马锐敏
摘 要:针对微观经济主体的调查数据为健全货币政策调控框架、完善宏观审慎管理体系提供了高效的微观信息保障,在中央银行的决策中发挥着重要作用。国外部分中央银行开展微观居民调查起步较早,逐步建立了比较成熟和系统的调查体系,通过科学规范的设计实施方案确保了数据质量准确可靠,调查成果在深化学术研究和服务宏观决策方面成效突出。本文对国外央行居民调查项目的设计框架、实施机制、数据运用等进行了深入分析比较,相关经验对我国完善微观调查有重要借鉴作用。
关键词:微观居民调查;抽样设计;数据价值
DOI:10.3969/j.issn.1003-9031.2022.05.008
中图分类号: F833;F837 文献标识码:A 文章编号:1003-9031(2022)05-0080-08
一、引言
居民是社会最基本的行为主体,是宏观政策决策的出发点和落脚点。自20世纪80年代以来,美国等发达国家陆续启动了针对微观居民个体的调查项目,主题涵盖消费者金融状况、家庭经济生活、民众社会预期等多个方面。数据成果不仅填补了针对微观主体的学术研究空白,还产生了广泛而积极的社会效应。在学术方面,居民调查发布的数据丰富了研究视角,拓宽了学术研究的广度和深度。在社会效益方面,调查数据为重大政策问题的研究与讨论提供了有效信息参考,如相关国家借助调查成果在家庭资产负债配置与消费行为、收入分配与经济发展、公众经济预期与央行货币政策操作等诸多宏观经济政策方面进行了深入探究。
国外部分国家开展微观居民调查起步较早,经过长时间发展,逐步建立了比较成熟和系统的调查体系,在抽样设计、指标选取、组织实施、数据运用等方面形成了一套科学详细的方案。本文详细归纳了国外居民调查项目的抽样设计框架,全面总结了调查组织实施过程中的主要做法,并结合国际经验提出了我国开展微观调查的一些借鉴和启示。
二、抽样方案的设计
(一)构建完备的抽样名录和选择合格的填答者是保证数据质量的基础
一是充分依托各类资源和辅助信息构建完备的抽样名录。居民调查面对数量众多、层次丰富的个体单元,根据调查主题在庞大的群体中精准识别目标单元是构建优良抽样框的前提,这就需要充分借鉴已建立的各类名录以及个体多维度的识别特征。一类是依托现有的其他抽样名录。如美联储理事会主管的居民经济和决策调查(SHED)的初级样本框选择了由调查执行机构GfK公司基于地址抽样(ABS)方法建立的、具有全国代表性的商业样本库Knowledge Panel。纽约联储负责的消费者预期调查(SCE)的受访者均来自消费者信心调查(CCS)。另一类是选择合理的个体识别特征建立样本框。如纽约联储建立的消费者信用面板数据库选择对初级样本单元覆盖全的美国居民社会安全号码(SSN)作为抽样名录。SSN对居民的广覆盖和一一对应性,赋予了其作为辅助信息构建完备样本框的特性。
二是根据调查目的和内容,在选择主要受访者方面均有要求。美联储的消费者金融调查(SCF)要求由调查家庭的户主、或者是家庭中财务知识较丰富的成员受访。消费者信用面板数据库的目标人群仅包括拥有信用记录的美国公民,18岁以下没有信贷需求或机会以及从未申请过贷款或没有资格申请贷款的消费者不包括在内。英格兰银行的公众通胀态度调查(IAS)受访对象为年龄超过16周岁的成年人,借助年龄门槛锁定目标人群。
三是兼顾数据需求和实施成本设计样本轮换周期。固定样本设计能够持续跟踪相同个体,建立面板数据库满足多方面研究的需要,但面访方式下固定监测的实施成本较随机抽取通常更高。一般而言,区域跨度较大、间隔周期较长、以面访为主要方式的项目在每期调查前样本会重新抽取更换,而高频调查为减少抽样波动对数据序列的影响,更倾向于设计较长的样本轮换周期。如按年度开展的全国性家庭或个人调查项目(HFCS、SCF等),每期样本会根据抽样设计重新抽取。而SCE这类旨在收集及时、高频数据的项目,为了提升调查结果的精确性,抽样设计采取轮换小组(每一个家庭在连续12个月参加调查后将被轮换出样本),以便能够跟踪同一个体、减轻月度间样本变动带来的数据波动;同时,持续一段时间跟踪同一家庭,能够准确了解家庭内部叙事和预期,还可以研究消费、收入等关键变量预期的交互影响。
