张云翔 饶竹一
摘 要:依存句法分析是分析句子各个成分之间相互支配与被支配关系,反映的是句子各成分的语义修饰关系。本文通过对句子中干扰成分过滤和专有名词进行替换技术来提升依存句法分析的准确率,然后对依存句法结构进行抽取与调整,并引入基本语义判别模型抽取句子的基本语义结构,通过基本语义结构的各个修饰成分进行调整得到句子的首层语义结构,然后利用首层语义结构中的每个词的修饰成分递归对句子所有成分进行调整,从而得到整个句子的语义层次结构。得到了句子的首层语义结构与嵌套语义结构,便可以从各个层次分析句子蕴含的语义,为准确的把握用户表达的需求,理解用户的真实意图打下扎实的基础。
关键词:语义分析;依存分析;专有名词替换;首层语义;嵌套语义;语义层次;
引言
语义指语句包含的概念和意义,语义不仅表述事物的本质,还表述事物之间的因果、施事和逻辑关系。语义层次指的是语句中语义的嵌套关系和修饰关系。句子语义层次识别是发现句子的基本含义和嵌套语义的过程。通过句子语义层次识别能够让机器清楚的知道用户各层次的语义关系,从而准确的把握用户的需求,更加透彻的理解用户的真实需求。
目前国内外针对语义分析的研究方法大致可以分为:基于词语语义知识规则(如语义词典、语言知识库、本体库等)的语义分析、基于统计的语义分析和基于机器学习的语义分析以及多种方法结合的分析方法。文献[1]和文献[2]是基于统计的思路分析文本表达的语义信息。此外董振东构建的知网知识库[ ],是一个以汉语和英语的词语所代表的概念为描述对象,以揭示概念与概念之间以及概念所具有的属性之间的关系为基本内容的常识知识库。国外经典的框架语义学 [9]是美国菲尔墨提出的一种经验主义语义学,它提供了描写词语意义和语法结构意义的一种途径。
虽然目前语义分析技术较多,但是几乎都是针对句子的语法成分或句法结构 [6]进行分析,对于嵌套句或复杂语句结构的理解存在一定的缺陷。因此准确的获取句子的语义层次具有重要的研究意义。本文一方面利用干扰词过滤和专有名词替换方法来处理句子中的特殊符号从而提升依存分析的准确率,另一方面基于依存分析得到的依存句法结构,对其进行抽取与调整,得到句子的语义层次结构。语义层次结构反映了句子各个层次的语义成分组成方式,能够准确的把握句子的各层次语义和真实意图。
1.语义层次识别系统介绍
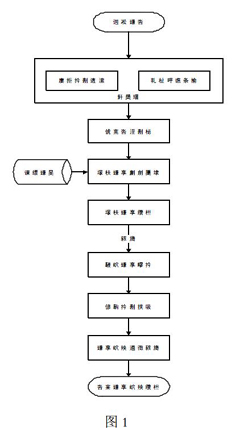
语义层次识别整体流程如图1所示,在进行依存分析前,首先对句子进行干扰成分过滤和专有名词替换的预处理操作,排除进行依存分析时受到句子中特殊字符和数字的干扰导致依存句法结构错误,从而提升依存分析的准确率。在得到句子依存句法结构后结合训练得到的基本语义判别模型提取句子的首层语义结构,再对首层语义中每个节点的修饰成分进行抽取与调整,得到节点与修饰关系之间的语义层次关系,再对每个子节点抽取其修饰成分并递归进行调整,直到句子中所有节点都处理完毕为止,这样便得到句子的语义层次结构,也得到句子的首层语义结构和嵌套语义结构。
1.1术语定义
① 基本语义:指不包括嵌套成分和修饰成分的简单句。
② 专有名词:指具有典型规则的英文符号或数字组成的实体名词,如身份证号、网址、邮箱、IP地址等。
③ 核心节点:指依存关系中的核心关系所代表的词语。
④ 关键节点:指当前语义层次中基本语义结构中包含的节点,不包括通过依存关系调整层次后上移的节点。
⑤ 父节点:指当前词语的依存关系指向的词语。
⑥ 子节点:指依存关系中所有指向当前词语的词语。
1.2 预处理模块
本文提出一种对句子干扰成分过滤和句子专有名词进行替换的预处理技术来提升依存分析的准确率,首先利用专有名词规则库(专有名词规则库是事先整理好的关于各种类型专有名词的匹配规则)对句子进行扫描,提取出句子中包含的各类型专有名词成分,然后对句子中的干扰符号(通过干扰符号库识别)进行过滤。具体步骤如下:
a.扫描句子中每个字符判断是否是干扰成分(干扰成分通常指表情符号,无意义的符号,通过干扰符号表来进行匹配识别);
b.将句子中扫描出的干扰成分进行删除;
c.利用专有名词识别规则对句子中的专有名词进行识别;
d.将句子中的专有名词替换为专有名词类型名;
e.通过专有名词在句子中的前后词判断替换后的句子结构是否存在歧义;
f.若替换后的句子存在歧义,则还原成删除干扰成分后的结构;
1.3 基本语义判别模型
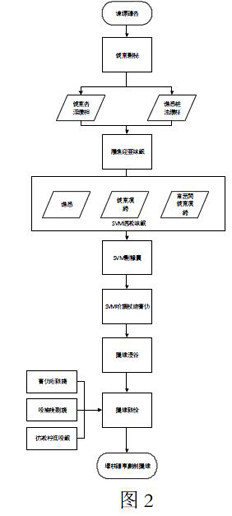
本文采用SVM分类器来对句子中每个词是否属于基本语义进行判断,以词的词性以及依存关系和子节点依存关系构成输入向量,通过训练用例对句子基本语义结构进行学习,得到基本语义判别模型,主要流程如图2所示。具体步骤如下:
