胡嘉欣,田 军
(中北大学,山西 太原 030051)
0 引言
随着科学技术的日益更新,多媒体数字音频数据可以带给人们更高的视觉、听觉体验,同时更高质量的多声道数字音频也被各个领域积极运用,以4 个空间层共28 个多声道琵琶音频体系为例,在该体系下输出的音频效果更加逼真,给人营造了一种身临其境的氛围。但在多声道音频的传播途径中,一个或多个的声道设备故障难免发生,最终音频的信号质量会出现低下的状况,可能还会伴随噪音,所以提高音频清晰度以及增强音频信号非常关键。
为此众多学者对此展开大量研究,文献[1]采用图信号处置最小方差失真反应波束方法,以矩阵间的方位和相位差形成多声道信号相邻矩阵权值为前提条件,最终通过改进傅里叶变化实现信号多声道增强,该方法虽可以提高信号的质量,但可行性较低;文献[2]提出基于滤波器组合信号多声道增强方法,根据耳蜗时域分散原则对数据收集开展分频处置,其次以信号与噪声的不同强弱差别实现各频数据归一化并获得判断总量,最终采用判断总量处理各频数据完成信号多声道增强,该方法实现信号多声道增强的同时,增强效果并不明显。对抗神经网络属于对弈方式的神经网络,该网络被广泛应用于各大领域,尤其在增强音频信号方面[3]。因此本文提出基于生成对抗网络的数字音频信号多声道增强方法,该方法不仅可实现数字音频信号多声道增强,而且增强效果也得以提高。
1 数字音频信号多声道增强方法
1.1 双边语谱图滤波的数字音频多声道信号去噪
对存留噪音的数字音频多声道信号x(n)进行加窗与分帧处理,并结合短时傅里叶变换(STFT)得出:
式中:k、l、K和R分别是频率指针、帧指针、帧长以及帧移;X(k,l)表示第l帧完成FFT 变化下的第k个频谱分量。所以根据公式(2)可获得音频信号时间n处频谱能量密度函数(功率频谱函数)的表达式为:
