何 阳,曲 凯,袁 璞,侯明豆
(1.华北计算技术研究所,北京 100083;2.北京师范大学 地理科学学部,北京 100875)
0 引 言
巡航导弹作为一种无人驾驶的吸气式飞行器[1],可以从陆地、海上或空中发射,以超低空方式飞行,打击敌方纵深内的要害目标[2],具有作战范围广、突防能力强及自主导航等特点[3]。巡航导弹高精度、高生存能力的有效实现主要依靠于巡航路径规划能力[4],使得其能够沿着预先设定好的飞行航线自主飞行。路径规划的主要目的是为巡航导弹提供最佳的突防飞行航线[5],最大限度地提升巡航导弹的突防能力并有效地摧毁预定敌方目标。
目前,典型的路径规划方法有Voronoi 图算法[6-8]、A*算法[9-10]、遗传算法[11-12]、蚁群算法[13-15]和粒子群优化(Particle Swarm Optimization, PSO)[16-17]算法等。其中,粒子群算法凭借着其搜索效率高、算法通用性强的特点,成为了目前包括导弹、机器人、无人机等的路径规划中应用最为广泛的算法之一[18]。然而,PSO 存在着收敛速度慢、在多峰值函数的测试中容易过早收敛等缺点。针对该问题,本文借鉴强化学习算法思路,将Q 学习机制引入PSO 中,实现算法局部搜索和全局搜索的平衡,提高PSO 在快速收敛的过程中发现最优解的准确性,保证巡航导弹路径规划算法能够快速、稳定地搜索到代价更低的路径,有效地提升巡航导弹的威胁规避能力。
1 巡航导弹路径规划问题描述
巡航导弹路径规划有效地弥补了巡航导弹飞行时间长、速度慢、低空突防能力弱的缺点,是巡航导弹进行精准打击、低空突防和提高实战效能的关键技术。理论上的巡航导弹路径规划空间为连续空间,如果在此空间中随机搜索最优航线,搜索空间的指数膨胀将导致搜索的效率极低甚至搜索失败。通过对路径规划空间进行划分可以有效地降低空间规模、路径规划难度,提高规划的效率。
1.1 巡航导弹路径规划问题描述
巡航导弹路径规划空间模型如图1 所示,S点和T点分别被定义为巡航导弹路径的起点和终点,一些深色的圆形区域被定义为危险区,例如雷达探测区、防空导弹杀伤区、高射炮兵杀伤区等。当巡航导弹的部分路径落在危险区内时,巡航导弹经过该部分路径时会面临被拦截的威胁。巡航导弹路径规划的任务是计算一条从S点到T点的最优路径,使得在满足巡航导弹机动特性的情况下,使其受到尽可能少的威胁。
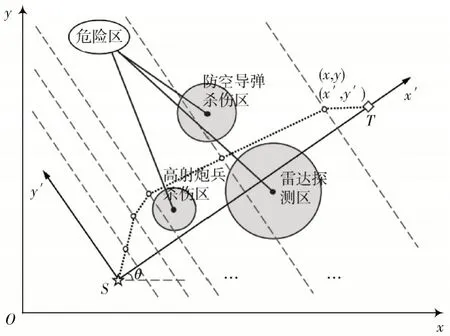
