傅小倞,罗正军,杨艺豪,郑祝倩
(南京航空航天大学经济与管理学院,江苏 南京 210000)
0 引 言
单词记忆是语言学习的重要环节之一,而如何快速、有效地记忆单词一直是学习者和教育者所关注的问题。文献[1]表明“Without grammar very little can be conveyed; Without vocabulary nothing can be conveyed”。
目前对于单词记忆的研究已经比较充分,文献[2-3]研究了如何减少单词记忆的枯燥性;文献[4]运用艾宾浩斯遗忘曲线提出了最优化单词记忆方法;文献[5]提出了象形图解单词记忆的方案。现有大部分研究追求如何高效地记忆单词,没有对人在记忆中的单词检索过程进行探讨。目前已有一些基于心理学的记忆检索研究。文献[6]通过实验得到了工作记忆搜索和视觉搜索具有相同搜索机制的结论;文献[7]认为少量相似项目不会影响工作记忆序列的检索。但是目前尚未有针对单词的记忆检索研究,也没有研究从单词自身的角度去挖掘单词的哪些属性会决定其记忆检索难度。
随机森林和聚类算法已被广泛应用于工程管理预测(如连铸坯纵裂预测[8]、陷落柱识别[9]、大型建筑能耗负荷预测[10]),且取得了较好的效果。本文提出一种将DBSCAN 聚类和随机森林相结合的单词记忆检索难度预测模型。该模型基于单词的固有特征,在单词记忆检索仿真程序的支持下,考虑了单词的字母组成结构、使用频率、词性等因素,预测出任意五个字母单词的记忆检索难度七维向量表达,以及相应的难度分类。本文所提出的预测模型能够为进一步研究单词记忆检索机制提供有价值的实证支持。
1 单词记忆检索难度预测模型
1.1 单词特征
单词记忆检索难度的特性与人的心理学机理密切相关,但是其共性取决于单词的固有特征。本文以字母组成结构、使用频率、词性作为决定单词记忆检索难度的固有特征。
1.1.1 字母组成结构
单词的字母组成结构是检索难度的决定性因素之一。部分研究强调字母存在类SNARC 效应,人在对英文单词尾字母的加工过程中存在显著的类SNARC 效应[11-12]。因此本文认为不同字母组成结构的单词在人们记忆中被检索到的难易程度有差别。
1.1.2 使用频率
单词本身在日常生活中的使用频率也会决定它的记忆检索难度。曾有实验证实单词使用频率越低,SNARC 效应越显著[13]。因此本文认为具有不同使用频率的单词在人们的记忆中被检索到的难易程度也是不同的。
