时慧芳
(昆明理工大学 信息工程与自动化学院, 云南 昆明 650000)
0 引 言
知识图谱是2012 年由谷歌提出的,近年来知识图谱发展迅速,如YAGO、DBpedia、BabelNet 以及中文CNDBpedia、Zhishi.me 等,这些大规模的知识图谱在知识推理[1]、信息抽取[2]以及问答系统[1]等方面起着重要作用。知识图谱通常是以三元组<头实体,关系,尾实体>的形式存储的。但是由于知识图谱的异构性,导致具有相同的实体却有着不同的表示。为提高知识图谱的完整性,实体对齐被提出并受到广泛的关注。知识图谱实体对齐目的是找到那些存在于不同知识图谱中但指代模相同的实体[3]。
传统的实体对齐方法主要是从两个方面解决实体对齐的:一种是计算相似度来进行实体对齐。王雪鹏等人提出一种基于网络语义标签的中文知识库实体对齐算法[4],该算法是通过综合计算多种标签相似度来进行实体对齐的;另一种是通过关系推理的方法来进行实体对齐的。基于关系推理的方法的主要思想是利用知识图谱中实体之间的关系,通过构造概率函数、关系相似函数等来推理关系之间的语义等价性,实现关系相应的实体之间的对齐。传统的实体对齐方法依赖人工设计的特征,在实体对齐过程中,由于实体的属性以及涉及领域的差异性,很难给出统一的相似性计算函数,且这种方法忽略了隐含的语义信息,使得实体对齐的效果有限;并且传统的实体对齐方法一般都集中在句法和结构上,主要依赖于本体模式对齐,这些方法侧重于计算实体之间标签和字符的距离,但是在大规模数据下准确率及效率显著下降[5]。
