杨 旭
(中央宣传部电影数字节目管理中心,北京 100866)
1 分布式存储
随着互联网化的发展,人们许多行为都从线下走到了线上,以前的现金支付已经被线上虚拟支付渐渐取代,人们通过互联网就能买到任何东西,小到一瓶饮料大到一辆汽车。互联网的迅猛发展,刺激的不只是购物,也促进了电影信息的进一步发展,同时也对传统的互联网平台架构设计提出了挑战。首先就是访问和并发量的考验,在面对日益增长的访问量的情况下,传统的单机关系数据库在大批量存储和数据处理能力上存在局限性,容易出现容量和性能瓶颈,分布式存储架构设计可解决单机数据库存储对容量和性能的依赖。
在“互联网+”“电影+”理念和思路的大环境下,对海量影片数据信息的分析成为更迫切的需求,这些都会对服务器的存储性能提出更高的要求,采用传统的存储模式会降低用户的体验感和满意度。分布式存储是将数据分布缓存在多台独立的服务器上,这不同于以往的把所有数据放在单独的存储服务器上的方式,分布式存储解决了传统单机存储服务器的海量读写性能的瓶颈,同时也为数据安全性提供了更加可靠的解决方案。
目前分布式存储应用较多的是基于Redis的分布式存储架构。
1.1 Redis简介
Redis是一个开源,遵守BSD 协议,使用ANSI C语言编写、支持网络、可基于内存,可被用于数据缓存、数据库或消息队列等,并提供多种语言的API支持,是现在最受欢迎的NoSQL 数据库之一 。
Redis的一个重要应用是其作为数据缓存以加快系统响应时间,提高系统吞吐量。例如,当有大量用户访问时,用户每次访问页面都需要向数据库发送请求,在很多情况下,从数据库请求的数据相对固定,针对这种情况可使用Redis作为缓存,即每次从数据库请求数据前,先判断缓存中是否存在所请求的数据,如果存在就从缓存中读取数据,如果不存在则去请求数据库,并将数据加入缓存,这样大大提高系统访问效率。
Redis也可以作为一种高级的Key-Value数据库,其中 Value 支持五种数据类型:字符串(Strings)类型、字符串列表 (Lists)类型、字符串集合 (Sets)类型、有序字符串集合 (Sorted Sets)类型和哈希(Hashes)类型。
Redis也可用作消息队列,其队列List类型可支持阻塞式读写,可以很容易地实现一个高性能的优先队列。
1.2 Redis优势
基于Redis的分布式存储架构,数据库完全在内存中,在读写速度上相比传统的单机架构的数据访问具有如下优势:
(1)Redis性能极高,是高性能的Key-Value数据库,Redis存储读写能力可达10w QPS 每秒。Redis最高可存储512MB 的键值对。而512MB×2=1024MB,即我们将最大获得1GB的数据支撑。
(2)Redis支持多种数据类型,常用的数据类型有:字符串 (Strings) 类型、字符串列表(Lists)类型、字符串集合(Sets)类型、有序字符串集合(Sorted Sets)类型、哈希(Hashes)类型,pub/sub发布与订阅和Transactions事务几种。其中哈希机制在复杂规模化的数据中广泛使用,本文利用Redis哈希存储信息,哈希是一个String类型的Field 和Value 类型的映射表,形如Value=[{Field1,Value},{Field2,Value},… {Fieldn,Value}],其在Redis的哈希类型中以String Field和String Value的map容器存储,本文利用Redis哈希存储结构存储影片信息,文中哈希表的Field值分别对应影片编号、影片名、推荐值、影片信息等属性标签,每一个哈希表最多可以存储40亿个键值对,所以该类型符合本文存储信息的需求。
(3)Redis操作都是原子性的,单个操作原子性,简化复杂的用户业务。Redis还具有持久化的特性,使得数据能持久地存储在磁盘上,具备主备模式可以在主库损坏的时候进行及时的切换。
(4)Redis支持多种编程语言的接入方式,具有C、Java、JavaScript、python、ruby 等客户端API,可方便用户利用客户端二次开发,如支持Java的Jedis客户端的jar包。
(5)Redis支持批量处理数据,可在短时间内插入百万条数据,并加载到缓存中。
1.3 Redis使用场景
Redis在频繁读取数据中能节省资源,提高速度,主要在以下几个场景中应用:
(1)Counting计数应用
Redis计数功能是最简单直观的模式,利用Redis原子性自增操作记录用户的点赞数、分享数、收藏数等,可快速并可节省开销。每当用户点击增加一个计数,利用Key:Value键值,key中存储字符串数,用incr操作实现对Redis存储数据的原子操作,Redis Incr命令可将key中存储的数字值增一。
(2)Cache缓存应用