a.对训练用例进行依存分析得到依存句法结构;
b.将训练用例中每个词的词性和依存关系以及子节点依存关系构成输入向量
c.利用SVM分类器(也就是本发明中基本语义判别模型所使用的分类器)对输入向量进行训练学习;
d.对得到的判别模型进行测试、调优;
e.得到判断句子中每个词是否是基本语义的判别模型。
1.4 首层语义抽取模块
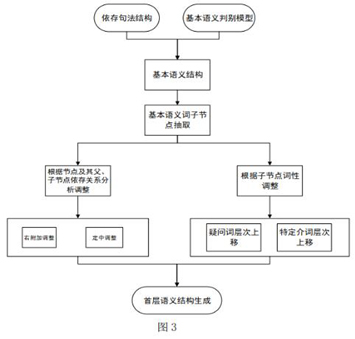
首层语义是句子的主要含义表现,因此即要准确的获取关键词语又要保留特定的表达方式才能准确的反映句子的含义。本文首层语义抽取流程如图3所示,通过依存句法结构和基本语义判别模型抽取句子的基本语义结构,再对基本语义结构中的词提取其子节点,并根据子节点词性和节点间的依存关系对句子语义结构进行调整,进而得到句子的首层语义结构。具体步骤如下:
a.遍历整个句子的依存句法结构,抽取首层语义中每个节点的子节点。
b.若首层语义中的节点有子节点则继续下面的步骤,若没有子节点,则设为叶子节点。
c.对子节点词性进行判断,若为疑问词则节点上移一层,若为介词,且介词的介宾结构不做状语,则该节点上移一层,并保持原句子顺序不变
d.对子节点依存关系进行判断,若为定中关系且两个节点在原句中连续(即定语词和定语修饰的词中间不包含其它词),则进行合并,若不连续,则需根据不连续的原因判断是否合并,若由于多个定中子节点导致不连续或者定中嵌套状中导致不连续则合并,反之不合并。若为右附加关系,则节点上移。
1.5 递归调整模块
递归调整模块是在首层语义的基础上对首层语义的各个修饰成分进行分析和调整,从而得到整个句子的语义层次的过程,递归调整模块流程如图4所示。首先对首层语义中的非关键节点的子节点的修饰成分直接按从右到左的顺序层次展开,而对关键节点的子节点结构进行子句判断,若子节点构成嵌套子句,则以该子句为基本语义进行上述第3步操作,若不构成子句,若有子节点,则对子节点结构进行调整,若没有子节点,则设为叶子节点。对所有的子节点递归进行同样的处理,直到句子所有成分都处理完成为止。
2.实验结果与分析
本文用500句不同数据源的测试语句进行测试,其中聊天语句200句、新闻中的语句200句、经典文献中的语句100句。对测试语句进行基于依存分析的语义层次识别方法后得到句子的语义层次,然后由人工审核测试效果。测试结果如表1-3所示
从上面三个表格可以看出新闻和文献的准确率要比聊天语句的准确率明显要高,通过分析得到,这是由于新闻和文献的表达较规范,进行依存分析得到的依存句法结构准确率明显要高。此外通过排除依存分析错误干扰的情况下,准确率都达到了96%以上,说明大部分的错误都是来自于依存分析出错的影响,因此只要提升依存分析的准确率就可以明显提升语义层次识别的准确率。
3.结论
本文采用干扰符号过滤和专有名词替换的方法来改进依存分析对特殊符号效果不好的影响,并在依存分析的基础通过对依存句法结构进行首次语义抽取和递归调整策略得到句子的语义层次结构。实验证明,在不同数据源的测试语句进行测试均取得较好的效果。
由于时间以及实验环境的限制,本文提出的语义层次识别方法还有改进的地方,大规模测试数据的验证还需要一个过程。因此本文的后续工作还包括:寻找更准确的依存分析算法作为技术支持或寻找新的句法分析策略,优化递归调整策略,构建自动校验的机制并收集整理大规模的样本数据。
参考文献:
[1] 李世齐.面向文景转换的中文浅层语义分析方法研究[D].哈尔滨:哈尔滨工业大学,2011.
[3] 李军辉.中文句法语义分析及其联合学习机制研究[D].苏州:苏州大学,2010.
[4] NirenburgS,Raskin V. Ontological semantics [M].Cambridge: MIT Press,2004.
[5] 董振东.语义关系的表达和知识系统的构造 [J].语言文字应用,1998 (3):76-82.
[6] 李正华.依存句法分析统计模型及树库转化研究 [D].硕士学位论文.哈尔滨工业大学.2008.
[9] Fillmore C J. Frames and semantics of understanding [J]. Quaderni di Semantica, 1985,6(2):222-254.
[10] 付国宏. 汉语句法歧义消解的统计方法研究. 哈尔滨工业大学博士论文,2001.
[11] 赵军,黄昌宁. 汉语基本名词短语结构分析模型. 计算机学报,1999;22(2):136-141.
[12] 周强,黄昌宁. 基于局部优化的汉语句法分析方法.软件学报,1999;10(1):4-6.
[13] 徐艳华. 现代汉语实词语法功能考察及词类体系重构 [D]. 南京:南京师范大学,2006.