近年来,文献[6]中提出一种基于知识表示学习的实体对齐方法。其思想是利用机器学习技术将描述对象表示为低维稠密的向量,通过降低高维实体和关系得到低维向量的数值表示。基于翻译模型的方法是将知识库中实体间的关系看作实体向量间的平移操作[7],翻译模型利用头实体、尾实体以及关系在空间的平移不变性来计算知识图谱实体和关系的嵌入表示。翻译模型可以学到实体的部分语义信息,但使用该方法需要依赖大量预先对齐的关系或者三元组。Hao 等人突破基于相似度的方法,第一次使用了基于表示学习的方法进行实体对齐[8]。Chen 等人将知识图谱嵌入到独立空间并且同时学习知识图谱间的转换[9]。Sun 等人利用自适应的方法学习嵌入,通过迭代的方式扩充数据集并达到了一定的效果[10]。Jongmo Kim 等人提出了一种基于模型深度的实体对齐方法,用于解决边缘数据之间的异构性,是一种比较新颖的实体对齐方法[11]。基于嵌入的方法的优点是需要较少的人工参与,并且可以扩展到大型知识图谱中。基于图的方法能够直接在图上提取图的整体结构信息[12]。这些方法取得了比传统方法更好的效果。
为充分利用知识图谱中的知识利用率,提出了一种针对实体关系和属性的联合实体对齐方法。目前实体对齐的方法是需要根据标注数据进行对齐,并且这些方法都是以标注的数据为真为前提的;但是标注数据中也可能会存在错误的数据,这些数据在很大程度上会影响实体对齐的准确率。为此,针对现实世界中真实数据的特点,本文提出一种融合高速路门机制的联合实体关系和属性信息的实体对齐模型。该模型使用两层GCN 模型并融合高速路门机制,利用高速路门机制控制了实体进入的数量,减少了候选项,并降低了噪声,提高了通过数据的质量。在进行实体关系和属性信息嵌入的过程中使得实体对齐的效果更加精准。
1 相关工作
1.1 实体对齐
知识图谱G= (E,R,T,A,V)是一种带有标记的有向图[13],其中包括实体集合E、关系集合R、关系三元组集合T以及属性A和属性值V。实体之间通过关系相互连接,构成复杂的网状知识结构[14]。知识图谱中的关系三元组表示为:
属性三元组表示为:
给定源知识图谱G1= (E1,R1,T1,A1,V1),目标知识图谱G2= (E2,R2,T2,A2,V2) 以及已对齐的实体对S={(e1,e2)|e1∈E1,e2∈E2,e1≡e2},其中“≡”是等价符号,代表实体e1和实体e2的指向相同,即指向现实世界中的同一个事物。实体对齐就是发现源知识图谱和目标知识图谱中等价的实体对。
现有的知识图谱主要关注实体本身,而知识图谱的属性信息对提高实体对齐的准确率也很重要,为此提出了一种联合实体关系和属性信息的实体对齐方法。利用带有高速路门机制图卷积的表示方法,联合学习关系三元组和属性信息的嵌入表示进行实体对齐。实体对齐案例如图1 所示。
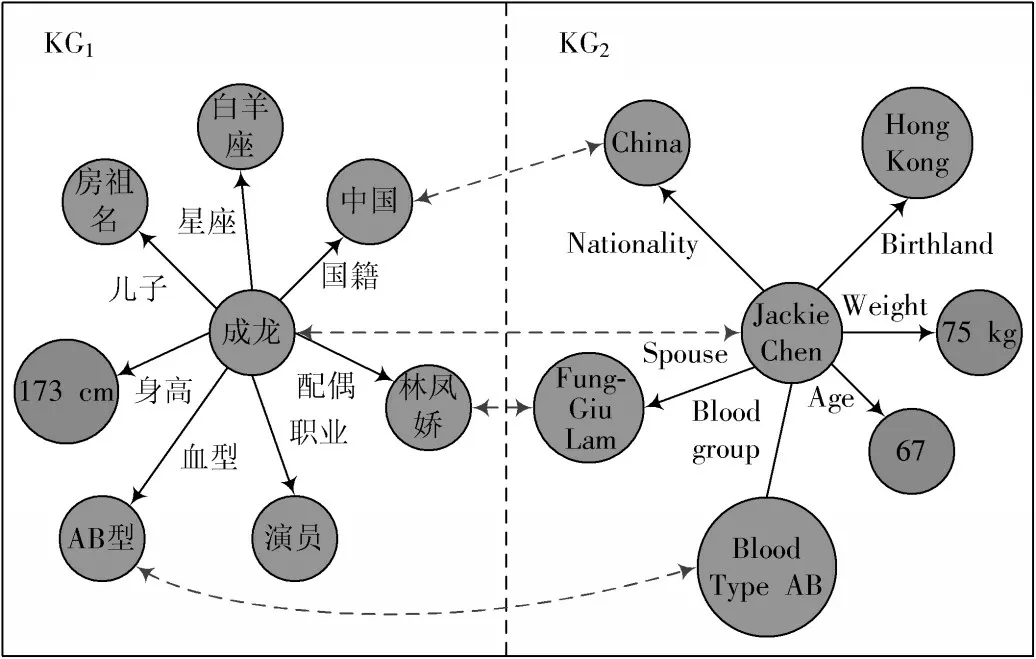
图1 实体对齐案例
1.2 模型结构图
知识图谱实体对齐的目的是找到不同知识图谱中指向现实世界中同一对象的过程。为提高实体对齐的准确性,提出一种联合实体关系和属性信息的实体对齐方法,利用带有高速路门机制图卷积的表示方法,学习关系三元组和属性的嵌入表示。在大型数据集上进行的实验结果表明,该方法效果良好。实体对齐模型结构图如图2 所示。
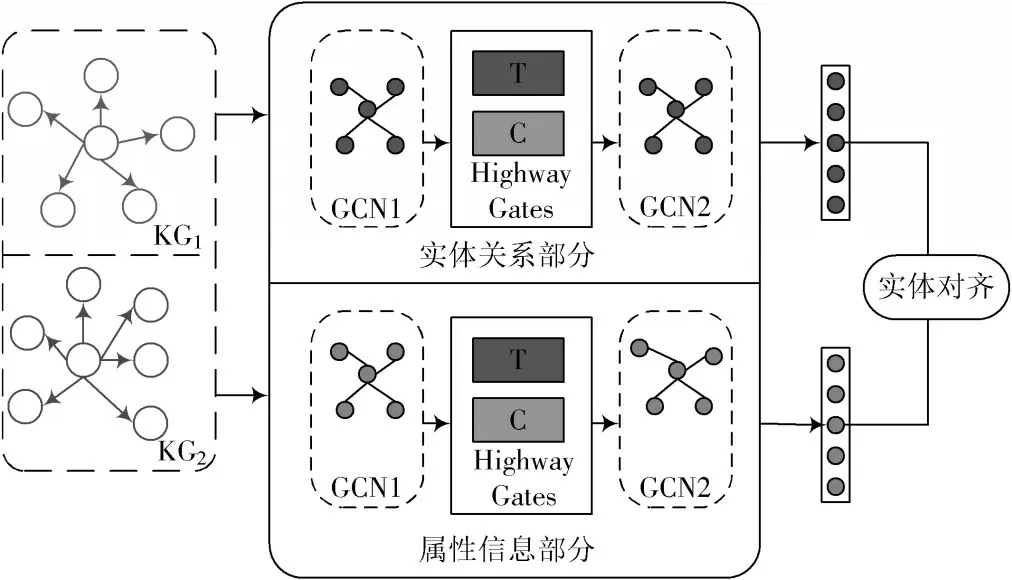
图2 实体对齐模型结构图
2 算法分析
给定两个知识图谱KG1和KG2,以及一部分预对齐的实体种子集S,使用图神经网络将KG1和KG2的实体映射到同一低维向量空间,并在图卷积神经网络中使用高速路门机制过滤相关实体和属性信息,以实现异构知识图谱之间更细粒度、更准确的实体对齐。提出的模型包括三部分,第一部分是实体关系的实体对齐,第二部分是属性信息的实体对齐,第三部分是融合实体关系和属性信息的实体对齐。