缓存热点数据,这也是Redis最典型的应用之一,根据实际情况,缓存用户信息,缓存Session等;热点排行榜:即利用Redis排行榜实现最近、最热、点击率最高、活跃度最高等条件的top list,完美地解决了数据库全表扫描的效率问题等。
Redis对Cache的应用和Memched技术一样,对内存读取利用率高,Redis 支持持久化,但是Memched 技术不支持持久化,Redis可以将内存中的数据保存到硬盘中,然后重启之后再读取数据。Redis使用Key-hash结构在缓存应用,可以有效压缩内存使用空间,提供内存利用率。
(3)热点和排行的应用
传统的排行使用方式是利用数据库的查询语句实现,例如SQL语句如下所示:
Select*from infotable order by time desc;
在Web开发过程中,上述利用SQL 语言实现排序查询的这种用法比较常见,这种方式会带来每次访问都需要数据库进行排序查询,其访问效率低,但这个问题如果在Redis实现起来就迎刃而解。Redis充分使用模板类,用Zrange进行数目限制,每次只保留最新的条数,只有数据修改或超出的范围才会访问数据库。Redis技术的使用降低了数据和Web交互的频次,而且在一定程度上解决了读写分离的问题,保证了信息的一致性。
2 基于Redis的应用设计
随着互联网、媒体融合、大数据应用的发展,现在的互联网平台对高性能需求逐渐增加,各大知名互联网企业都在大量使用基于非关系型数据库(NoSQL)的分布式存储应用。目前包括新浪微博、阿里云、传媒巨头Viacom 及Pinterest都在Redis技术上有重要的应用。新浪微博自己拥有史上最大的Redis集群,阿里云提供云数据库Redis数据缓存业务,提供包括集群版、读写分离版、容灾版、混合存储版等多种定制模式,也是当前用户使用Redis的选择之一,该技术的应用是在架构上对互联网类应用上很好的补充。
2.1 方案设计
本文把Redis部署在服务器上,为了保证项目在生产应用中的稳定使用,配置Redis主备机。图1为基于Redis的分布式架构部署图。

图1 基于Redis的分布式架构部署图
在图1架构部署图中配置了2台Redis数据库缓存服务器,Redis技术的应用可加速数据读取速度,减少数据库的读写操作和使用频次,比如用户在读一些基本信息可用Redis数据缓存服务代替数据库查询功能。当用户新写入数据时,直接访问数据库并写入数据库,等数据库数据更新完成后再更新Redis服务器中的缓存数据,从而保证数据的一致性。
2.2 Redis的配置安装
以一台linux服务器为例配置Redis服务,表1为Redis服务的安装环境:

表1 Redis配置表
(1)安装编译环境
Redis需要依赖一些编译环境库,需安装编译环境以及依赖:gcc gcc-c++make tcl、centos-release-scl、devtoolset-9-gcc devtoolset-9-gcc-c++devtoolset-9-binutils。
(2)编译安装Redis
复制redis-6.0.9.tar.gz 到指定目录 (如:/root目录),再解压缩redis-6.0.9.tar.gz到指定目录(如:/root目录),再切换进入指定目录。
编译并安装redis-6.0.9,具体指令如下:
make PREFIX=/usr/local/redis install
(3)配置Redis
配置Redis安装目录中conf文件及其中bind、logfile、daemonize、protected-mode、dir等参数,在centos下运行redis-server,如图2所示。
图2 redis运行结果图
2.3 Redis模式的配置方式
Redis主要有四种工作模式:Redis单点、Redis集群、Redis哨兵模式和分片Redis四种模式。
Redis单点模式:在实际生产过程中,单点模式在出现故障风险时,如Redis服务恢复不及时会对整个系统运行产生重大影响。
Redis集群模式:集群模式是由多个单点Redis组成,任意节点都是互通的。
Redis哨兵模式:哨兵模式是由一个或多个哨兵实例组成,并对主Master状态进行监控,如遇到Master异常,则会进行主从切换,将从机切换为主机,之前的主机作为从机。
分片Redis模式:分片即分区是分割数据到多个Redis,系统共同维护整个内存。
结合本文应用需求及四种模式的应用场景和优缺点选择Redis哨兵模式。本文在Redis服务器上配置了Sentinel模式,需要先配置主机master的redis.conf配置文件,再配置从机slave的sentinel.conf配置文件,利用如下命令启动Sentinel系统:
redis-server/path/to/sentinel.conf --sentinel