(二)主要采用分层抽样和补充抽样来确保各子群体的入样概率
针对居民或居民家庭的问卷调查,抽样设计主要采用了分层多阶段概率抽样和补充抽样两种方式来确保样本对总体的代表性。
一是分层多阶段概率抽样。分层抽样适合于变量值差异较大的总体,其基本原理是异质性较强的总体分成若干个同质性较强的子总体,从中分别抽取样本合并后代表总体。其优势在于,每层抽样的独立进行,每层可选择适合本层的不同抽样方法,同时也可对各层进行参数估计,而不单是对整个总体的估计。因此,分层技术在区域跨度较大的项目中,如全球性、全国性调查中被广泛应用。
纽约联储的消费者信用面板数据库、CCS、以及欧央行的家庭金融与消费调查(HFCS)均采用了分层随机抽样方法。首先,采取符合各国实际的方式确定广泛的初级抽样单元,再根据调查意义确定各个阶段的分层指标,同时通过控制分层指标权重或引入附加指标的方式来控制抽样中的误差问题,从而保证各子群体的入样概率。如消费者信用面板数据库每季使用相同标准对居民社会安全号码进行5%的随机抽样,由于个人社会保险号码最后4位数字是按申请的时间顺序随机分配,此种抽样方法能够自动捕获进出目标人群的新流量,从而避免了静态面板随着时间推移代表性弱化的缺点。CCS的初级抽样框依靠美国邮政服务地址库①建立,再根据性别、收入、地域和年龄指标分层,并选择权重,以最大限度地增强样本的代表性。HFCS调查各国在分层指标的选择上,均使用了地区、区划单位人口规模等主要指标,部分国家还引入了其他一些附加指标,如卢森堡和芬兰使用个人收入、就业状态,西班牙使用个人应税财富数据等,以满足每个参与国家的样本能够代表本国以及整个欧元区总体分布特征的要求。
二是补充抽样。各国在关于居民或家庭金融调查的抽样设计中,对于富裕群体都给予了特别关注。原因在于:家庭财富分布存在不均衡现象,导致分位点较高的家庭占社会总财富的比例更高;资产配置结构有其特性,由于财富分布是倾斜的,因而某些类型的资产只有一小部分顶端家庭拥有。从理论研究角度看,等概率抽样由于每一单元都有已知的被选概率,对于偏态分布的总体并不适用,而不等概率抽样通过调整入样概率来平衡样本分布,因此对于具有群结构的总体而言,在初级抽样单元层次上的不等概率抽样比等概率抽样对总体有更好的代表性。
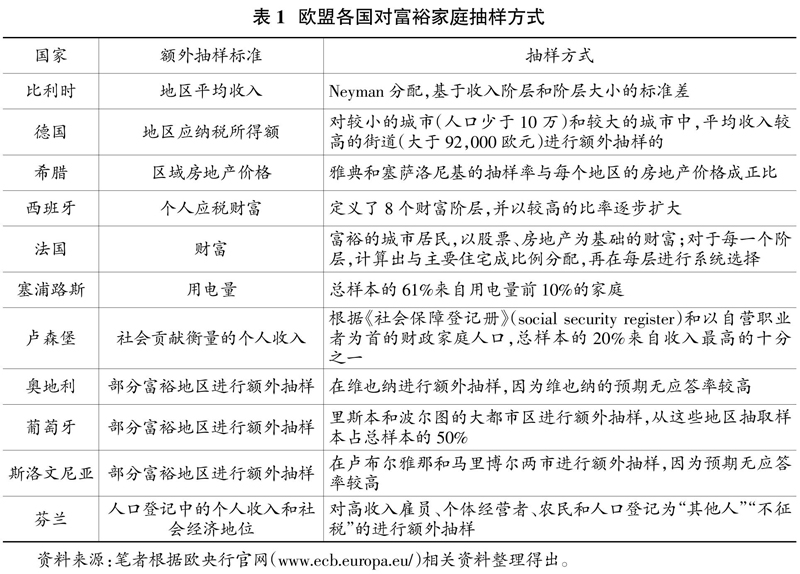
从实践操作看,SCF和参与HFCS的部分国家采用了不同策略对富裕家庭进行补充抽样,抽样设计是先通过技术手段构建针对富裕家庭的抽样框,再按照一定方式进行补充抽样。如SCF的额外样本框称为列表样本,该方式下的抽样是基于美国税务局收入统计司(SOI)从个人所得税申报表②中提取的关于个人收入税收的信息文件,该份文件覆盖范围是包括高收入群体在内的极有可能成为富人的纳税者,因而将其作为富裕家庭的样本框是适当的。SCF建立了从应税收入到财富的映射函数来测算所有税务申报人的“财富指数”,再通过“财富指数”的百分比分布将抽样地区的样本划分为七个层次,其中顶层抽样阶层(第4、5、6、7层)覆盖了前1%富裕的样本,接下来每层再根据收入和年龄进行次分层的PPS抽样设计。HFCS开展的两轮调查中有相当比例的国家对富裕家庭进行了补充抽样。各国虽在抽样标准的选择上差别很大,但都高度依赖于现存的数据,主要以区域一级的收入和(或)财产价格信息为基础(见表1)。
(三)采用技术手段事后修正数据提高样本代表性。
一是针对无回答现象,采用插补技术估算缺失值或后分层方法调整调查无响应。如SCF依据外部渠道的可得数据构建模型来补充项目无回答的内容。具体做法是对丢失的数据进行多次重复估算,以估计这种类型的无响应导致的不确定性,再采取插值法加以弥补。德国家庭金融调查(PHF)通过重复提取数据条件分布的估值来模拟单个插补值,估算所有主要缺失变量的观测值。SHED则选取年龄、性别、人种、族裔等指标作为权重调整变量,通过后分层方法来调整由于研究特定样本而产生的调查无响应以及非覆盖或欠采样和过采样。