2.1 实体关系表示
在实体关系表示部分使用两层的图卷积网络模型,图卷积网络的核心思想是利用边的信息对节点信息进行聚合,从而生成新的节点表示。在实体通过关系连接的图上进行卷积,其中邻接矩阵是图的邻接矩阵。邻接矩阵的维度是两个知识图谱中实体的总个数,其中第一层的输入采用随机的方式进行。层与层之间的传播方式如下所示:
式中:,A是n×n的邻接矩阵,表示实体和属性信息的连接,I是A的单位矩阵;是的度矩阵;W(L)是权重矩阵。
2.2 属性信息表示
属性信息表示部分同样采用两层图卷积网络模型,矩阵是关系实体与属性信息的邻接矩阵,在此过程中将属性信息当作节点看待。实体如果拥有某一个属性信息,那么实体与该属性信息就会有一条边进行连接,该邻接矩阵的维度是实体的数量和属性信息数量之和。在该部分中,采用随机的方式进行第一层的输入。层与层之间的传播方式同式(1)。
以上两部分在模型训练的过程中使用边际得分函数作为两个模块的损失函数,定义公式如下:
2.3 高速路门机制融入模块
在第一层卷积以后采用高速路门机制来控制应该有多少实体关系信息和属性信息传递到节点并减少噪声传播。高速路门机制是在第一层网络输入的数据一部分经过非线性变换,另一部分会直接从该网络中通过并且不进行任何形式转换。而且经过非线性数据转换的数量和不进行任何形式转换的数据是由权值矩阵和输入的数据共同决定的。高速路门机制的目的是减少噪声传播并控制向节点传递多少的邻域信息的平衡。高速路门机制有两个非线性转换层,一个是transform gate,用T 表示;另一个是carry gate,用C 表示。一般来说,transform gate 表示输入信息经过卷积或者循环被转换的部分,carry gate 表示的是原始输入信息被保留的部分。
