谢 敏,高 超
(常德职业技术学院附属第二医院,湖南常德 415000)
脂肪肝的诊断方法,目前主要为临床诊断,难以用于人群大规模脂肪肝的普查;作为疾病的计量诊断,有周慎等[1]采用最大似然判别法进行中风后遗症中医证候的计量诊断研究、袁肇凯等[2]用Fisher判别函数法进行冠心病中医证候临床实验指标的计量诊断研究、朱文锋[3]常见症状的计量诊病研究的报道,但未见脂肪肝计量诊断的报道。笔者思量,若能利用肝功能检查结果进行脂肪肝的筛选,找出脂肪肝的高危人群,并有针对性地进行干预,则对控制人群脂肪肝的发生具有重大意义;为此,试以常德市武陵区老年体检肝功能资料为依据,采用因子计量诊断法对脂肪肝进行了计量诊断研究[4],其方法结果如下:
1 资料与方法
1.1 资料来源
以常德市2008年老年健康体检资料数据齐全的538名对象的患脂肪肝与否及血清生化指标数据为分析用资料。538名对象中,脂肪肝者150名,非脂肪肝388名;男339名,女199名;年龄(57.1786±9.56162)岁;肝功能血清生化指标包括三酰甘油(X1)、总胆固醇(X2)、高密度脂蛋白(X3)、低密度脂蛋白(X4)、谷丙转氨酶(X5)、谷草转氨酶(X6)、纤维蛋白原(X7)。
1.2 资料分析
先令患脂肪肝者为“1”、未患脂肪肝者为“0”,然后用SPSS软件对患脂肪肝与否和上述7个血清生化指标进行标准正态离差变换,并计算此8个指标(标准化变量)两两间的相关系数;再选与患脂肪肝与否相关有统计学意义的标准化变量,定入选水准α=0.05、剔除水准α=0.01,做以患脂肪肝与否为应变量、选入的各血清生化指标为自变量的标准化变量的逐步回归分析,筛选自变量;最后对进入逐步回归方程的各标准化变量进行因子分析,从专业的角度解释各公因子,建立因子回归方程、计算各对象因子得分计量值、令因子计量值≥0者为脂肪肝、<0者为非脂肪肝,并以临床诊断为标准进行因子计量诊断[1]与筛检方法的真实性评价。
2 结果
2.1 标准化变量的逐步回归模型
进入标准化变量逐步回归方程的自变量依次为谷丙转氨酶(X5′)、三酰甘油(X1′)、低密度脂蛋白(X4′)、纤维蛋白原(X7′);逐步回归模型的决定系数为 0.250、F=44.384、P=0.000。
2.2 入选标准化变量的因子分析
2.2.1 各公因子的方差贡献 患脂肪肝与否(Y′)与进入逐步回归方程的4个标准化自变量(Xi)的因子分析,在定因子个数为4的情况下,各公因子的方差贡献见表1。
2.2.2 各指标于公因子的载荷 做因子分析的上述5个指标于4个公因子上的载荷见表2。

表1 4个公因子的方差贡献率
2.2.3 各公因子的专业解释 自表2看来,第一公因子主要支配 X5′和 Y′,可解释为肝脏功能;第二公因子主要支配 X1′,可解释为三酰甘油水平;第三公因子主要支配X7′,可解释为凝血机制;第四公因子主要支配X4′,可解释为低密度脂蛋白水平。
2.2.4 因子得分的回归模型 用SPSS自动生成的各对象的于各公因子的得分为自变量、Y′为应变量建立一般因子回归模型,其复相关系数为0.833、确定系数为0.694、调整确定系数为0.691、F=301.778、P=0.000;其因子得分回归方程的工作式为:
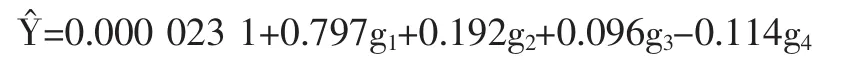
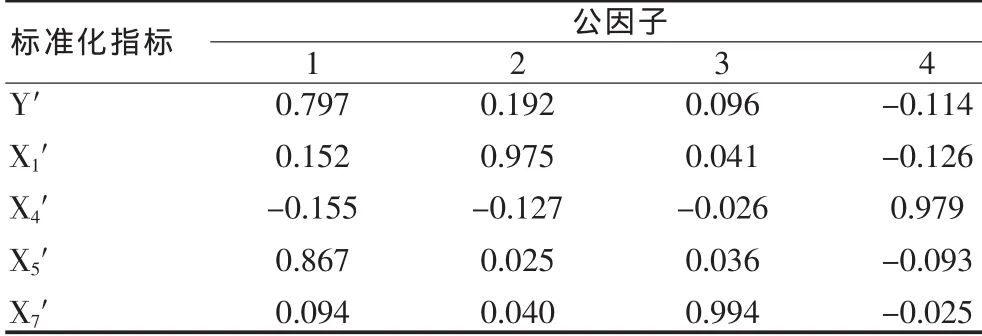
表2 旋转后的因子载荷
式中 g1、g2、g3、g4为第一、第二、第三、第四公因子得分(按此式计算的结果为标准化应变量Y′)
其回归系数及其t检验结果见表3。
2.2.5 计算因子系数与因子计量值 本资料计算各对象因子得分的因子系数见表5。个人因子得分计量值=Σ因子得分系数·i标化指标j;其中因子得分系数由SPSS软件自动生成,标化指标即分别为谷丙转氨酶、三酰甘油、纤维蛋白原、低密度脂蛋白标准化正态离差;分别依次上四指标的实测值及其均数与标准差,其值见表4。
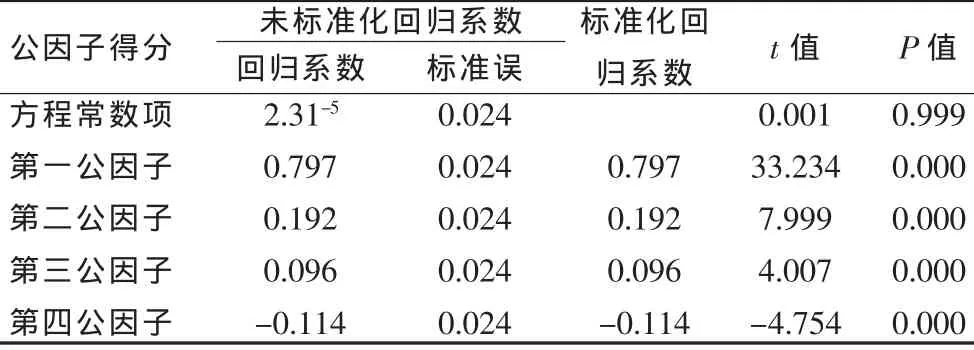
表3 各公因子得分的回归系数及其t检验结果