二是根据数据使用需求来调整样本权重提升估计值精度。如消费者信用面板数据库若仅针对被抽样的个体消费者进行分析,则不需要引入权重调整,因为该个体样本组是代表目标人群5%的随机样本。但以家庭为单位进行分析时,考虑到采用的抽样方法可能对人口多的家庭进行过度抽样的事实,就需要使用权重保证样本家庭能够代表一国的目标人群家庭,并获得对人口特征的无偏估计,家庭层面分析时的权重等于目标群中给定家庭被包括在样本中的概率的倒数。
三、问卷题目的设置
(一)保持问卷核心内容稳定,提高数据的纵向可比性
SCF问卷会随着每次调查不断修改,新问题不断增加,但自1989年以来,调查问卷的核心内容变化不大。2016年的调查对教育程度、教育贷款和支付方式部分进行了修订,并新增关于受访者财务知识、父母教育程度和假设不同财务状况下的决策问题,新增问题的设置尽力确保数据在一段时间内具有最大程度的可比性。日本央行的民意调查自1993年启动以来,问卷在宏观经济形势看法、家庭经济状况感受、物价走势判断和央行政策信誉四大板块的结构一直保持稳定,从而形成了极具研究价值的调查时序数据。
(二)适当引入定量问题提供有价值的信息/观点
过去习惯使用的定性问题(“非常满意”“基本满意”“可以接受”“不满意”)虽易于理解,但具有选项设计粗略、缺乏对不确定性的精确衡量、缺少个体之间和个体内部可比性的缺陷。为提高估计值的精度,SCE引入了关于概率预期的定量问题。定量问题大致分为三类:对双边结果产生预期的问题(如股市在12个月内增长的可能性);对未来持续结果的逐点期望问题(如未来12个月的通货膨胀率);引起受访者对未来连续结果预测的概率密度问题。这三类问题能够对受访者整体的不确定变化性提供一种量化方法:点预测能够获得具体的调查结果,这对宏观决策部门的参考意义重大;对未来持续事件的双边结果概率预期和密度预测则为不确定性提供了更清晰全面的度量维度。
四、调查项目的组织开展
(一)调查访谈方式高度契合调查项目需求
调查访谈方式是影响数据质量重要的方面,国外居民调查主要采取面访和网络在线调查两种方式。对于问卷设置较为复杂、非高频的调查项目,普遍采取的是目前公认质量控制较好的计算机辅助面访(CAPI)方式,如SCF、HFCS和PHF第一阶段等。专业的面访官能有效减少单元无回答和项目无回答现象发生、降低受访者理解偏误、同时在当面交流过程中获取更多调查信息。而计算机程序系统的实时校验功能则最大程度保证了一手数据的准确性。因此,CAPI从根本上满足了大样本复杂问卷调查对样本配合性、操作规范性和数据真实性的要求。
对于高频调查或是出于持续跟踪样本的需要,调查主要依靠网络进行。如SHED是完全网络在线进行的。除成本优势外,在线采访可以相对轻松地持续追踪同一受访者,此外网络调查能够保存受访者的历史数据信息,通过以往的填答情况自动跳过不相关问题,减轻受访者的负担。SCE作为月度调查项目,采用的是美国需求研究所开发的互联网平台开展调查,平台借助视觉辅助工具等手段方便受访者理解和填答特定问题。
(二)提高调查公信力和知晓度、提升访员专业性、争取受访者应答是降低拒答率的主要举措
一是多举措提高调查公信力和知晓度。如韩国家庭金融福利调查在开展期间,政府官网上会出现动态标语,基层政府部门的办公大楼悬挂横幅,电子屏幕上展现宣传标语,并在调查区发放传单。SCF在调查启动阶段,会通过邮件向受访者简要介绍调查项目,同时附上联储主席签署的邀请函。在开展HFCS期间,意大利央行会首先向受访家庭发送预先通知信,告知调查的目的和重要性;同时提供央行工作人员的联系方式,解答受访家庭疑虑。西班牙家庭金融调查在邀请邮件中同时提供了确认调查合法性的网站和电话号码。