式中:X(L)是输入的特征矩阵;σ是sigmoid 函数;“·”是对应元素的乘积;W(L)T是权重矩阵;b(L)T是偏置向量。
实体对齐是根据表示空间中知识图谱间实体之间的距离来衡量的,表示空间中X={x1,x2,…,xn|xn∈Rd},其中e1来自知识图谱KG1,e2来自知识图谱KG2,实体之间的距离公式为:
2.4 模块融合
在获得两部分的表示向量后,分别计算实体关系和属性信息的相似性,然后通过加权求和得到实体之间的相似性。
式中:β为超参数,用来平衡两种向量;d1和d2分别表示经过模型后的实体关系信息和属性信息的向量维度。
3 实 验
3.1 数据集
采用DBP15K 和DWY100K 的数据集进行实体对齐实验。DBPedia 包含中英、日英、法英语言版本。DWY100K 包含DBPedia、Wikidata 和YAGO3 数据集。
3.2 评价指标与实验设置
本文使用Hits@k作为实体对齐的评价指标。在本实验中k的取值分别为1 和10。
在实验设置方面,实体关系、属性信息嵌入以及联合训练epoch=6 000,实体关系的学习率设置为0.01,嵌入维度为200,间隔超参数γ=5.0;属性信息的学习率设置为0.01,嵌入维度为100,间隔超参数γ=3.0。联合实体关系和属性信息的连接权重β=0.8。在实验训练过程中使用10%~50%已对齐的种子集。
3.3 对比实验分析
表1~表4 所示为GCN-HW 在DBP15K 三个跨语言数据集上与对比模型的实体对齐结果。为更好地对比实验结果,对三个数据集进行了反向验证。
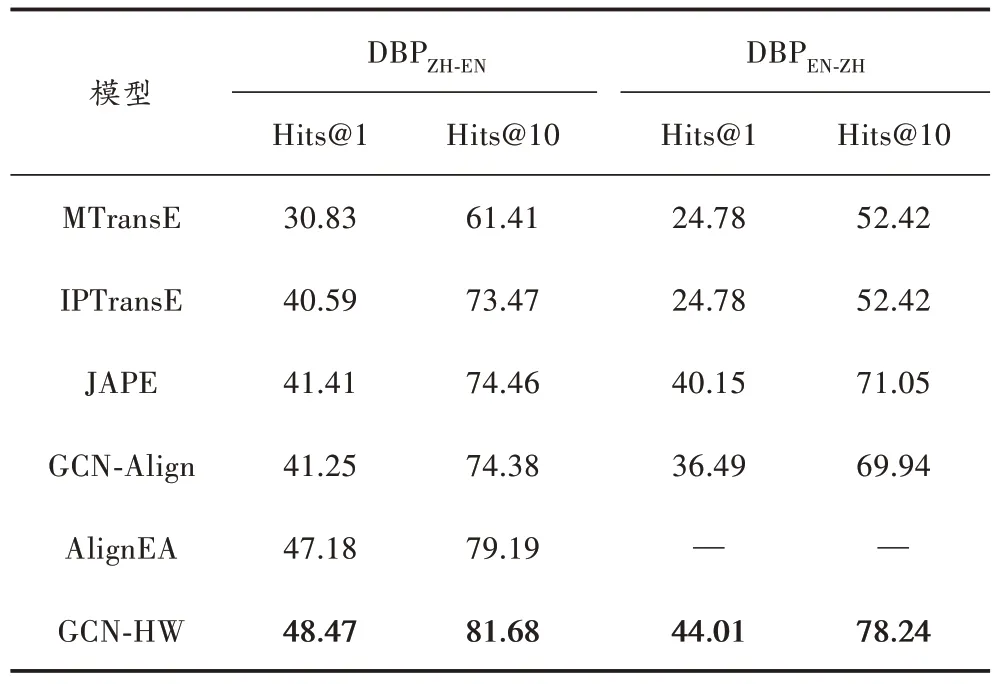
表1 不同模型在中英数据集上的实验结果对比 %

