朱雨晗
(浙江省富阳中学,浙江杭州,311400)
1 研究背景
近现代以来,随着以通信技术和计算机技术为代表的信息技术得到快速发展的同时也带来了海量的数据积累,如何在这些琳琅满目的数据中找到自己所需要的东西成为难题。在这种背景下,推荐系统能够实现在信息过载的环境下为人们提供其感兴趣的信息消费需求方案[1]。虽然推荐系统只有几十年的发展,但已基本成为互联网各个领域的标配,如抖音的“朋友圈”、今日头条的“关注”,淘宝的“猜你喜欢”等。
虽然推荐系统给我们的生活带来了诸多便利,但其仍存在个性化程度不足、推荐精度低、受干扰信息影响大等缺点。个性化推荐系统的目标用户是单独个体,每个人的兴趣偏好不尽相同,然而许多网站的推荐系统只是泛泛而谈,将有一定差别的用户兴趣属性一视同仁,导致所给出的推荐项目针对目标太广泛,不具有很强的个性化,对一名用户的实际帮助程度有限。如果一个用户把他的社交应用的账号分享给了兴趣与他不同的一位好友,或者用户自身浏览了一些文章却发现自己对其兴趣不大,那幺这些实际上并不是用户兴趣的东西就会成为推荐系统输入端的干扰项,影响推荐结果的准确性。进行重要性赋权能够降低这些干扰信息和一些用户恶意输入的错误信息的影响。新的应用,或者新的用户往往没有足够的用户数据来支持推荐。此外,大众文化和社交环境的碎片化导致了信息的碎片化,使得不同的应用无法获得足够的用户信息,对用户的兴趣属性很难有一个精准的定位来进行准确的推荐。
针对这些缺点,本文使用了混合推荐系统,将协同过滤推荐和基于兴趣标签的推荐进行组合,试图排除无关或恶意信息的干扰,增加推荐精确度,并解决因用户数据不足导致推荐系统输入较少或推荐不准确的问题。
2 思路阐述
■2.1 传统的推荐算法
当前社会主流的推荐方法有基于内容推荐、协同过滤推荐、基于关联规则推荐、基于知识推荐、组合推荐等。下面将简单的介绍本文所使用到的协同过滤推荐、基于内容的推荐和混合推荐。
协同过滤推荐一般采用最近邻技术,利用广大用户信息计算用户行为的相似性,然后将计算出的对等用户对物品的评价进行赋权,以此预测目标用户对特定物品的偏好。其最大的优点是对推荐对象没有特殊要求,不需要了解其本身的性质,能够处理难以结构化的复杂对象,如视频和音乐,但也存在数据稀疏问题和可伸缩性问题。
基于内容的推荐是根据项目的主观定性特征与目标用户资料的匹配程度进行推荐的。其优点在于:不需要其他的用户数据,没有协同过滤那样的数据稀疏和冷启动问题,能够为兴趣冷门的用户提供良好的推荐并解释推荐原因。缺点是需要有物品特征与和用户偏好的结构化描述,且用户的兴趣本身会随着时间改变。
这个时候就可以考虑组合推荐算法,常见的组合方法有加权、变换、混合、层叠、特征扩充等,其通常是用多种推荐方法各得出一个推荐预测结果,然后在通过以上某种形式进行组合,这样便可以弥补各种推荐算法的缺点,以便得到更将精确的推荐结果。
■2.2 标签的设立
在基于标签的推荐算法中,标签是维系用户和物品之间的纽带,也是提供用户兴趣的重要数据源[2],根据什幺要求怎幺设置标签、如何存储标签是基于标签的推荐算法研究的重要课题。
标签的设立方法主要有:提取待推荐物品的关键字和目录,提取出现频率高的字词,或者直接使用用户输入的兴趣标签。LOFTER就是一个标签系统的典型代表,它支持用户自主输入和创立标签,并根据用户关注的标签推送文章。这种用户自主输入的标签能够较主观的体现出一篇文章的特性,但是有的时候也不是能准确的描述物品内容属性的关键词,所以此时便需要我们人工编辑一些特定的标签供用户选择[3]。当将文章用出现频率高的字词作为标签来表示时,需要先删除所谓的停用词,如英文中的介词和冠词“a”“in”和中文里的“的”“和”等,这些字词几乎会出现在所有文档中且频率极高且无用,因此需要删除。文章本身自带的目录能够为设立标签提供参考,但毕竟有的文章目录标题因不能很好的概括出文章本身内容,所以不能直接作为标签使用。此外,标签本身还具有噪声、歧义、冗余等问题,给基于标签的推荐技术研究带来了挑战。好在用户兴趣的动态性、渐变性和稳定性这三个特性能够反映相对稳定的用户需求[4],能够有效的避免这些问题。