1.1.3 词 性
词性与字母结构和使用频率具有一定的相关性。比如在英语单词中,介词的数量大约只有150 个,大部分介词使用频率较高并且字母结构比较固定,因此本文将词性作为字母组成结构和使用频率的补充。
1.2 数 据
本文从美国COMAP 公司的赛题中获取了一个数据文件,该文件是对《纽约时报》单词猜谜游戏的用户提交结果,能为模型的建立提供数据支撑。
1.2.1 猜词游戏
Wordle 是《纽约时报》的一款猜单词游戏,每天提供一个秘密单词供广大玩家猜测。玩家尝试通过在6 次或更少的尝试中猜出一个五个字母的单词来解决谜题。玩家每猜测一次都会获得相应的字母提示,随后根据之前的所有提示再重新猜测单词,直至猜对。具体游戏规则见Wordle 官网[13]。
1.2.2 数据说明
美国COMAP 公司统计了玩家的游玩结果并公开发布出一个Excel 数据文件[14],一共有359 条记录。本文获取了该数据文件,将其记作数据E1。该数据文件中的玩家尝试次数百分比能够反映出一个单词被检索到的难度,即尝试次数越多的单词越难在记忆中被检索到。
为了得到单词使用频率的信息,本文从一个单词库网站[15]上获取了一个由74 995 个单词组成的词典集合G,并从另一个网站[16]上获取了3 565 个日常生活中高频出现的词汇,作为词典集合B。令S为所有单词的集合,B为高频词汇集合,C=S-B为低频词汇集合。
1.2.3 数据预处理
文件中的大部分单词都能在集合G中找到,以集合G中的词性标记为基础,为少数不能在集合G中找到的单词做人工标记。随后,将属于集合B的单词标记为高频词,属于集合C的单词标记为非高频词。
将上述处理过后的数据文件记为数据E2。
1.3 模型建立
1.3.1 单词检索仿真程序
人类玩家在猜词时会根据已经得到的提示信息在大脑中搜索可能正确的单词。本文开发了一个单词检索仿真程序来模拟人猜词的逻辑特征。首先建立一个全部由五个字母单词构成的词典空间。将集合G与数据E2中的单词取并集,只选择所有字母数量为5 的单词作为词典空间F。
算法1 展示了计算机模拟人猜词时的基本步骤。
算法1:单词检索仿真程序算法
本文的仿真程序抽取到生僻单词的概率更小,这与人类玩家更容易想到常用词这一事实是一致的。
1.3.2 特征工程