图1 巡航导弹路径规划空间建模示意图
为了进一步量化这个问题,作线段ST并将其平均分为D+ 1 份,基于这些分割点作垂直于线段ST的D条直 线Li(i= 1,2,…,D),取 路 径 点Pi(i= 1,2,…,D) 使 得Pi∈Li,则这些路径点与S、T点组成的集合便构成了一条生成路径,即:
由此,巡航导弹路径规划问题转变为了D维函数的优化问题。最后,将危险区信息从原始坐标系xOy转换到旋转坐标系x′Oy′中。假设S点坐标为(x1,y1),T点坐标为(x2,y2),则原坐标系下坐标为(x,y)的点向新坐标系下(x′,y′)坐标转换的公式为:
1.2 适应度函数
对于粒子群算法而言,适应度函数是描述个体性能的主要指标,其优劣程度直接影响算法的收敛速度以及能否找到最优解。当粒子群算法被用于巡航导弹路径规划问题中时,适应度函数则是生成路径优劣程度的评价标准。
生成路径的主要性能指标包括危险区威胁消耗成本Ji,t和路径消耗成本Ji,f,总成本表示为:
式中:Ji,t为第i个路径段的威胁消耗成本;Ji,f为第i个路径段的路径消耗成本;φ是用于平衡威胁消耗成本和路径消耗成本的加权系数,在0~1 之间取值,当任务更注重降低威胁消耗成本时,φ的取值更靠近0,当任务更注重降低路径消耗成本时,φ的取值更靠近1,在本文所述实验过程中,φ取值为0.3。威胁消耗成本和路径消耗成本的定义为:
式中:ωi,t代表威胁消耗成本权重,与第i条路段和危险区的距离关系相关,是威胁消耗成本的衡量标准;ωi,f代表路径消耗成本权重,在本文所述实验过程中,取值ωi,f= 1。
为了简化威胁消耗成本的计算,将第i条路径平均分为8 份,通过计算第1、3、5、7 个节点与危险区的相对位置关系来确定第i条路径的威胁消耗成本,计算方法为:
式中:Li为生成路径第i个子路径段的长度;Nt为搜索空间中危险区的数量;d40,1,i,k为生成路径第i个子路径段的第1 个节点到第k个危险区的欧氏距离;Rk为人为设定的第k个危险区的威胁等级,在本文所述实验过程中,各危险区的威胁等级均取值为Rk= 3。
2 算法设计
为了改善经典粒子群算法收敛性能差、在多峰值函数的测试中容易过早收敛的缺点,借鉴强化学习思想,在粒子群算法中引入Q 学习机制,提出了基于学习型粒子群算法的路径规划算法,实现算法局部搜索和全局搜索的平衡,提高粒子群算法在快速收敛的过程中发现最优解的准确性,保证巡航导弹路径规划算法能够快速、稳定地搜索到代价更低的路径,有效地提升巡航导弹的威胁规避能力。