二是确保访员的专业水准。如SCF的数据收集工作由社会专业调查机构NORC执行;参与HFCS的20个国家中,访员是政府统计部门职员或指定的专业外部调查机构工作人员。在各项调查中,对访员的专业化培训均是调查执行前必要的步骤。
三是尽力争取受访者应答。如SCF将访问过程分为三个阶段,第一阶段,访员当面拜访受访家庭,通过介绍项目意义、提供奖金激励等方式获取受访许可;若未获得认同,在第二阶段,仍通过当面拜访或邮件方式,采取增加奖金额等手段,再次争取受访同意;在第三阶段,允许访员采取任何认为有效的方法获得调查同意,这一阶段对受访者完成调查的激励也从基础的50美金提升到300美金的上限。PHF对于第一阶段未完成调查的家庭,6个月后启动第二阶段,在第二阶段要求访员每周至少要与每个待调查家庭联系一次,同时对在该阶段完成调查的访员提供额外奖金。奥地利的家庭金融调查中,访员在邀请函发出后,需至少两次实地拜访样本家庭,其中至少有一次是在周末。
(三)对无回答样本的替换较为谨慎
在抽样理论中,无回答现象会对概率样本造成损害,从而影响调查质量。因此对于单元无回答现象,各调查项目均要求了严格的换样步骤以减少无应答误差。如HCFS为降低无回答造成的偏差,会尝试再次联系拒访家庭。西班牙家庭金融调查为样本中的每个原始家庭提供最多4个替换家庭,替代家庭必须与样本家庭属于相同的财富阶层,且在抽样框中紧挨抽样家庭前后两位,同时替换家庭地址与原始样本家庭的距离不能太远。意大利央行对于调查过程中无法联系到的家庭由同一城市中随机选择的其他家庭替代,但样本替换有严格制度来规定何时可以更换,并指定要调查的新家庭。
五、调查数据成果的运用及价值
(一)灵活、实时的数据来源,为宏观政策决策提供了重要信息保障
宏观经济数据能够翔实记录国民经济发展状况,但数据生产流程长、耗时多、时效慢。调查工作凭借组织实施的灵活性和数据发布的时效性,为经济前景评估和政策决策提供了一手高效的信息支撑。如新冠疫情反复导致投资、就业和消费等指标出现较大波动,微观主体对经济前景的不确定性作为解释经济边际变化的重要补充指标,受到了政策制定者的关注。基于此,欧盟委员会在其月度商业和消费者经济调查(BCS)中,通过在问卷中增加受访者对经济运行和家庭收入状况的预测难度问题,合成了经济不确定性指数,此类指数较传统的离散度指标不仅更客观合理地反映了经济走势边际变化,还能揭示结构性的分类信息,为宏观部门出台前瞻性的政策举措提供了极强的信息保障。
(二)丰富学术研究视角,拓宽了学术研究的广度和深度
微观调查数据库数据条目多、指标种类丰富、结构性特征多样,与宏观数据相比,为学术探究提供的视角更广泛。如SCE通过收集居民对各类经济生活预期和决策的数据,不仅填补了家庭部门预期和行为之间关联性数据的空白,也为政策预期管理提供了重要信息参考。因为只有准确掌握居民预期的形成路径和机理,才能有效监测并做好预期管理。学术界借助SCE搜集的消费者对某些具有连续结果事件(如未来通货膨胀、收入和房价)的主观概率分布数据,构建中心趋势(如密度平均值或中值)、不确定性和感知尾部风险的个体度量(如极端积极或消极结果的概率)等一系列指标,来刻画预期与行为之间的联系,为宏观决策部门做好政策预期管理、提高政策效能提供了宝贵的智力支撑。再如,美联储在其网站上公布了一系列基于历年SCF数据所撰写的工作论文,主题涵盖社会居民财富分配状况、税收制度的再分配效应、富裕人群收入和财富积累途径等多个领域,相关研究成果为促进经济社会发展提供了极具价值的微观视角。
六、启示
(一)积极发挥微观居民调查数据在深化学术研究和服务宏观决策方面的作用
住户部门既是消费者、又是投资者、也是社会资金的主要供给者之一,因此与微观居民个体相关的数据在学术探索、政策管理和社会治理等方面意义重大。居民调查数据的指标体系丰富多样,既拓展了数据视角,又凭借时效性发挥了重要的信息保障作用。