对留有噪音的多声道音频x(n)进行归一化处理并获取其语谱图x,采用一阶递归平滑方式处理得到语谱图,并通过公式(3)得到双边语谱图滤波器的输入p:
式中,遗忘因子用β描述,0 ≤β≤1。
依据Tomasi的双边滤波法,用表示假定语谱图在时频区域u=(k,l)的能量,用描述滤波后所得语谱图在u处的能量。通过公式(4)可得双边语谱图的滤波:
中心时频单位u的相邻时频单位、相邻时频单位集合和归一化因素分别用v=(k0,l0)、Ω以及Wu描述。
1.2 基于GAN 的数字音频信号多声道增强模型
1.2.1 生成对抗网络
由于对抗神经网络(GAN)应用性较高,所以在图片产生及转化等领域都离不开该网络。本文从对弈角度切入形成对抗网络模型[4-5],以最大或最小的原则为判断基准,从任意噪音Z下的生成器中获取真实数据。图1代表生成判断网络流程。判断器通过自参量优化处理实现对数据的高判断效果[6],进而使判别结果更加真实可靠;此外,生成器以判断器的传达结果为基础不停处理本身参量并尝试欺骗判断器,最终让生成器产生的数据(假数据)被判断器辨别为真。
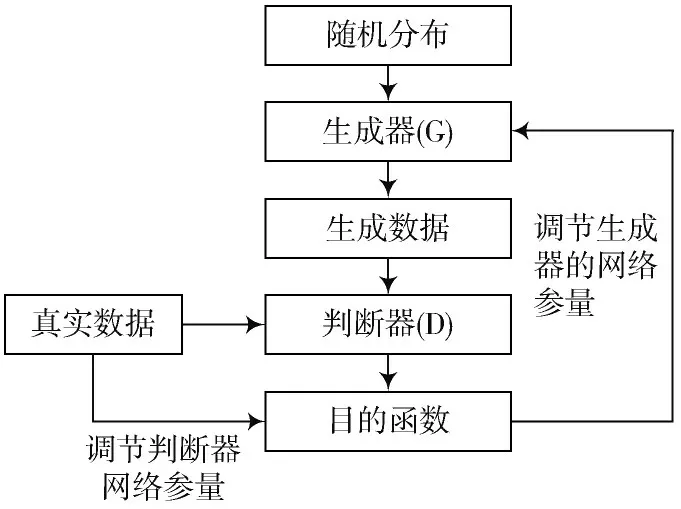
图1 生成判断网络流程图
较大概率的真实数据D(x)与较小判别输出结果D(G(z))是判别函数D所期望的,因此更大的目的函数值是该函数的最佳期望;更贴合真实样本X的生成样本G(z)与更大的D(G(Z))是生成函数G所期望的,同时会得到更小的目的函数值。公式(5)给出GAN 训练进度中的目的函数:
1.2.2 数字音频信号多声道增强实现
全卷积神经网络构造模型如图2 所示。
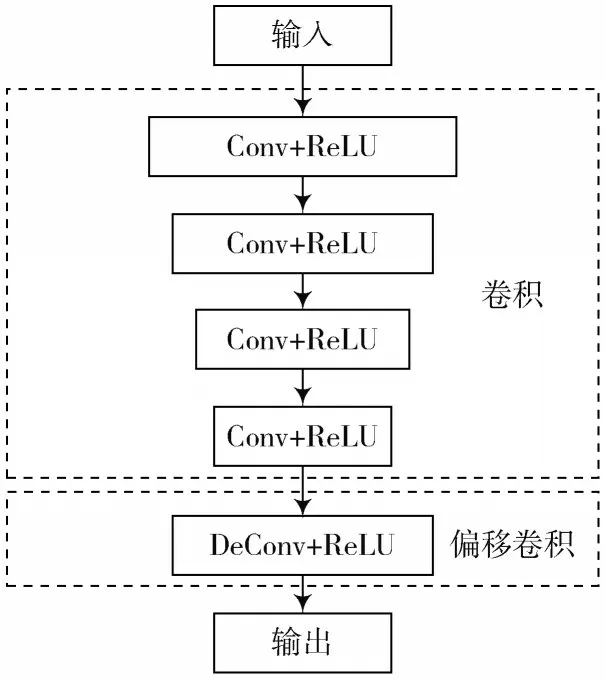