2.1 粒子群算法
粒子群算法是一种群智能算法,原理示意图如图2所示。其思想借鉴了鸟群搜索食物源的行为策略,将鸟群中的鸟拟化为搜索空间中的点[19],将其寻找食物源的过程拟化为在问题空间中求解的过程。该过程仅将适应度函数作为评价体系,利用鸟群个体对信息的共享机制,使得整个鸟群不断趋向最大食物源,从而找到问题的最优解[20]。凭借着较强的通用性、易于实现的算法原理及较好的全局最优性,粒子群算法成为了最经典的智能算法之一。
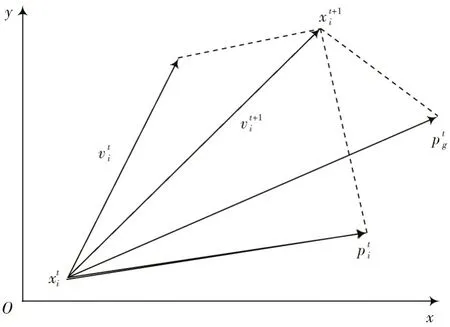
图2 粒子群算法原理示意图
假设存在一个粒子种群,其种群个体数量为M,搜索空间维度为N,记为x=[x1,x2,…,xi,…,xM]T,其中编号为i的粒子位置表示方法为xi=[xi1,xi2,…,xiN]T,粒子的移动速度即为该粒子本次迭代与上次迭代的位置变化,表示方法为vi=[vi1,vi2,…,viN]T,粒子i的个体极值即为该粒子历次迭代过程中所到过的适应度函数值最优的位置,表示方法为Pi=[pi1,pi2,…,piN]T,全局极值即为历次迭代过程中整个种群搜索到的适应度函数值最优的位置,表示方法为Pg=[pg1,pg2,…,pgN]T。由此,粒子的位置与速度的迭代更新方式如下:
式中:vki是编号为i的粒子第k次迭代的速度,vkid为vki第d维分量;xki是编号为i的粒子在第k次迭代的位置,xkid为xki的第d维分量;pki是编号为i的粒子在第k次迭代的个体极值,pkid为pki的第d维分量;pkg是粒子群在第k次迭代的全局极值,pkgd为pkg的第d维分量;ε、η是在[0,1]区间均匀分布的随机数;ω为惯性因子,用来调节粒子速度改变的比例;c1、c2为趋向因子,c1的取值增大会使得粒子在每次迭代过程中更加趋向个体极值,c2的取值增大则会使得粒子在每次迭代过程中更加趋向全局极值。通过引入Q 学习机制,学习型粒子群算法实现了对ω、c1、c2的自适应控制,使得算法能够自适应调节全局寻优性能与快速收敛能力。
2.2 Q 学习机制