算法1 每执行一次,就相当于人类玩家进行一次猜词游戏。使用仿真程序完成相互独立的成千上万轮猜测,并统计计算机猜测结果的分布。为了预测第k次猜出某个单词的人类玩家比例,需要把机器第k次猜出该单词的概率作为它的一个特征。在计算这个概率时,以频率fk代替概率。
用列数为130 的行向量W表达单词字母组成结构的特征。其公式如下:
式中:Li是列数为26 的行向量,表示单词的第i个字母的位置,存在位为1,非存在位均置为0。
按照主流的英语语法,英语单词有9 种词性,它们分别是:名词、动词、形容词、副词、代词、冠词、介词、连词、感叹词。用列数为9 的行向量C表达单词的词性特征。同样将存在位置为1,非存在位均置为0。
用列数为2 的行向量U表达单词是否常用的特征。
最终单词在第k次被猜测出的回归模型训练特征被构造为Fk,其公式如下:
式中:fk为单词检索仿真程序第k次猜中单词的频率;W是单词字母组成结构特征;C是单词的词性特征;U是单词使用频率特征。
1.3.3 决策树回归模型
本文首先提出一个决策树回归模型。对于样本集D,设a是属性空间A1中的一个连续属性,假定a在D上出现了n个不同的取值,将这些取值从小到大进行排序,记为:{}a1,a2,…,an,其中:ai是D在属性空间A1中第i小的一个值。
设划分点t可将D分为子集和,其中包含在属性a上取值不大于t的样本,包含在属性a上取值大于t的样本。对于相邻属性取值ai与ai+1,t在区间[ai,ai+1]中取任意值所产生的划分结果相同。因此,对连续属性a,只需要考察包含n- 1 个元素的候选划分点集合Tn:
假设R为当前节点样本集,n为样本数量,那么每一种划分都对应一个损失值。使用划分出的两个类别的均方差之和作为决策树的损失值Loss,其计算如下:
式中:xi是R中的一个样本;R1、R2为划分后两个子集;分别是R1和R2的标签值均值。
1.3.4 随机森林回归模型
随机森林采取自助采样法[17]。对于样本集D进行自主采样法操作N次,最终训练出N个决策树模型。对于回归任务,使用平均法结合所有基学习器的预测结果,得到随机森林回归模型的预测结果为:
式中hi(x)为第i个决策树回归模型的预测结果。
1.3.5 单词记忆检索难度七维向量预测模型
