆矩阵
两个对比结果表明,BN 算法的加入可有效提高网络性能,其原因在于深度神经网络训练时若浅层网络在提取特征时发生一些微小的变化,那么这个微小的变化就会随着网络加深而被逐层放大,从而影响网络对特征的学习效率和性能。因此,在每一次提取特征之前加入BN 算法,将每层输入特征都进行归一化处理,可有效增强模型的性能。
3.3.2 实验二结果分析
实验二的Model T3 和Model F3 对视网膜图像分类结果混淆矩阵如图4 所示。
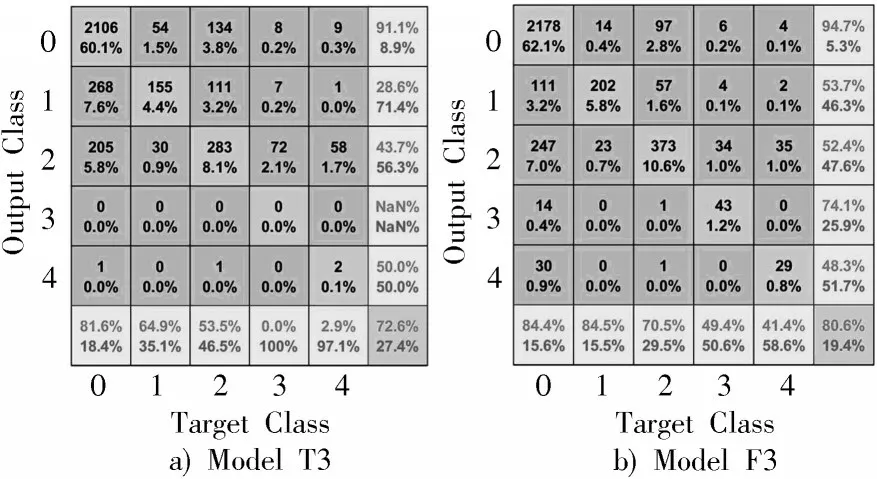
图4 混淆矩阵
图4a)和图4b)分别是Model T3 和Model F3 的实验分类混淆矩阵。Model T3 和Model F3 的准确率分别为72.6%和80.6%,准确率提高了12.1%。Kappa 指标分别为0.711 2 和0.851 3。
在Model F3 中的Leaky ReLU 函数,当输入特征小于0 时,将得到一个较小斜率的函数,因此保留了特征图中的负值信息,并增加有效特征的学习。
在ModelF3 中使用Leaky ReLU 激活函数,用来提取小于零的特征。由文献[15]可知,当函数中的斜率为100 时,其分类效果与使用ReLU 作为激活函数时的分类效果没有明显区别;当斜率为5.5 时,其分类效果要明显优于ReLU 函数。
由图5 可知,在实验Model T3 中,当训练次数迭代到12 000 时,网络收敛,测试集的分类准确率达到了70%以上,但此时的Loss 值相对来说还是比较大的。而在Model F3 中,训练次数迭代到12 000 时,误差仍在下降,迭代到大约28 000 时,网络收敛,Loss 接近于0。网络可能发生过拟合,但说明它越来越接近于每个类别图之间的关系,此时测试集的分类准确率为80%以上。虽然相比于实验Model F3,其网络收敛速度比较慢,但最后分类结果却是有显著效果。
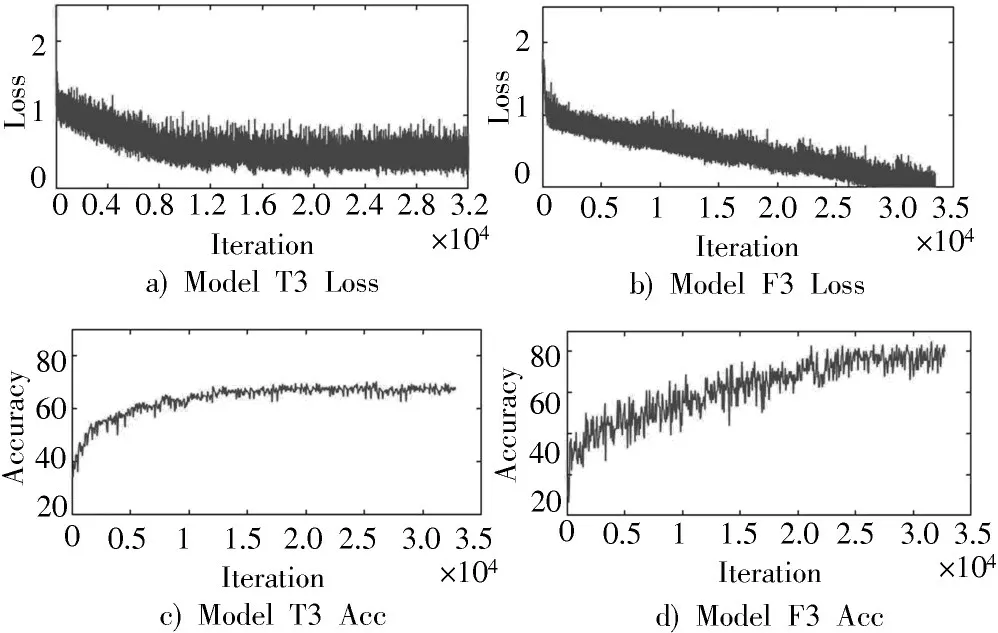
图5 Acc 和Loss 变化曲线
4 结 论
本文在VGG16 的基础上提出SupplementNet 来解决DR 图像分类效率低、准确率不高等问题。该模型将激活函数由ReLU 换为Leaky ReLU,提高了视网膜图像特征的利用率,并在网络相应位置加入BN 算法来对图像特征进行归一化,有效地增强了网络结构的泛化性能。实验结果表明,SupplementNet 的分类准确率要优于AlexNet 及VGG16 两种常用的算法,可为DR 图像分类提供新的有效途径。
在后续的实验中,可以尝试利用已经比较成熟的网络模块,例如最新研究的SE⁃block,穿插进所提的网络结构中,进一步提高网络性能。