强化学习是智能体通过试错的方式进行学习,通过不断尝试不同的动作来得到环境的奖励反馈,最终智能体能够根据累计奖励计算并选择获得奖励最大的动作[21]。Q 学习算法是一种基于无模型、离线策略的时序差分学习算法,在路径规划算法中被经常采用,可用马尔科夫决策过程(Markov Decision Process, MDP)框架来形式化描述[22]。 MDP可用四元组(S,A,P(s,s′,a),R(s,s′,a))定义,其中S是智能体能够处于的所有状态的集合;A是智能体所能够执行所有动作的集合;P(s,s′,a)是智能体状态转移概率函数,代表智能体在做出动作a∈A后使得环境状态s∈S转移到新状态s′∈S的概率;R(s,s′,a)是智能体执行动作a∈A使得环境状态s∈S转移到新状态s′∈S后环境所给予的奖励反馈。
Q 学习算法会建立一个存储智能体状态集和动作集映射关系的Q 表[23],利用奖励函数来给予智能体在某状态下选择执行某动作的奖励,并以此为依据不断更新Q 表。若在某状态下执行某动作后得到了环境给予的正向奖励,则在该状态下执行该动作的Q 值表示会不断增大,否则降低在该状态下执行该动作的Q 值表示[24]。通过不断地试错训练,Q 学习算法会不断地优化更新Q 表,基于贝尔曼公式的Q 表更新公式为:
式中:α为学习率,在0~1 之间取值,表示当前奖励对于Q 表的更新权重;γ为折扣因子,在0~1 之间取值,表示未来对于现在的影响权重;R(st,at)为状态st下执行动作at的即时奖励;Q(st,at)为状态st下执行动作at的潜在奖励期望。
Q 学习算法的常用搜索策略被称为ε-贪婪策略[25],即智能体在选择动作时,将以ε的概率选择Q 表中Q值最优的动作,以1 -ε的概率选择一个随机动作。其算法表达式为:
式中:ε在0~1 的范围内取值,当ε的取值趋近于0 时,智能体仅随机选择动作以探索环境,当ε趋近于1 时,智能体仅选择Q 表中Q值最优的动作以获取最佳奖励反馈;σ是在每次迭代过程中随机生成的一个变量,在0~1 的范围内取值。
2.3 学习型粒子群算法
Q 学习粒子群优化(Q-learning Particle Swarm Optimization, QLPSO)算法借鉴强化学习的思想,将Q 学习算法引入经典粒子群算法框架,并设计状态、动作、Q 表和奖励等方面的策略机制[26-28],以实现对粒子群算法参数的自适应控制。
2.3.1 状态与行为
由经典粒子群算法的原理可知,其粒子状态主要由空间位置状态与适应度状态构成。
空间位置状态指的是粒子与全局最优粒子之间的相对位置距离,分为很近、近、远、很远4 种状态,并记为sd(sd= 1,2,3,4),如表1 所示。

表1 空间位置状态划分关系
表1 中:di为粒子i与全局最优粒子之间的位置距离;D为粒子群与全局最优粒子之间的最大位置距离。