一是居民调查项目作为重要的基础性资源,能够填补居民或家庭的微观数据空白。来自调查的一手数据蕴含广泛信息,具有重要的经济价值、社会价值和学术研究价值。特别是在当前共同富裕的战略背景下,与居民个体息息相关的民生数据对于实施路径探索、政策效果评估都发挥着极强的信息参考价值。
二是调查数据凭借深入刻画总体内在结构性趋势的优势,与宏观数据有机结合,能够全面真实地揭示经济社会发展的趋势和规律。单一的宏观数据并不能客观反映各子群体的真实情况,借助调查触角的延展性,宏、微观相结合的数据在对总体以及各子群体上的画像,以及把握形势变化上将更加精准有效。
(二)调查设计科学合理,夯实数据质量,提升数据研究价值
一是抽样设计科学,确保样本代表性。抽样方法上,合理的分层通过实现层间方差尽可能大、层内方差尽可能小,从而能够保证各层抽到的样本单位对本层具有较好代表性。考虑到居民调查目标多、总体单位差异大,因此多目标分层抽样技术被普遍采用;在各层间的抽样中,由于不同单元在总体中所占地位不一致,PPS系统抽样在实践中有着广泛的应用。抽样方式上,初级抽样单元的广泛性决定了是否需要针对两端人群补充抽样。若调查设计的单一抽样框未能基本实现对目标总体完整覆盖、或是总体具有明显偏态分布特征,则需要采取额外抽样方式补充两端小规模群体的样本,以保证样本结构与总体一致。
二是问卷设置合理,聚焦调查目的。问题选择上,紧扣调查意义设置与研究主题密切相关的题目;同时在保持核心板块稳定的前提下,通过灵活增加新问题增强数据靶向聚焦能力。问卷测试上,充分借鉴认知心理测试实验论证、专家审查评估和田野试访实践反馈等多种形式,不断完善问卷以增强受访者填答的精确性,尽可能减少因受访者未能正确理解问题、叠缩效应等原因产生的非抽样误差。
三是调查实施有效,避免执行偏差。通过精细化流程控制提升调查质量,减少因无法从样本单元获取调查信息引起的无回答误差、或是由受访者或测量手段所引起的计量误差。
四是借助技术手段提升数据准确性。利用插补技术修正无回答现象对样本质量的损害,引入权重提高估计值的精度。■
(责任编辑:张恩娟)
参考文献:
[1]Arthur B Kennickell.The Good Shepherd: Sample Design and Control for Wealth Measurement in the Survey of Consumer Finances[EB/OL].[2021-12-03].https://www.federalreserve.gov/econresdata/scf/files/samplingperugia052.pdf.
[2]Arthur B Kennickell.Wealth Measurement in the Survey of Consumer Finances: Methodology and Directions for Future Research[EB/OL].[2021-12-05].http://www.federalreserve.gov/econres/scf_workingpapers.htm.
[3]Bank of England.Bank of England/Kantar Inflation Attitudes Survey[EB/OL].[2022-01-12].http://www.bankofengland.co.uk/inflation-attitudes-survey/2020/november-2020.
[4]Bank of Japan.Results of the 88th Opinion Survey on the General Public’s Views and Behavior[EB/OL].[2022-01-12].http://www.boj.or.jp/en/research/o_survey/data/ishiki2201.pdf.