图2 全卷积神经网络模型图
对卷积过程而言,在多个卷积层以及池化层的降维凝缩处理下,输入的去噪后多声道信号在第N步时即可获得一个卷积结果[7-9]。此外,由于ReLU 在后向传播途径中降低了音频训练流程的梯度分散,所以选取修正线性区域(ReLU)为每层的激活函数[10]。生成模型G的训练构架如图3所示,该构架与自动编码器的解码及编码流程相似,属于对称的端到端构架。本文通过36 kHz上采样去噪后,音频信号多声道样本隐藏的特征向量z和N个滤波器所得卷积结果c相连,这时的目的函数可用式(6)表达:
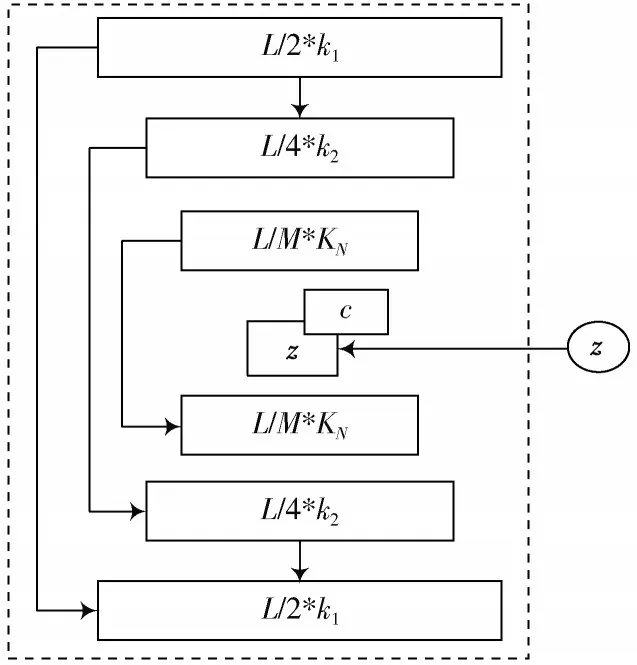
图3 生成模型G 的训练模型图
本文将目的函数、交叉熵损失函数更换为最下二乘并以此改进生成对抗网络,这样训练更加稳固,此外,G的生成样本也具备更高质量。通过公式(7)获取生成模型G的损失函数:
本文通过L2范数的应用避免训练过拟合化并提高网络泛化效果,同时更新生成模型G的损失函数如式(8)所示:
2 实验分析
本文选取某广播公司的200组多声道数字音频信号为实验对象,其中包含男生数字音频多声道信号34 组,女生数字音频多声道信号68 组,多种音乐的音频多声道信号98 组。应用本文方法对其信号进行增强处理,分析本文方法的应用效果。从98 组音乐的音频多声道信号中随机抽取一组琵琶独奏曲的音频信号,对其应用本文方法进行信号多声道增强,给出增强后信号的传输效果如图4 所示。
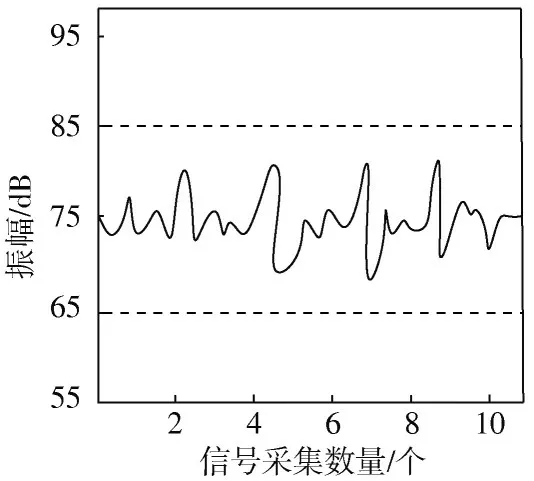
图4 增强后信号传输效果图