将所有单词的Fk作为特征值,第k次被猜中的比例作为标签值,训练7 个随机森林回归模型,并在预测输出上设置等比缩放运算,使得七维向量所有值的和为100。这样就构成了本文的单词检索难度七维向量预测模型。
1.3.6 密度聚类
本文使用DBSCAN 密度聚类算法将数据E2中出现的单词进行聚类,以更直观地反映单词检索难度。本文的聚类计算使用欧氏距离度量,计算公式为:
式中:xi是第i个样本,xj是第j个样本,它们以n个维度来度量;xiu是样本i在u维度上的值;xju是样本j在u维度上的值。
DBSCAN 算法基于一组邻域参数(∊,Minpts)来刻画样本分布的紧密程度。对xj∈D,其∊-邻域包含样本集D中与xj的距离不大于∊的样本,即:
若xj的∊-邻域至少包含MinPts 个样本,则xj是一个核心对象;除此之外,若xj在某个核心对象的邻域中,则xj是一个边界对象,其他的点均为噪声点。
如果xi在xj的邻域内,而xj是一个核心对象,则xj到xi是密度可达的。如果存在一个对象链p1,p2,…,pn,p1=xj,pn=xi,对于pi∈D(1 ≤i≤n),pi+1是从pi关于∊和Minpts 直接密度可达的,则xi是从xj关于∊和Minpts 密度可达的。
行动主张:质量控制活动在事前、事中、事后的三个基本环节都存在,作为最基层的教学管理单位---教研室,它是学校质量管理中非常重要的环节,必须在遵循学院既定的质量方针、目标的前提下提出能够操作、量化的检查性质量控制活动的内容、项次、指标、测评方法,并且提出准确、公正的过程执行及最后成果效果评价方案,并在实施过程中具有能够操作性的纠偏空间。
DBSCAN 算法可描述为:如果点xj的邻域包含的点多于Minpts 个,则创建一个以p为核心对象的新簇,然后迭代地聚集从这些核心对象密度可达的对象。当没有新的点可以添加到任何簇时,算法结束。
Davies-Bouldin(DBI)指数是一种评估聚类算法的度量,其计算公式如下:
第i个簇的簇内平均距离的计算公式如下:
式中:wi是第i个簇的中心;xij表示第i类中第j个数据点;Ai表示第i类的中心;Ti表示第i类中数据点的个数;q为度量参数。
1.3.7 随机森林分类预测模型
本文所使用的随机森林分类预测模型生成原理与随机森林回归模型有如下的微小差别:
1)将决策树的损失函数Loss 定义为信息增益的相反数,其计算公式如下:
当前节点以A条件划分之后的样本集信息熵H(D|A)计算公式如下:
式中:Di为D中所有i类样本组成的样本集;Dik表示当前节点下采用某种划分方式之后得到的样本集中的第k个子样本集。
2)本文的随机森林分类预测模型采用投票法,取所有决策树输出结果的众数作为随机森林分类预测模型的最终输出结果。
1.3.8 单词记忆检索难度分类预测模型
将数据E2中所有单词的七维向量输入到基于欧氏距离的DBSCAN 算法进行聚类,得到每个单词的分类标签,根据所得标签训练一个随机森林分类预测模型。单词记忆检索难度预测流程图如图1 所示。
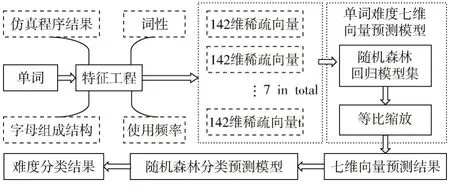
图1 单词记忆检索难度预测流程图
2 实验结果分析
2.1 聚类结果
将数据E2中的七维向量特征输入到DBSCAN 算法中,综合考虑簇的个数和DBI 指标进行网格搜索,最终E2中的所有单词被聚类为6 个簇,结果如表1 所示。
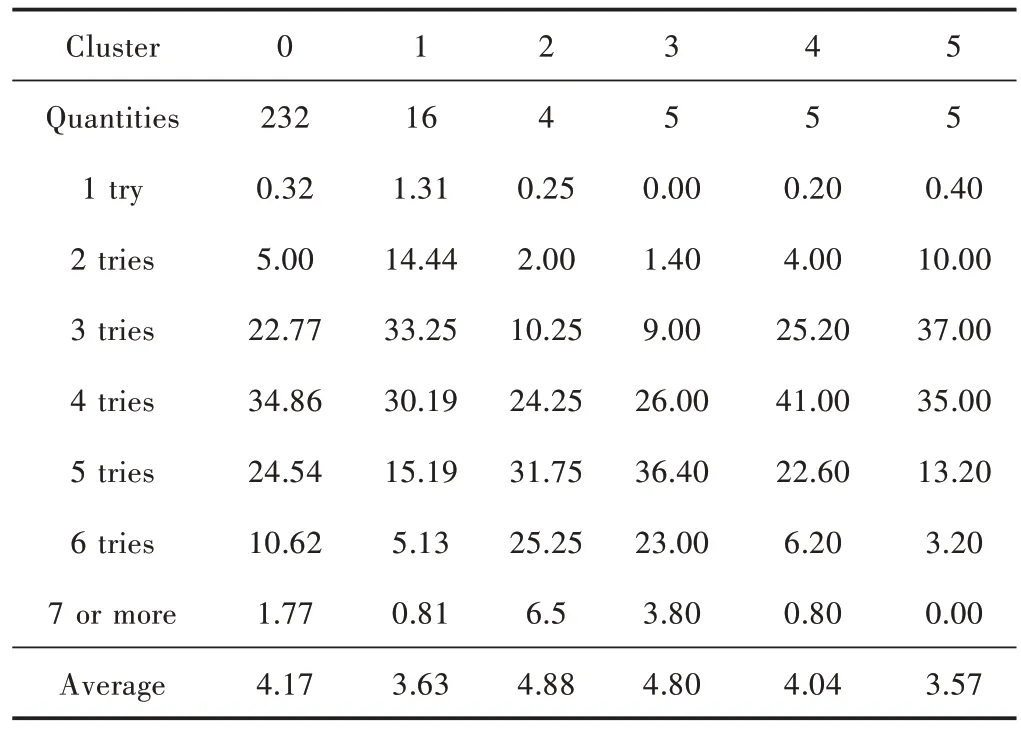
表1 单词记忆检索难度聚类结果
将单词记忆检索难度七维向量十分相近的簇进行两两合并,得到单词记忆检索难度的三个类别:简单、中等、困难。三种难度单词的七维向量平均值分布图如图2 所示。
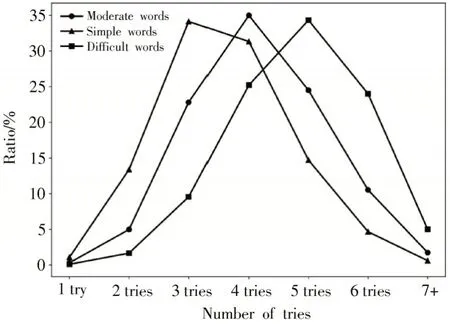
图2 不同难度单词的七维向量平均值分布图
2.2 预测单词的记忆检索难度
对单词“EERIE”进行预测得到的结果是“中等”,平均猜测次数为4.47 次。图3 是单词“EERIE”的七维向量特征分布及其与不同难度单词的七维向量特征的对比。
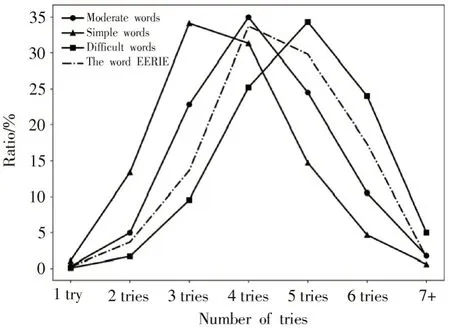
图3“EERIE”猜测次数分布以及与不同难度的对比
从图3 可以看出,“ERRIE”属于偏难的单词,但是与困难单词仍具有较大的差别。
2.3 模型评估
2.3.1 随机森林回归模型评估
采用平均绝对误差(MAE)和拟合优度(R2)对模型预测结果进行评价。MAE 用于评价回归模型的误差,R2用于评价回归模型的可解释性[18]。计算公式如下:
式中:ŷi是第i个样本的预测值;yi为第i个样本的真实值;yˉ是所有样本的平均值。
设置决策树个数为1 000,特征选择比例为40%。训练随机森林回归模型集并计算其MAE 和R2值,结果如表2 所示,回归模型具有很强的拟合优度。