表2 不同模型在日英数据集上的实验结果对比 %
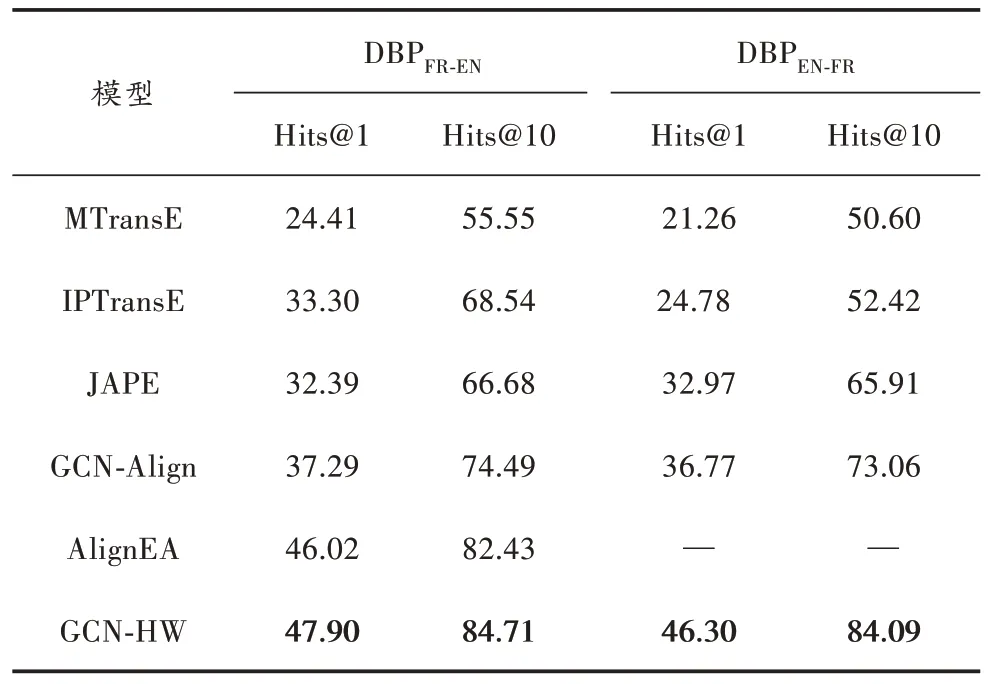
表3 不同模型在法英数据集上的实验结果对比 %

表4 不同模型在DWY 数据集上的实验结果对比 %
总的来说,通过使用带有高速机制门的图卷积网络方法捕获实体关系和属性信息,在Hits@1 的性能优于基于翻译和基于图的实体对齐方法。由表1~表4 可得出以下结论:
1) 在所有基于翻译的实体对齐方法中,AlignEA 效果最好,原因在于其采用多种边际的方法来控制三元组的得分函数,使得基于三元组建模的效果优于其他方法。
2) MTransE 的侧重点在于对关系三元组的头尾实体和关系进行建模,并没有考虑更细粒度的语义信息和属性特征;而JAPE 依赖对齐种子的数量,效果表现一般。
3) 在与基于图方法的比较中,GCN-Align 只考虑了相同实体关系间的实体对齐,没有考虑知识图谱中丰富的关系,具有单一性。
4) 在DBP15K 三个大型的跨语言数据集上,本文所提出的模型GCN-HW 的表现较好。在ZH-EN 数据集上,GCN-HW 比所有模型中效果最好的Hits@1 高出了1.29%,比Hits@10 高出了2.49%;反向的数据集EN-ZH上Hits@1 高出了3.86%,Hits@10 高出了7.19%。在JA-EN 数据集上,GCN-HW 比所有模型中效果最好的Hits@1 高出了4.7%,Hits@10 高出了3.81%;反向的数据集EN-JA 上Hits@1 高 出 了7.15%,Hits@10 高 出 了10.04%。在FR-EN 数据集上,GCN-HW 比所有模型中效果最好的Hits@1 高出了1.88%,Hits@10 高出了2.28%,反向的数据集EN-FR 上Hits@1 高出了9.53%,Hits@10 高出了11.03%。