适应度状态是当前粒子与全局最优、最差粒子的适应度之间的相对性能状态,分为小、较小、较大、大4 种状态,标记为Sf(Sf= 1,2,3,4),如表2 所示。

表2 适应度状态划分关系
表2 中:fi为粒子i与全局最优粒子的适应度函数值之差;ΔF为全局最差与最优粒子的适应度函数值之差。其中,粒子i的适应度可以通过适应度函数进行计算。
此外,设定粒子执行的行为有全局搜索和局部搜索两种,在算法执行的90%迭代过程中,粒子执行全局搜索行为,在10%迭代过程中,粒子执行局部搜索行为。全局搜索行为被进一步划分为大幅搜索、小幅搜索、缓慢收敛、快速收敛4 种行为,记为Λd,f(Λd,f= 1,2,3,4)。这些行为所对应的一组ω、c1、c2的参数[29]设置如表3 所示。
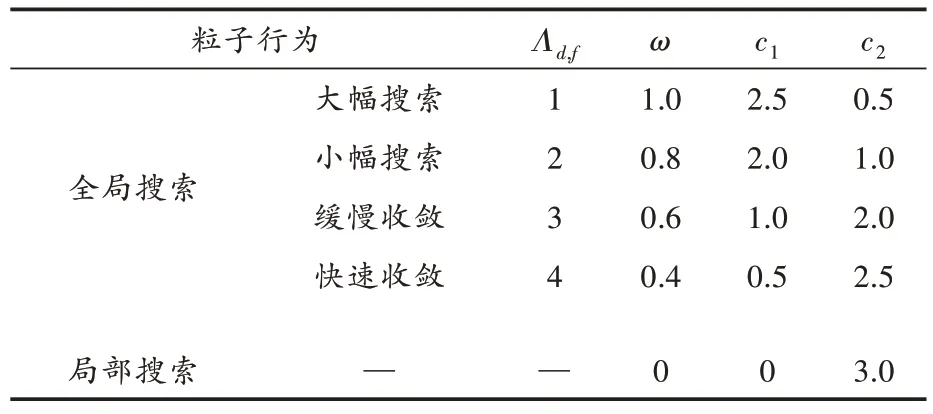
表3 搜索行为参数设置信息
2.3.2 Q 表和奖励
Q 表是状态-动作与估计奖励之间的映射表[30],本文定义的Q 表是一个结合空间位置状态、适应度状态和动作行为的三维表,表中的元素标记为QT(sd,sf,Λd,f)。当粒子要进行状态转移时,根据当前时刻的状态得到sd和sf的 取 值,比 较QT(sd,sf,1)、QT(sd,sf,2)、QT(sd,sf,3) 和QT(sd,sf,4) 的 值,假设四者中最大值是QT(sd,sf,η)(η∈{1,2,3,4}),则选择Ad,f=η,并根据上表选择相应的粒子行为,获取粒子群算法中粒子位置更新所需的参数值。
此外,算法需要观测粒子的行为结果,对相应Q值进行奖励和惩罚,从而不断更新Q 表。即当粒子完成某一行为并得到行为结果后,若其行为结果致其性能表现上升,则奖励对应的Q值;若其行为结果致其性能表现下降,则惩罚对应的Q值。具体的方法为:若空间位置状态为sd、适应度状态为sf的某粒子,根据Q 表执行了Ad,f=η的搜索行为后性能表现上升,则:
否则:
2.3.3 算法流程
根据上述算法思想,设计基于学习型粒子群算法的巡航导弹路径规划算法的运行步骤如下:
步骤1:定义新坐标系原点为巡航导弹路径起点,x轴为从起点出发指向路径目标点的直线,并根据式(2)和式(3),将圆形危险区威胁信息转换到新的坐标系下。
步骤2:初始化粒子群个体Xi(i= 1,2,…,D)。
步骤3:根据式(4)对每个粒子的总成本消耗进行计算,记录消耗最低的粒子的位置信息,并标记所有粒子的空间位置状态和适应度状态。