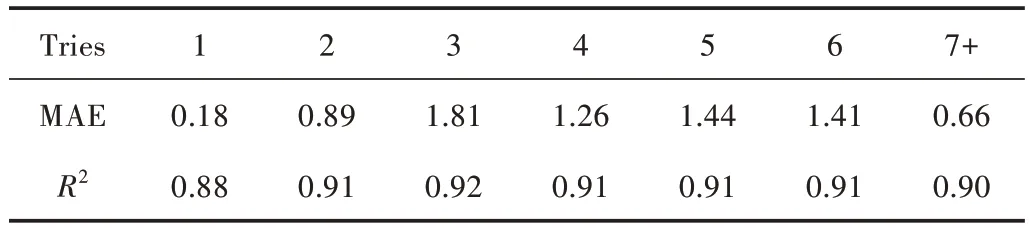
表2 随机森林回归模型集误差评估指标
2.3.2 随机森林分类预测模型评估
准确率(Accuracy)、精确率(Precision)、召回率Recall、F1值是分类预测问题的常用评估指标,计算公式分别如下:
式中:TP、FP、FN、TN 的具体含义如表3 所示。
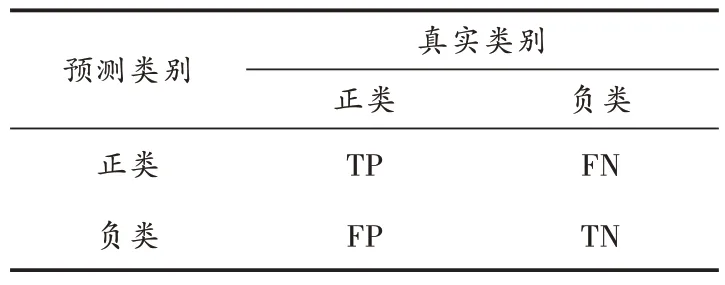
表3 预测类别和真实类别的混淆矩阵
留出25%的样本作为测试集,并重新训练分类模型。通过对测试集的样本进行预测得到随机森林分类预测模型的准确率为0.985,其他各项泛化能力评估指标如表4 所示。
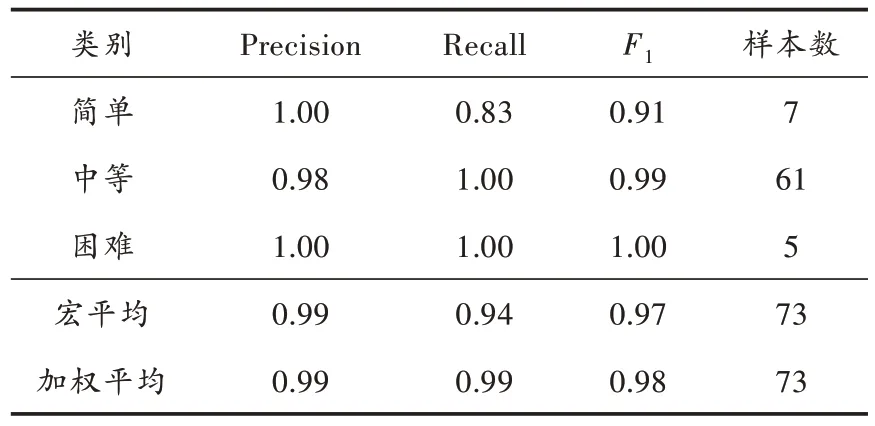
表4 随机森林分类预测模型泛化能力评估指标
2.3.3 鲁棒性评估
鲁棒性是指模型对数据变化的容忍程度。如果数据的微小偏差对模型的输出只有很小的影响,那么模型是稳健的。分别在142 维稀疏矩阵中删除第一个字母和最后一个字母的所有结构信息之后,训练“4 tries”的随机森林回归模型集,并将新模型和原始模型作对比得到图4 的结果。
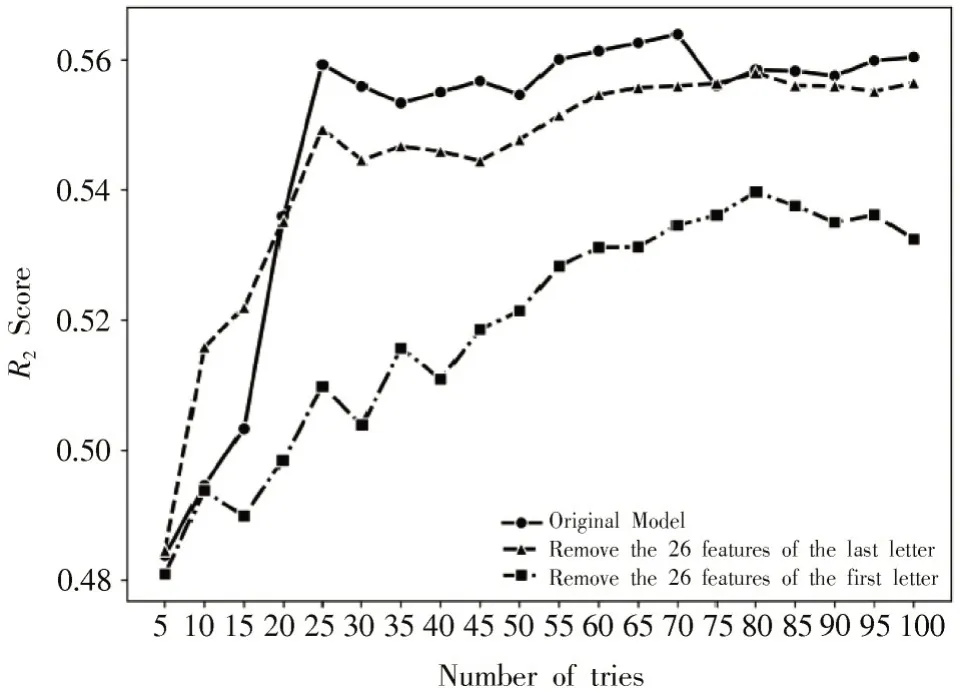
图4 随机森林回归模型减少部分输入后的测试集R2
图4 表明删除26 个特征之后,随机森林回归模型的R2变化不大。这说明回归模型具有较强的鲁棒性。
分别删除七维向量中的其中一维,将剩下的六维向量输入随机森林算法训练分类预测模型,结果如表5 所示,结果表明随机森林分类预测模型具有较强的鲁棒性。
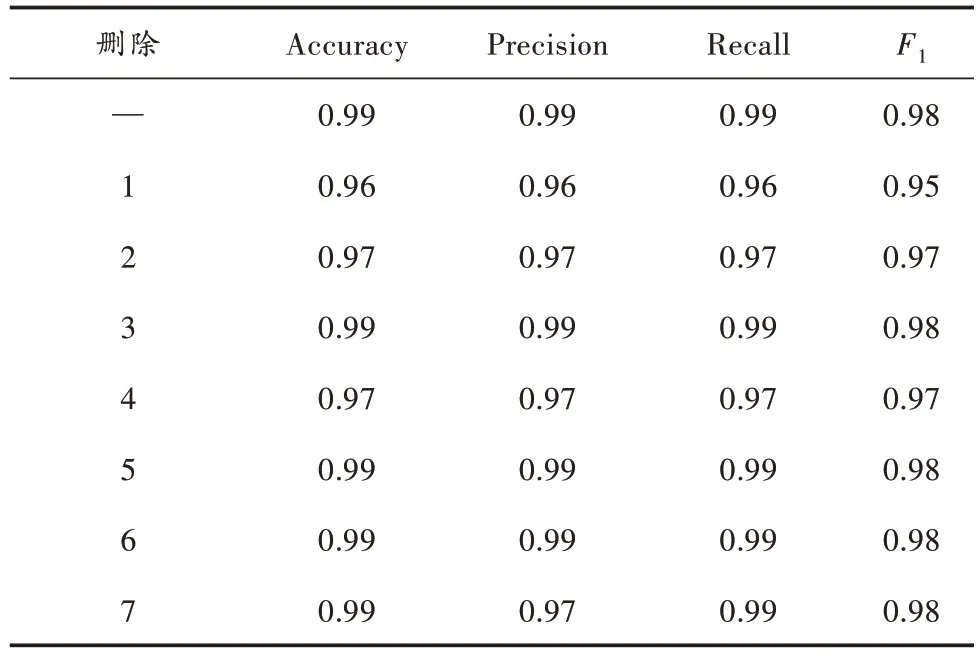
表5 随机森林分类预测模型减少部分输入后的测试集评估
3 结 语
本文提出一种基于DBSCAN 和随机森林的单词记忆检索难度预测模型。该模型不仅能预测单词记忆检索难度的七维向量表达,还能预测出更加直观的难度分类:“简单”“中等”“困难”。实验结果表明:模型中的回归模型集具有很好的拟合优度;分类预测子模型具有很强的泛化能力;模型整体具有很好的鲁棒性。另外,本文提出的单词记忆检索难度预测模型只能针对字母个数为5 的单词,对于其他字母数量单词的难度预测还有待研究。
注:本文通讯作者为罗正军。