在DBP15K 三个大型的跨语言数据集上,模型GCN-HW 的表现效果相似,优于SOTA。值得一提的是,在ZH-EN、JA-EN 数据集上,Hits@1 的效果要好于FR-EN,这是因为FR-EN 数据集中的关系三元组的数量远远高于ZH-EN 和JA-EN 数据集中关系三元组的数量,数量越多则表明结构越复杂,建模的难度越大。
5) 在DWY100K数据集上,每个数据集有100 000个预对齐实体对,该数据集的实体对是经过人工标注的,能够保证数据的高质量和准确性。在DWYDB-WI数据集上,GCN-HW 与效果较好的AlignEA 相比,Hits@1 提高了1.35%,Hits@10 提高了1.39%;在DWYDB-YG数据集上,Hits@1 提高了0.66%,Hits@10 提高了2.23%。以上实验数据表明,数据的质量越高,实体对齐的效果越好。
3.4 消融实验
为验证本文模型的有效性,将GCN-HW 模型做了相关消融实验,分别是关系实体GCN-HW-R、属性GCNHW-A 以及联合关系实体和属性信息GCN-HW 的消融实验,所得实验结果如表5~表8 所示。
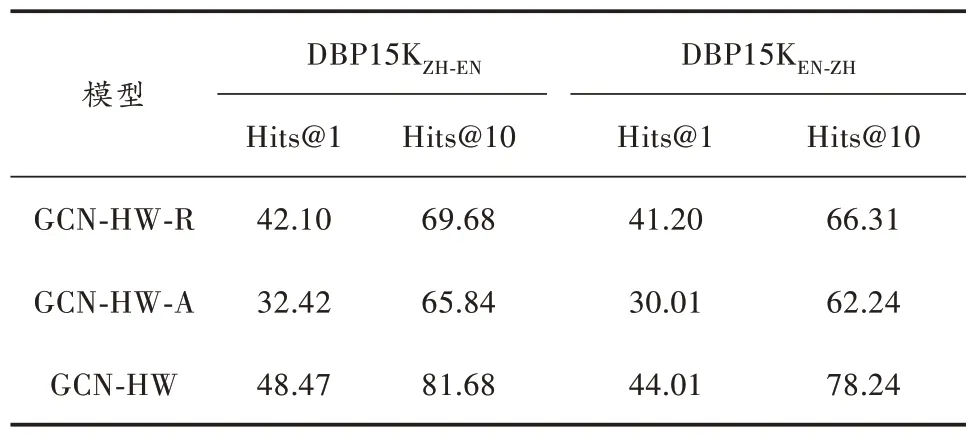
表5 DBP15K 中英数据集上的实验结果 %

表6 DBP15K 日英数据集上的实验结果 %
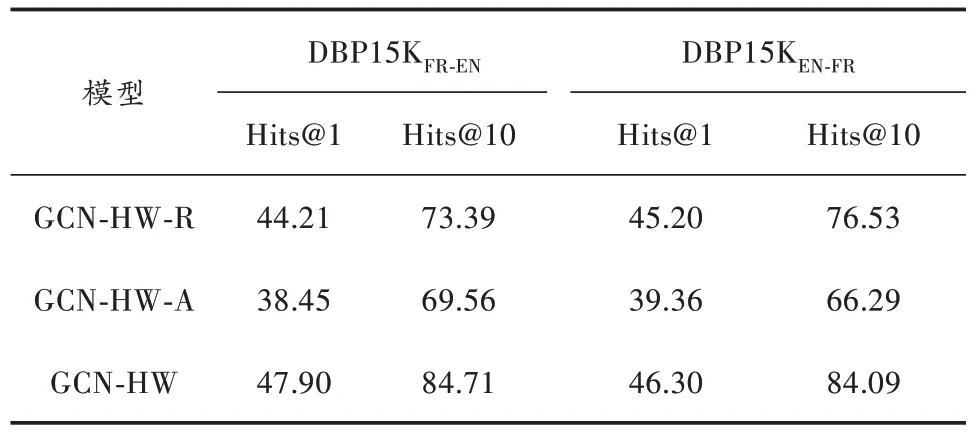
表7 DBP15K 法英数据集上的实验结果 %
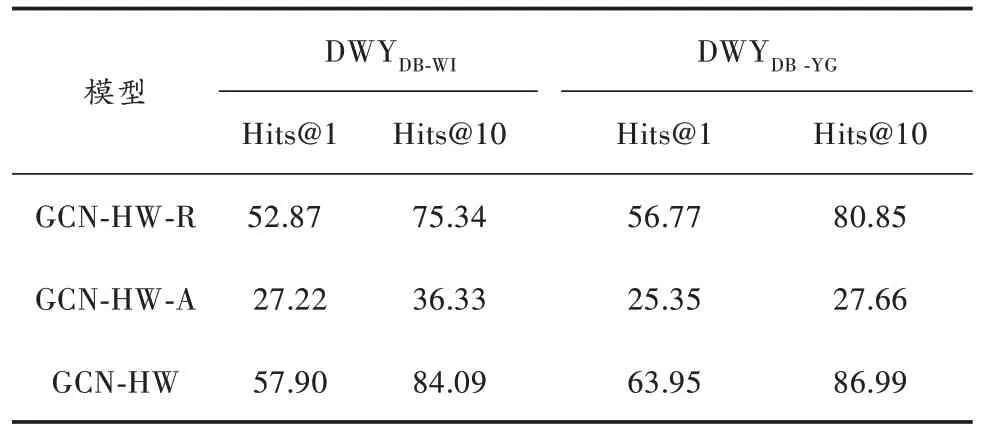
表8 DWY100K 数据集上的实验结果 %