步骤4:首先确定每个粒子应执行全局搜索或局部搜索。执行全局搜索则根据每个粒子的空间位置状态和适应度状态,从Q 表中读取该粒子应执行的搜索行为,获取其ω、c1、c2的参数;执行局部搜索则直接获取其ω、c1、c2的参数。
步骤5:根据式(8)计算每个粒子下一步的移动速度vk+1id,并记录该速度。
步骤6:根据式(9)计算每个新粒子的位置。
步骤7:根据式(4)计算每个粒子的总成本消耗并更新每个粒子的局部最优位置,记录当前成本消耗最低的粒子的位置信息,并标记所有粒子的空间位置状态和适应度状态。
步骤8:根据式(12)与式(13),更新Q 表中空间位置状态、适应度状态与搜索行为对应关系的权重因子。
步骤9:返回步骤4,直到迭代次数达到要求。
步骤10:计算总成本消耗最低的粒子的总成本消耗及其生成路径信息。
步骤11:将最优路径的坐标点信息变换到初始坐标系下并输出。
2.4 对比的相关粒子群算法
2.4.1 线性递减惯性权重粒子群算法
在经典PSO 算法中,ω作为惯性因子,调节着粒子对当前自身运动状态的信任程度。当ω较大时,PSO 探索新区域的能力增强,能够更快地搜索到全局变量;当ω较小时,局部寻优能力增强,收敛速度更快。所以,当ω数值固定时,其数值的大与小均有一定的优势。线性递减惯性权重粒子群优化(Linear Decreasing Particle Swarm Optimization, LDPSO)算法将ω设置为线性变化的函数,使惯性权重ω随算法的不断迭代从最大值线性减小至最小值,其计算方法如下:
式中:ωmax表示ω的最大值;ωmin表示ω的最小值;t表示算法此刻的迭代数;tmax表示最大迭代数。
2.4.2 基于量子修正的粒子群算法
基于量子修正的粒子群算法(Quantum-Behaved Particle Swarm Optimization, QPSO)假定粒子具有量子行为并处于束缚状态,即被一个以其局部吸引粒子为中心的量子引力吸引。通过选择收缩-膨胀系数,从概率的角度对QPSO 的每个粒子进行分析,提出了全新算法迭代公式:
式中:r是从(0,1)中生成的随机数;pkid是一个局部吸引子。pkid计算方法为:
式中a是从(0,1)中生成的随机数。Gikd的计算方法为:
式中:mbestkd是粒子群的平均最佳位置;β是收缩-膨胀系数。mbestkd的计算方法为:
QPSO 算法有效地降低了算法陷入局部极值的概率,但同时也降低了算法收敛速度。