图4中的两条虚线为传输信号振幅,处于65~85 dB,在两条虚线之外的是干扰信号的噪声,其振幅小于65 dB 或大于85 dB。从图4 可看出,在2~10 个信号变化过程中,本文方法下的信号波形振幅一直位于65~85 dB之间,说明本文方法增强后的数字音频信号可以剔除信号中的噪声。信噪比(SNR)和音频客观评判基准(PESQ)为信号分析领域的重要指标,所以选用SNR 以及PESQ 为本次实验的评价指标,并给出应用本文方法、文献[1]基于图信号处理的信号增强方法和文献[2]滤波器组合信号多声道增强方法后的200 组多声道数字音频信号SNR 与PESQ,如表1 所示。
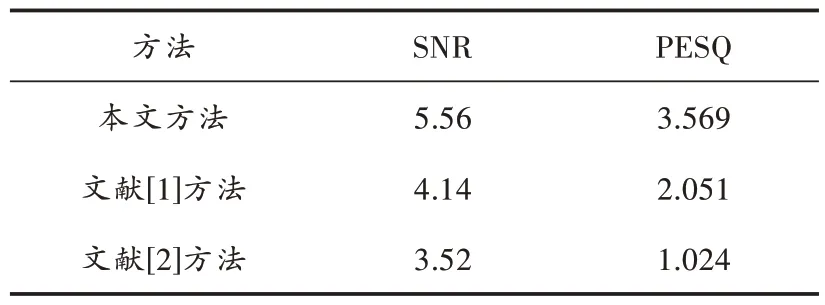
表1 去噪后的SNR 与PESQ
信噪比即信号的有效成分与噪音的高低对比,信噪比越大说明该信号的噪音越少。通过表1 可知,本文方法的SNR 与PESQ 均高于文献[1]、文献[2]的方法,说明本文方法可以更好地实现数字音频信号多声道的增强,增强后数字音频信号的质量更好。
为验证本文方法对数字音频信号多声道的增强效果,实验给出本文方法以及文献[1]、文献[2]方法去噪前后语谱图,如图5 所示。
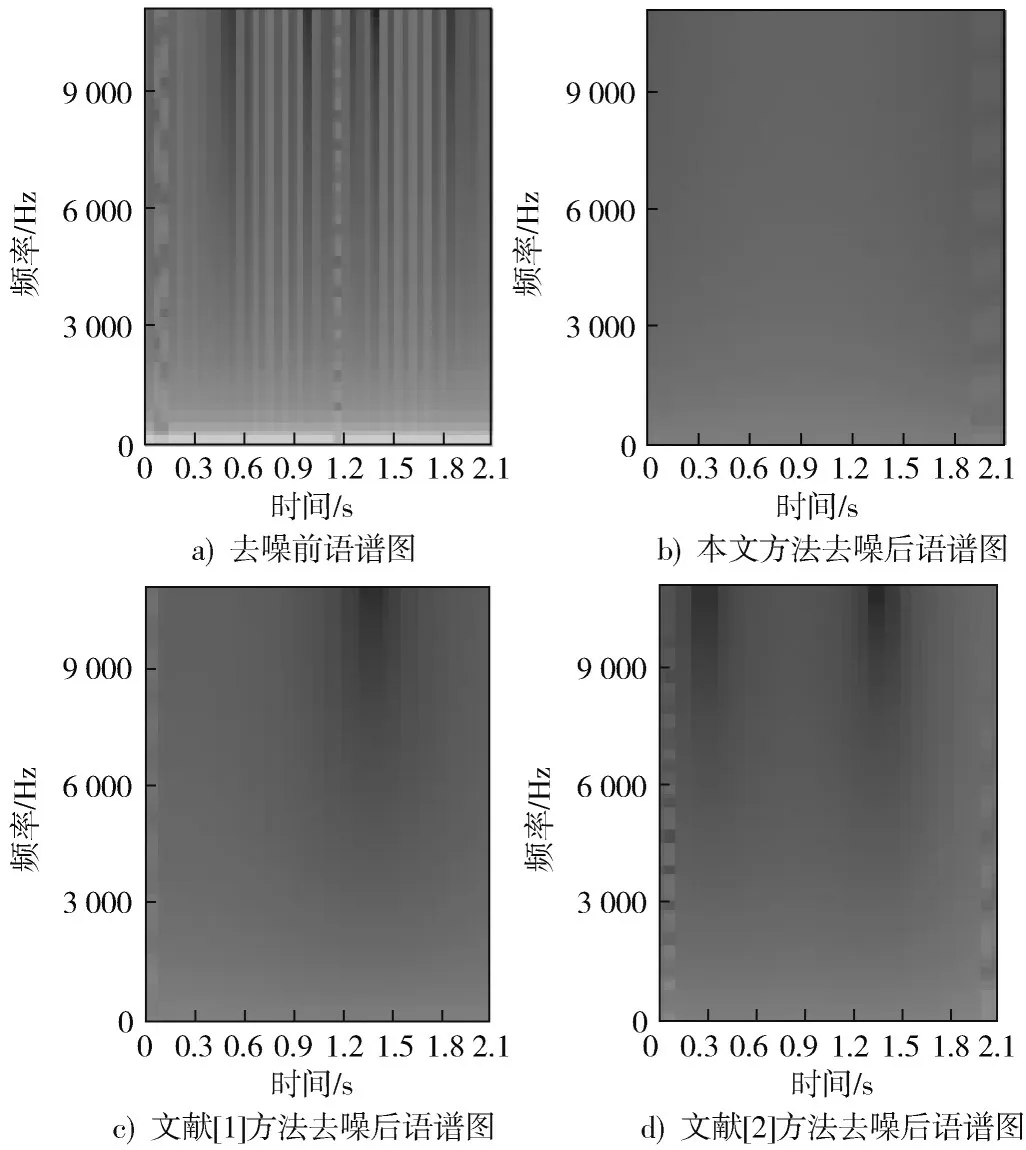
图5 去噪前后语谱图比对
分析图5 不难看出,本文方法去噪后的语谱图相比文献[1]、文献[2]方法噪点以及模糊区较少,说明本文方法对数字音频信号的多声道去噪效果更明显,应用效果较好。
3 结论
本文方法不仅可以去除数字音频信号多声道中的噪音,而且去噪效果更为显著。此外,本文方法可以更好地实现数字音频信号多声道的增强,并得到更高质量的数字音频信号,可有效提升多媒体数字音频数据带给人们的听觉体验,并通过提升信号质量扩大其在各领域的应用范围。