[5]De Heer W,De leeuw E.Trends in household survey nonresponse:A longitudinal and international comparison[J].Survey Nonresponse,2002(41):41-54.
[6]European Central Bank.The Household Finance and Consumption Survey:methodological report for the second wave[EB/OL].[2020-06-05].http://sdw.ecb.europa.eu/reports.do?node=1000004952.
[7]Gosselin M Khan.A Survey of Consumer Expectations for Canada[J].Bank of Canada Review,2015(8):14-23.
[8]Harkness J A,Braun M,Edwards B.Comparative Survey Methodology[J].Survey methods in multinational, multiregional and multicultural contexts,2010(5):1-16.
[9]Iannacchione V G,Staab J M,Redden D T.Evaluating the use of residential mailing addresses in a metropolitan household survey[J].Public Opinion Quarterly,2003(2):202-210.
[10]Jesse Bricker,Richard Windle.Contacting Strategies and Increased Incentives during the Field Period:Evidence from the SCF[EB/OL].[2021-12-22].http://www.federalreserve.gov/econres/scf_workingpapers.htm.
[11]Natalie Shlomo,Chris Skinner.Barry Schouten Estimation of an indicator of the representativeness of survey response[J].Journal of Statistical Planning and Inference,2011(1):142-145.
[12]Olivier Armantier,Giorgio Tbpa,Wilbert van der Klaauw,Basit Zafar.An Overview of the Survey of Consumer Expectations[J].FRBNY Economic Policy Review,2017(12):51-72.
[13]PA Glasow.Fundamentals of survey research methodology[J].Retrieved January,2005(1):47-64.
[14]Pradeep Chintagunta,Ekaterini Kyriazidou,Josef Perktold.Panel data analysis of household brand choices[J].Journal of Econometrics,2011(1):103-108.
[15]Shelley Andrew,Horner Keith.Questionnaire surveys-source of error and implications for design,reporting and appraisal[J].British Dental Journal,2021(4):251-258.