3 仿真验证与结果分析
为了验证基于学习型粒子群算法的巡航导弹路径规划算法的有效性,在1 800×1 200 的多危险区环境模型 中,采 用Python 编 程 实 现QLPSO 算 法、PSO 算 法、LDPSO 算法和QPSO 算法并进行路径规划仿真试验,设置导弹发射点坐标为(1 600,900)、攻击目标点坐标为(200,200),危险区信息如表4 所示。
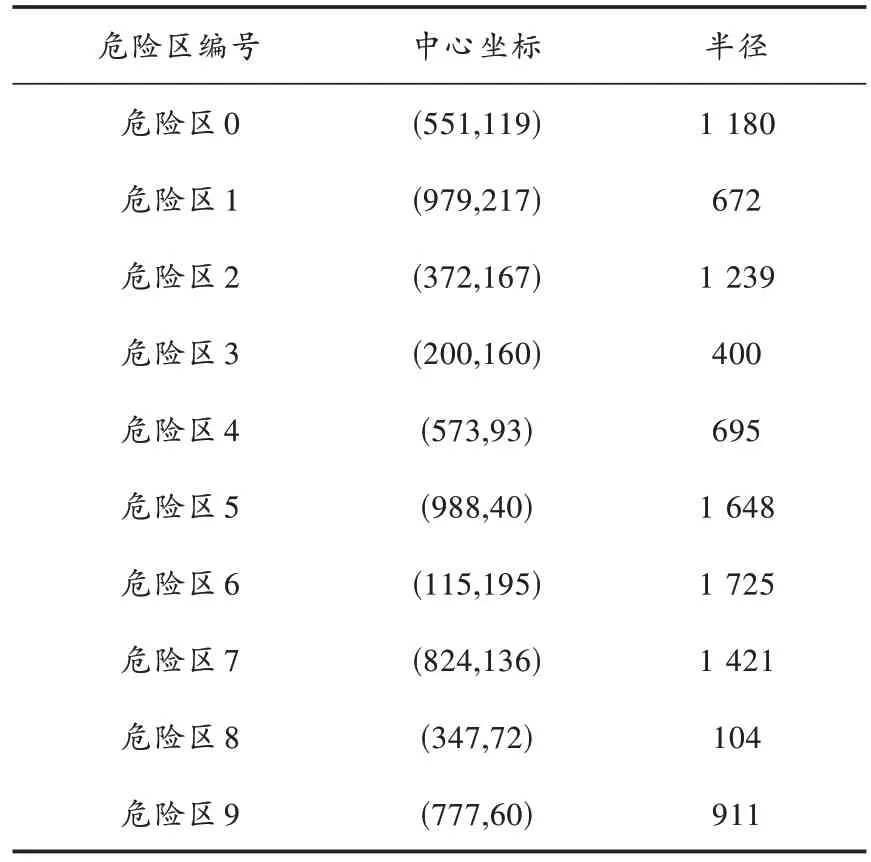
表4 仿真验证场景信息
对于QLPSO、PSO、LDPSO 和QPSO 这4 种粒子群算法,分别设定其初始参数如表5 所示。
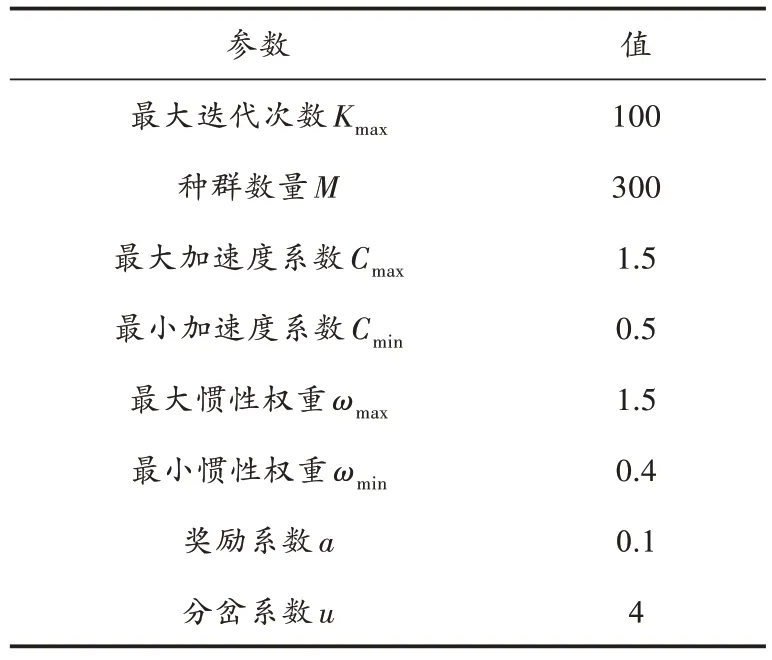
表5 粒子群算法初始参数设定
图3 和图4 分别给出了该仿真场景下4 种粒子群算法的收敛曲线及最优路径规划图。
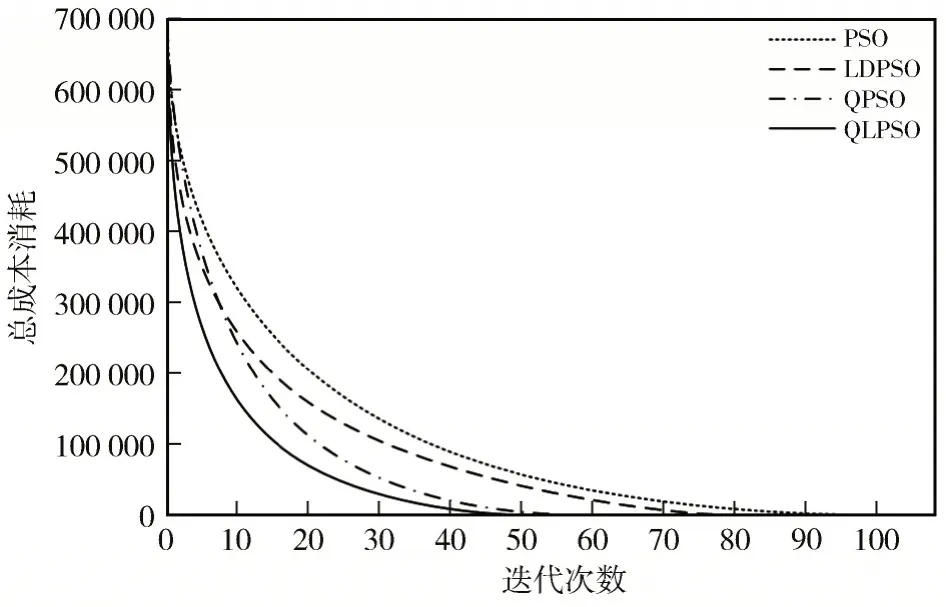
图3 算法收敛曲线图
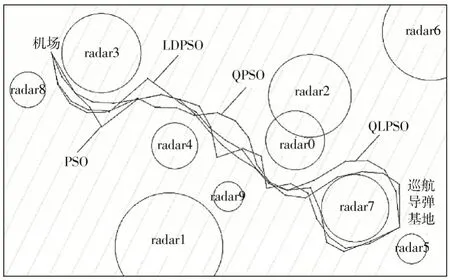
图4 路径规划图
由图3 和图4 可知,4 种算法在给定的环境模型中均能够输出一条可行的生成路径,使得巡航导弹能够从发射点顺利地到达攻击目标点,但QLPSO 算法生成的规划路径较为平滑且路径长度相对较短。此外,QLPSO算法的收敛性能也要明显优于其他3 种算法。表6 总结了4 种算法在该环境模型中重复运行50 次的数据结果,可以看出,QLPSO 算法相比于其他粒子群算法总能够寻找到最优路径,且算法的标准差远小于其他算法,曲线离散程度低。仿真结果表明,将强化学习思想引入PSO 算法后,不仅改善了算法的寻优稳定性,也较大地提升了算法的收敛性,降低了算法收敛到最优路径的时间。
4 结 语
本文针对巡航导弹的作战特点,提出了一种基于学习型粒子群算法的巡航导弹路径规划算法,针对经典粒子群算法做了以下改进:
1)将粒子群算法中的惯性权重和学习因子由线性值转化为非线性值,有效地规避了局部最优陷阱;
2)将粒子群算法与强化学习思想结合起来,将意识赋予粒子群体自身,提高了算法的收敛性。
此外,本文设计并实现了相关仿真实验,验证了该算法在巡航导弹路径规划情景下的可行性和有效性。仿真结果表明,学习型粒子群算法能够比较好地解决巡航导弹路径规划问题,相比其他一些经典的粒子群算法,总成本消耗更小,且在收敛速度上有明显提升。