哨兵模式可以有效的监控异常,并具有主备配置,在主机宕机时,备机能即时补充,符合本文应用需求。
2.4 基于Jedis的实现
Redis是开源的,支持C++、Java、Python等多种开发语言,它的最大优势是读写速度快,比较多的应用是基于Java 语言开发的Jedis客户端API的应用。本文使用基于Java语言开发的Redis接口API,开始在Java中使用Redis 前,需要确保已经安装了redis服务及Java 的Redis驱动,具体驱动包括redis.clients.jedis、redis.clients.jedis.exceptions、redis.clients.util三个Packages,在开发过程中根据用户需要引入不同的Packages。
在本文工程pom.xml文件中配置dependency,加入Jedis客户端的相关依赖jedis.2.1.0.jar,其中:group Id配置为redis.clients,artifactId配置为jedis,version配置为2.1.0。
Redis客户端和服务端之间的通信协议是RESP(Redis Senalization Protocol),为实现基于Redis的RESP协议的客户端与服务器端的数据交互,本文使用Jedis客户端API实现与本地的Redis服务端进行数据交互,文中配置启动端口为默认端口6379,连接Ip 为192.168.70.102,代码利用Jedis的incr、decr函数实现增减操作,set、get函数实现设置和获取操作。
文中为实现Redis分布式存储,在工程中引入Spring Session,即是把Session 统一存储在Redis中。在工程pom.xml文件中加入引用Redis依赖,配置dependency属性,引入启动器spring-sessiondata-redis.1.3.1.RELEASE,spring-session-dataredis可以实现把session信息存储到Redis分布式集群中,并可自动装载Redis Template对象,具体配置为:groupid配置为org.springframework.session,artifactId 配置为spring-session-data-redis,version配置为1.3.1.RELEASE。
(1)数据类型的选择
Jedis支持使用String、List、set、sorted sets等几种类型,下面是Redis要用到的数据结构的不同特点及应用场景,如表2所示。

表2 Redis数据类型比较
经过表2的对比,本文结合Redis分布式存储技术,采用sorted sets数据类型来存储用户喜爱影片的数据信息。
(2)影响因素的确定
本文中影响影片推荐功能有几个重要的影响因素,分别是用户的喜爱程度和用户的所在区域等,通过用户长时间登录的所在区域和喜爱程度两个变量共同协作,得出符合用户需求的推荐影片。
因此设计Key∶Vaule关系时,Key值设为用户属性 (即所在区域值)、Value哈希表为属性标签,包括影片属性及喜爱度值等,如图3所示。
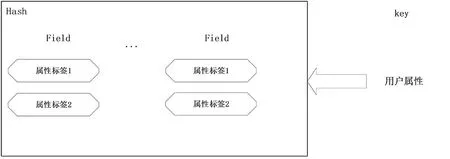
图3 Key∶Value的哈希关系结构图
图3中,通过Key (用户属性)+Filed (属性标签)就可以组成Key∶Value的哈希关系结构,这样设计既不需要存储大量的重复数据,也不会带来序列化和并发修改控制的问题,提高了访问效率,也节省了开销。
本文利用Redis分布式存储技术实现影片推荐功能,使不同区域用户可获得定制化的推荐影片排行榜,更有针对性地服务目标群体,如图4所示。
图4 推荐影片实现结果图
测试Redis分布式存储架构和传统的单机存储架构在用户并发在100、300、500、1000的吞吐率,当用户并发数达到1000时,传统单机模式下响应时间变长,处理请求能力下降到79req/s,而Redis模式性能保持不变。Redis分布式存储架构在日常高峰期可以瞬间响应,节省了访问数据库的频次,提升用户体验度的同时保证了系统稳定性。
3 总结
在互联网、大数据、媒体融合快速发展的今天,提高用户的满意度和体验度是互联网平台的首要和重要的任务,现在判断一个平台的好坏不只是能否使用,更要有舒适的体验度。本文综合分析了Redis分布式存储数据的应用现状,并通过实践应用验证了Redis分布式存储在提高读写性能、解决内存消耗上的优势。本文根据Redis的适用场景,搭建主备Redis的分布式存储架构,提出一种支持影片推荐的分布式存储方法,该架构实现了利用Redis的分布式存储的技术,节省内存消耗,提升读写速度,大大减少了在影片推荐排行过程中读写数据库的压力,同时也保证了数据安全性和一致性。❖