表4 本资料4个指标的均数与标准差
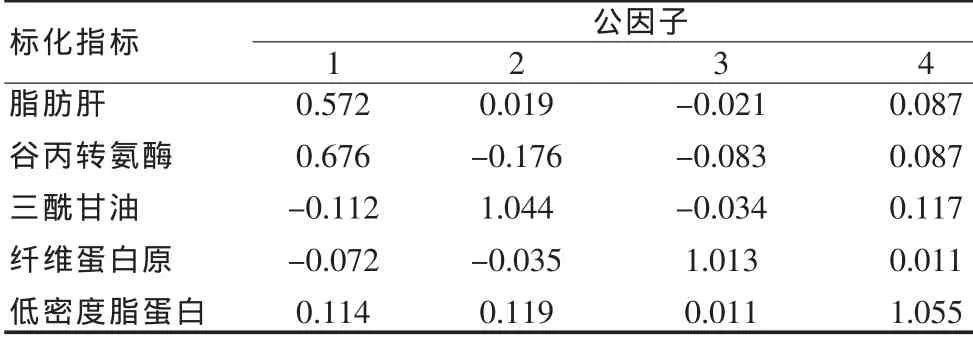
表5 计算因子得分的因子系数
2.3 因子计量诊断结果
以临床诊断为标准的因子计量诊断结果见表6。

表6 因子计量诊断与临床诊断结果比较
2.4 真实性与收益评价
灵敏度=68.00% 特异度=75.00% 漏诊率=32.00%误诊率=25.00%
+LR=2.72 -LR=0.43 准确度=73.05% 阳性预测值=51.26%
阴性预测值=85.84%
3 讨论
3.1 本法的诊断依据
本法诊断的依据是基于原资料经因子分析所提取的公因子——肝功能、三酰甘油、纤维蛋白原和低密度脂蛋白三者的表现值(标准化值即前述的uj)。从其对脂肪肝的方差贡献达88.920%,因子回归模型的复相关系数达0.833、确定系数达0.694、F=301.778、P=0.000来看,可认为其诊断依据是可靠和可信的。
3.2 本法诊断的实用性
从筛检方法应用要求的角度来看,本法似乎并不理想(特异度低、误诊率高、符合率低)。从实际应用角度来看,笔者认为,若从筛选脂肪肝高危人群以便进行干预的目的出发来考量,仍有应用意义。其理由有二:①灵敏度、阳性似然比、阴性预测值均高,且误诊率高一点不但不会导致对象的健康危害反而,有益(被误诊的人多为上述指标表现值接近临界值的人,更多的这样的人接受干预对他们本人有益无害);②对象自己即可诊断,稍有文化的人,肝功能化验结果出来后,对象本人即可按条目2.2.5介绍的计算个人因子得分,若≥0即可判定为自己脂肪肝。
3.3 本法应用的优缺点
3.3.1 优点 应用本法的优点有四:①成本低,做一个肝功能检查花不了多少钱;②对象本人自己可以根据肝功能结果进行诊断;③可用于大规模人群筛选;④方法阳性率高而漏诊率低,适于筛选高危人群以便进行干预。
3.3.2 缺点 资料分析方法非常复杂,需懂统计学方法原理的人才能建模,且本资料的研究对象为47岁以上的人,不适用从年轻人群中筛选脂肪肝高危者。
[1]周慎,周重余.最大似然判别法对中风后遗症中医证候的计量诊断研究[J].上海中医药大学学报,2009,21(4):26-29.
[2]袁肇凯,田松,李杰,等.冠心病中医证候临床实验指标的计量诊断研究[J].湖南中医药大学学报,2005,25(4):26-29.
[3]朱文锋.常见症状的计量诊病[J].辽宁中医杂志,2002,29(3):142.
[4]黄正南.医用多因素分析[M].3版.长沙:湖南科学技术出版社,1995:219-244.