从表5~表8 的消融实验结果中可知,在DBP15K三个数据集及DWY100K 的两个数据集中,GCN-HW-R的效果均优于GCN-HW-A,这说明实体关系对齐的效果优于属性实体对齐。GCN-HW 模型的效果在Hita@1 和Hits@10 总是高于单独的GCN-HW-R 和GCN-HW-A 的效果,这说明知识图谱中的属性对于知识图谱实体对齐效果提高是很重要的。总的来说,在实体对齐的过程中要充分、全面地考虑各种信息对知识图谱实体对齐的重要性。
3.5 种子集的影响
为更清楚、直观地展示GCN-HW 与对比模型的有效性,实验过程中设置不同种子集在数据集DBP15K 上的Hits@1 的效果,如图3~图5 所示。
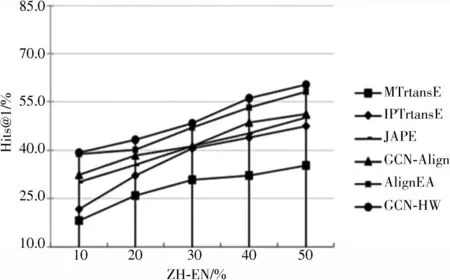
图3 ZH-EN 数据集上在不同种子集规模的结果
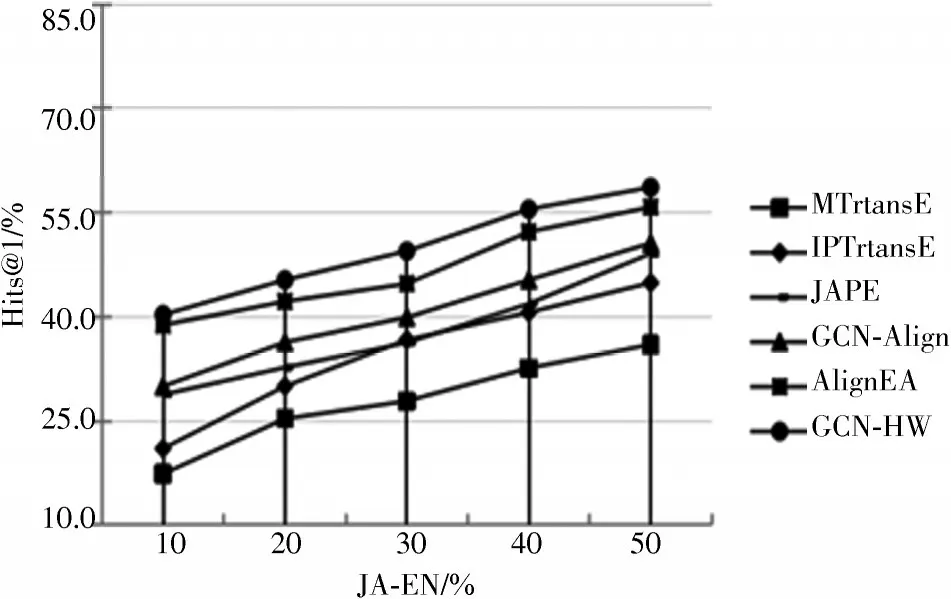
图4 JA-EN 数据集上在不同种子集规模的结果
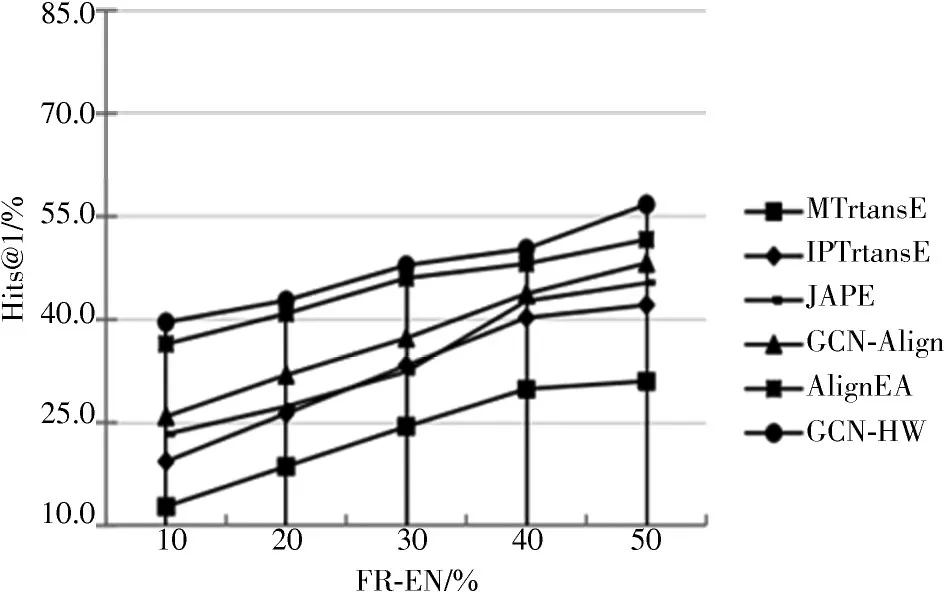
图5 FR-EN 数据集上在不同种子集规模的结果
图3~图5 的实验表明:在不同种子集的情况下,随着种子集的不断增加,训练效果也在变好。当种子集达到50%时,所有方法的效果有显著提升;当给到10%的种子集时所有的方法效果表现一般,但提出的GCN-HW在所有不同的种子集上效果均优于其他五种对比模型,再次证明了GCN-HW 的有效性。
4 结 语
实体对齐是知识图谱构建过程中一种关键性的知识融合技术,本文充分利用知识图谱三元组信息,并融合高速路门机制,提高了实体对齐的效率。在实际知识图谱构建过程中是非常复杂的,比如领域广、范围杂、结构复杂等,这给知识融合带来了挑战。后续将进一步关注实体对齐的结构问题。