■2.3 基于标签的推荐算法
目前,有许多学者在关于兴趣标签的推荐算法上开展了许多相关的研究工作。下面将介绍三种具有较大意义的标签推荐算法,这些算法或优化了传统的推荐方案或建立了新的模型,有效提高了推荐系统的准确率和召回率。
2.3.1 基于张量分解的个性化标签推荐算法
学者李贵、王爽、李征宇、韩子扬、孙平、孙焕良,为有效取得用户、物品、标签三者间潜在的关系,引入三维张量模型。在基于标签元数据构建初始张量的基础上应用高阶奇异值分解减少标签的噪音。核心思想为:首先构造一个表达了用户、标签、物品三者所以关联数据的初始张量A,其次对其进行n-模矩阵展开,形成三个新的矩阵。然后在新的矩阵中分别进行SVD计算用以构建新的核心张量,计算近似张量A。此算法有效的提高了推荐系统的效率和准确率[5]。
2.3.2 基于三部图张量分解标签推荐算法
学者廖志芳、李玲等在此论文中基于三部图作为标签系统的表示方法,虽然简化了元素间关系的表达,但却丢失了系统间的部分联系,且无法有效处理标签存在的稀疏值和缺失值数据的这些问题,提出了基于三部图的三维张量分解推荐算法(TTD算法),通过不断迭代最终取得最优值。此算法优化了缺失值部分,解决了信息丢失问题,效率较高,且显着改善了推荐预测结果的准确率,但算法复杂度不够[6]。
2.3.3 基于用户兴趣-标签的混合推荐方法研究
学者李兴华、陈冬林等将兴趣与标签相结合。通过定义计算用户兴趣权重值、用户兴趣相似度、用户候选兴趣集、推荐兴趣-标签集、并从中选取项目推荐集满足某值域的项目推荐集作为推荐预测结果进行输出。此过程可以有效的提高推荐结果的准确率,但由于所涉及的兴趣比较少所以不够完善,算法复杂度也有待改进[7]。
本章节大致介绍了协同过滤、基于内容的推荐和混合推荐这几种常用的算法,提出了在如何设立标签上的想法,并总结了一些前辈们在基于标签的推荐算法上开展的相关研究工作以及成果和优点,接下来本文将详细阐述本文的思路和算法。
3 基于兴趣标签的混合推荐算法实现
一些非文本的内容,比如视频与图片,由于本身就缺乏相应的描述文本,所以将兴趣标签作为一种直观且重要的介绍素材,而用户本身行为的多样性决定了用户的兴趣难以被定义,所以可通过用户感兴趣的标签来确立用户的偏好并推荐。
针对用户兴趣标签的不准确定位,本文提出该算法:通过用户对各种标签的浏览时间、次数、以及用户自己输入的自我认同的标签来为用户确立个性化的兴趣标签,并以此为基础实行协同过滤与基于内容的混合推荐,具体过程如下。
■3.1 兴趣标签的设立
确立物品的明确标签。这个步骤通常采用提取目录和介绍内容的方法,或者直接使用发表作者自行打上的tag。对于作者自行打上的标签,第一个标签基本代表作者对自身或者其作品的第一印象,可赋稍高的权值。以小说为例, 建立矩阵E表示一个作品的标签w表示该标签的权重,用向量表示一个作品用这些标签表示的量,则={w·1,1,1,0,0,0,0,…};={0,0,0,1,0,1,0,…} (w 即为该标签的权重)
对目标用户的行为数据进行采集。以小说为例,记录用户对有各种标签的小说的短期浏览时长或次数,长期的浏览或浏览次数,以及直接或间接给出的对该小说的评价。根据标签的详细程度建立用户兴趣标签体系。越详细的标签赋予越高的权重。建立集合A、B、C,分别表示用户浏览某一标签的短期次数,长期次数, Di= (Di+ ti⋅Ai⋅ Wi)⋅p 评论,标签在该小说中本身的权重w,因此建立数集D用来量化与储存用户对某一标签的兴趣程度。
t的值与目标用户评论高低有关,若用户评论较少则选取小说总体评价。P为时间衰减系数,用户行为距当前时间越近的影响越大,因此从用户标签上可以反应该用户最近的兴趣点。
将短期浏览次数多且给予高评分的设定为用户暂时性的兴趣标签,将长期浏览次数多的设定为用户稳定兴趣标签,分别表示为、,向量、表示了一个用户的短期兴趣和长期兴趣。用传统的余弦相似度计算与目标用户偏好最为相同的4、5个用户,取他们的兴趣标签集的交集,再与向量计算相似度,按照相似度排序进行推荐。
■3.2 算法步骤的实现
针对用户兴趣标签的不准确定位,以及标签本身存在的噪音和冗余问题,本文提出了机遇用户兴趣标签的混合推荐算法。通过用户对各种标签的浏览时间、次数、以及用户自己输入的自我认同的标签来为用户确立个性化的兴趣标签,以提高对用户兴趣标签的定位的准确性,并以此为基础,通过短期兴趣向量和长期兴趣向量表现出用户兴趣的动态性、稳定性,来避免和解决标签的噪音问题。具体步骤如下:
第一步,获取网站所提供的商品信息与用户信息,实现用户和物品的标签的设立。
第二步,输入用户的短期兴趣标签G,长期兴趣标签H,利用余弦相似度公式进行计算。
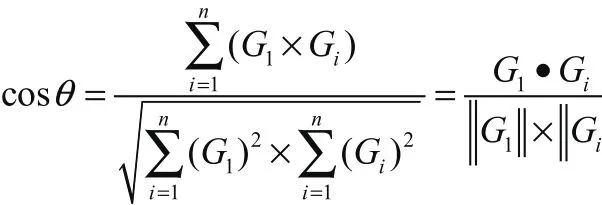
用上述公式来计算目标用户与数据库中其余用户的相似度,得到4到5名与目标用户兴趣偏好最相同的用户。
详细阐述了为解决用户兴趣标签的定位不准确性和标签本身存在的噪音和冗余问题而提出的算法思想和主要步骤。在兴趣标签中加入时间衰减系数,通过能反映用户动态性和稳定性的兴趣向量有效的避免了对目标用户偏好的定位的不准确,降低了标签噪音和冗余问题所来带的影响。长期兴趣标签和短期兴趣标签的设立能反映用户长期稳定的爱好和短期的关注点,推荐系统可以用根据这两个不同的偏好类型进行不同的推荐。先寻找与目标用户偏好最相似的三至五个用户并将这些用户组成用户集提取共同兴趣标签,能够去掉兴趣标签的冗余,并且显着提高推荐系统工作效率。本算法利用余弦相似和多维向量距离计算公式计算相似度并排序输出结果,虽然算法复杂性不够但适当解决了所提出的问题,且效率较高,提升了推荐系统的推荐精度和多样化程度。
4 总结
个性化的推荐系统在各个领域中得到了广泛的应用,缓解了用户在各种信息中无从下手找不到自己满意物品的难题,给用户带来了很大的便利,但也存在推荐精度不足、个性化程度低、受干扰信息影响大等缺点。本文对基于用户兴趣标签的混合推荐进行研究和提出算法,解决了推荐系统对用户兴趣标签的不准确定位。
本文第一部分说明了研究背景,叙述了一些个性化推荐系统目前存在的缺点以及造成其推荐不准确的成因。
本文第二部分介绍了协同过滤、基于内容的推荐和混合推荐这几个常用的算法,并提出了在标签的设立上的一些想法,总结了前辈们在基于标签的推荐算法上所开展的相关研究工作以及取得的成果。
本文第三部分详细阐述所提出的思路和算法。先从兴趣标签的设立方面介绍该算法的准备步骤,包括确立物品的明确标签、对目标用户进行行为数据采集、设立用户的短期和长期兴趣标签,再从用户兴趣标签本身所存在的问题出发,详细说明了要解决该问题的具体算法步骤,最后对此算法的优缺点进行了总结,即对提高用户兴趣标签设立的精度,增加推荐系统推荐精度和多样化程度,提高推荐系统的效率有较好的作用。
下一步作者会从降低算法复杂度进行研究,以更好的提高该算法的效率,也会对如何实现大数据平台下用户兴趣标签推荐系统的实现展开进一步的研究。



